当前位置:网站首页>Pytorch学习记录(八):生成对抗网络GAN
Pytorch学习记录(八):生成对抗网络GAN
2022-08-01 20:55:00 【狸狸Arina】
1. GAN 原理
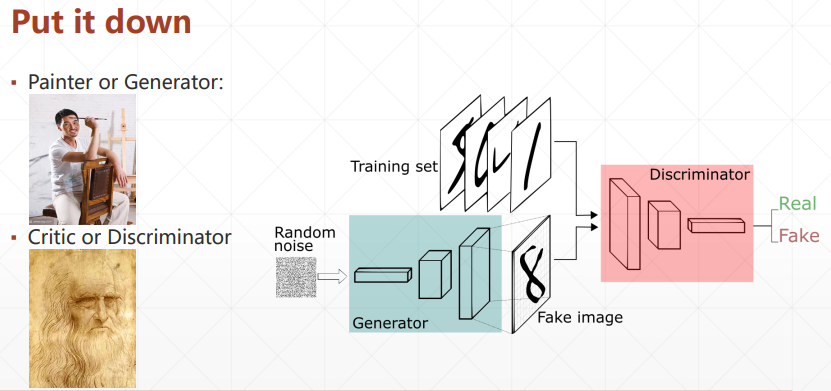
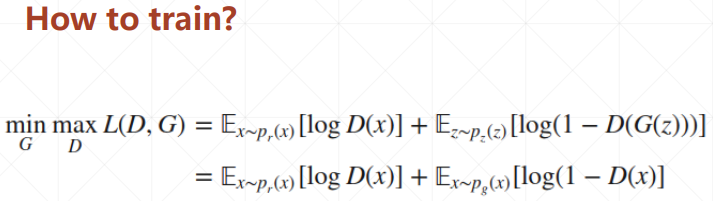
2. 纳什均衡



3. JS散度的缺陷
- 当两个分布完全不重叠的时候,对于任意的x输入,其JS散度值等于log2;
- 在固定D从而训练G时(此时网络损失和JS散度呈线性关系),会导致JS散度值为一个常量值,从而网络的损失也固定为一个常量值,从而网络参数梯度为0,参数得不到更新,训练不稳定;

4. EM距离
- 能够解决由于训练数据和虚假数据分布不重叠而导致的网络训练不稳定的问题,使用Wssserstein距离替代原来JS散度的损失;

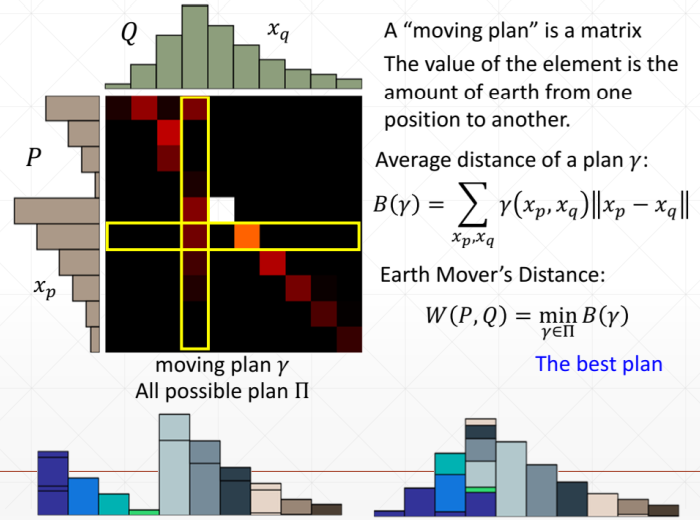

5. GAN 实现
import torch
from torch import nn, optim, autograd
import numpy as np
import visdom
import random
h_dim = 400
batchsz = 512
viz = visdom.Visdom()
class Generator(nn.Module):
def __init__(self, h_dim):
super().__init__()
self.net = nn.Sequential(
nn.Linear(2, h_dim),
nn.ReLU(inplace=True),
nn.Linear(h_dim, h_dim),
nn.ReLU(inplace=True),
nn.Linear(h_dim, h_dim),
nn.ReLU(inplace=True),
nn.Linear(h_dim, 2)
)
def forward(self, x):
return self.net(x)
class Discriminator(nn.Module):
def __init__(self, h_dim):
super().__init__()
self.net = nn.Sequential(
nn.Linear(2, h_dim),
nn.ReLU(inplace=True),
nn.Linear(h_dim, h_dim),
nn.ReLU(inplace=True),
nn.Linear(h_dim, h_dim),
nn.ReLU(inplace=True),
nn.Linear(h_dim, 1), #输出分类概率
nn.Sigmoid()
)
def forward(self, x):
return self.net(x).view(-1)
def data_gernerator():
scale = 2
centers = [(1,0),(-1,0),(0,1),(0,-1),
(1. / np.sqrt(2), 1. / np.sqrt(2)),
(1. / np.sqrt(2), -1. / np.sqrt(2)),
(-1. / np.sqrt(2), 1. / np.sqrt(2)),
(-1. / np.sqrt(2), -1. / np.sqrt(2))]
centers = [(scale * x, scale * y) for x,y in centers]
while True:
dataset = []
for i in range(batchsz):
point = np.random.randn(2) * 0.02 #随机采样两个数据
center = random.choice(centers) #从八个高斯分布中随机选一个
# N(0,1) + center_x1/x2 加上一个均值,方差还是为1
point[0] += center[0]
point[1] += center[1]
dataset.append(point)
dataset = np.array(dataset).astype(np.float32)
dataset /= 1.414
yield dataset #保存状态,返回dataset,下次运行时又继续从while处开始执行
def main():
# 固定随机性
torch.manual_seed(23)
np.random.seed(23)
data_iter = data_gernerator()
x = next(data_iter)
# print(x.shape) [b, 2]
G = Generator(h_dim)
D = Discriminator(h_dim)
optim_G = optim.Adam(G.parameters(), lr = 5e-4, betas=(0.5, 0.9))
optim_D = optim.Adam(D.parameters(), lr = 5e-4, betas=(0.5, 0.9))
for epoch in range(50000):
# Generator 和 Discriminator交替训练
# 一般先训 Discrimator
# 1. train Discriminator firstly, max(D(x)), min(D(G(z)))
for _ in range(5):
# 1.1 train on real data
x = next(data_iter)
x = torch.from_numpy(x)
pred_real = D(x) #真实数据的判决结果
loss_real = -pred_real.mean() # max pred_real
# 1.2 train on fake data
z = torch.randn(batchsz, 2) #随机生成噪声
x_fake = G(z).detach() #根据噪声生成假的数据 tf.stop_gradient()
pred_fake = D(x_fake) #假的数据的判决结果
loss_fake = pred_fake.mean()
# 1.3 aggreate loss
loss_D = loss_real + loss_fake #最大化真实数据的判决概率, 最小化生成数据的判决概率
# 1.4 optimize
optim_D.zero_grad()
loss_D.backward()
optim_D.step()
# 2. train Generator, max D(G(z))
z = torch.randn(batchsz, 2) #随机生成噪声
x_fake = G(z) #不能detach, 因为D在G后面
pred_fake = D(x_fake) # D和G都有梯度反向传播,但只有G更新
loss_G = - pred_fake.mean() # 最大化生成数据的判决概率
# optimize
optim_G.zero_grad()
loss_G.backward() #反向传播计算G和D的梯度
optim_G.step() #只更新G的参数
if epoch % 100 == 0:
print(loss_D.item(), loss_G.item())
#会出现 0.0, -1.0两个值
# 原因是Discriminator训练得很好,可以很好地将真假数据区分开来, 所以loss为0
# 但由于Generator训练过程中, 使用JS散度不能衡量两个没有重叠的分布,使得网络没有梯度信息,
# Generator长期得不到更新,所以loss长期处于-1.0.
if __name__ == '__main__':
main()
''' -0.14626020193099976 -0.47136804461479187 0.0 -1.0 0.0 -1.0 0.0 -1.0 0.0 -1.0 0.0 -1.0 0.0 -1.0 0.0 -1.0 '''
...
6. WGAN 实现
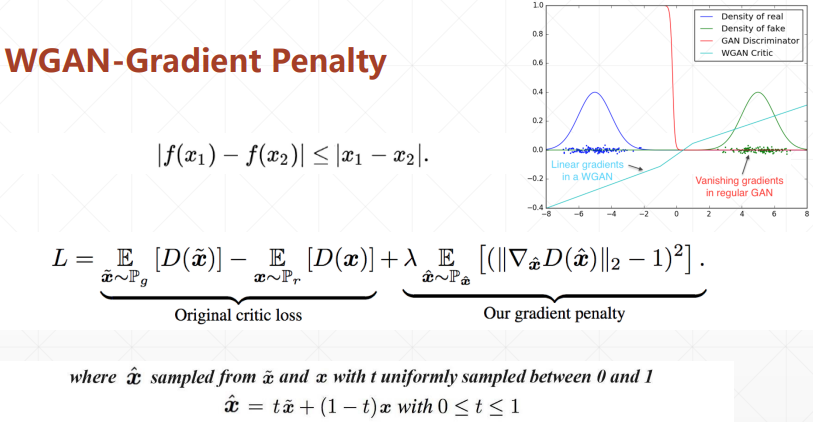
from re import L
import torch
from torch import nn, optim, autograd
import numpy as np
import visdom
import random
h_dim = 400
batchsz = 512
viz = visdom.Visdom()
class Generator(nn.Module):
def __init__(self, h_dim):
super().__init__()
self.net = nn.Sequential(
nn.Linear(2, h_dim),
nn.ReLU(inplace=True),
nn.Linear(h_dim, h_dim),
nn.ReLU(inplace=True),
nn.Linear(h_dim, h_dim),
nn.ReLU(inplace=True),
nn.Linear(h_dim, 2)
)
def forward(self, x):
return self.net(x)
class Discriminator(nn.Module):
def __init__(self, h_dim):
super().__init__()
self.net = nn.Sequential(
nn.Linear(2, h_dim),
nn.ReLU(inplace=True),
nn.Linear(h_dim, h_dim),
nn.ReLU(inplace=True),
nn.Linear(h_dim, h_dim),
nn.ReLU(inplace=True),
nn.Linear(h_dim, 1), #输出分类概率
nn.Sigmoid()
)
def forward(self, x):
return self.net(x).view(-1)
def data_gernerator():
scale = 2
centers = [(1,0),(-1,0),(0,1),(0,-1),
(1. / np.sqrt(2), 1. / np.sqrt(2)),
(1. / np.sqrt(2), -1. / np.sqrt(2)),
(-1. / np.sqrt(2), 1. / np.sqrt(2)),
(-1. / np.sqrt(2), -1. / np.sqrt(2))]
centers = [(scale * x, scale * y) for x,y in centers]
while True:
dataset = []
for i in range(batchsz):
point = np.random.randn(2) * 0.02 #随机采样两个数据
center = random.choice(centers) #从八个高斯分布中随机选一个
# N(0,1) + center_x1/x2 加上一个均值,方差还是为1
point[0] += center[0]
point[1] += center[1]
dataset.append(point)
dataset = np.array(dataset).astype(np.float32)
dataset /= 1.414
yield dataset #保存状态,返回dataset,下次运行时又继续从while处开始执行
def gradient_penalty(D, x_real, x_fake): #dskj1
t = torch.rand(batchsz, 1) #随机sample
# [b,1]=>[b,2]
t = t.expand_as(x_real)
x = t*x_real + (1-t)*x_fake #真实数据和fake数据之间做一个线性插值
x.requires_grad_() #设置x需要导数信息
pred = D(x)
grads = autograd.grad(outputs = pred, inputs=x,
grad_outputs=torch.ones_like(pred),
create_graph=True, #用于二阶求导
retain_graph=True, #如果还需要backward一次,就把这个梯度信息保留下来,否则会报错
only_inputs=True
)[0]
gp = torch.pow((grads.norm(2, dim = 1) -1), 2).mean()
return gp
def main():
# 固定随机性
torch.manual_seed(23)
np.random.seed(23)
data_iter = data_gernerator()
x = next(data_iter)
# print(x.shape) [b, 2]
G = Generator(h_dim)
D = Discriminator(h_dim)
optim_G = optim.Adam(G.parameters(), lr = 5e-4, betas=(0.5, 0.9))
optim_D = optim.Adam(D.parameters(), lr = 5e-4, betas=(0.5, 0.9))
for epoch in range(50000):
# Generator 和 Discriminator交替训练
# 一般先训 Discrimator
# 1. train Discriminator firstly, max(D(x)), min(D(G(z)))
for _ in range(5):
# 1.1 train on real data
x = next(data_iter)
x = torch.from_numpy(x)
pred_real = D(x) #真实数据的判决结果
loss_real = -pred_real.mean() # max pred_real
# 1.2 train on fake data
z = torch.randn(batchsz, 2) #随机生成噪声
x_fake = G(z).detach() #根据噪声生成假的数据 tf.stop_gradient()
pred_fake = D(x_fake) #假的数据的判决结果
loss_fake = pred_fake.mean()
# 1.3 gradient penalty
gp = gradient_penalty(D, x, x_fake.detach()) #这里x_fake要detach一下,因为不需要对它进行求导
# 1.4 aggreate loss
loss_D = loss_real + loss_fake + 0.2 * gp #最大化真实数据的判决概率, 最小化生成数据的判决概率
# 1.4 optimize
optim_D.zero_grad()
loss_D.backward()
optim_D.step()
# 2. train Generator, max D(G(z))
z = torch.randn(batchsz, 2) #随机生成噪声
x_fake = G(z) #不能detach, 因为D在G后面
pred_fake = D(x_fake) # D和G都有梯度反向传播,但只有G更新
loss_G = - pred_fake.mean() # 最大化生成数据的判决概率
# optimize
optim_G.zero_grad()
loss_G.backward() #反向传播计算G和D的梯度
optim_G.step() #只更新G的参数
if epoch % 100 == 0:
print(loss_D.item(), loss_G.item())
#会出现 0.0, -1.0两个值
# 原因是Discriminator训练得很好,可以很好地将真假数据区分开来, 所以loss为0
# 但由于Generator训练过程中, 使用JS散度不能衡量两个没有重叠的分布,使得网络没有梯度信息,
# Generator长期得不到更新,所以loss长期处于-1.0.
if __name__ == '__main__':
main()
''' 0.010273948311805725 -0.4702531099319458 -0.5763486623764038 -0.1938347965478897 -0.20412319898605347 -0.4627363085746765 -0.21898901462554932 -0.4972558617591858 -0.13111859560012817 -0.504425048828125 -0.1431763768196106 -0.4709075689315796 -0.09945613145828247 -0.5348900556564331 '''
边栏推荐
- LTE time domain and frequency domain resources
- 任务调度线程池-应用定时任务
- 4.1 配置Mysql与注册登录模块
- 写给刚进互联网圈子的人,不管你是开发,测试,产品,运维都适用
- [Energy Conservation Institute] Application of Intelligent Control Device in High Voltage Switchgear
- Custom command to get focus
- Determine a binary tree given inorder traversal and another traversal method
- Simple test of the use of iptables
- OSG Notes: Set DO_NOT_COMPUTE_NEAR_FAR to manually calculate far and near planes
- 进行交互或动画时如何选择Visibility, Display, and Opacity
猜你喜欢

Wildcard SSL/TLS certificate

STAHL touch screen repair all-in-one display screen ET-316-TX-TFT common faults

Convolutional Neural Network (CNN) mnist Digit Recognition - Tensorflow

OSG Notes: Set DO_NOT_COMPUTE_NEAR_FAR to manually calculate far and near planes

【节能学院】智能操控装置在高压开关柜的应用
【多任务模型】Progressive Layered Extraction: A Novel Multi-Task Learning Model for Personalized(RecSys‘20)

2022年秋招,软件测试开发最全面试攻略,吃透16个技术栈

WhatsApp group sending actual combat sharing - WhatsApp Business API account

】 【 nn. The Parameter () to generate and why do you want to initialize
![[Multi-task learning] Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts KDD18](/img/f3/a8813759e5b4dd4b4132e65672fc3f.png)
[Multi-task learning] Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts KDD18
随机推荐
Protocol Buffer usage
技术栈概览
LinkedList源码分享
WhatsApp群发实战分享——WhatsApp Business API账号
[Multi-task learning] Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts KDD18
Redis does web page UV statistics
【luogu P1912】诗人小G(二分栈)(决策单调性优化DP)
】 【 nn. The Parameter () to generate and why do you want to initialize
tiup mirror clone
小数据如何学习?吉大最新《小数据学习》综述,26页pdf涵盖269页文献阐述小数据学习理论、方法与应用
Internet使用的网络协议是什么
LTE time domain and frequency domain resources
Acrel-5010重点用能单位能耗在线监测系统在湖南三立集团的应用
织梦发布文章提示body has not allow words错误
To promote energy conservation institute 】 【 the opinions of the agricultural water price reform
宝塔搭建PESCMS-Ticket开源客服工单系统源码实测
数据库单字段存储多个标签(位移操作)
Failed to re-init queues : Illegal queue capacity setting (abs-capacity=0.6) > (abs-maximum-capacity
人工智能可信安全与评测
Multithreaded producers and consumers