当前位置:网站首页>batch_size of deep learning foundation
batch_size of deep learning foundation
2022-08-02 05:29:00 【hello689】
Background knowledge: batch size is a parameter that can only be used in batch learning.Statistical learning can be divided into two categories: online learning and batch learning.That is to say, deep learning can be divided into online learning and batch learning according to a certain division method. We usually use batch learning more.For details, please refer to "Statistical Learning and Methods" Second Edition, p13.
Online learning: accept one sample at a time, make predictions, and repeatedly learn the model;
Batch learning: It is an offline learning method (all samples need to be acquired in advance for training tasks), and all samples oris a partial sample for learning.
1. Why do I need batch size?
One answer is this statement in the picture below. As a beginner, it may be a little confusing to see it for the first time.

The second answer is as follows: Is this answer still a bit convoluted?
In the batch method of supervised learning, the adjustment of the salient weights of the multilayer perceptron is performed after all N examples of the training sample set have appeared, which constitutes a traininground.The cost function for batch learning is defined by the mean error energy.So batch training is required.
My summary:
Why batch size is needed, the core is not enough memory.If the memory is sufficient, the error of all samples is used, and then the optimal gradient direction of the parameter to be optimized can be calculated, that is, the globally optimal gradient direction.However, in practice, the amount of data is very large, and the video memory is not enough, so the batch training method is needed for training.If the batch is too small, the randomness of the gradient descent direction is large, and the model is difficult to converge stably (the convergence speed is slow), and many iterations are required.Therefore, the selection of batch size is generally enough to choose a suitable one, which not only ensures high memory utilization, but also ensures that the model converges quickly and achieves a balance.
In addition, batch normal also requires batch data to find the mean square error. If the batch size is 1, BN is basically useless.
2. The benefits of increasing batch size (three points)
- The memory utilization is improved, and the parallelization efficiency of large matrix multiplication is improved.
- The number of iterations required to run an epoch is reduced, and the processing speed is accelerated relative to the same amount of data
- In a certain range, generally increase the batch size, the gradient descent direction is more accurate, and the convergence is stable
3. Disadvantages of increasing batch size (three points)
- The memory utilization is improved, but the memory capacity may not be enough (buy more memory)
- The number of iterations required to run an epoch is reduced. To achieve the same accuracy, it is necessary to train several more iterations, then increase the epoch and increase the training time.
- When the batch size increases to a certain extent, its decreasing direction is difficult to change, and it may fall into a local optimum.(The ship is difficult to turn around), unless the batch is all data.
4. How does adjusting batch size affect the training effect?
- The batch size is too small, the model performance is not good (error soars)
- As the batch size increases, the speed of processing the same amount of data is faster.
- As the batch size increases, the number of epochs required to achieve the same accuracy increases.
- Due to the contradiction between the above two factors, when the batch size increases to a certain value, the optimal time is achieved.
- Because the final convergence accuracy will fall into different local extremums, the batch size is increased to a certain time to achieve the optimal final convergence accuracy.
5. Why does batch_size need to be a multiple of 2?
Memory Alignment and Floating Point Efficiency;
One of the main arguments for choosing batch sizes as powers of 2 is that CPU and GPU memory architectures are powers of 2organized.Or more precisely, there is the concept of a memory page, which is essentially a contiguous block of memory.If you're on macOS or Linux, you can check the page size by executing getconf PAGESIZE in a terminal, which should return a power of 2 number.For details, please refer to this article.
References
- https://www.cnblogs.com/Wanggcong/p/4699932.html
- https://cloud.tencent.com/developer/article/1358478
- "Statistical Learning Methods" Li Hang
边栏推荐
- 树莓派4B开机自动挂载移动硬盘,以及遇到the root account is locked问题
- How to save a section of pages in a PDF as a new PDF file
- Your device is corrupt. It cant‘t be trusted and may not work propely.
- 如何将PDF中的一部分页面另存为新的PDF文件
- 并发性,时间和相对性(1)-确定前后关系
- jetracer_pro_2GB AI Kit系统安装使用说明
- 3D目标检测之数据集
- 剩余参数、数组对象的方法和字符串扩展的方法
- EasyCVR视频广场切换通道,视频播放协议异常的问题修复
- 科研笔记(七) 基于路径规划和WiFi指纹定位的多目的地室内导航
猜你喜欢
v-bind动态绑定
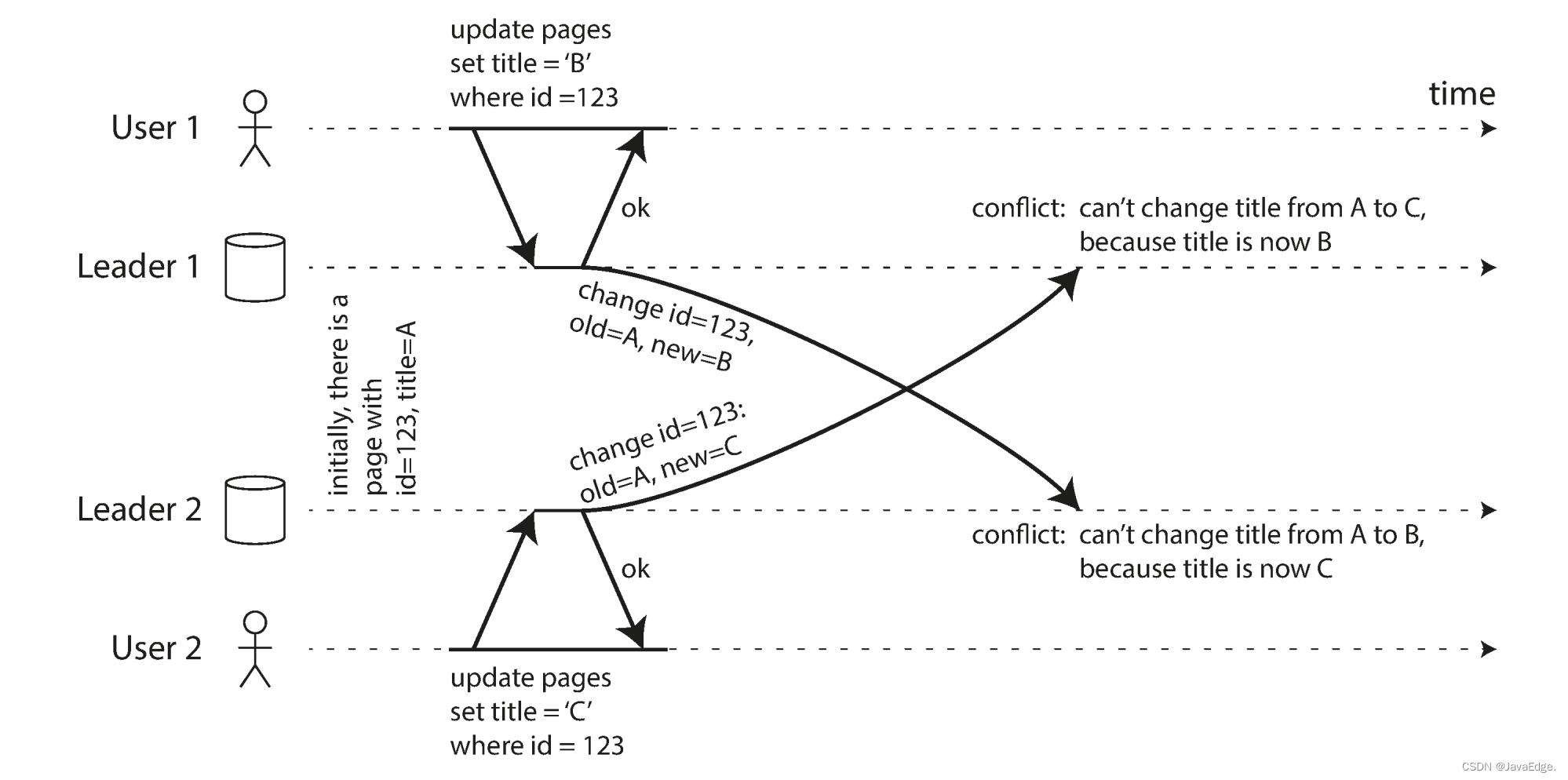
多主复制下处理写冲突(1)-同步与异步冲突检测及避免冲突
轮询和长轮询的区别

SCI writing strategy - with common English writing sentence patterns

科研笔记(八) 深度学习及其在 WiFi 人体感知中的应用(上)

复制延迟案例(3)-单调读

Andrew Ng's Machine Learning Series Course Notes - Chapter 18: Application Example: Image Text Recognition (Application Example: Photo OCR)
ftp服务的部署和优化
CaDDN paper reading of monocular 3D target detection
QT中更换OPENCV版本(3->4),以及一些宏定义的改变
随机推荐
SCI期刊最权威的信息查询步骤!
七分钟深入理解——卷积神经网络(CNN)
两端是圆角的进度条微信对接笔记
Reinforcement Learning (Chapter 16 of the Watermelon Book) Mind Map
ffmpeg视频播放、格式转化、缩放等命令
ScholarOne Manuscripts提交期刊LaTeX文件,无法成功转换PDF!
复制延迟案例(4)-一致前缀读
深蓝学院-视觉SLAM十四讲-第七章作业
强化学习(西瓜书第16章)思维导图
VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tupl
多主复制的适用场景(2)-需离线操作的客户端和协作编辑
科研笔记(八) 深度学习及其在 WiFi 人体感知中的应用(下)
EasyCVR视频广场切换通道,视频播放协议异常的问题修复
从事功能测试1年,裸辞1个月,找不到工作的“我”怎么办?
asyncawait和promise的区别
SCI writing strategy - with common English writing sentence patterns
无主复制系统(3)-Quorum一致性的局限性
Jetson Nano 2GB Developer Kit Installation Instructions
jetracer_pro_2GB AI Kit系统安装使用说明
多数据中心操作和检测并发写入