当前位置:网站首页>sql 常用优化
sql 常用优化
2022-07-07 17:52:00 【whiteye太白】
sql 优化
1. 小表驱动大表
先执行查询数据少的表,再执行查询数据多的表。
2. 建索引,一张表不超过5个索引
避免大量内存占用。
3. 走索引,尽量满足最左匹配,避免索引失效
索引失效:
(1)select *
(2)>、<、!=、between
(3)前置 % 的like查询。
(4)where字段值类型与数据库不一致,存在自动转换。
(5)or连接不同字段。
(6)or连接同一字段,但存在 >、<、!= 非索引查询。(左右查询均为索引时才有效。)
(7)函数或运算导致索引失效。
(8)IS NULL不走索引,IS NOT NULL走索引(表设计:非必要时,字段不要为NULL,设置默认空字符串或0)
(9)复合索出现范围查询时,后面的索引失效 。
(10)IN会走索引,但是当IN的取值范围较大时会导致索引失效。
- ep_range_index_dive_limit这个参数影响in是否使用索引,MySQL 5.6默认10, MySQL。5.7默认200。但是我们代码更倾向于控制在50内。 A表数据大于B表数据时,选择in比exists执行效率要高。 相反,A表数据小于B表数据时,选择exists比较高效。 in先执行子查询,exists先执行外表。
(11)not in会使索引失效,无论在哪种情况not exists 都比 not in 高效。
- 使用 left join 或 not exists 来优化not in 操作。
4. 尽量做到冷热数据分离
减少查询表列数,避免进行冷数据过滤。
5. 调整索引列的顺序
唯一性较好、字段较短、使用频繁的列放在联合索引的最左侧
6. 对于频繁的查询优先考虑使用覆盖索引
走索引时一并查询出数据。
7. 避免数据类型的隐式转换
避免索引失效。
8. 禁止使用 SELECT * 必须使用 SELECT <字段列表> 查询
会存在冗余字段,消耗更多的CPU和网络带宽 会无法使用覆盖索引。
9. 避免使用子查询,可以把子查询优化为 join 操作
子查询会产生大量的临时表也没有索引。
10. 避免使用 JOIN 关联太多的表
关联表越多关联缓存越大。
11. 在明显不会有重复值时使用 UNION ALL 而不是 UNION
UNION ALL不会进行去重操作,加快查询速度。
12. 大SQL拆分,多个同种SQL进行批处理
一个 SQL 只能使用一个cpu 进行计算,拆分后可由多个cpu并行计算。
13. WHERE 从句中禁止对列进行函数转换和计算
避免索引失效。
14. 使用count(*)而不是count(列名)?
综合性能:count(非主键列) < count(主键) < count(1) ≈ count()
count()是SQL92定义的标准统计行数的语法,跟数据库无关,count(*)会统计值为 NULL的行,而
count(列名)不会统计此列为 NULL值的行。
边栏推荐
- 吞吐量Throughout
- IP tools
- LC:字符串转换整数 (atoi) + 外观数列 + 最长公共前缀
- Semantic SLAM源码解析
- Jürgen Schmidhuber回顾LSTM论文等发表25周年:Long Short-Term Memory. All computable metaverses. Hierarchical reinforcement learning (RL). Meta-RL. Abstractions in generative adversarial RL. Soccer learn
- Throughput
- 小试牛刀之NunJucks模板引擎
- R language ggplot2 visualization: use the ggqqplot function of ggpubr package to visualize the QQ graph (Quantitative quantitative plot)
- 开源重器!九章云极DataCanvas公司YLearn因果学习开源项目即将发布!
- 2022.07.04
猜你喜欢

The project manager's "eight interview questions" is equal to a meeting
爬虫实战(七):爬王者英雄图片
![[RT thread env tool installation]](/img/bc/9b39651d40a240f0893200793f67e9.png)
[RT thread env tool installation]
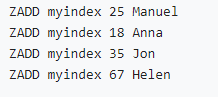
Implement secondary index with Gaussian redis

编译器优化那些事儿(4):归纳变量
![Jerry's headphones with the same channel are not allowed to pair [article]](/img/7d/3dcd9c7df583944e1d765b67543eb1.png)
Jerry's headphones with the same channel are not allowed to pair [article]
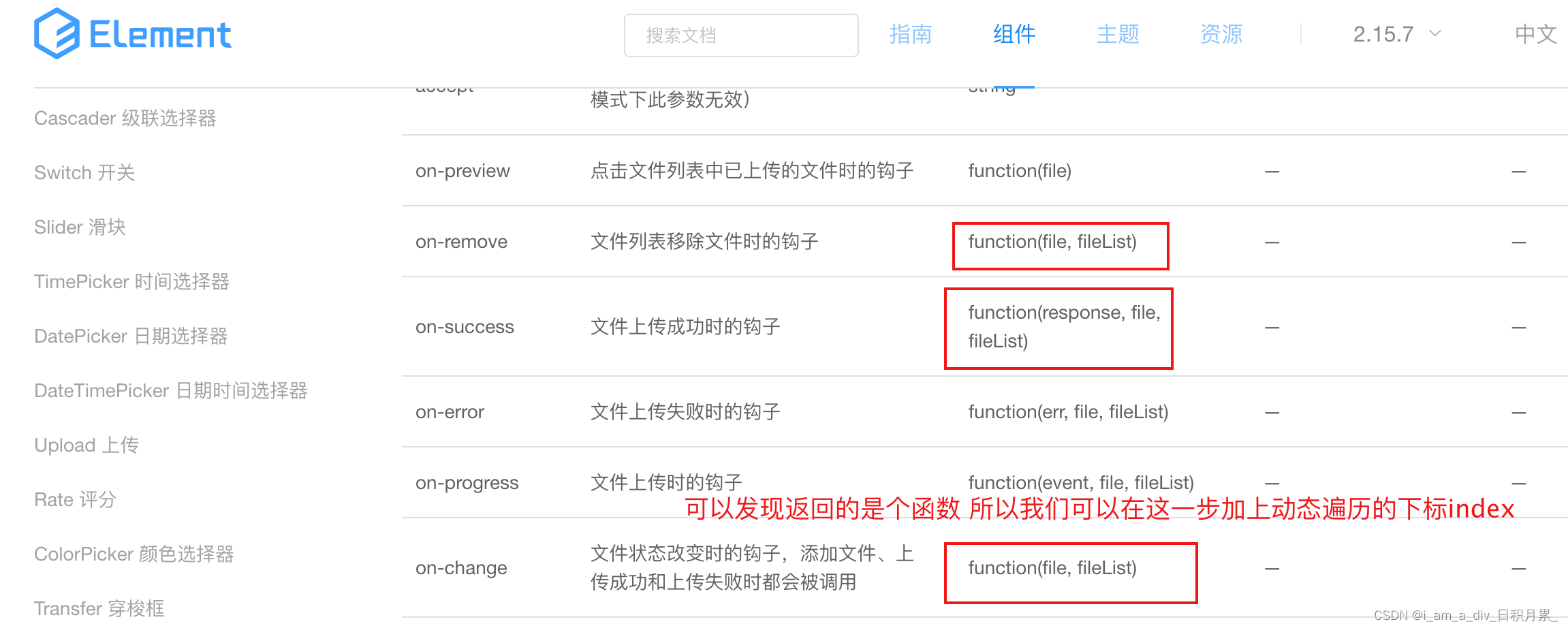
el-upload上传组件的动态添加;el-upload动态上传文件;el-upload区分文件是哪个组件上传的。
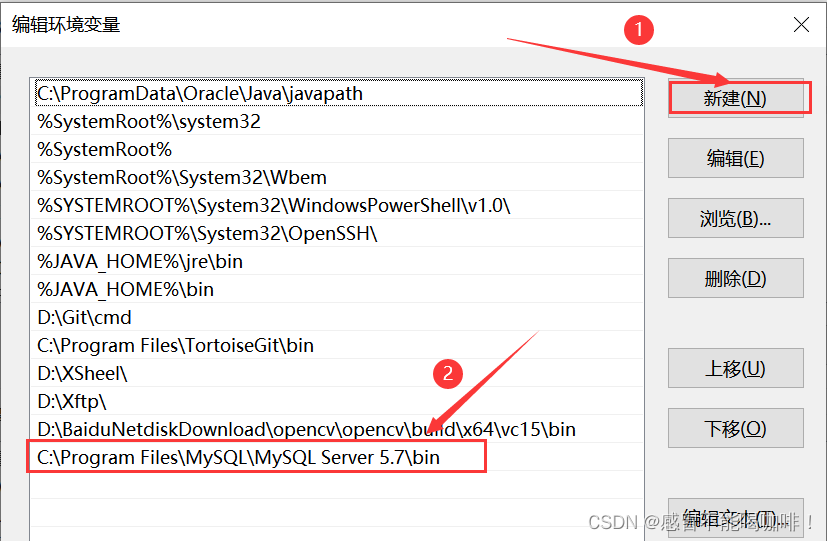
CMD command enters MySQL times service name or command error (fool teaching)

小试牛刀之NunJucks模板引擎
多个线程之间如何协同
随机推荐
关于自身的一些安排
我的创作纪念日
一张图深入的理解FP/FN/Precision/Recall
Visual Studio 插件之CodeMaid自动整理代码
一锅乱炖,npm、yarn cnpm常用命令合集
LeetCode 648(C#)
银行理财产品怎么买?需要办银行卡吗?
位运算介绍
R language ggplot2 visualization: use the ggdensity function of ggpubr package to visualize the packet density graph, and use stat_ overlay_ normal_ The density function superimposes the positive dist
2022.07.05
Browse the purpose of point setting
el-upload上传组件的动态添加;el-upload动态上传文件;el-upload区分文件是哪个组件上传的。
杰理之关于 TWS 交叉配对的配置【篇】
凌云出海记 | 赛盒&华为云:共助跨境电商行业可持续发展
开源OA开发平台:合同管理使用手册
9 原子操作类之18罗汉增强
IP tools
Implement secondary index with Gaussian redis
R language ggplot2 visualization: use the ggqqplot function of ggpubr package to visualize the QQ graph (Quantitative quantitative plot)
how to prove compiler‘s correctness