当前位置:网站首页>Hands on deep learning (45) -- bundle search
Hands on deep learning (45) -- bundle search
2022-07-04 09:41:00 【Stay a little star】
List of articles
Beam search
stay seq2seq in , We predict the markers of the output sequence one by one , Until the end of the sequence marker appears in the prediction sequence “<eos>”. In this section , We will first discuss this Greedy search (greedy search) Strategy , And discuss its existing problems , Then compare this strategy with other alternative strategies : Exhaustive search (exhaustive search) and Beam search (beam search).
Before introducing greedy search , Let's use seq2seq The same mathematical symbols in define the search problem . At any time step t ′ t' t′, Decoder output y t ′ y_{t'} yt′ The probability of depends on the time step t ′ t' t′ Previous output subsequence y 1 , … , y t ′ − 1 y_1, \ldots, y_{t'-1} y1,…,yt′−1 The context variable encoded with the information of the input sequence c \mathbf{c} c. In order to quantify the cost , use Y \mathcal{Y} Y( It contains “<eos>”) Represents the output vocabulary . So the cardinality of this vocabulary set ∣ Y ∣ \left|\mathcal{Y}\right| ∣Y∣ Is the size of the vocabulary . We also specify the maximum number of tags in the output sequence as T ′ T' T′. therefore , Our goal is from all O ( ∣ Y ∣ T ′ ) \mathcal{O}(\left|\mathcal{Y}\right|^{T'}) O(∣Y∣T′) Find the ideal output in a possible output sequence . Of course , For all output sequences , These sequences contain “<eos>” And subsequent parts will be discarded in the actual output .
One 、 Greedy search
First , Let's look at a simple strategy : Greedy search . This strategy has been used seq2seq Sequence prediction of . For any time step of the output sequence t ′ t' t′, We will all search from... Based on greed Y \mathcal{Y} Y Find the marker with the highest conditional probability , namely :
y t ′ = * a r g m a x y ∈ Y P ( y ∣ y 1 , … , y t ′ − 1 , c ) y_{t'} = \operatorname*{argmax}_{y \in \mathcal{Y}} P(y \mid y_1, \ldots, y_{t'-1}, \mathbf{c}) yt′=*argmaxy∈YP(y∣y1,…,yt′−1,c)
Once the output sequence contains “<eos>” Or reach its maximum length T ′ T' T′, Then the output is completed .
So what's the problem with greedy search ?
actually , The optimal sequence (optimal sequence) It should be maximization ∏ t ′ = 1 T ′ P ( y t ′ ∣ y 1 , … , y t ′ − 1 , c ) \prod_{t'=1}^{T'} P(y_{t'} \mid y_1, \ldots, y_{t'-1}, \mathbf{c}) ∏t′=1T′P(yt′∣y1,…,yt′−1,c) Output sequence of values , This is the conditional probability of generating the output sequence based on the input sequence . Unfortunately , There is no guarantee that the optimal sequence can be obtained through greedy search .

Let's use an example to describe . Suppose there are four tags in the output “A”、“B”、“C” and “<eos>”. In the diagram above , The four numbers under each time step represent the generation of “A”、“B”、“C” and “<eos>” Conditional probability of . At each time step , Greedy search selects the marker with the highest conditional probability . therefore , The output sequence will be predicted in the figure “A”、“B”、“C” and “<eos>”. The conditional probability of this output sequence is 0.5 × 0.4 × 0.4 × 0.6 = 0.048 0.5 \times 0.4 \times 0.4 \times 0.6 = 0.048 0.5×0.4×0.4×0.6=0.048.

Next , Let's take a look at another example in the figure above . Different from Figure 1 , In time step 2 in , We choose the tag in Figure 1 “C”, It has second High conditional probability . Because of the time step 3 Based on time steps 1 and 2 The output subsequence at has been removed from “A” and “B” Change for “A” and “C”, So time step 3 The conditional probability of each marker at is also shown in the figure 2 Change in China . Let's say we're in the time step 3 Choose the mark “B”. Now? , Time step 4 The previous three time steps “A”、“C” and “B” The output subsequence of is conditional , This is similar to “A”、“B” and “C” Different . therefore , In the figure 2 Time step in 4 The conditional probability of generating each tag is also different from the graph 1 Conditional probabilities in . result , chart 2 Output sequence in “A”、“C”、“B” and “<eos>” The conditional probability of is 0.5 × 0.3 × 0.6 × 0.6 = 0.054 0.5\times0.3 \times0.6\times0.6=0.054 0.5×0.3×0.6×0.6=0.054, This is larger than figure 1 Conditional probability of greedy search in .
In this case , Output sequence obtained by greedy search “A”、“B”、“C” and “<eos>” Not the best sequence .
Two 、 Exhaustive search
If the goal is to obtain the optimal sequence , We can consider using Exhaustive search (exhaustive search): Enumerate exhaustively all possible output sequences and their conditional probabilities , Then output the one with the highest conditional probability .
Although we can use exhaustive search to obtain the optimal sequence , But it's Amount of computation O ( ∣ Y ∣ T ′ ) \mathcal{O}(\left|\mathcal{Y}\right|^{T'}) O(∣Y∣T′) May be too high . for example , When ∣ Y ∣ = 10000 |\mathcal{Y}|=10000 ∣Y∣=10000 and T ′ = 10 T'=10 T′=10 when , We need to evaluate 1000 0 10 = 1 0 40 10000^{10} = 10^{40} 1000010=1040 Sequence . It's almost impossible . On the other hand , The calculation amount of greedy search is O ( ∣ Y ∣ T ′ ) \mathcal{O}(\left|\mathcal{Y}\right|T') O(∣Y∣T′): It is usually significantly smaller than exhaustive search . for example , When ∣ Y ∣ = 10000 |\mathcal{Y}|=10000 ∣Y∣=10000 and T ′ = 10 T'=10 T′=10 when , We just need to evaluate 10000 × 10 = 1 0 5 10000\times10=10^5 10000×10=105 A sequence of .
3、 ... and 、 Beam search
Determining the sequence search strategy depends on a range , In any extreme case, there are problems . If only accuracy is the most important ? Is obviously an exhaustive search . If calculating the cost is the most important ? Is obviously greedy search . Practical applications lie between these two extremes .
Beam search (beam search) Is an improved version of greedy search . It has a super parameter , be known as Beam width (beam size) k k k. In time step 1 1 1, We choose the one with the highest conditional probability k k k A sign . this k k k The marks will be k k k The first tag of the candidate output sequence . At each subsequent time step , Based on the last time step k k k Candidate output sequences , We will continue from k ∣ Y ∣ k\left|\mathcal{Y}\right| k∣Y∣ Choose the one with the highest conditional probability among the possible choices k k k Candidate output sequences .

The above figure illustrates the process of beam search . Suppose the output vocabulary contains only five elements : Y = { A , B , C , D , E } \mathcal{Y} = \{A, B, C, D, E\} Y={ A,B,C,D,E}, One of them is “<eos>”. Set the beam width to 2, The maximum length of the output sequence is 3. In time step 1, Assume the highest conditional probability P ( y 1 ∣ c ) P(y_1 \mid \mathbf{c}) P(y1∣c) The sign of is A A A and C C C. In time step 2, We calculate all y 2 ∈ Y y_2 \in \mathcal{Y} y2∈Y:
P ( A , y 2 ∣ c ) = P ( A ∣ c ) P ( y 2 ∣ A , c ) , P ( C , y 2 ∣ c ) = P ( C ∣ c ) P ( y 2 ∣ C , c ) , \begin{aligned}P(A, y_2 \mid \mathbf{c}) = P(A \mid \mathbf{c})P(y_2 \mid A, \mathbf{c}),\\ P(C, y_2 \mid \mathbf{c}) = P(C \mid \mathbf{c})P(y_2 \mid C, \mathbf{c}),\end{aligned} P(A,y2∣c)=P(A∣c)P(y2∣A,c),P(C,y2∣c)=P(C∣c)P(y2∣C,c),
Choose the largest two of these ten values , such as P ( A , B ∣ c ) P(A, B \mid \mathbf{c}) P(A,B∣c) and P ( C , E ∣ c ) P(C, E \mid \mathbf{c}) P(C,E∣c). Then in the time step 3, For all y 3 ∈ Y y_3 \in \mathcal{Y} y3∈Y, We calculated :
P ( A , B , y 3 ∣ c ) = P ( A , B ∣ c ) P ( y 3 ∣ A , B , c ) , P ( C , E , y 3 ∣ c ) = P ( C , E ∣ c ) P ( y 3 ∣ C , E , c ) , \begin{aligned}P(A, B, y_3 \mid \mathbf{c}) = P(A, B \mid \mathbf{c})P(y_3 \mid A, B, \mathbf{c}),\\P(C, E, y_3 \mid \mathbf{c}) = P(C, E \mid \mathbf{c})P(y_3 \mid C, E, \mathbf{c}),\end{aligned} P(A,B,y3∣c)=P(A,B∣c)P(y3∣A,B,c),P(C,E,y3∣c)=P(C,E∣c)P(y3∣C,E,c),
Choose the largest two of these ten values , namely P ( A , B , D ∣ c ) P(A, B, D \mid \mathbf{c}) P(A,B,D∣c) and P ( C , E , D ∣ c ) P(C, E, D \mid \mathbf{c}) P(C,E,D∣c). result , We get six candidate output sequences :(1) A A A;(2) C C C;(3) A , B A,B A,B;(4) C , E C,E C,E;(5) A , B , D A,B,D A,B,D ;(6) C , E , D C,E,D C,E,D.
Last , We are based on these six sequences ( for example , Discarding includes “<eos>” And the rest ) Obtain the final set of candidate output sequences . Then we choose the following sequence with the highest score as the output sequence :
1 L α log P ( y 1 , … , y L ) = 1 L α ∑ t ′ = 1 L log P ( y t ′ ∣ y 1 , … , y t ′ − 1 , c ) , \frac{1}{L^\alpha} \log P(y_1, \ldots, y_{L}) = \frac{1}{L^\alpha} \sum_{t'=1}^L \log P(y_{t'} \mid y_1, \ldots, y_{t'-1}, \mathbf{c}), Lα1logP(y1,…,yL)=Lα1t′=1∑LlogP(yt′∣y1,…,yt′−1,c),
among L L L Is the length of the final candidate sequence , α \alpha α Usually set to 0.75. Because a longer sequence will have more logarithmic terms in the sum of the above formula , So in the denominator L α L^\alpha Lα Used to punish long sequences .
The calculation amount of beam search is O ( k ∣ Y ∣ T ′ ) \mathcal{O}(k\left|\mathcal{Y}\right|T') O(k∣Y∣T′). This result is between greedy search and exhaustive search . actually , Greedy search can be seen as a beam width of 1 Special type of bundle search . By flexibly selecting the beam width , Beam search can make a trade-off between accuracy and computational cost .
Summary
- The sequence search strategy includes greedy search 、 Exhaustive search and beam search .
- Beam search through flexible selection of beam width , Find a balance between accuracy and computational cost .
practice
- Can we regard exhaustive search as a special kind of bundle search ? Why? ?
k = 1 Greedy search ;k = n It's time to search exhaustively
- stay seq2seq Application of bundle search in machine translation problems . How beam width affects results and prediction speed ?
The smaller the beam width , The fewer times it is exhausted , So the prediction speed will be faster , But the result may not be the optimal result
- stay seq2seq in , We use a language model to generate user prefixed text . What search strategy does it use ? Can you improve ?
边栏推荐
- Kotlin 集合操作汇总
- Hands on deep learning (38) -- realize RNN from scratch
- Fatal error in golang: concurrent map writes
- Reading notes on how to connect the network - hubs, routers and routers (III)
- How does idea withdraw code from remote push
- Web端自动化测试失败原因汇总
- Regular expression (I)
- Report on investment analysis and prospect trend prediction of China's MOCVD industry Ⓤ 2022 ~ 2028
- Hands on deep learning (35) -- text preprocessing (NLP)
- PHP student achievement management system, the database uses mysql, including source code and database SQL files, with the login management function of students and teachers
猜你喜欢
MySQL foundation 02 - installing MySQL in non docker version

C # use gdi+ to add text to the picture and make the text adaptive to the rectangular area

At the age of 30, I changed to Hongmeng with a high salary because I did these three things
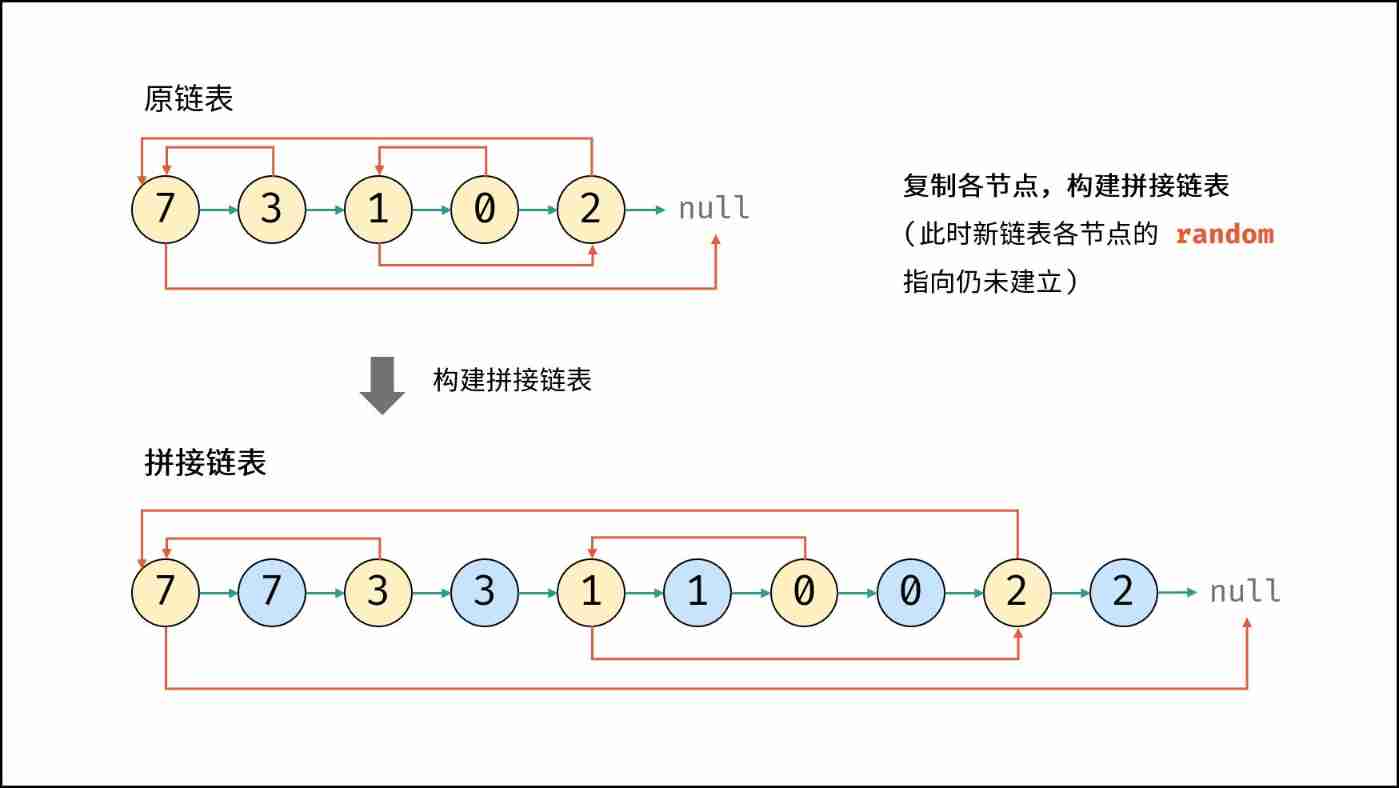
Leetcode (Sword finger offer) - 35 Replication of complex linked list

Four common methods of copying object attributes (summarize the highest efficiency)
C语言指针经典面试题——第一弹
QTreeView+自定义Model实现示例
How does idea withdraw code from remote push
Log cannot be recorded after log4net is deployed to the server

智能网关助力提高工业数据采集和利用
随机推荐
2022-2028 global protein confectionery industry research and trend analysis report
Multilingual Wikipedia website source code development part II
Global and Chinese market of sampler 2022-2028: Research Report on technology, participants, trends, market size and share
Modules golang
Hands on deep learning (32) -- fully connected convolutional neural network FCN
Write a jison parser from scratch (3/10): a good beginning is half the success -- "politics" (Aristotle)
PHP student achievement management system, the database uses mysql, including source code and database SQL files, with the login management function of students and teachers
`Example of mask ` tool use
Matlab tips (25) competitive neural network and SOM neural network
2022-2028 global industry research and trend analysis report on anterior segment and fundus OTC detectors
Global and Chinese markets of thrombography hemostasis analyzer (TEG) 2022-2028: Research Report on technology, participants, trends, market size and share
Fatal error in golang: concurrent map writes
How to write unit test cases
C # use smtpclient The sendasync method fails to send mail, and always returns canceled
Solution to null JSON after serialization in golang
2022-2028 global tensile strain sensor industry research and trend analysis report
Dynamic analysis and development prospect prediction report of high purity manganese dioxide in the world and China Ⓡ 2022 ~ 2027
Lauchpad x | MODE
Explanation of closures in golang
System.currentTimeMillis() 和 System.nanoTime() 哪个更快?别用错了!