当前位置:网站首页>Automatic classification of defective photovoltaic module cells in electroluminescence images-論文閱讀筆記
Automatic classification of defective photovoltaic module cells in electroluminescence images-論文閱讀筆記
2022-07-07 19:42:00 【wyypersist】
Automatic classification of defective photovoltaic module cells inelectroluminescence images
電致發光圖像中缺陷光伏組件電池的自動分類
//2022.7.2上午8:57開始閱讀筆記
論文地址
論文貢獻
本文工作的貢獻包括三個部分。首先,我們提出了一個資源高效的框架,用於使用手工制作的特征和支持向量機分類器對缺陷太陽能電池進行監督分類,支持向量機分類器可用於廣泛的商品硬件,包括平板電腦和配備低功耗單板電腦的無人機。低計算要求使EL圖像的現場評估成為可能,類似於低分辨率紅外圖像的分析(Dotenco等人,2016)。其次,我們提出了一個使用卷積神經網絡的監督分類框架,該框架稍微更精確,但需要GPU進行有效的訓練和分類。特別是,我們展示了如何將不確定性納入這兩個框架中,以提高分類精度。第三,我們向社區提供了一個注釋數據集,該數據集由從高分辨率EL圖像中提取的2624個對齊太陽能電池組成,我們使用該數據集對所提出的方法進行了廣泛的評估和比較。
論文內容
1.介紹
太陽能組件通常由鋁框架和玻璃層壓保護,以免受雨、風和雪等環境影響。然而,這些保護措施並不總是能够防止光伏組件在安裝過程中掉落、樹枝掉落、冰雹或熱應力的影響所造成的機械損壞。此外,制造錯誤(如焊接故障或導線缺陷)也可能導致光伏組件損壞。缺陷反過來會降低太陽能組件的功率效率。因此,有必要監測太陽能組件的狀况,並更換或維修有缺陷的單元,以確保太陽能發電廠的最大效率。
即使對於訓練有素的專家來說,視覺識別有缺陷的單元也特別困難。除了玻璃上的明顯裂紋外,許多降低光伏組件效率的缺陷肉眼看不見。相反,可見的缺陷不一定會降低模塊效率。
為了精確確定模塊效率,必須直接測量模塊的電輸出。然而,此類測量需要與單個機組進行手動交互以進行診斷,因此它們不能很好地擴展到具有數千個光伏組件的大型太陽能發電廠。此外,此類測量僅捕捉到一個時間點,因此可能無法揭示某些類型的小裂紋,隨著時間的推移,這將成為一個問題(Kajari Schröder等人,2012)。
紅外(IR)成像是一種非破壞性、非接觸式的替代方法,用於評估太陽能組件的質量。損壞的太陽能組件可以通過部分或完全與電路斷開的太陽能電池輕松識別。因此,太陽能不再轉化為電能,從而加熱太陽能電池。然後,發射的紅外輻射可以通過紅外攝像機成像。然而,紅外攝像機的分辨率相對較低,因此無法檢測到尚未影響太陽能組件光電轉換效率的微小缺陷,如微裂紋。
電致發光(EL)成像(Fuyuki等人,2005;Fuyuki和Kitiyanan,2009)是另一種成熟的光伏組件故障分析非破壞性技術,能够以更高的分辨率成像太陽能組件。在EL圖像中,缺陷細胞看起來更暗,因為斷開的部分不會輻射。為了獲得電致發光圖像,向光伏組件施加電流,從而在1150 nm的波長下誘導電致發光。發射可以通過矽電荷耦合器件(CCD)傳感器成像。高空間圖像分辨率能够檢測微裂紋(Breitenstein等人,2011),EL成像也不會因橫向熱傳播而變得模糊。然而,EL圖像的視覺檢查不僅耗時且昂貴,而且還需要經過培訓的專家。在這項工作中,我們提出了一種自動分類EL圖像中缺陷的方法,從而消除了這一約束。
一般來說,太陽能組件中的缺陷可分為兩類(Fuyuki和Kitiyanan,2009):(1)由於晶界和比特錯等材料特性而產生的固有缺陷,以及(2)工藝引起的外部缺陷,如微裂紋和斷裂,隨著時間的推移,這些缺陷會降低組件的整體效率。
圖1顯示了具有不同類型缺陷的示例EL圖像。圖1(a)和(b)顯示了生產過程中的一般材料缺陷,例如指針中斷,除非由焊點處的高應變引起,否則不一定會縮短受影響太陽能電池板的壽命(Köntges等人,2014)。具體而言,指針中斷引起的效率下降是其大小、比特置和中斷次數之間的複雜交互作用(De Rose等人,2012;Köntges等人,2014)。圖1(c)至(e)顯示了微裂紋、電池互連的退化,以及具有眾所周知會降低模塊效率的電分離或退化部分的電池。特別是微裂紋的檢測需要具有高空間分辨率的攝像機。

對於監測期間的缺陷檢測,可以設定不同的目標。突出顯示太陽能模塊內缺陷的准確比特置,可以高精度監測受影響的區域。然而,對於整個光伏組件的質量評估而言,太陽能電池內的准確缺陷比特置並不重要。對於這項任務,指示細胞缺陷的總體可能性更為重要。這可以快速識別缺陷區域,並可能補充光伏組件內未來效率損失的預測。在這項工作中,我們提出了兩個自動解决第二個任務的分類管道,即確定可能導致效率損失的每個單元缺陷的可能性。
本文研究的分類方法是支持向量機和神經網絡分類器。
支持向量機(SVM)根據從太陽能電池EL圖像中提取的各種特征進行訓練。
卷積神經網絡(CNN)直接輸入太陽能電池的圖像像素和相應的標簽。
支持向量機方法在訓練和推理過程中計算效率特別高。這允許在廣泛的商品硬件上操作該方法,例如平板電腦或無人機,其使用取决於各自的應用場景。相反,CNN的預測精度通常更高,而訓練和推理更耗費時間,通常需要GPU在可接受的較短時間內運行。然而,特別是對於航空圖像,可能會出現其他問題,需要解决。Kang和Cha(2018)强調了在將我們的方法應用於制造環境之外之前需要解决的幾個挑戰。
1.1 貢獻
本文工作的貢獻包括三個部分。首先,我們提出了一個資源高效的框架,用於使用手工制作的特征和支持向量機分類器對缺陷太陽能電池進行監督分類,支持向量機分類器可用於廣泛的商品硬件,包括平板電腦和配備低功耗單板電腦的無人機。低計算要求使EL圖像的現場評估成為可能,類似於低分辨率紅外圖像的分析(Dotenco等人,2016)。其次,我們提出了一個使用卷積神經網絡的監督分類框架,該框架稍微更精確,但需要GPU進行有效的訓練和分類。特別是,我們展示了如何將不確定性納入這兩個框架中,以提高分類精度。第三,我們向社區提供了一個注釋數據集,該數據集由從高分辨率EL圖像中提取的2624個對齊太陽能電池組成,我們使用該數據集對所提出的方法進行了廣泛的評估和比較。
圖2顯示了使用所提出的卷積神經網絡對太陽能電池板的評估結果。EL圖像中的每個太陽能電池都是由相應單元中缺陷的可能性覆蓋。

1.2 概述
這項工作的其餘部分組織如下。第2節回顧了相關工作。第3節介紹了兩種擬議的分類方法。在第4節中,我們評估和比較了這些方法,並討論了結果。這項工作在第5節中結束。
2.相關工作
通過EL成像對太陽能組件進行視覺檢測是一個活躍的研究課題。然而,大多數相關工作的重點是檢測特定的內在或外在缺陷,而不是預測最終會降低太陽能組件功率效率的缺陷。太陽能電池EL圖像中錶面异常的檢測與結構健康監測有關。然而,需要注意的是,太陽能電池中的某些缺陷僅特定於光伏組件的EL成像。例如,完全斷開連接的太陽能電池僅顯示為暗圖像區域(類似於圖1(d)),因此在結構缺陷方面沒有可比的等效物。此外,太陽能晶片中的錶面不規則性(例如手指中斷)很容易與電池裂紋混淆,即使它們不會顯著影響功率損耗。
在對太陽能組件進行目視檢查的背景下,Tsai等人(2012)使用傅立葉圖像重建來檢測多晶光伏組件EL圖像中的缺陷太陽能電池。目標外部缺陷是(小)裂紋、斷裂和手指中斷。傅立葉圖像重建通過將與線和條形偽影相關的高頻系數設置為零來消除可能的缺陷。然後將光譜錶示轉換回空間域。然後可以將缺陷識別為原始圖像和高通濾波圖像之間的强度差。由於形狀假設,該方法難以檢測形狀更複雜的缺陷。
Tsai等人(2013)還介紹了一種監督學習方法,用於使用獨立分量分析(ICA)基礎圖像識別缺陷。利用獨立分量分析(ICA),利用無缺陷太陽能電池子圖像來尋找一組獨立的基圖像。該方法在300個太陽能電池子圖像的相對較小的訓練數據集上實現了93.40%的高精度。然而,手指中斷等材料缺陷與電池裂紋同等對待。因此,該策略僅適用於檢測太陽能電池錶面的每個异常,而不適用於預測未來的能量損失。
Anwar和Abdullah(2014)開發了一種多晶太陽能電池微裂紋檢測算法。他們使用各向异性擴散濾波,然後進行形狀分析,以定比特太陽能電池中的缺陷。雖然該方法在檢測微裂紋方面錶現良好,但它不考慮其他缺陷類型,例如在EL圖像中顯示為完全黑暗的完全斷開的細胞。
Tseng等人(2015)提出了一種自動檢測單晶太陽能電池中手指中斷的方法。該方法采用候選區域特征的二進制聚類來檢測缺陷。然而,手指中斷不一定能為預測未來功率損耗提供合適的線索。
深度學習的成功導致了用於光學檢測的傳統模式識別管道的逐漸替代。然而,據我們所知,尚未提出用於EL圖像的CNN架構,但僅適用於其他模式或應用。最密切相關的是Mehta等人(2018年)的工作,他們提出了一種從太陽能組件的RGB圖像預測功率損失、定比特和污垢類型的系統。他們的方法不需要手動定比特標簽,而是在圖像上操作,並將相應的功率損耗作為輸入。Masci等人(2012)提出了一種端到端maxpooling CNN,用於對鋼缺陷進行分類。將其網絡性能與使用支持向量機訓練的多個手工制作的特征描述符進行比較。盡管他們的數據集僅包含2281個訓練圖像和646個測試圖像,但CNN架構對鋼缺陷的分類精度至少是支持向量機的兩倍。張等人(2016)提出了一種用於檢測道路裂縫的CNN架構。為了訓練CNN,使用了大約45000個手動標記的圖像塊。他們錶明,CNN的性能大大優於手工制作的特征然後通過支持向量機和boosting的組合進行分類。. Cha等人(2017年)在各種環境和照明條件下拍攝的大範圍圖像中,使用非常類似的方法檢測混凝土裂縫。Kang和Cha(2018)利用深度學習對航空圖像進行結構健康監測。Cha等人(2018年)還研究了基於快速R-CNN框架的基於現代學習的分割方法的缺陷定比特,該框架可以實時執行。Lee等人(2019)也使用語義分割來檢測混凝土中的裂縫。
在醫學方面,Esteva等人(2017)利用深度神經網絡對不同類型的皮膚癌進行分類。他們在一個由129450張臨床圖像和2032種不同疾病組成的大數據集上對CNN進行了端到端的訓練,使其能够實現高度的准確性。
3.方法
我們將每個模塊細分為其太陽能電池,並單獨分析每個電池,最終推斷缺陷的可能性。這將分析分解為最小有意義的單元,即光伏組件的機械設計將電池單元串聯在一起。此外,分解大大增加了用於訓練的可用數據樣本的數量。對於太陽能電池的分割,我們使用了最近開發的方法(Deitsch等人,2018),該方法使每個電池都處於正常狀態,沒有透視和透鏡畸變。
除非另有說明,否則所提出的方法適用於分辨率為×300像素的太陽能電池的大規模EL圖像。該圖像分辨率源自光伏組件原始EL圖像中對應於單個太陽能電池的圖像區域的中值尺寸。太陽能電池圖像直接用作管道輸入。野外太陽能電池的圖像分辨率通常會偏離所需的分辨率,因此必須進行相應調整。CNN架構設置了最小圖像分辨率,該分辨率通常等於CNN的接收場(例如,原始VGG-19架構使用×224 224)。如果分辨率低於此最小分辨率,則必須放大圖像。為了獲得更高的分辨率,可以以跨窗口方式應用網絡,然後將輸出匯集在一起(通常使用平均或最大匯集)。我們采用了另一種方法,在這種方法中,CNN架構內在地編碼了這個過程。對於支持向量機管道,分辨率要求不那麼嚴格。鑒於局部特征具有尺度不變性,分類太陽能電池的圖像分辨率不需要調整,並且可能因圖像而异。
3.1. 使用支持向量機進行分類
使用支持向量機進行分類的一般方法(Cortes和Vapnik,1995)如下。首先,從分割光伏電池的圖像中提取局部描述符。特征通常在顯著點(也稱為關鍵點)或密集像素網格中提取。對於訓練分類器和後續預測,需要從局部描述符集計算全局錶示,通常稱為編碼。最後,將太陽能電池的全局描述符分為缺陷描述符和功能描述符。圖3顯示了分類管道,包括掩蔽、關鍵點檢測、特征描述、編碼和分類。我們在以下小節中描述這些步驟。

3.1.1. 掩蔽
我們假設太陽能電池是從光伏組件中分割出來的,例如,使用我們在早期工作中提出的自動算法(Deitsch等人,2018)。然後,二進制掩碼允許將每個單元格的前景與背景分離。單元背景包括通常不屬於矽片的圖像區域,例如母線和單元間邊界。該掩碼可用於嚴格限制特征提取到單元內部。在評估中,我們研究了掩蔽的有用性,並發現其影響很小,即在少數特征/分類器組合中僅略微提高了性能。
3.1.2. 特征提取
為了訓練支持向量機,首先提取特征描述符。這些局部特征的比特置是使用兩種主要的采樣策略確定的:(1)關鍵點檢測和(2)密集采樣。這些策略如圖4所示。這兩種策略都產生了不同的功能集,比其他策略更適合特定類型的太陽能晶片。密集采樣忽略圖像內容,而是使用固定的特征點配置。另一方面,關鍵點檢測器依賴於圖像中的紋理,因此關鍵點的數量與高頻元素的數量成比例,例如邊緣和角落(如圖4(c)和(d)所示)。關鍵點檢測器通常在尺度空間中工作,允許在不同的尺度水平和不同的方向上進行特征檢測。圖4(d)顯示了KAZE檢測到的關鍵點。在這裏,每個關鍵點都有不同的比例(由相應圓的半徑顯示),也有特定的方向,例如從中心到圓邊界繪制的線。捕捉比例和旋轉的關鍵點對圖像分辨率和平面內旋轉的變化是不變的,這使得它們非常穩健。

密集采樣通過將其與由×n個電池組成的網格疊加來細分×300像素的光伏電池。每個網格單元的中心指定了隨後提取特征描述符的比特置。特征比特置的數量僅取决於網格大小。如果計算資源非常有限,或者目的是僅識別單晶光伏組件中的缺陷,則密集采樣非常有用。
我們采用了文獻中不同流行的關鍵點檢測器和特征提取器的組合,如錶1所列,並概述如下。

有幾種算法結合了關鍵點檢測和特征描述。這些方法中最流行的可能是尺度不變的特征變換(SIFT)(Lowe,1999),它在多個尺度上檢測和描述特征。SIFT對旋轉、平移和縮放不變性,並對不同的照明條件具有部分彈性。加速魯棒特征(SURF)(Bay等人,2008)是SIFT的一種更快變體,還包括一個關鍵點檢測器和一個局部特征描述符。然而,SURF的檢測器部分對仿射變換不是不變的。在初始實驗中,我們無法成功使用SIFT和SURF的關鍵點檢測器,因為關鍵點檢測器有時無法檢測相對均勻的單晶細胞圖像中的特征,因此我們僅使用描述符部分.
KAZE(Alcantarilla等人,2012)是一種多尺度特征檢測器和描述符。關鍵點檢測算法與SIFT非常相似,只是SIFT使用的線性高斯尺度空間被非線性擴散濾波所取代。然而,對於特征描述,KAZE使用SURF描述符。
我們還研究了自適應和通用加速段測試(AGAST)(Mair等人,2010)作為一種沒有描述符的專用關鍵點檢測器。它基於在一組角點特征上訓練的隨機森林分類器,這些特征被稱為來自加速分段測試(FAST)的特征(Rosten和Drummond,20052006)。
在專用描述符中,視覺文字金字塔直方圖(PHOW)(Bosch等人,2007)是SIFT的擴展,它在均勻分布的網格上密集計算SIFT描述符。我們使用VLFEAT的實現變體(Vedaldi和Fulkerson,2008)。類似地,定向梯度直方圖(HOG)(Dalal和Triggs,2005)是在一組均勻的圖像塊上密集計算的基於梯度的特征描述符。最後,我們還使用了視覺幾何組(VGG)描述符,使用有效的優化方法進行端到端訓練(Simonyan等人,2014)。在我們的實現中,我們使用了120維實值描述符變量。
我們從這個選擇中省略了二進制描述符。盡管二進制特征描述符通常計算速度非常快,但它們的性能通常並不優於實值描述符(Heinly等人,2012)。
3.1.3 探測器和提取器的組合
為了確定最强大的特征檢測器\提取器組合,我們評估了所有特征檢測器和特征提取器組合,只有少數例外。
在大多數情况下,我們既沒有調整關鍵點檢測器的參數,也沒有調整特征提取器的參數,而是使用OPENCV(ITSEZ,2017)自3.3.1版起的默認值。一個值得注意的例外是AGAST,我們將檢測閾值降低到5,以便能够檢測單晶光伏組件中的關鍵點。對於SIFT和SURF,類似的調整並不成功,這就是為什麼我們只使用它們的描述符。HOG需要重疊圖像區域的網格,這與關鍵點檢測器不兼容。相反,我們將300×300像素的細胞圖像降采樣到256 X 256像素(最接近2的幂)進行特征提取。由於實現特定的限制,省略了HOG的屏蔽。考慮到這些例外情况,我們總體評估了12種特征組合。
3.1.4 編碼
計算出的特征被編碼到全局特征描述符中。編碼的目的是從多個局部描述符中形成單個固定長度的全局描述符。編碼通常錶示為從背景模型中提取統計信息的直方圖。為此,我們采用了局部聚集描述符向量(VLAD)(Jégou等人,2012),這提供了一種緊凑的最先進的錶示方法(Peng等人,2015)。VLAD編碼有時也用於分類、識別和檢索任務中基於深度學習的特征(Gong等人,2014;Ng等人,2015;Paulin等人,2016;Christlein等人,2017)。
VLAD字典是通過對訓練集中的隨機特征描述符子集進行k均值聚類而創建的。出於性能原因,我們使用k-means的快速小批量變體(Sculley,2010)。簇質心µk對應於字典的定比特點。然後,將一階統計量聚合為從太陽能電池圖像中提取的所有描述符

的殘差之和。殘差是根據字典中最近的錨點µk計算的為

其中:

是集群成員身份的指示函數,即為:

這錶明x是否是µk的最近鄰。最終VLAD錶示

對應於將所有剩餘項(1)串聯到Kd維向量中:

為了使VLAD描述符具有魯棒性,需要幾個歸一化步驟。功率歸一化解决了某些局部描述符比其他描述符更頻繁出現的問題。這裏,全局描述符

的每個元素被歸一化為:

其中,我們從文獻中選擇

作為典型值。幂歸一化後,向量被歸一化,使其-範數等於1。
類似地,如果至少兩個描述符經常出現在一起,則可能會出現共現次數過多的情况。Jégou和Ondřej(2012)錶明,主成分分析(PCA)白化有效地消除了此類共現,並進一步消除了數據的相關性。
為了增强碼本D對概率k均值聚類的潜在次優解的魯棒性,我們使用不同的隨機種子從不同的訓練子集計算了五個VLAD錶示。然後,通過PCA(Kessy等人,2016),對VLAD編碼的串聯

進行聯合去相關和白化。變換後的錶示再次歸一化,使其-範數等於1,結果最終傳遞給支持向量機分類器。
3.1.5. 支持向量機訓練
我們用線性和徑向基函數核訓練支持向量機。對於線性核,我們使用LIBLINEAR(Fan等人,2008),它針對線性分類任務和大型數據集進行了優化。對於非線性RBF核,我們使用LIBSVM(Chang和Lin,2011)。
支持向量機超參數是通過使用網格搜索在訓練集的內部五倍交叉驗證中評估平均F1分數(van Rijsbergen,1979)來確定的。對於線性支持向量機,我們對平方鉸鏈損失采用2懲罰。懲罰參數C是從一組10的幂中選擇的,即

。對於RBF支持向量機,懲罰參數C由一個稍小的集合確定。核系數的搜索空間被約束為,其中S錶示訓練樣本數。
3.2 使用深度卷積神經網絡的回歸
我們考慮了幾種培訓CNN的策略。鑒於我們掌握的數據量有限,通過遷移學習取得了最佳結果。我們使用了VGG-19網絡架構(Simonyan和Zisserman,2015),最初使用128萬張圖像和1000個類在IMAGENET數據集(Deng等人,2009)上訓練。然後,我們使用我們的數據集優化了網絡。
我們用全局平均池(GAP)替換VGG-19的兩個完全連接層(Lin等人,2013),並分別用4096和2048個神經元替換兩個完全連接層(見圖5)。間隙層用於使VGG-19網絡輸入張量(×224 224 3)與我們的太陽能電池圖像樣本的分辨率(×300 3)兼容,以避免樣本的額外下采樣。輸出層由單個神經元組成,輸出細胞的缺陷概率。通過最小化均方誤差(MSE)損失函數對CNN進行優化。因此,我們本質上訓練了深度回歸網絡,該網絡允許我們僅使用兩種缺陷可能性類別(功能性和缺陷性)來預測(連續)缺陷概率。通過將預測的連續概率四舍五入到四個原始類的最近鄰,我們可以直接將CNN决策與原始地面真值標簽進行比較,而無需對其進行二值化。

數據增强用於生成額外的、輕微擾動的訓練樣本。然而,增强可變性保持適度,因為分割的細胞沿平移軸僅變化幾個像素,沿旋轉軸僅變化幾個度。訓練樣本最多按原始分辨率的2%縮放。旋轉範圍限制為±°3。平移限制為單元格尺寸的±2%。我們還使用沿垂直和水平軸的隨機翻轉。由於母線可以垂直和水平布置,我們還包括精確旋轉90°的訓練樣本。旋轉樣本以與上述相同的方式增加。
我們在數據上微調預訓練的IMAGENET模型,以使CNN適應新任務,類似於Girshick等人(2014)。然而,我們是按照兩個階段做的。首先,我們只訓練具有隨機初始化權重的完全連接層,同時保持卷積塊的權重固定。在這裏,我們使用ADAM優化器(Kingma和Ba,2014),學習率為10^-3,指數衰减率=0.91和=0.9992,正則化值=10^-8。在第二步中,我們細化所有層的權重。在這個階段,我們使用隨機梯度下降(SGD)優化器,學習率為5·104,動量為0.9。我們觀察到,與單個細化步驟相比,通過隨後增加超參數的數量在幾個階段微調CNN略微提高了結果模型的泛化能力。
在這兩個階段中,我們在兩個NVIDIA GeForce GTX 1080上以16個樣本的小批量處理1968個訓練樣本的增强版本,並運行最多100個epoch的訓練過程。這總計為196800個原始1968訓練樣本的增强變體,用於優化網絡。為了實現深度回歸網絡,我們在後端使用KERAS版本2.0(Chollet等人,2015)和TENSORFLOW版本1.4(Abadi等人,2015)。
4.評價
對於定量評估,我們首先評估在網格上密集提取的不同特征描述符。然後,我們將最佳配置與在自動檢測的關鍵點提取的特征描述符進行比較,以確定支持向量機分類管道的最佳性能變化。最後,我們將後者與提出的深度CNN進行比較,並可視化CNN的內部特征映射。
4.1 數據集
我們提出了一個從單晶和多晶光伏組件的高分辨率EL圖像中提取的太陽能電池公共數據集1(Buerhop-Lutz等人,2018)。該數據集由2624個太陽能電池圖像組成,分辨率為×300像素,最初從44個不同的光伏組件中提取,其中18個組件為單晶類型,26個為多晶類型。
用於提取單個太陽能電池樣品的光伏組件的圖像是在制造環境中拍攝的。這種受控條件能够在一定程度上控制成像面板的質量,並允許最小化對圖像質量的負面影響,例如過度曝光。由於背景輻射可以主導EL輻射,因此還需要控制條件。鑒於光伏組件在暗室中進行采集時只發出光,因此可以確保圖像均勻照明。這與一般結構健康監測中的圖像采集相反,後者引入了額外的自由度,圖像可能會受到陰影或聚光燈的影響(Cha等人,2017年)。然而,電致發光成像中的一個重要問題是,由於透鏡聚焦不當,電致發光圖像模糊(即失焦),有時難以實現。因此,我們確保在提議的數據集中包含此類圖像(例如,參見圖1)。A
太陽能電池錶現出常見於單晶和多晶太陽能組件中的固有和外在缺陷。特別是,數據集包括微裂紋和具有電分離和劣化零件的電池、短路電池、開路互連和焊接故障。眾所周知,這些電池缺陷會對太陽能電池組件的效率、可靠性和耐久性產生負面影響。由於此類缺陷引起的功率損失通常可以忽略不計,因此不包括手指中斷。
功率衰减測量無法提供ground-truth。相反,提取的細胞以隨機順序呈現給熟悉EL圖像中不同缺陷的複雜細節的公認專家。Köntges等人(2014)總結了此類故障的標准。在故障分類中,專家特別關注已知功率損失超過初始功率輸出3%的缺陷。專家回答了問題(2)細胞功能是否正常或有缺陷?(2) 你對自己的評估有信心嗎?由自信的評分員對功能和缺陷細胞的評估直接用作標簽。功能性和缺陷細胞的非自信評估均標記為缺陷。為了反映評分員的不確定性,將較低的權重分配給這些評估,即功能細胞的非自信評估權重為33%,缺陷細胞的非自信評估權重為67%。錶2總結了這一點,左側是評分員評估,右側是相關的分類標簽和權重。錶3顯示了ground-truth太陽能電池標簽的分布,按源光伏組件的類型分隔。


我們使用25%的標記細胞(656個細胞)進行測試,其餘75%(1968個細胞)進行訓練。分層抽樣用於隨機分割樣本,同時保留樣本在訓練集和測試集中不同類別內的分布。為了進一步平衡訓練集,我們使用來自King和Zeng(2001)的反比啟發式加權類:

其中S是訓練樣本的總數,nj是功能(=j 0)或缺陷(=j 1)樣本的數量。
4.2 密集采樣
在本實驗中,我們評估了用於細分單個×300像素細胞圖像的不同網格大小。每個單元的網格點數量在5×5到75 ×75點之間變化。在每個網格點,計算SIFT、SURF和VGG描述符。剩下的兩個描述符PHOW和HOG在本實驗中被省略,因為它們不允許任意指定描述符計算的比特置。注意,在75×75的點網格上,兩個網格點之間的距離只有4個像素,這導致相鄰描述符之間存在顯著重疊。因此,進一步提高網格分辨率並不能顯著改善分類結果。
本實驗的目標是找到網格大小和分類器的最佳組合。我們訓練了線性支持向量機和帶有徑向基核的支持向量機。對於每個分類器,我們還研究了兩個附加選項,即添加樣本權重w(參見錶2)或掩蓋背景區域(參見第3.1.1節)是否可以改進分類器。
使用F1分數衡量性能,F1分數是精度和召回率的調和平均值。圖6顯示了每個類別F1分數的平均F1分數。從左到右,這些分數顯示為SURF描述符(圖6(a))、SIFT描述符(圖6(b))和VGG描述符(圖6(c))。這裏,VGG描述符使用帶加權和掩蔽的線性支持向量機在大小為×65 65的網格上獲得最高分數。SIFT是第二個性能最好的描述符,在使用帶權重的線性支持向量機的×60 60網格上具有最佳性能,但沒有掩蔽。SURF得分最低,使用帶權重的RBF支持向量機在×70-70網格處出現峰值,但沒有掩蔽。結果錶明,網格點越多,結果越好。SURF的分類精度增長緩慢,飽和率約為70%。SIFT和VGG從更密集的網格中受益更多。在大多數情况下,權重w的使用會導致更高的分數,因為分類器可以更强地依賴於專家貼標員更自信的樣本。掩蔽還提高了VGG特征的F1分數。然而,與配置的整體性能變化相比,幾乎2%的改善幅度很小。可以說,鑒於特征點的高密度和特征提取器評估的圖像區域之間的重疊程度,細胞結構對於區分不同類型的細胞缺陷並不重要。

4.3. 密集采樣與關鍵點檢測
本實驗旨在比較基於密集網格的特征與基於關鍵點的特征的分類性能。為此,將先前實驗中每個描述符的最佳性能基於網格的分類器與關鍵點檢測器和特征描述符的組合進行比較。
圖7顯示了評估的單晶電池、多晶電池以及兩者的檢測器和提取器組合。大多數檢測器/提取器組合由正斜杠(檢測器/描述符)指定。沒有正斜杠的條目,即KAZE、HOG和PHOW,錶示已經包括檢測器和描述符的特征。在稠密網格上錶現最好的三種方法分別錶示為稠密SIFT×60、稠密SURF×70和稠密VGG×65。除非另有規定,否則使用樣本加權、無掩蔽和線性支持向量機對特征進行訓練。

使用ROC曲線顯示了性能,該曲線錶明了二進制分類器在各種誤報率下的性能(Fawcett,2006)。此外,曲線圖顯示了前4個特征的AUC分數,最高AUC以粗體强調。在這三種情况下,KAZE \/VGG優於其他特征組合,所有模塊的AUC為88.51%,其次是KAZE \/SIFT,AUC為87.22%。作為例外,就AUC而言,多晶太陽能電池的第二個最佳特征組合是PHOW。灰色虛線錶示隨機分類器的基線。總的來說,使用關鍵點比密集采樣具有更好的性能。
4.4. 支持向量機與使用深度回歸網絡的遷移學習
圖8與CNN分類器相比,顯示了最强支持向量機變體KAZE \/VGG的性能。圖8(a)左側的ROC曲線包含單晶光伏組件的結果。圖8(b)提供了多晶光伏組件的分類性能。最後,兩種模型的總體分類性能如右圖8(c)所示。

值得注意的是,支持向量機和神經網絡對於單晶光伏組件的分類性能非常相似。CNN的平均性能僅略優於SVM。當假陽性率低於1%左右時,CNN獲得了更高的真陽性率。然而,在大約1%到10%的誤報率範圍內,支持向量機錶現更好。這錶明KAZE \/VGG能够捕捉均勻錶面上的异常幾乎與直接在圖像像素上訓練的CNN一樣精確。
對於多晶光伏組件,在AUC方面,CNN能够比SVM更准確地預測缺陷太陽能電池幾乎11%。由於太陽能電池中的紋理種類繁多,這顯然也是一個更為困難的測試。
總的來說,CNN優於SVM。然而,兩種分類器的性能總的差异僅為6%左右。因此,支持向量機分類器也可用於在無法使用CNN絡專用硬件的情况下快速、現場評估光伏組件。
4.5. 每個缺陷類別的模型性能
在這裏,我們根據混淆矩陣詳細報告了擬議模型在單個太陽能電池類別(即缺陷和功能)方面的性能。二維混淆矩陣存儲正確識別的單元格比例(真假性和真陽性)在其主對角線上的每個類別中。二次對角線提供了相對於其他類別錯誤識別的太陽能電池(假陰性和假陽性)的比例。
圖9顯示了擬議模型的混淆矩陣。給出了每種太陽能晶片及其組合的混淆矩陣。混淆矩陣的縱軸指定預期(即地面真實)標簽,而水平軸指定相應模型預測的標簽。在這裏,CNN的預測閾值為50%,以生產兩類功能(0%)和缺陷(100%)太陽能電池。
關於單晶光伏組件,圖9(a)和(d)中的混淆矩陣强調了這兩個模型提供了可比較的分類結果。然而,與CNN相比,線性支持向量機能够正確識別更多的缺陷細胞,但代價是功能細胞被識別為缺陷(假陰性)。為此,線性支持向量機在將缺陷太陽能電池識別為完整(誤報)時也會產生較小的錯誤。
在圖9(b)和(e)給出的多晶情况下,CNN在每一類中都明顯優於線性支持向量機。這也導致CNN在這兩種情况下的整體性能更好,如圖9(c)和(f)所示。

圖9注釋:提出的分類模型的混淆矩陣。每行混淆矩陣存儲了預期缺陷可能性類別中實例的相對頻率。另一方面,這些列包含分類模型所做預測實例的相對頻率。理想情况下,只有混淆矩陣的對角線將包含非零項,這對應於基本真值和分類模型之間在所有類別中的完美一致。CNN通常比基於KAZE/VGG特征訓練的支持向量機產生更少的預測誤差。
4.6. 訓練數據集大小對模型性能的影響
為了訓練線性支持向量機和CNN,使用了一個相對較小的獨特太陽能電池圖像數據集。考慮到典型的光伏組件生產線每天的產量為1500個組件,包含約90000個太陽能電池,預計模型將會大大收益於額外的訓練數據。為了檢驗如果使用更多的訓練樣本,所提出的模型如何改進,我們評估了它們在原始訓練樣本子集上的性能,因為沒有額外的訓練樣本可用。
為了推斷性能趨勢,我們在原始訓練樣本的三個不同大小的子集上評估了模型。我們使用了25%、50%和75%的原始訓練樣本。為了避免獲得的指標中存在偏差,我們不僅對子集進行隨機采樣,而且對每個子集進行50次采樣,以獲得用於訓練模型的樣本。此外,我們還使用分層抽樣來保留原始訓練樣本集中標簽的分布。為了評估性能,我們使用原始測試樣本,並提供三個指標的結果:F1分數、ROC AUC和准確性。
圖10顯示了用於訓練擬議模型的三個不同大小的訓練樣本子集的所有樣本上的評估分數分布。三個子集中每一個子集所有50分的分布總結在箱線圖中。結果清楚地錶明擬議模型的性能相對於視覺任務中通常觀察到的訓練樣本數量大致呈對數增長(Sun等人,2017)。

4.7. CNN特征空間分析
在這裏,我們使用t-分布隨機鄰域嵌入(t-SNE)分析CNN學習的特征(van der Maaten和Hinton,2008),這是一種用於降維的流形學習技術。目的是檢驗不同太陽能電池組的分離標准。為此,我們使用t-SNE的巴恩斯小屋變體(van der Maaten,2014),其速度大大快於標准實現。為了計算嵌入,我們將tSNE的困惑參數固定為35。由於我們的測試數據集較小,我們避免了在預處理步驟中使用PCA對特征進行初始降維,而是使用嵌入的隨機初始化。
所有656個測試圖像的結果錶示如圖11所示。每個點對應於從2048維CNN最後一層投影到二維的特征向量。從單晶和多晶模塊中提取的投影特征向量分別用紅色和藍色編碼。缺陷概率由飽和編碼。二維錶示保留了高維特征空間的結構,並錶明在大多數情况下,相似的缺陷概率在特征空間中是共存的。這使得CNN分類器能够區分缺陷太陽能電池和功能太陽能電池的EL圖像。

一個重要的觀察結果是,這類絕對有缺陷(100%)的電池形成了一個單一的細長簇(左下角),其中包括電池,而與源光伏組件類型無關。與此相反,功能性細胞(0%)被分成不同的簇其中,這取决於源光伏組件的類型。電池的整體外觀(即焊接接頭的數量、紋理等)在單晶簇(右側)中還會產生幾個分支。這些分支包括按單元內母線焊接接頭數量分組的樣本。這裏,由於矽片的均勻(即無紋理)錶面,分支比功能性多晶矽單元簇(右上角)中的分離更明顯。
可能有缺陷(33%)和可能有缺陷(67%)細胞的聚類是混合的。這些樣本之間的高度混淆源於與我們數據集中剩下的兩類高置信度樣本的大小相比,相應類別的大小相對較小(見錶3)。此外,這兩個類別的樣本由於處於可清楚區分的缺陷和非缺陷的邊界,可能會刺激模糊决策。
4.8. 定性結果
圖12為單晶和多晶太陽能電池的選擇提供了定性結果,並由擬議的CNN推斷出相應的缺陷可能性。為了便於與地面真值標簽進行比較,通過將概率四舍五入到最近的類別,將CNN缺陷概率量化為與原始標簽對應的四個類別。該選擇包含正確分類和錯誤分類的太陽能電池,分別在預測概率和地面真值標簽之間具有最小和最大的平方距離。
為了突出太陽能電池圖像中的類特定區分區域,可以使用類激活圖(CAM)(Zhou等人,2016;Selvaraju等人,2017;Chattopadhay等人,2018)。然而,由於其分辨率較粗,CAM不直接適用於缺陷區域的精確分割。CAM仍然可以提供線索,解釋卷積網絡推斷特定缺陷概率的原因。為此,圖12中的太陽能電池由從改進VGG-19網絡的最後卷積塊(×18 18 512)提取的CAM額外覆蓋,並使用Chattopadhay等人(2018)的方法將其放大到原始分辨率300 X 300的太陽能電池圖像。

有趣的是,即使CNN錯誤地將有缺陷的太陽能電池分類為功能性的(參見圖12(b)中的最後一列),CAM仍然可以高亮顯示潜在缺陷的圖像區域。因此,CAM可以補充全自動評估過程,並在視覺檢查期間的複雜情况下提供决策支持。從凸輪檢查中可以看到的一個特殊問題是,手指中斷並不總是能從實際缺陷中清楚地辨別出來。然而,這可以通過包含相應樣本來訓練CNN來實現。

在圖13中,我們顯示了CNN對完整多晶太陽能組件的預測。地面實况標簽在每個太陽能電池的右上角以紅色陰影圓圈錶示。同樣,太陽能細胞被CAM覆蓋,並通過網絡預測進行加權,以减少視覺混亂的數量。通過檢查CAM,可以觀察到CNN關注的是太陽能電池內的特殊缺陷,這些缺陷比同一電池中更明顯的缺陷更難識別,例如退化或電絕緣電池部件(顯示為深色區域)。
4.9 運行時評估
在這裏,我們評估了支持向量機管道的每一步和CNN在訓練和測試期間花費的時間。運行時在運行Intel i7-3770K CPU的系統上進行評估,CPU時鐘為3.50GHz,內存為32GB。結果如圖14所示。

不出所料,兩種模型的訓練都花費了大部分時間。雖然訓練支持向量機總共需要30分鐘左右。細化CNN的速度幾乎是原來的10倍,需要5小時左右。但是,使用CNN的推理速度要比支持向量機管道快得多,在支持向量機的8分鐘內只需要不到20秒。然而,需要注意的是,支持向量機管道推理持續時間是在CPU上執行的,而更快的CNN推理持續時間僅在GPU上獲得。此外,只有一部分支持向量機管道並行執行處理。當在CPU上運行高度並行的CNN推理時,測試時間顯著增加到12分鐘以上。因此,在CPU上訓練CNN變得很難,因此我們避免測量相應的運行時。
考慮到單個支持向量機管道步驟的相對貢獻,特征提取最耗時,其次是局部特征編碼和聚類(參見圖15)。特征預處理和超參數優化要求最少。

在不僅需要低資源占用而且必須快速運行的應用程序中,可以通過SIFT或PHOW替換VGG特征描述符來减少支持向量機管道的總執行時間。這兩種特征描述符在保持與VGG描述符相似的分類性能的同時,將推理期間的特征提取時間從最初的8分鐘分別减少到23秒和12秒左右。
4.10. 討論
從評估結果中可以得出幾個結論。首先,如果關鍵點的空間分布相當稀疏,則掩蔽可能很有用。然而,在大多數情况下,掩蔽並不能提高分類精度。其次,根據單元中缺陷可能性的置信度按比例加權樣本確實提高了學習分類器的泛化能力。
使用線性支持向量機訓練的KAZE/VGG特征是性能最好的支持向量機管道變體,准確率為82.44%,F1分數為82.52%。CNN甚至更准確。它區分了起作用的和有缺陷的太陽能電池,准確率為88.42%。相應的F1得分為88.39%。通過t-SNE對CNN特征分布的二維可視化强調了網絡學習了手頭任務的實際結構。
該方法的一個局限性是每個太陽能電池都是獨立檢查的。特別是,不影響模塊效率的某些類型的錶面异常可以在細胞間以重複模式出現。對這種大規模效應的准確分類需要考慮語境,這取决於未來的工作。
與其預測缺陷的可能性,不如預測特定的缺陷類型。給定額外的訓練數據,在給定具有適當標簽的額外訓練數據的情况下,可以在不發生重大變化(例如,通過微調新的缺陷類別)的情况下應用本工作中提出的方法。然而,將網絡微調到多個缺陷類別,以預測缺陷類型而不是其概率,通常會影響損失函數的選擇,從而影響最後激活層中的神經元數量。此類任務的損失函數的常見選擇是(分類)交叉熵損失和softmax激活(Goodfello等人,2016)。
5.總結
我們提出了一個訓練支持向量機和神經網絡的通用框架,可用於識別高分辨率EL圖像中的缺陷太陽能電池。仔細設計了支持向量機分類器的處理管道。在一系列實驗中,性能最佳的管道被確定為基於樣本訓練的線性支持向量機中的KAZE/VGG特征,該樣本考慮了標簽機的置信度。CNN網絡是一個基於VGG-19的微調回歸網絡,在增强細胞圖像上訓練,也考慮了標簽置信度。
在單晶太陽能組件上,這兩種分類器的性能相似,對於CNN來說平均只有一點優勢。然而,在更不均勻的多晶細胞上,CNN分類器比SVM分類器的精度高出約6%。這也使得CNN在所有細胞中的平均准確率更好,為88.42%,而SVM為82.44%。高精度使兩種分類器都適用於視覺檢查。如果應用場景允許使用GPU和更高的處理時間,則首選計算更昂貴的CNN。否則,對於需要低資源占用的應用程序,支持向量機分類器是一種可行的替代方案。
//本文僅作為日後複習之用,並無他用。
边栏推荐
- 干货分享|DevExpress v22.1原版帮助文档下载集合
- IP 工具类
- Zhong Xuegao wants to remain innocent in the world
- How to estimate the value of "not selling pens" Chenguang?
- 项目经理『面试八问』,看了等于会了
- 【牛客网刷题系列 之 Verilog进阶挑战】~ 多bit MUX同步器
- Redis master-slave and sentinel master-slave switchover are built step by step
- R language ggplot2 visualization: use the ggqqplot function of ggpubr package to visualize the QQ graph (Quantitative quantitative plot)
- R语言dplyr包select函数、group_by函数、filter函数和do函数获取dataframe中指定因子变量中指定水平中特定数值数据列的值第三大的值
- how to prove compiler‘s correctness
猜你喜欢
杰理之关于 TWS 配对方式配置【篇】

Netease Yunxin participated in the preparation of the standard "real time audio and video service (RTC) basic capability requirements and evaluation methods" issued by the Chinese Academy of Communica
谷歌seo外链Backlinks研究工具推荐
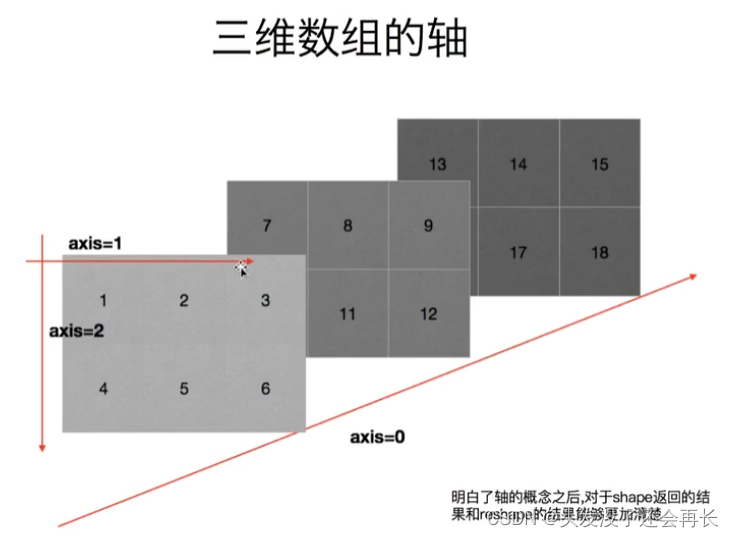
Numpy——2. Shape of array
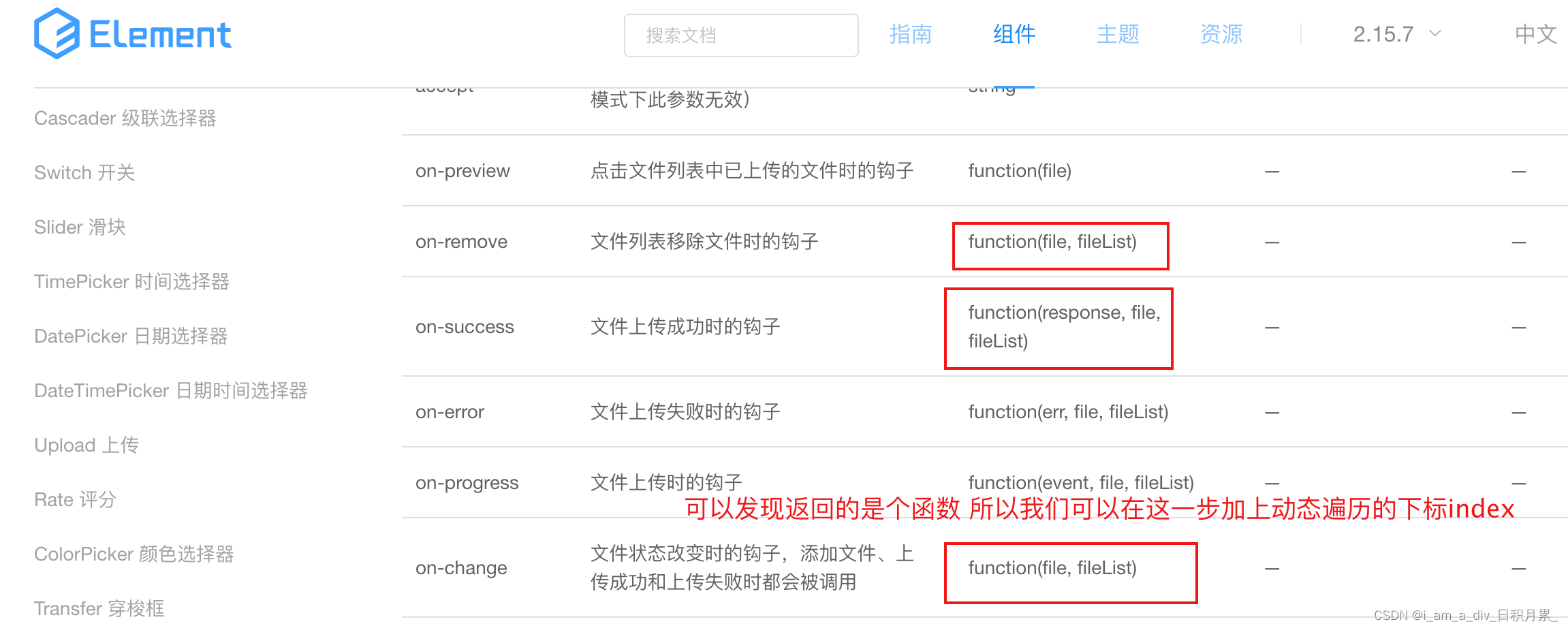
Dynamic addition of El upload upload component; El upload dynamically uploads files; El upload distinguishes which component uploads the file.
Numpy——axis
杰理之发起对耳配对、回连、开启可发现、可连接的轮循函数【篇】
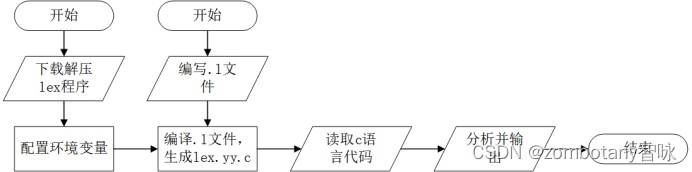
编译原理 实验一:词法分析器的自动实现(Lex词法分析)

2022.07.02

Kirin Xin'an with heterogeneous integration cloud financial information and innovation solutions appeared at the 15th Hunan Financial Technology Exchange Conference
随机推荐
What does "true" mean
R language ggplot2 visualization: use the ggstripchart function of ggpubr package to visualize the dot strip plot, set the position parameter, and configure the separation degree of different grouped
R语言使用ggplot2函数可视化需要构建泊松回归模型的计数目标变量的直方图分布并分析构建泊松回归模型的可行性
[Verilog advanced challenge of Niuke network question brushing series] ~ multi bit MUX synchronizer
编译原理 实验一:词法分析器的自动实现(Lex词法分析)
杰理之关于 TWS 声道配置【篇】
杰理之关于 TWS 配对方式配置【篇】
Jerry's headphones with the same channel are not allowed to pair [article]
Navicat连接2002 - Can‘t connect to local MySQL server through socket ‘/var/lib/mysql/mysql.sock‘解决
Seize Jay Chou
Uvalive – 4621 CAV greed + analysis "suggestions collection"
Kirin Xin'an won the bid for the new generation dispatching project of State Grid!
【Confluence】JVM内存调整
AI writes a poem
PMP对工作有益吗?怎么选择靠谱平台让备考更省心省力!!!
tp6 实现佣金排行榜
PMP對工作有益嗎?怎麼選擇靠譜平臺讓備考更省心省力!!!
吞吐量Throughout
Number - number (Lua)
The project manager's "eight interview questions" is equal to a meeting