当前位置:网站首页>Flink Task退出流程与Failover机制
Flink Task退出流程与Failover机制
2022-07-06 19:54:00 【Direction_Wind】
这里写目录标题
1 TaskExecutor端Task退出逻辑
Task.doRun() 引导Task初始化并执行其相关代码的核心方法,
构造并实例化Task的可执行对象: AbstractInvokable invokable。
调用 AbstractInvokable.invoke() 开始启动Task包含的计算逻辑。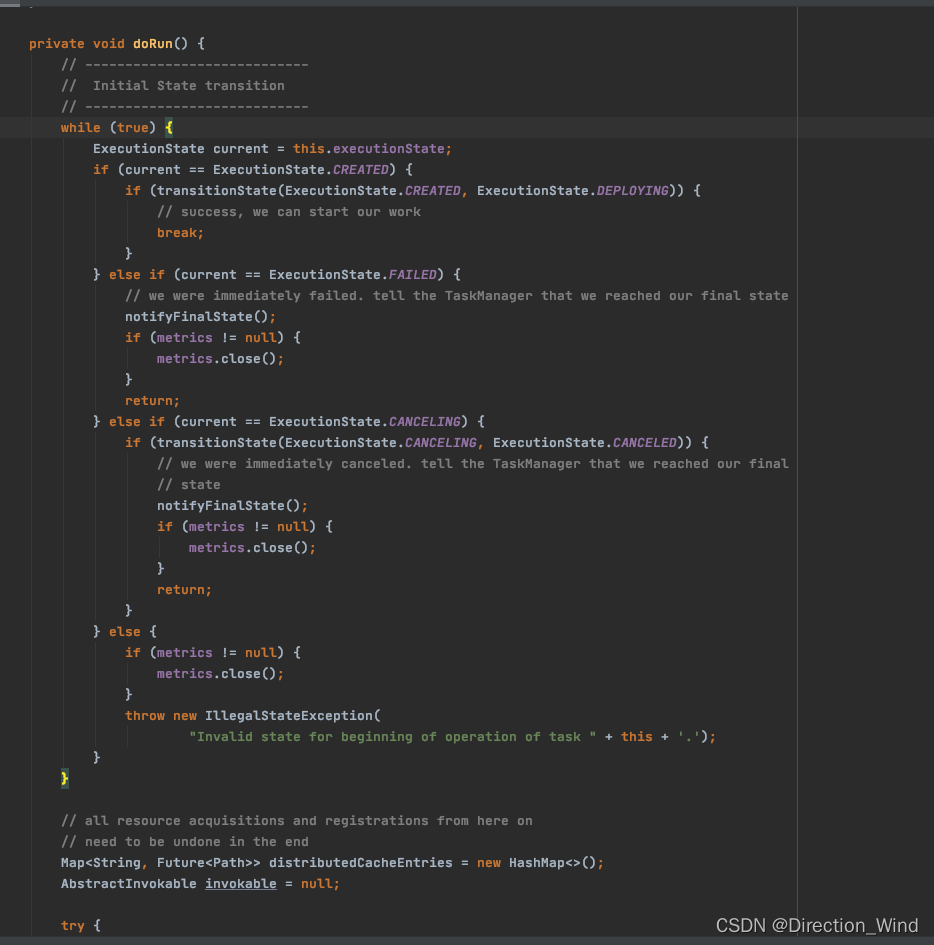
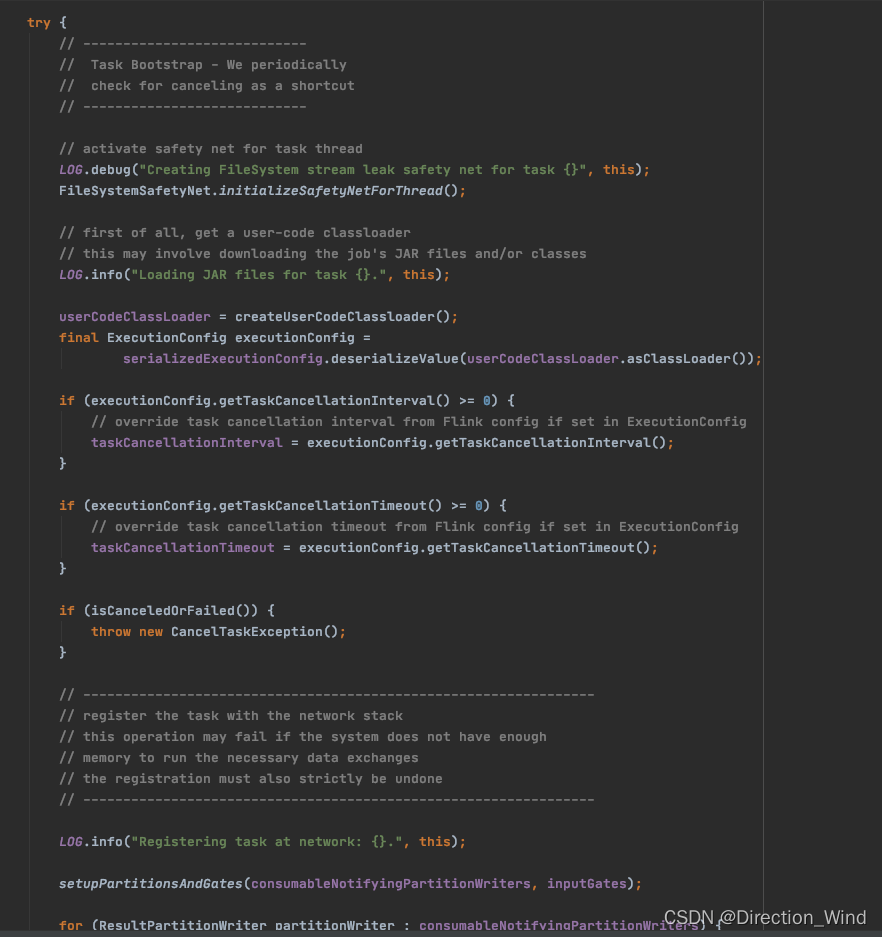
当AbstractInvokable.invoke()执行退出后,根据退出类型执行相应操作:
- 正常执行完毕退出:输出ResultPartition缓冲区数据,并关闭缓冲区,标记Task为Finished;
- 取消操作导致退出:标记Task为CANCELED,关闭用户代码;
- AbstractInvokable.invoke()执行过程中抛出异常退出:标记Task为FAILED,关闭用户代码,记录异常;
- AbstractInvokable.invoke()执行过程中JVM抛出错误:强制终止虚拟机,退出当前进程。
紧接着释放Task相关的网络、内存、文件系统资源。最后通过Task->TaskManager->JobMaster的传递链路将Task的终止状态通知给Leader JobMaster线程。
Task.notifyFinalState() -> TaskManagerActions.updateTaskExecutionState(TaskExecutionState) -> JobMasterGateway.updateTaskExecutionState(TaskExecutionState)
- TaskExecutionState携带的关键信息:
TaskExecutionState {
JobID // 任务ID
ExecutionAttemptID // Task执行的唯一ID,标示每次执行
ExecutionState // 枚举值,Task执行状态
SerializedThrowable // 若Task抛出异常,该字段记录异常堆栈信息
...
}
- Task 执行状态转换:
CREATED -> SCHEDULED -> DEPLOYING -> RUNNING -> FINISHED
| | | |
| | | +------+
| | V V
| | CANCELLING -----+----> CANCELED
| | |
| +-------------------------+
|
| ... -> FAILED
V
RECONCILING -> RUNNING | FINISHED | CANCELED | FAILED
2 JobMaster端failover流程
2.1 Task Execute State Handle
JobMaster收到TaskManager通过rpc发送的task执行状态变更信息,将通知当前Flink作业的调度器(SchedulerNG)处理,因为都是通过同个线程调用,后续对ExecutionGraph(运行时执行计划)、failover计数等有状态实例的read/write操作都不会出现线程安全问题。
JobMaster的核心处理逻辑在SchedulerBase.updateTaskExecutionState(TaskExecutionStateTransition) 中(TaskExecutionStateTransition主要是TaskExecutionState的可读性封装)。
处理逻辑:尝试将收到的Task执行状态信息更新到ExecutionGraph中。若更新成功且target状态为FINISHED,根据具体的SchedulingStrategy实现策略,选择可消费的结果分区并调度相应的消费者Task;若更新成功且target状态为FAILED,进入具体的failover流程。
- SchedulerBase.updateTaskExecutionState(TaskExecutionStateTransition) :
public final boolean updateTaskExecutionState(
final TaskExecutionStateTransition taskExecutionState) {
final Optional<ExecutionVertexID> executionVertexId =
getExecutionVertexId(taskExecutionState.getID());
boolean updateSuccess = executionGraph.updateState(taskExecutionState);
if (updateSuccess) {
checkState(executionVertexId.isPresent());
if (isNotifiable(executionVertexId.get(), taskExecutionState)) {
updateTaskExecutionStateInternal(executionVertexId.get(), taskExecutionState);
}
return true;
} else {
return false;
}
}
- ExecutionGraph.updateState(TaskExecutionStateTransition): 在当前的物理执行拓扑中找不到目标ExecutionAttemptID 时,将更新失败。需要注意的是这个ID用于唯一标示一个Execution,而Execution则代表ExecutionVertex(代表拓扑顶点的一个subTask计划)的一次执行实例,ExecutionVertex可以重复多次执行。这意味着当有subTask重新运行,currentExecutions将不再持有上一次执行的ID信息。
/** * Updates the state of one of the ExecutionVertex's Execution attempts. If the new status if * "FINISHED", this also updates the accumulators. * * @param state The state update. * @return True, if the task update was properly applied, false, if the execution attempt was * not found. */
public boolean updateState(TaskExecutionStateTransition state) {
assertRunningInJobMasterMainThread();
final Execution attempt = currentExecutions.get(state.getID());
if (attempt != null) {
try {
final boolean stateUpdated = updateStateInternal(state, attempt);
maybeReleasePartitions(attempt);
return stateUpdated;
} catch (Throwable t) {
......
return false;
}
} else {
return false;
}
}
JobMaster: 负责一个任务拓扑的中心操作类,涉及作业调度,资源管理,对外通讯等…
SchedulerNG:负责调度作业拓扑。所有对该类对象方法的调用都会通过ComponentMainThreadExecutor触发,将不会出现并发调用的情况。
ExecutionGraph: 当前执行拓扑的中心数据结构,协调分布在各个节点上的Execution。描述了整个任务的各个SubTask及其分区数据,并与其保持通讯。
2.2 Job Failover
2.2.1 Task Failure Handle
- Task异常的主要流程在 DefaultScheduler.handleTaskFailure(ExecutionVertexID, Throwable), 根据RestartBackoffTimeStrategy判断是重启还是failed-job;根据FailoverStrategy选择需要重启的SubTask;最后根据任务当前的SchedulingStrategy执行相应的调度策略重启相应的Subtask。
private void handleTaskFailure(
final ExecutionVertexID executionVertexId, @Nullable final Throwable error) {
// 更新当前任务异常信息
setGlobalFailureCause(error);
// 如果相关的算子(source、sink)存在coordinator,同知其进一步操作
notifyCoordinatorsAboutTaskFailure(executionVertexId, error);
// 应用当前的restart-stratege并获取FailureHandlingResult
final FailureHandlingResult failureHandlingResult =
executionFailureHandler.getFailureHandlingResult(executionVertexId, error);
// 根据结果重启Task或将任务失败
maybeRestartTasks(failureHandlingResult);
}
public class FailureHandlingResult {
//恢复所需要重启的所有SubTask
Set<ExecutionVertexID> verticesToRestart;
//重启延迟
long restartDelayMS;
//万恶之源
Throwable error;
//是否全局失败
boolean globalFailure;
}
- ExecutionFailureHandler:处理异常信息,根据当前应用策略返回异常处理结果。
public FailureHandlingResult getFailureHandlingResult(
ExecutionVertexID failedTask, Throwable cause) {
return handleFailure(
cause,
failoverStrategy.getTasksNeedingRestart(failedTask, cause), // 选择出需要重启的SubTask
false);
}
private FailureHandlingResult handleFailure(
final Throwable cause,
final Set<ExecutionVertexID> verticesToRestart,
final boolean globalFailure) {
if (isUnrecoverableError(cause)) {
return FailureHandlingResult.unrecoverable(
new JobException("The failure is not recoverable", cause), globalFailure);
}
restartBackoffTimeStrategy.notifyFailure(cause);
if (restartBackoffTimeStrategy.canRestart()) {
numberOfRestarts++;
return FailureHandlingResult.restartable(
verticesToRestart, restartBackoffTimeStrategy.getBackoffTime(), globalFailure);
} else {
return FailureHandlingResult.unrecoverable(
new JobException(
"Recovery is suppressed by " + restartBackoffTimeStrategy, cause),
globalFailure);
}
}
FailoverStrategy: 故障转移策略。
- RestartAllFailoverStrategy: 使用该策略,当出现故障,将重启整个作业,即重启所有Subtask。
- RestartPipelinedRegionFailoverStrategy:当出现故障,重启故障出现Subtask所在的的Region。
- RestartBackoffTimeStrategy: 当Task发生故障时,决定是否重启以及重启的延迟时间。
FixedDelayRestartBackoffTimeStrategy:允许任务以指定延迟重启固定次数。
- FailureRateRestartBackoffTimeStrategy:允许在固定失败频率内,以固定延迟重启。
- NoRestartBackoffTimeStrategy:不重启。
SchedulingStrategy: Task执行实例的调度策略
- EagerSchedulingStrategy: 饥饿调度,同时调度所有Task。
- LazyFromSourcesSchedulingStrategy:当消费的分区数据都准备好后才开始调度其后续Task,用于批处理任务。
- PipelinedRegionSchedulingStrategy:以pipline链接的Task为一个Region,作为其调度粒度。
2.2.2 Restart Task
private void maybeRestartTasks(final FailureHandlingResult failureHandlingResult) {
if (failureHandlingResult.canRestart()) {
restartTasksWithDelay(failureHandlingResult);
} else {
failJob(failureHandlingResult.getError());
}
}
private void restartTasksWithDelay(final FailureHandlingResult failureHandlingResult) {
final Set<ExecutionVertexID> verticesToRestart =
failureHandlingResult.getVerticesToRestart();
final Set<ExecutionVertexVersion> executionVertexVersions =
new HashSet<>(
executionVertexVersioner
.recordVertexModifications(verticesToRestart)
.values());
final boolean globalRecovery = failureHandlingResult.isGlobalFailure();
addVerticesToRestartPending(verticesToRestart);
// 取消所有需要重启的SubTask
final CompletableFuture<?> cancelFuture = cancelTasksAsync(verticesToRestart);
delayExecutor.schedule(
() ->
FutureUtils.assertNoException(
cancelFuture.thenRunAsync( // 停止后才能重新启动
restartTasks(executionVertexVersions, globalRecovery),
getMainThreadExecutor())),
failureHandlingResult.getRestartDelayMS(),
TimeUnit.MILLISECONDS);
}
2.2.3 Cancel Task:
- 取消正在等待Slot分配的SubTask,若已经处于部署/运行状态,则需要通知TaskExecutor执行停止操作并等待操作完成。
private CompletableFuture<?> cancelTasksAsync(final Set<ExecutionVertexID> verticesToRestart) {
// clean up all the related pending requests to avoid that immediately returned slot
// is used to fulfill the pending requests of these tasks
verticesToRestart.stream().forEach(executionSlotAllocator::cancel); // 取消可能正处于等待分配Slot的SubTask
final List<CompletableFuture<?>> cancelFutures =
verticesToRestart.stream()
.map(this::cancelExecutionVertex) // 开始停止SubTask
.collect(Collectors.toList());
return FutureUtils.combineAll(cancelFutures);
}
public void cancel() {
while (true) {
// 状态变更失败则重试
ExecutionState current = this.state;
if (current == CANCELING || current == CANCELED) {
// already taken care of, no need to cancel again
return;
}
else if (current == RUNNING || current == DEPLOYING) {
// 当前状态设为CANCELING,并向TaskExecutor发送RPC请求停止SubTask
if (startCancelling(NUM_CANCEL_CALL_TRIES)) {
return;
}
} else if (current == FINISHED) {
// 即使完成运行,后续也无法消费,释放分区结果
sendReleaseIntermediateResultPartitionsRpcCall();
return;
} else if (current == FAILED) {
return;
} else if (current == CREATED || current == SCHEDULED) {
// from here, we can directly switch to cancelled, because no task has been deployed
if (cancelAtomically()) {
return;
}
} else {
throw new IllegalStateException(current.name());
}
}
}
- 操作完毕后又会执行Task退出流程通知ExecutionGraph执行相应数据更新: ExecutionGraph.updateState(TaskExecutionStateTransition)->ExecutionGraph.updateStateInternal(TaskExecutionStateTransition, Execution) -> Execution.completeCancelling(…) -> Execution.finishCancellation(boolean) -> ExecutionGraph.deregisterExecution(Execution) 。在deregisterExecution操作会在currentExecutions中移除已停止的执行ExecutionTask。
2.2.4 Start Task
private Runnable restartTasks(
final Set<ExecutionVertexVersion> executionVertexVersions,
final boolean isGlobalRecovery) {
return () -> {
final Set<ExecutionVertexID> verticesToRestart =
executionVertexVersioner.getUnmodifiedExecutionVertices(
executionVertexVersions);
removeVerticesFromRestartPending(verticesToRestart);
// 实例化新的SubTask执行实例(Execution)
resetForNewExecutions(verticesToRestart);
try {
// 恢复状态
restoreState(verticesToRestart, isGlobalRecovery);
} catch (Throwable t) {
handleGlobalFailure(t);
return;
}
// 开始调度,申请Slot并部署
schedulingStrategy.restartTasks(verticesToRestart);
};
}
边栏推荐
- How-PIL-to-Tensor
- unrecognized selector sent to instance 0x10b34e810
- Summary of research status of inertial navigation calibration at home and abroad (abridged version)
- 杰理之RTC 时钟开发【篇】
- How to verify accesstoken in oauth2 protocol
- 从 1.5 开始搭建一个微服务框架——日志追踪 traceId
- The whole process of knowledge map construction
- Construction of knowledge map of mall commodities
- leetcode-02(链表题)
- Oracle connection pool is not used for a long time, and the connection fails
猜你喜欢
Redis入门完整教程:RDB持久化
2022.6.28
商城商品的知识图谱构建
掘金量化:通过history方法获取数据,和新浪财经,雪球同用等比复权因子。不同于同花顺
MOS transistor realizes the automatic switching circuit of main and auxiliary power supply, with "zero" voltage drop and static current of 20ua
Redis getting started complete tutorial: replication topology
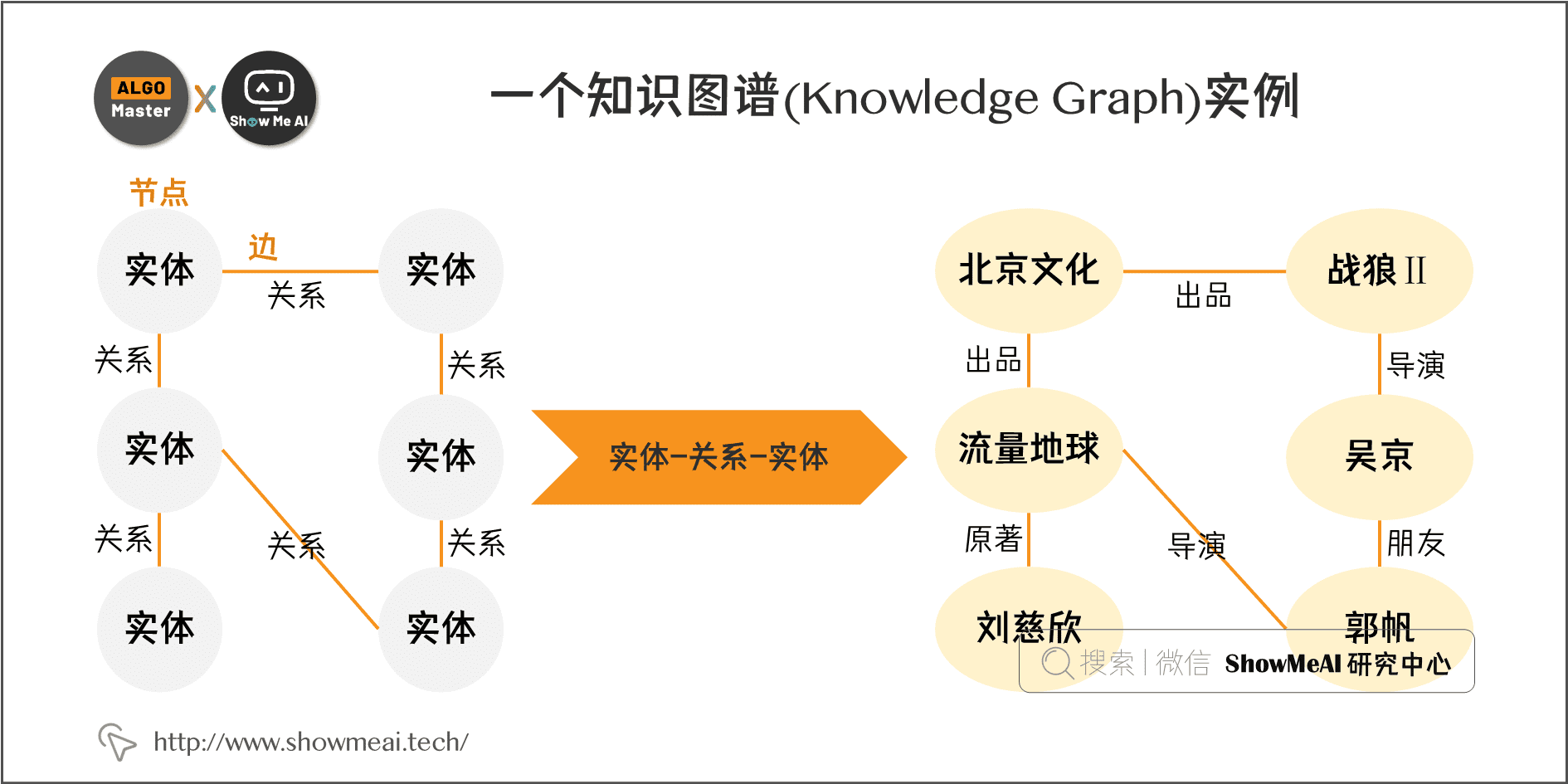
知识图谱构建全流程
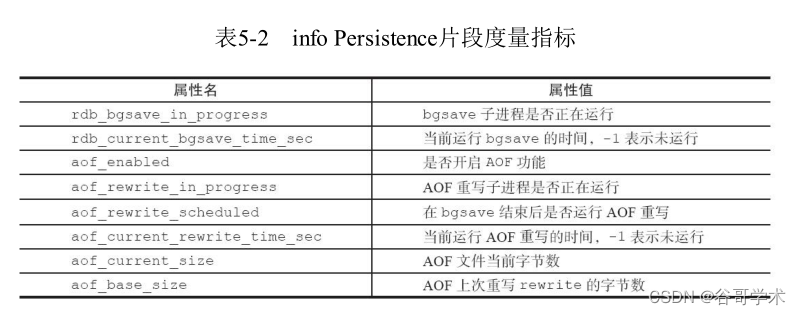
Redis Getting started tutoriel complet: positionnement et optimisation des problèmes
Oauth2协议中如何对accessToken进行校验

Left path cloud recursion + dynamic planning
随机推荐
Es6中Promise的使用
MOS transistor realizes the automatic switching circuit of main and auxiliary power supply, with "zero" voltage drop and static current of 20ua
Static proxy of proxy mode
MySQL is an optimization artifact to improve the efficiency of massive data query
【基于 RT-Thread Studio的CPK-RA6M4 开发板环境搭建】
C language string sorting
How to analyze fans' interests?
又一百万量子比特!以色列光量子初创公司完成1500万美元融资
首届“量子计算+金融科技应用”研讨会在京成功举办
Don't you know the relationship between JSP and servlet?
Redis getting started complete tutorial: common exceptions on the client
Cocos2d-x Box2D物理引擎编译设置
Left value, right value
Redis入门完整教程:客户端案例分析
leetcode
硬件之OC、OD、推挽解释
sshd[12282]: fatal: matching cipher is not supported: [email protected] [preauth]
INS/GPS组合导航类型简介
Codeforces Round #264 (Div. 2) C Gargari and Bishops 【暴力】
Matlab Error (Matrix dimensions must agree)