当前位置:网站首页>Technical practice of dolphin dispatching in kubernetes system
Technical practice of dolphin dispatching in kubernetes system
2022-06-11 09:23:00 【CSDN cloud computing】


author | Yangdian
edit | warrior_
* Editor's note
Kubernetes Is a container based technology 、 Implement container choreography 、 A cluster system that provides microservices and buses , It involves a large number of knowledge systems .
This article starts from the author's actual work experience , It shows us the use and technology sharing of dolphin scheduling in actual scenarios , I hope this article can give some inspiration to people who have the same experience .
Why do we use dolphin scheduling ,
What value has it brought , What's the problem
Dolphin scheduling is an excellent distributed and extensible visual workflow task scheduling platform .
Starting from the author's industry , The application of dolphin scheduling has quickly solved the ten pain points in data development :
Multi source data connection and access , Most common data sources in the technical field can be accessed , Adding a new data source does not require much change ;
diversified + professional + Massive data task management , Really focus on big data (hadoop family,flink etc. ) Task scheduling , It is significantly different from the traditional scheduler ;
Graphical task scheduling , Super user experience , It can be directly benchmarked with commercial products , And most foreign open source products cannot directly drag and drop the task of generating data ;
Task details , Atomic task rich view 、 Log view , The timeline displays , Meet the developers' fine management of data tasks , Fast positioning is slow sql, Performance bottleneck ;
Support for multiple distributed file systems , Enrich users' choice of unstructured data ;
Natural multi tenant management , Meet the data task management and isolation requirements of large organizations ;
Fully automatic distributed scheduling algorithm , Balance all scheduled tasks ;
With cluster monitoring function , monitor cpu, Memory , The number of connections ,zookeeper state , It is suitable for one-stop operation and maintenance of small and medium-sized enterprises ;
Built in task alarm function , Minimize the risk of task operation ;
Strong community operation , Listen to the real voice of the customer , Constantly adding new functions , Continuously optimize the customer experience ;
In the projects that the author participated in online dolphin scheduling , Also encountered many new challenges :
How to deploy dolphin dispatch with less human resources , Whether the fully automatic cluster installation and deployment mode can be realized ?
How to standardize technical component implementation specifications ?
Whether it can be unsupervised , System self healing ?
Network security control requirements , How to achieve air-gap Mode installation and update ?
Whether it can automatically expand the capacity without feeling ?
How to build and integrate the monitoring system ?
Based on the above challenges , We have incorporated dolphin scheduling into the existing kubernetes Cloud native system , Solve the pain , Make dolphin technology more powerful .
Kubernetes Technical system
New technical features brought to dolphin dispatching
In the use of kubernetes After managing dolphins , The overall technical scheme soon has rich and efficient technical features , It also solves the above practical challenges :
Various independent deployment projects , Quickly establish development and production environments , All of them have realized one click deployment , One click upgrade implementation mode ;
Fully support offline installation without Internet , Cutting installation speed is faster ;
Try to unify the information of installation configuration , Reduce exceptions to multiple project configurations , All configuration items , Can be based on different projects through the enterprise git management ;
And object storage technology , The technology of unifying unstructured data ;
Convenient monitoring system , With the existing prometheus Monitoring system integration ;
Mixed use of multiple schedulers ;
Fully automatic resource adjustment capability ;
Fast self-healing ability , Automatic abnormal restart , And restart based on probe mode ;
The cases in this paper are all based on dolphin scheduling 1.3.9 Version based .
be based on Helm Automated and efficient deployment of tools
First , We will introduce the helm Installation method of .helm Is to find 、 Share and use software to build kubernetes The best way . It's also Yunyuan cncf One of my graduation projects .

Dolphin's official website and github There are very detailed configuration files and cases on . Here we will focus on some of the consultations and problems that often occur in the community .
Official website document address
https://dolphinscheduler.apache.org/zh-cn/docs/1.3.9/user_doc/kubernetes-deployment.html
github Folder address
https://github.com/apache/dolphinscheduler/tree/1.3.9-release/docker/kubernetes/dolphinscheduler
stay value.yaml Modify the image in the file , For offline installation (air-gap install);
image:
repository: "apache/dolphinscheduler"
tag: "1.3.9"
pullPolicy: "IfNotPresent"For internal installed harbor, Or other private warehouses of the public cloud , Conduct pull,tag, as well as push. Here we assume that the private warehouse address is harbor.abc.com, The host on which the image is being built has docker login harbor.abc.com, And the private warehouse has been established and authorized to create apache project .
perform shell command
docker pull apache/dolphinscheduler:1.3.9
dock tag apache/dolphinscheduler:1.3.9 harbor.abc.com/apache/dolphinscheduler:1.3.9
docker push apache/dolphinscheduler:1.3.9Replace with value Image information in the file , Here we recommend Always To pull the image , In the production environment, try to check whether it is the latest image content every time , Ensure the correctness of software products . Besides , Many students will put tag It's written in latest, Make an image without writing tag Information , This is very dangerous in the production environment , anybody push Mirrored , It's a change latest Mirror image , And I can't judge latest What version is it , Therefore, it is suggested to specify the of each release tag, And use Always.
image:
repository: "harbor.abc.com/apache/dolphinscheduler"
tag: "1.3.9"
pullPolicy: "Always"hold https://github.com/apache/dolphinscheduler/tree/1.3.9-release/docker/kubernetes/dolphinscheduler Entire directory copy To be able to execute helm Command host , Then follow the official website
kubectl create ns ds139
helm install dolphinscheduler . -n ds139Offline installation can be realized .
Integrate datax、mysql、oracle Client component , Download the following components first
https://repo1.maven.org/maven2/mysql/mysql-connector-java/5.1.49/mysql-connector-java-5.1.49.jar
https://repo1.maven.org/maven2/com/oracle/database/jdbc/ojdbc8/
https://github.com/alibaba/DataX/blob/master/userGuid.md
Compile and build according to the prompts , The package is located at
{DataX_source_code_home}/target/datax/datax/
Based on the above plugin New component dockerfile, The basic image can use the already push Mirror image to private warehouse .
FROM harbor.abc.com/apache/dolphinscheduler:1.3.9
COPY *.jar /opt/dolphinscheduler/lib/
RUN mkdir -p /opt/soft/datax
COPY datax /opt/soft/dataxpreservation dockerfile, perform shell command
docker build -t harbor.abc.com/apache/dolphinscheduler:1.3.9-mysql-oracle-datax . # Don't forget the last point
docker push harbor.abc.com/apache/dolphinscheduler:1.3.9-mysql-oracle-dataxmodify value file
image:
repository: "harbor.abc.com/apache/dolphinscheduler"
tag: "1.3.9-mysql-oracle-datax"
pullPolicy: "Always"perform helm install dolphinscheduler . -n ds139, Or perform helm upgrade dolphinscheduler -n ds139, You can also start with helm uninstall dolphinscheduler -n ds139, Re execution helm install dolphinscheduler . -n ds139.
It is generally recommended to use independent peripherals in production environments postgresql As a management database , And use a stand-alone installation zookeeper Environmental Science ( This case uses zookeeper operator https://github.com/pravega/zookeeper-operator, In the same place as the dolphin kubernetes In the cluster ). We found that , After using the external database , The dolphin is dispatched in kubernetes Complete deletion in , Then redeploy dolphin dispatch , Mission data 、 Tenant data 、 User data and so on are reserved , This verifies the high availability and data integrity of the system once again .( If you delete pvc , The historical job log will be lost )
## If not exists external database, by default, Dolphinscheduler's database will use it.
postgresql:
enabled: false
postgresqlUsername: "root"
postgresqlPassword: "root"
postgresqlDatabase: "dolphinscheduler"
persistence:
enabled: false
size: "20Gi"
storageClass: "-"
## If exists external database, and set postgresql.enable value to false.
## external database will be used, otherwise Dolphinscheduler's database will be used.
externalDatabase:
type: "postgresql"
driver: "org.postgresql.Driver"
host: "192.168.1.100"
port: "5432"
username: "admin"
password: "password"
database: "dolphinscheduler"
params: "characterEncoding=utf8"
## If not exists external zookeeper, by default, Dolphinscheduler's zookeeper will use it.
zookeeper:
enabled: false
fourlwCommandsWhitelist: "srvr,ruok,wchs,cons"
persistence:
enabled: false
size: "20Gi"
storageClass: "storage-nfs"
zookeeperRoot: "/dolphinscheduler"
## If exists external zookeeper, and set zookeeper.enable value to false.
## If zookeeper.enable is false, Dolphinscheduler's zookeeper will use it.
externalZookeeper:
zookeeperQuorum: "zookeeper-0.zookeeper-headless.zookeeper.svc.cluster.local:2181,zookeeper-1.zookeeper-headless.zookeeper.svc.cluster.local:2181,zookeeper-2.zookeeper-headless.zookeeper.svc.cluster.local:2181"
zookeeperRoot: "/dolphinscheduler"be based on argo-cd Of gitops Deployment way
argo-cd Is based on Kubernetes The declarative form of gitops Continuous delivery tools .argo-cd yes cncf The incubation program of ,gitops Best practice tools for . About gitops The explanation can be referred to https://about.gitlab.com/topics/gitops/

gitops It can bring the following advantages to the implementation of dolphin scheduling .
Graphical installation of clustered software , A key to install ;
git Record the full release process , One click rollback ;
Convenient dolphin tool log viewing ;
Use argo-cd Implementation and installation steps of :
from github Download dolphin scheduling source code , modify value file , Refer to the previous chapter helm Install what needs to be modified ;
Create a new directory of the modified source code git project , also push To the inside of the company gitlab in ,github The directory name of the source code is docker/kubernetes/dolphinscheduler;
stay argo-cd Middle configuration gitlab Information , We use https The pattern of ;
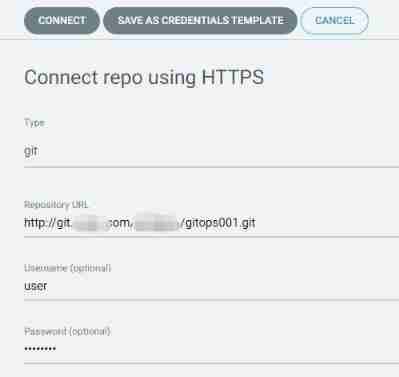
argo-cd Create a new deployment project , Fill in relevant information


Yes git Refresh and pull the deployment information in , Realize the final deployment . You can see pod,configmap,secret,service,ingress And so on , also argo-cd Shows the previous git push The use of commit Information and submitter user name , In this way, all the publishing event information is completely recorded . At the same time, you can roll back to the historical version with one click .
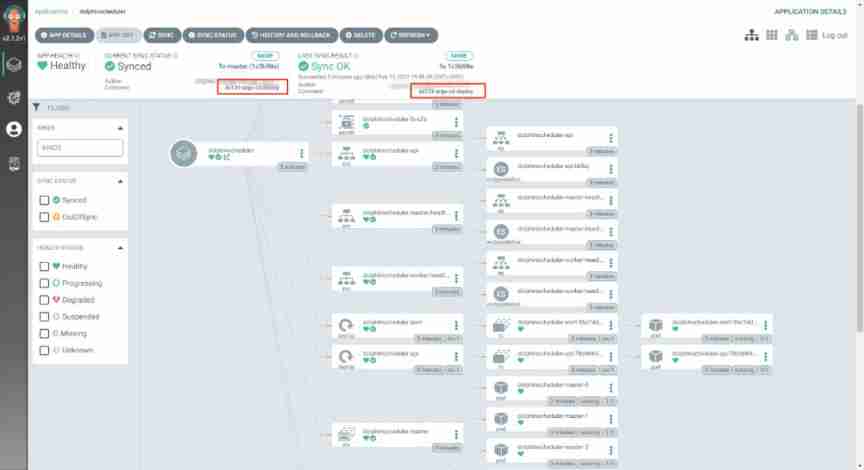

adopt kubectl Command can see relevant resource information ;
[[email protected] ~]# kubectl get po -n ds139
NAME READY STATUS RESTARTS AGE
dolphinscheduler-alert-96c74dc84-72cc9 1/1 Running 0 22m
dolphinscheduler-api-78db664b7b-gsltq 1/1 Running 0 22m
dolphinscheduler-master-0 1/1 Running 0 22m
dolphinscheduler-master-1 1/1 Running 0 22m
dolphinscheduler-master-2 1/1 Running 0 22m
dolphinscheduler-worker-0 1/1 Running 0 22m
dolphinscheduler-worker-1 1/1 Running 0 22m
dolphinscheduler-worker-2 1/1 Running 0 22m
[[email protected] ~]# kubectl get statefulset -n ds139
NAME READY AGE
dolphinscheduler-master 3/3 22m
dolphinscheduler-worker 3/3 22m
[[email protected] ~]# kubectl get cm -n ds139
NAME DATA AGE
dolphinscheduler-alert 15 23m
dolphinscheduler-api 1 23m
dolphinscheduler-common 29 23m
dolphinscheduler-master 10 23m
dolphinscheduler-worker 7 23m
[[email protected] ~]# kubectl get service -n ds139
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
dolphinscheduler-api ClusterIP 10.43.238.5 <none> 12345/TCP 23m
dolphinscheduler-master-headless ClusterIP None <none> 5678/TCP 23m
dolphinscheduler-worker-headless ClusterIP None <none> 1234/TCP,50051/TCP 23m
[[email protected] ~]# kubectl get ingress -n ds139
NAME CLASS HOSTS ADDRESS
dolphinscheduler <none> ds139.abc.comYou can see everything pod All scattered kubernetes Different in the cluster host On , for example worker 1 and 2 On different nodes .


We've configured ingress, A pan domain name is configured inside the company to facilitate access by using the domain name ;
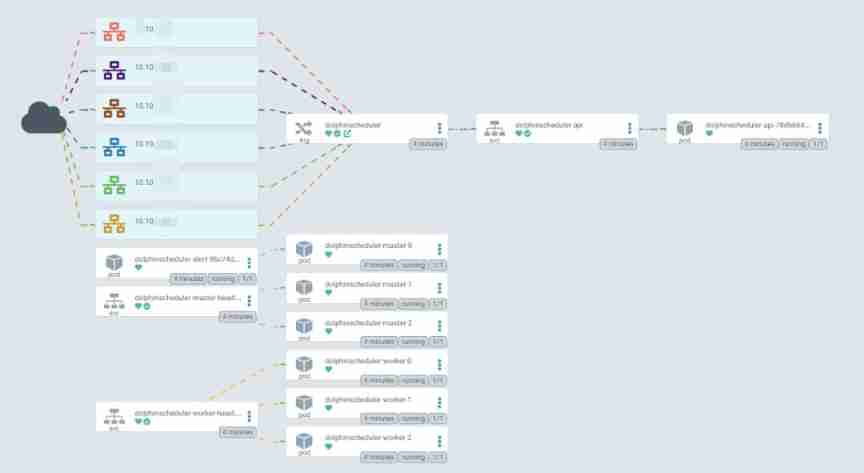
You can log in to the domain name to access .

The specific configuration can be modified value Contents of the file :
ingress:
enabled: true
host: "ds139.abc.com"
path: "/dolphinscheduler"
tls:
enabled: false
secretName: "dolphinscheduler-tls"It is convenient to view the internal logs of dolphin scheduling components :

Check the deployed system ,3 individual master,3 individual worker,zookeeper All configurations are normal ;


Use argo-cd It can be easily modified master,worker,api,alert Number of copies of such components , Dolphin helm Configuration is also reserved cpu And memory setting information . Here we modify value Copy value in . After modification ,git pish Inside the company gitlab.
master:
## PodManagementPolicy controls how pods are created during initial scale up, when replacing pods on nodes, or when scaling down.
podManagementPolicy: "Parallel"
## Replicas is the desired number of replicas of the given Template.
replicas: "5"
worker:
## PodManagementPolicy controls how pods are created during initial scale up, when replacing pods on nodes, or when scaling down.
podManagementPolicy: "Parallel"
## Replicas is the desired number of replicas of the given Template.
replicas: "5"
alert:
## Number of desired pods. This is a pointer to distinguish between explicit zero and not specified. Defaults to 1.
replicas: "3"
api:
## Number of desired pods. This is a pointer to distinguish between explicit zero and not specified. Defaults to 1.
replicas: "3"Only need argo-cd Click on sync Sync , Corresponding pods Have been increased according to the demand


[[email protected] ~]# kubectl get po -n ds139
NAME READY STATUS RESTARTS AGE
dolphinscheduler-alert-96c74dc84-72cc9 1/1 Running 0 43m
dolphinscheduler-alert-96c74dc84-j6zdh 1/1 Running 0 2m27s
dolphinscheduler-alert-96c74dc84-rn9wb 1/1 Running 0 2m27s
dolphinscheduler-api-78db664b7b-6j8rj 1/1 Running 0 2m27s
dolphinscheduler-api-78db664b7b-bsdgv 1/1 Running 0 2m27s
dolphinscheduler-api-78db664b7b-gsltq 1/1 Running 0 43m
dolphinscheduler-master-0 1/1 Running 0 43m
dolphinscheduler-master-1 1/1 Running 0 43m
dolphinscheduler-master-2 1/1 Running 0 43m
dolphinscheduler-master-3 1/1 Running 0 2m27s
dolphinscheduler-master-4 1/1 Running 0 2m27s
dolphinscheduler-worker-0 1/1 Running 0 43m
dolphinscheduler-worker-1 1/1 Running 0 43m
dolphinscheduler-worker-2 1/1 Running 0 43m
dolphinscheduler-worker-3 1/1 Running 0 2m27s
dolphinscheduler-worker-4 1/1 Running 0 2m27sDolphin scheduling and S3 Object storage technology integration
Many students ask questions in the dolphin community , How to configure s3 minio Integration of . Here is based on kubernetes Of helm To configure .
modify value in s3 Part of , It is recommended to use ip+ The port points to minio The server .
common: ## Configmap configmap: DOLPHINSCHEDULER_OPTS: "" DATA_BASEDIR_PATH: "/tmp/dolphinscheduler" RESOURCE_STORAGE_TYPE: "S3" RESOURCE_UPLOAD_PATH: "/dolphinscheduler" FS_DEFAULT_FS: "s3a://dfs" FS_S3A_ENDPOINT: "http://192.168.1.100:9000" FS_S3A_ACCESS_KEY: "admin" FS_S3A_SECRET_KEY: "password"minio Where dolphin files are stored bucket The name is dolphinscheduler, Here, create new folders and files to test .minio The directory of is under the tenant of the upload operation .


Dolphin scheduling and Kube-prometheus Technology integration of
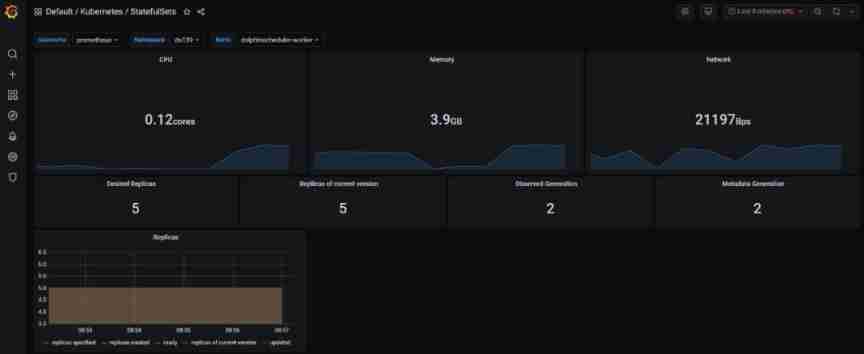
We are kubernetes Use kube-prometheus operator technology , After deploying dolphins , It automatically realizes the resource monitoring of each dolphin component .
Please note that kube-prometheus Version of , Need corresponding kubernetes Main version .https://github.com/prometheus-operator/kube-prometheus


Dolphin scheduling and Service Mesh Technology integration of
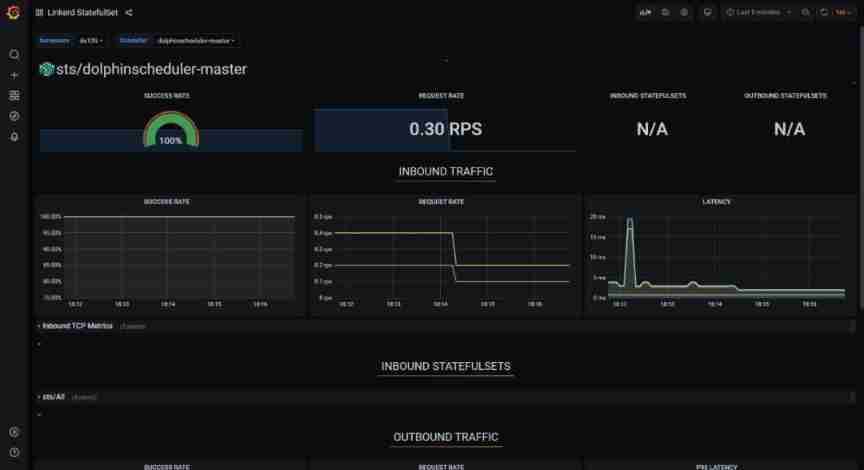
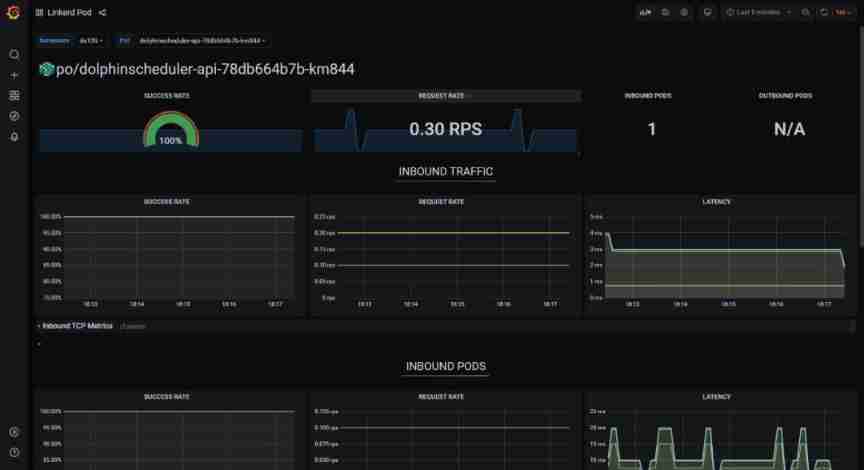
adopt service mesh Technology can realize the service call inside dolphin , And dolphins api Observability analysis of external calls , So as to realize the self service optimization of dolphin dispatching products .
We use linkerd As service mesh Product integration ,linkerd It's also cncf One of the excellent graduation projects .

Just in the dolphins helm Of value Modification in file annotations, Redeployment , You can quickly achieve mesh proxy sidecar The injection of . It can be done to master,worker,api,alert And so on .
annotations: #{}
linkerd.io/inject: enabledThe quality of service communication between components can be observed , The number of requests per second, etc .
The future of dolphin scheduling based on cloud native technology
Dolphin scheduling is a native big data tool for the new generation cloud , The future can be in kubernetes Ecology integrates more excellent tools and features , Meet more user groups and scenarios .
and argo-workflow Integration of , Can pass api,cli Etc. in dolphin scheduling argo-workflow Single job ,dag Homework , And periodic operations ;
Use hpa The way , Automatic volume expansion and shrinkage worker, Realize the horizontal expansion mode without human intervention ;
Integrate kubernetes Of spark operator and flink operator Tools , Comprehensive Yunyuan biochemistry ;
Realize the distributed job scheduling of multi cloud and multi cluster , strengthening serverless+faas Class schema properties ;
use sidecar Realize periodic deletion worker Job log , Further realize worry free operation and maintenance ;

Previous recommendation
from 40% Fell to 4%,“ paste ” the Firefox Can you return to the top ?
Gartner Release 2022 Five major technological trends in the automotive industry in
Use this library , Let your service operate Redis Speed up
comic : What is? “ Low code ” Development platform ?

Share

Point collection

A little bit of praise

Click to see
边栏推荐
- ERP体系的这些优势,你知道吗?
- 工厂出产流程中的这些问题,应该怎么处理?
- MSF基于SMB的信息收集
- [scheme development] sphygmomanometer scheme pressure sensor sic160
- Redis source code analysis hash object (z\u hash)
- Award winning survey streamnational sponsored 2022 Apache pulsar user questionnaire
- 机器学习笔记 - 使用TensorFlow的Spatial Transformer网络
- Video review pulsar summit Asia 2021, cases, operation and maintenance, ecological dry goods
- Remote office related issues to be considered by enterprises
- 2161. divide the array according to the given number
猜你喜欢

Opencv oak-d-w wide angle camera test

DOS command virtual environment

Some learning records I=

Exclusive interview - dialogue on open source Zhai Jia: excellent open source projects should be seen by more people. I am honored to participate in them
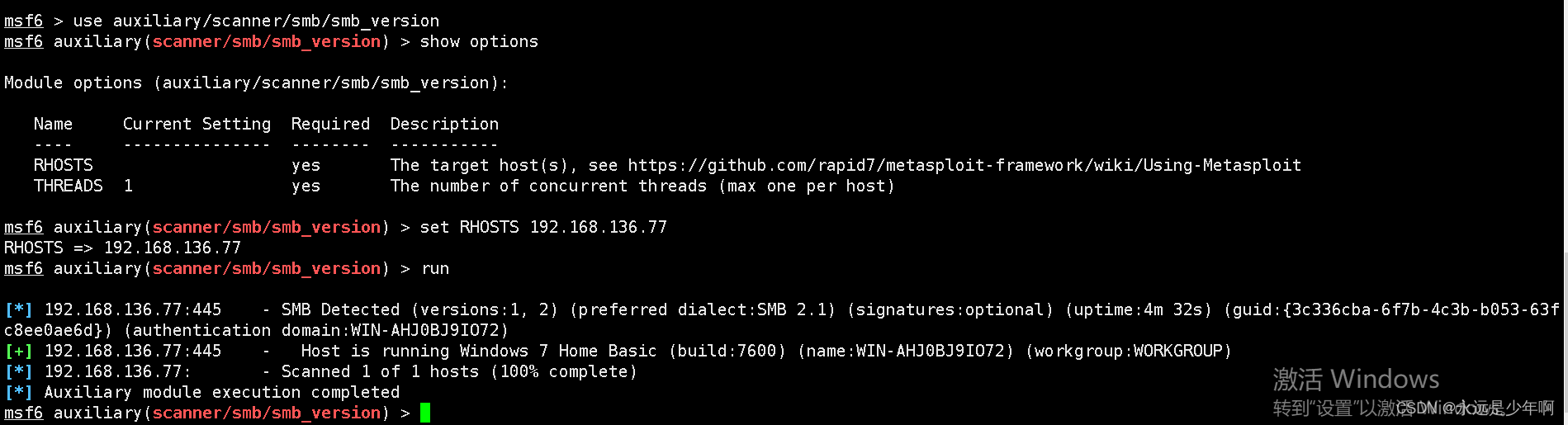
MSF SMB based information collection

Identifier keyword literal data type base conversion character encoding variable data type explanation operator

Type-C扩展坞自适应供电专利维权案例
![[C language - data storage] how is data stored in memory?](/img/cb/2d0cc83fd77de7179a9c45655c1a2d.png)
[C language - data storage] how is data stored in memory?

Résumé de la méthode d'examen des mathématiques

Openstack explanation (22) -- neutron plug-in configuration
随机推荐
Machine learning notes - spatial transformer network using tensorflow
面试题 17.10. 主要元素
【分享】企业如何进行施行规划?
Sword finger offer II 036 Postfix Expression
MySQL啟動報錯“Bind on TCP/IP port: Address already in use”
Detailed explanation of this and static
Interview question 17.10 Main elements
Talk about how to customize data desensitization
【软件】大企业ERP选型的方法
MSF adds back door to normal program
MSF evasion模块的使用
Fabric.js 动态设置字号大小
[C language - Advanced pointer] mining deeper knowledge of pointer
[ERP system] how much do you know about the professional and technical evaluation?
The mobile terminal page uses REM for adaptation
MSF基于SMB的信息收集
Shandong University project training (IV) -- wechat applet scans web QR code to realize web login
2161. 根据给定数字划分数组
Openstack explanation (24) -- registration of neutron service
affair