当前位置:网站首页>机器学习——集成学习
机器学习——集成学习
2022-08-05 10:55:00 【Ding Jiaxiong】
10. 集成学习
文章目录
通过建立几个模型来解决单一预测问题
10.1 工作原理
生成多个分类器/模型,各自独立地学习和作出预测
- 这些预测最后结合成组合预测,因此优于任何一个单分类的做出预测
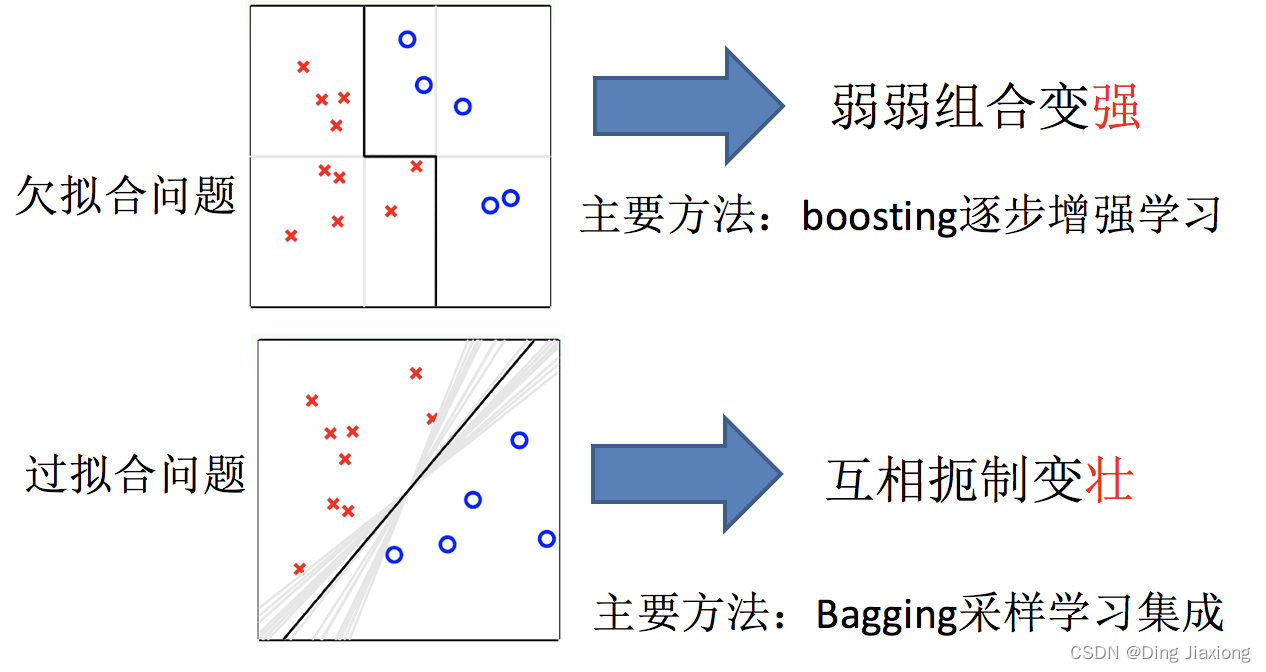
10.2 机器学习中的两个核心任务
如何优化训练数据 解决 欠拟合问题
如何提升泛化性能 解决 过拟合问题
10.3 boosting和Bagging
10.4 Bagging
主要实现过程
- 采样
- 学习
- 集成
10.5 随机森林构造过程
随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定
随机森林 = Bagging + 决策树
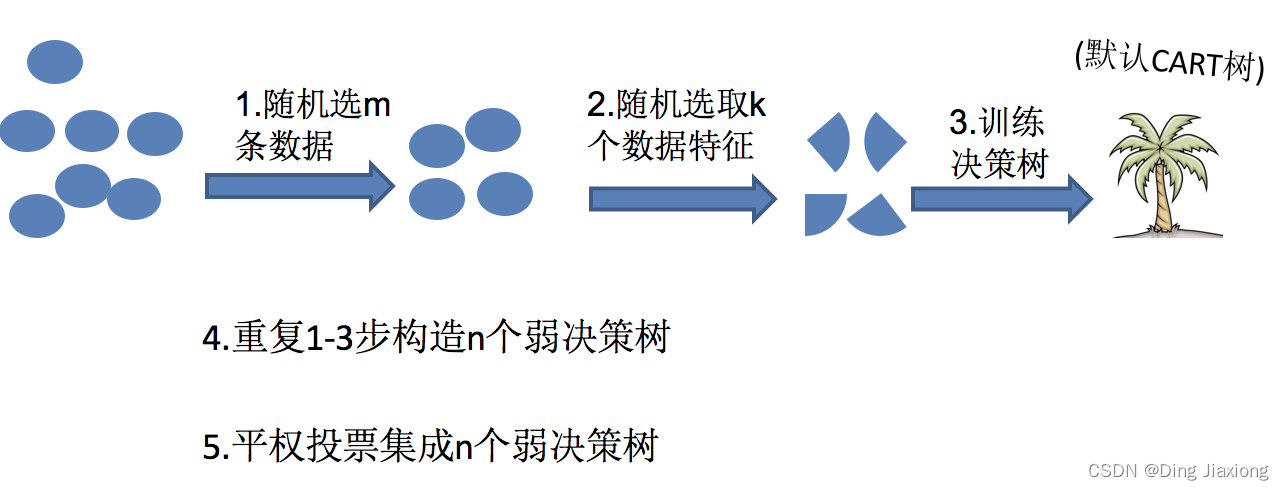
10.5.1 关键步骤
- 1)一次随机选出一个样本,有放回的抽样,重复N次(有可能出现重复的样本)
- 2) 随机去选出m个特征, m <<M,建立决策树
10.6 随机森林API
10.6.1 sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion=’gini’, max_depth=None, bootstrap=True, random_state=None, min_samples_split=2)
n_estimators:integer,optional(default = 10)森林里的树木数量
Criterion:string,可选(default =“gini”)分割特征的测量方法
max_depth:integer或None,可选(默认=无)树的最大深度
max_features="auto”,每个决策树的最大特征数量
- If “auto”, then max_features=sqrt(n_features).
- If “sqrt”, then max_features=sqrt(n_features)(same as “auto”).
- If “log2”, then max_features=log2(n_features).
- If None, then max_features=n_features.
bootstrap:boolean,optional(default = True)是否在构建树时使用放回抽样
min_samples_split:节点划分最少样本数
min_samples_leaf:叶子节点的最小样本数
10.6.2 超参数:n_estimator, max_depth, min_samples_split,min_samples_leaf
10.7 bagging集成优点
Bagging + 决策树/线性回归/逻辑回归/深度学习… = bagging集成学习方法
10.7.1 优点
- 均可在原有算法上提高约2%左右的泛化正确率
- 简单, 方便, 通用
10.8 Boosting集成
每新加入一个弱学习器,整体能力就会得到提升
10.8.1 代表算法
- Adaboost
- GBDT
- XGBoost
10.8.2 AdaBoost的构造过程小结

10.8.3 API
- from sklearn.ensemble import AdaBoostClassifier
10.9 bagging集成与boosting集成的区别
10.9.1 数据方面
- Bagging:对数据进行采样训练;
Boosting:根据前一轮学习结果调整数据的重要性。
10.9.2 投票方面
- Bagging:所有学习器平权投票;
Boosting:对学习器进行加权投票。
10.9.3 学习顺序
- Bagging的学习是并行的,每个学习器没有依赖关系;
Boosting学习是串行,学习有先后顺序。
10.9.4 主要作用
- Bagging主要用于提高泛化性能(解决过拟合,也可以说降低方差)
Boosting主要用于提高训练精度 (解决欠拟合,也可以说降低偏差)
10.10 GBDT
梯度提升决策树(GBDT Gradient Boosting Decision Tree)
一种迭代的决策树算法,该算法由多棵决策树组成,所有树的结论累加起来做最终答案
GBDT = 梯度下降 + Boosting + 决策树
10.10.1 主要执行思想
- 1.使用梯度下降法优化代价函数;
- 2.使用一层决策树作为弱学习器,负梯度作为目标值;
- 3.利用boosting思想进行集成
10.11 XGBoost
XGBoost= 二阶泰勒展开+boosting+决策树+正则化
- 二阶泰勒展开:每一轮学习中,XGBoost对损失函数进行二阶泰勒展开,使用一阶和二阶梯度进行优化。
- Boosting:XGBoost使用Boosting提升思想对多个弱学习器进行迭代式学习
- 决策树:在每一轮学习中,XGBoost使用决策树算法作为弱学习进行优化。
- 正则化:在优化过程中XGBoost为防止过拟合,在损失函数中加入惩罚项,限制决策树的叶子节点个数以及决策树叶子节点的值。
10.12 泰勒展开式
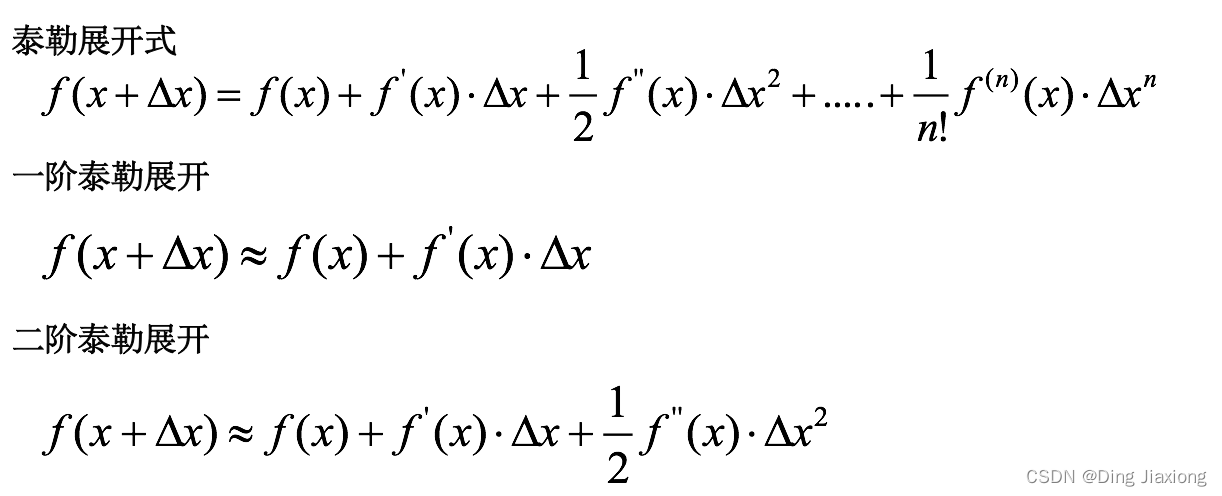
泰勒展开越多,计算结果越精确
边栏推荐
- DocuWare平台——文档管理的内容服务和工作流自动化的平台详细介绍(下)
- 【综合类型第 35 篇】程序员的七夕浪漫时刻
- Scaling-law和模型结构的关系:不是所有的结构放大后都能保持最好性能
- Android 开发用 Kotlin 编程语言三 循环控制
- poj2935 Basic Wall Maze (2016xynu暑期集训检测 -----D题)
- poj2287 Tian Ji -- The Horse Racing(2016xynu暑期集训检测 -----C题)
- 单片机:温度控制DS18B20
- #yyds干货盘点#【愚公系列】2022年08月 Go教学课程 001-Go语言前提简介
- PostgreSQL 2022 Report: Rising popularity, open source, reliability and scaling key
- Leetcode刷题——623. 在二叉树中增加一行
猜你喜欢

Opencv图像缩放和平移
微服务结合领域驱动设计落地
TiDB 6.0 Placement Rules In SQL 使用实践
阿里全新推出:微服务突击手册,把所有操作都写出来了PDF

PostgreSQL 2022 报告:流行度上涨,开源、可靠性和扩展是关键

#yyds干货盘点#【愚公系列】2022年08月 Go教学课程 001-Go语言前提简介

今天告诉你界面控件DevExpress WinForms为何弃用经典视觉样式
CenOS MySQL入门及安装
Huawei's lightweight neural network architecture GhostNet has been upgraded again, and G-GhostNet (IJCV22) has shown its talents on the GPU
Dynamics 365Online PDF导出及打印
随机推荐
苹果Meta都在冲的Pancake技术,中国VR团队YVR竟抢先交出产品答卷
【名词】什么是PV和UV?
R语言使用yardstick包的pr_curve函数评估多分类(Multiclass)模型的性能、查看模型在多分类每个分类上的ROC曲线(precision(精准率),R代表的是recall(召回率)
如何修改管理工具client_encoding
单片机:温度控制DS18B20
软件测试之集成测试
Ali's new launch: Microservices Assault Manual, all operations are written out in PDF
张朝阳对话俞敏洪:一边是手推物理公式,一边是古诗信手拈来
第九章:activit内置用户组设计与组任务分配和IdentityService接口的使用
数据可视化(一)
Google启动通用图像嵌入挑战赛
Detailed explanation of PPOCR detector configuration file parameters
学生信息管理系统(第一次.....)
The fuse: OAuth 2.0 four authorized login methods must read
2022 Hangzhou Electric Power Multi-School Session 6 1008.Shinobu Loves Segment Tree Regular Questions
JS introduction to reverse the recycling business network of learning, simple encryption mobile phone number
.NET深入解析LINQ框架(六:LINQ执行表达式)
一张图看懂 SQL 的各种 join 用法!
Http-Sumggling缓存漏洞分析
PostgreSQL 2022 报告:流行度上涨,开源、可靠性和扩展是关键