scala特点
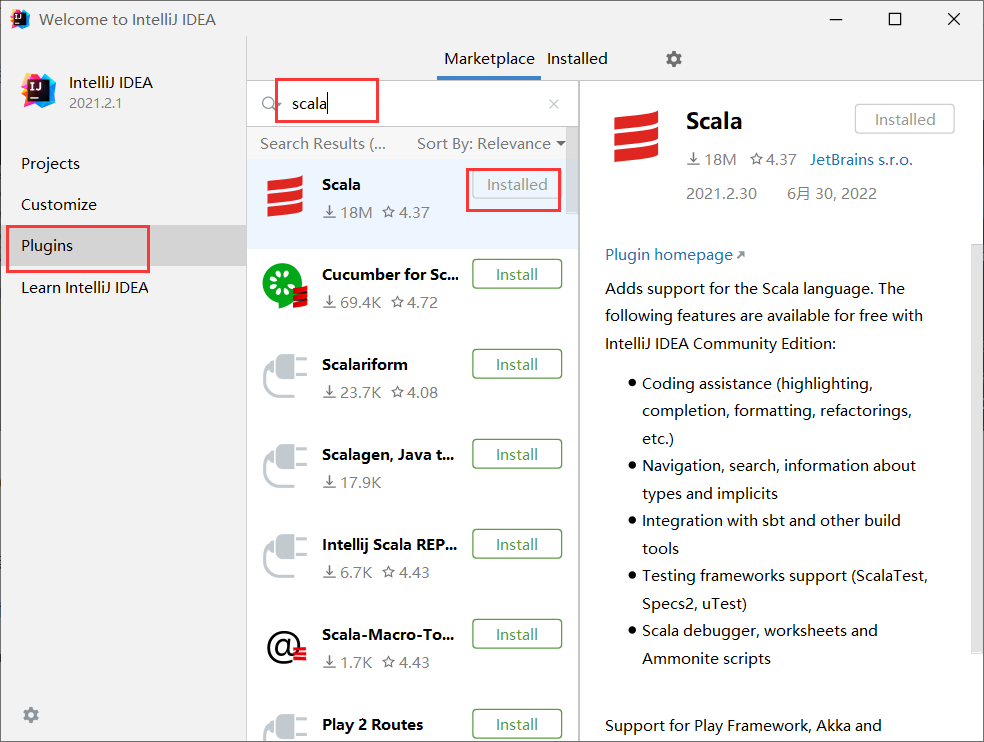
idea中下载安装scala插件
打开idea-->plugins-->搜索scala-->点击installed安装
创建scala程序
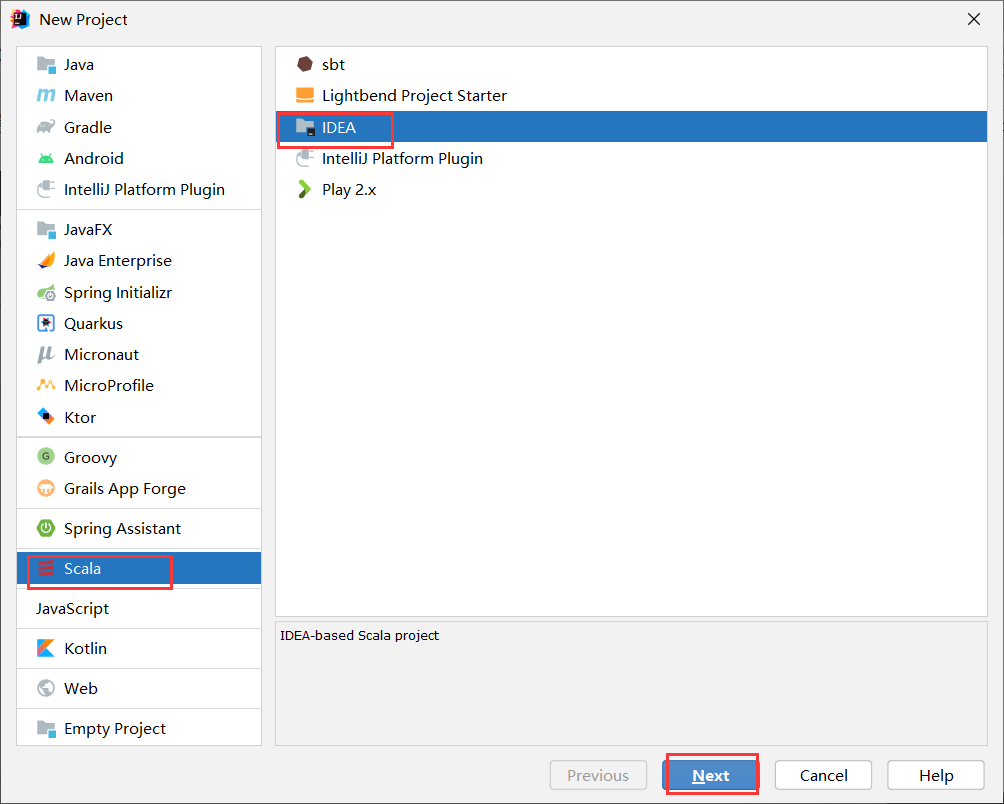
选着对应的jdk和scala-sdk进行创建:
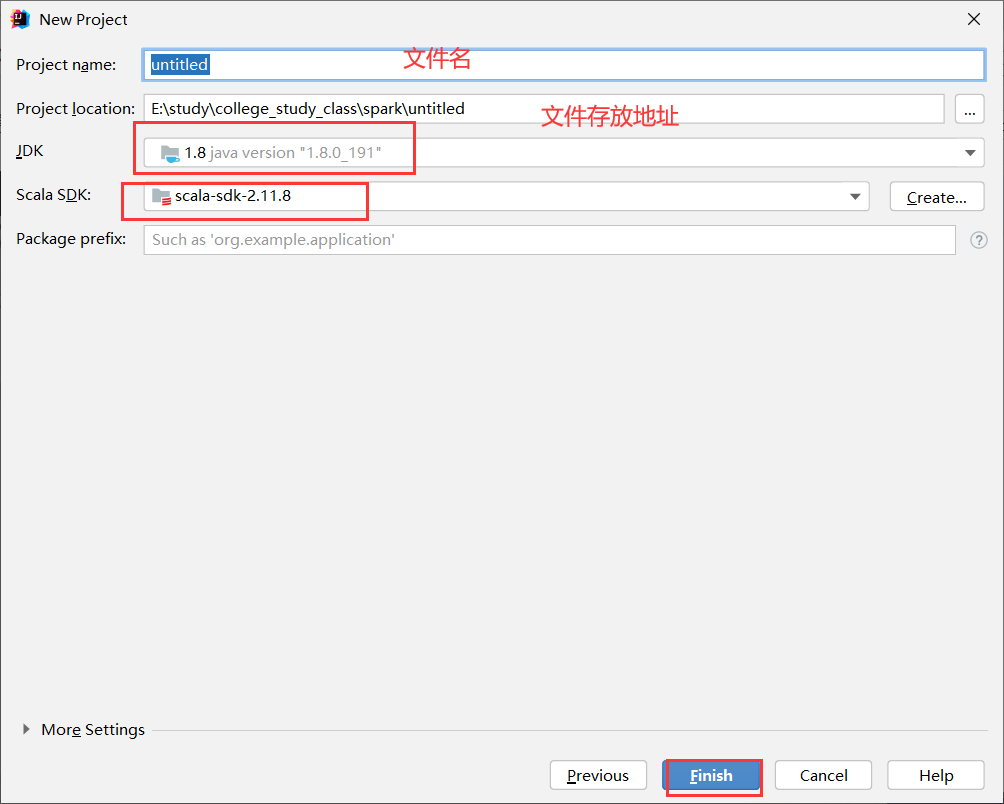
创建成功后可以看到一下目录:
我们在src文件中进行代码的编写。
scala基础语法
使用var声明的变量,值是可变的。
使用val声明的变量,也叫常量,值是不可变的。
var myVar:String = "Hello"
val age:Int = 10注意:
(1)scala中的变量在声明是必须进行初始化。
(2)声明变量时,我们可以不给出变量的类型,以内在初始化的时候,scala的类型推断机制能够更具变量初始化的值自动推算出来。
var myVar = "Hello"
val age = 102.数据类型
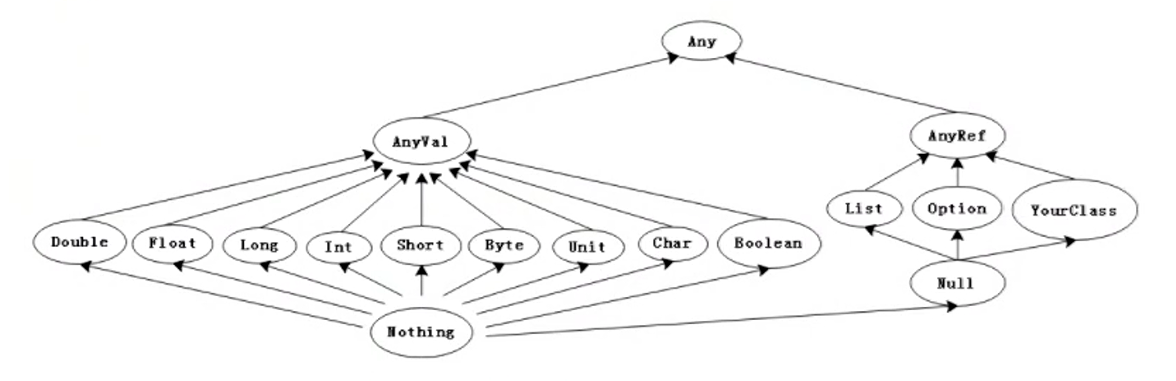
AnyRef:表示应用的类型,可以认为,除值外,所有类型都继承自AnyRef。
Nothing:所有类型的子类型,也称为底部类型。它常见的用途是发出终止信号,例如抛出异常、程序退出或无限循环。
Null:所有应用类型的额子类型,它主要用途是与其他JVM语言操作,几乎不在scala代码中使用。
scala中算术操作符(+、-、*、/、%)的作用和java是一样的,位操作符(&、|、>>、<<)也是一样的。特别强调,scala的这些操作符其实是方法。
val a = 1 val b = 2 a+b a.+(b)
scala没有提供操作符++和--。如果我们想实现递增或者递减的效果,可以使用+=1或-=1这种方式。
在scala中,控制结构语句包括条件分支语句和循环语句。
条件分支语句:
//if... if(布尔表达式){ 结果为ture,执行的语句 } //if...else... if(布尔表达式){ 结果为ture,执行的语句 }else{ 结果为false,执行的语句 } if...else if ..else.. if(布尔表达式1){ 布尔表达式1为ture,执行的语句 }else if(布尔表达式2){ 布尔表达式2为ture,执行的语句 }else if(布尔表达式3){ 布尔表达式3为ture,执行的语句 }else{ 以上结果都为false,执行的语句 } //嵌套 if(布尔表达式1){ 布尔表达式1为ture,执行的语句 if(布尔表达式2){ 布尔表达式2为ture,执行的语句 } }else if(布尔表达式3){ 布尔表达式3为ture,执行的语句 else if(布尔表达式4){ 布尔表达式4为ture,执行的语句 } }else{ 以上都为false,执行语句 }
循环语句:
scala中的for循环语句和java中的for循环语句在语法上有较大的区别。
for循环
for (变量<-表达式/数组/集合){ 循环语句; }
从0循环到9,每循环一次则将该值打印输出进行操作演示,在scala语法中,我们可以只用“0 to 9”表示,范围包含9,代码如下:
for (i <- 0 to 9){ print(i+" ") }
scala在for循环语句中可以铜鼓使用if判断语句过滤一些元素,多个过滤条件用分好分隔开。如,输入0-9范围中大于5的偶数,代码如下:
for (i <- 0 to 9; if i%2==0; if i>5){ print(i+" ") }
var x = 1while(x < 10){ print(x+" ") x += 2}do { 循环语句; }while(布尔表达式)
do...while循环语句与while循环语句的主要区别是,do...while语句的循环语句至少执行一次,代码如下:
x = 10 do{ print(x+" ") x += 1 }while (x < 20)
5.方法和函数
scala的方法是类的一部分,而函数是一个对象可以赋值给一个变量。scala中可以使用def语句和val语句定义函数,而定义方法只能使用def语句。
方法:
scala方法的定义格式如下:
def functionName([参数列表]):[return type]={ function body return [expr] }
下面,定义一个方法add,实现两个数相加就和,代码如下:
def add(a: Int, b: Int): Int={ var sum:Int = 0 sum = a + b return sum }
scala方法调用的格式如下:
//没有使用实例的对象调用格式 functionName(参数列表) //方法使用实例的对象来调用,我们可以使用类似java的格式(使用“.”号) [instance.]functionName(参数列表)
下面,在类Test中,定义一个方法addInt,实现两个整数相加求和。在这里,我们通过“类名。方法名(参数列表)”来进行调用,代码如下:
:paste //进入多行输入模式 object Test{ def addInt(a: Int, b: Int): Int={ var sum: Int = 0 sum = a + b retrun sum } } ctrl+D //退出多行输入模式 Test.addInt(4,5)
val addInt = (a: Int, b: Int) => a + b
(1)方法转换成函数:
方法转换成函数格式如下:
val f1 = m _
方法名m后紧跟一个空格和一个下划线,是为了告知编译器将方法m转换成函数,而不是要调用这个方法。下面,定义一个方法m,实现将方法m转换成函数,代码如下:
def m(x: Int, y: Int): Int = x + y //方法 val f = m _ //函数
注意:
scala方法的返回值类型可以不写,编译器可以自动推断出来,但是对于递归方法来说,必须要指定返回类型。
scala数据结构
scala提供了许多数据结构,如常见的数组、元组、集合等。
1.数组
数组(Array)主要用来存储数据类型相同的元素
1.1 数组定义与使用
scala中的数组分为定长数组和变长数组,这两种数组的定义方式如下:
new Array[T] (数组长度) //定长数组 ArrayBuffer[T]() //变长数组
注意:定义变长数组时,则需要导包import scala.collection.mutable.ArrayBuffer
下面,我们通过例子来演示scala数组简单使用,具体代码如下:
import scala.colletion.mutable.ArrayBuffer object ArrayDemo{ def main(array: Array[String]) { //import scala.collection.mutable.ArrayBuffer object ArrayDemo { def main(args: Array[String]): Unit = { // 定义定长数组:定义长度为8的定长数组,数组中的每个元素都初始化为0 val arr1 = new Array[Int](8) //打印定长数组,内容就是数组的hashcode值 println(arr1) //定义边长数组(数组缓冲),需要导入包 val ab = ArrayBuffer[Int]() //向变长数组中追加元素 ab += 1 //打印变长数组 println(ab) //向变长数组中追加多个元素 ab += (2,3,4,5) println(ab) //追加一个定长数组 ab ++= Array(6,7) println(ab) //追加一个变长数组(数组缓冲) ab ++= ArrayBuffer(8,9) println(ab) //在变长数组的某个位置插入元素 ab.insert(0,-1,0) //在0索引位置插入-1和0 println(ab) //删除数组的某个元素 ab.remove(0) println(ab) } }
1.2 数组的遍历
scala中,如果要获取数组中的每一个元素,则需要将数组进行遍历操作
文件ArrayTraversal.scala:
object ArrayTraversal { def main(args: Array[String]): Unit = { //定义定长数组 //val array = new Array[Int](8) //第一种方式 val myArr = Array(1.9, 2.9, 3.4, 3.5) //第二种方式 //打印输出数组中所有元素 for (x <- myArr){ print(x+" ") } //打印换行 println() //计算数组中所有元素的和 var total = 0.0 for (i <- 0 to (myArr.length - 1)){ total += myArr(i) } println("总和为:"+total) //查找数组中的最大元素 var max = myArr(0) for (i <- 1 to (myArr.length - 1)){ if (myArr(i) > max){ max = myArr(i) } } println("最大值:" + max) } }
1.3 数组的转换
数组转换就是通过yield
文件ArrayYieldTest.scala:
object ArrayYieldTest { def main(args: Array[String]): Unit = { //定义一个数组 val arr = Array(1, 2, 3, 4, 5, 6, 7, 8, 9) val newArr = for (e <- arr; if e % 2 ==0) yield e * 10 println(newArr.toBuffer) //将定长数组转为变长数组输出 } }
2. 元组
2.1 创建元组
创建元组语法如下:
val tuple = (元素,元素...)
创建一个包含String类型,Double类型以及int类型的元组,代码如下:
val tuple = ("itcast",3.14,65535)2.2 获取元组中的值
tuple._1 //获取第一个值 tuple._2 //获取第二个值
3.2 拉链操作
val scores = Array(88,95,80) val names = Array("zhangsan ","lisi","wangwu") names.zip(scores)
3.集合
scala中,集合有三大类:List、Set以及Map
scala集合分为可变(mutable)和不可变(immutable)的集合。
3.1 List
在scala中,List列表和数组类似,列表的所有元素都具有相同类型。这里的list默认是不可变列表,如果要定义可变列表,需要导入“impport scala.collection.mutabe.ListBuffer”包。
定义不同类型列表list,代码如下:
val = fruit:List[String] = List("apples","oranges","pears") //字符串
val nums:List[Int] = List(1, 2, 3, 4) //整型
val empty:List[Nothing] = List() //空
val dim:List[List[Int]] = List(List(1,0,0),
List(0,1,0),
List(0,0,1))在scala中,可以使用"Nil"和"::"操作符来定义列表。
val fruit = "apples"::("oranges"::("pears"::Nil)) //字符串
val nums = 1::(2::(3::(4::Nil))) //整型
val empty = Nil
val dim = (1::(0::(0::Nil))) ::
(0::(1::(0::Nil))) ::
(0::(0::(1::Nil))) :: Nilscala也提供了很多操作List的方法:
| 相关说明 | |
|---|---|
| head | 获取列表第一个元素 |
| tail | 返回除第一个之外的所有元素组成的列表 |
| isEmpty | 若列表为空,则返回ture,否则返回false |
| take | 获取列表前n个元素 |
| contains |
文件ListTest.scala:
object ListTest { def main(args: Array[String]): Unit = { //定义List集合 // val fruit2:List[String] = List("apples","oranges","pears") val fruit = "apples"::("oranges"::("pears"::Nil)) val nums = Nil //空List集合 println("Head of fruit:" + fruit.head) println("Tial of fruit:" + fruit.tail) println("Check if fruit is empty:" + fruit.isEmpty) println("Check if fruit is nums:" + nums.isEmpty) println("Tack of fruit:" + fruit.take(2)) println("Contains of fruit:" + fruit.contains("apples")) } }
3.2.Set
在scala中,Set是没有重复对象的集合,所有元素都是唯一的。默认情况下,scala使用不可变Set集合,若想使用可变的Set集合,则需要引入scala.collection.mutable.Set包。
定义Set集合的语法格式如下:
val set:Set[Int] = Set(1,2,3,4,5)
scala提供了很多操作Set集合的方法。接下来,列举一些操作Set集合的常见方法。
| 方法名称 | 相关说明 |
|---|---|
| head | 获取Set集合第一个元素 |
| tail | 返回除第一个之外的所有元素组成的Set集合 |
| isEmpty | 若Set集合为空,则返回ture,否则返回false |
| take | 获取Set集合前n个元素 |
| contains | 判断Set集合是否包含指定元素 |
定义一个Set集合site,使用常见的方法对集合site进行相关的操作,代码如下:
文件SetTest.scala:
object SetTest { def main(args: Array[String]): Unit = { //定义set集合 val site = Set("Itcast","Google","Baidu") val nums:Set[Int] = Set() println("第一个网站是:"+site.head) println("最后一个网站是:"+site.tail) println("查看集合site是否为空:"+site.isEmpty) println("查看集合nums是否为空:"+nums.isEmpty) println("查看site的前两个网站:"+site.take(2)) println("查看集合中是否包含网站Itcast:"+site.contains("Itcast")) } }
3.3 Map
定义Map集合的语法格式如下:
var A:Map[Char,Int] = Map(键 -> 值,键 ->值...) //Map键值对,键为Char,值为Int
| 方法名称 | 相关说明 |
|---|---|
| () | 根据某个键查找对应的值,类似于java中的get() |
| contains() | 检查Map中是否包含某个指定的键 |
| getOrElse() | 判断是否包含键,若包含返回对应的值,否则返回其他的 |
| keys | 返回Map所有的键(key) |
| values | 返回Map所有的值(value) |
| isEmpty | 若Map为空时,返回ture |
定义一个Map集合colors,使用Map常见的方法对集合colors进行先关操作,代码如下:
文件MapTest.scala:
object MapTest { def main(args: Array[String]): Unit = { //定义Map集合 val colors = Map("red" -> "#FF0000", "azure" -> "#F0FFFF", "peru" -> "#CD853F") val peruColo = if (colors.contains("peru")) colors("peru") else 0 val azureColo = colors.getOrElse("azure", 0) print("获取colors中键为red的值:" + colors("red")) println("获取colors中所有的键:" + colors.keys) println("获取colors中所有的值:" + colors.values) println("检测colors是否为空:" + colors.isEmpty) println("判断colors中是否包含键peru,包括含则返回对应的值,否则返回0:" + peruColo) println("判断colors中是否包含键azure,包括含则返回对应的值,否则返回0:" + azureColo) } }
scala面向对象的特征
scala是一种面向对象的语言
1. 类与对象
创建类的语法格式如下:
class 类名[参数列表]创建对象的语法格式如下:
类名 对象名称 = new 类名();//定义类 class Point(xc:Int,yc:Int){ var x:Int = xc var y:Int = yc def move(dx:Int, dy:Int): Unit = { x = x + dx y = y + dy println("x的坐标点:"+ x) println("y的坐标点:"+ y) } } object ClassTest { def main(args: Array[String]): Unit = { //定义类对象 val pt = new Point(10, 20) //移动一个新的位置 pt.move(10,10) } }
2. 继承
scala和java类似,只允许继承一个父类。不同的是,java只能继承父类中非私有的属性和方法。而scala可以继承父类中的所有属性和方法。
在scala子类继承父类的时候,有几点需要注意:
如果子类要重写一个父类中的非抽象方法,则必须使用override关键字,否则会出现语法错误。
如果紫烈要重写父类中的抽象方法时,则不需要使用override关键字。
创建一个Pt类和一个Location类,并且Location类继承Pt类,演示子类Location重写父类Pt中的字段,代码如下:
//定义父类Point类 class Pt(val xc:Int, val yc:Int){ var x:Int = xc var y:Int = yc def move(dx:Int, dy:Int): Unit = { x = x + dx y = y + dy println("x的坐标点:" + x) println("y的坐标点:" + y) } } //定义子类:Location,继承Point类 class Location(override val xc:Int, override val yc:Int, val zc:Int) extends Pt(xc, yc) { var z:Int = zc def move(dx:Int, dy:Int, dz:Int):Unit = { x = x + dx y = y + dy z = z + dz println("x的坐标点:" + x) println("y的坐标点:" + y) println("z的坐标点:" + z) } } object ExtendsTest { def main(args: Array[String]): Unit = { //创建一个子类对象:Location val loc = new Location(10, 20, 15) //移动到一个新的位置 loc.move(10,10,5) } }
3. 单例对象和伴生对象
在scala中,没有静态方法或静态字段,所以不能用类名直接访问类中的方法和字段,而是创建类的实例对象去访问类中的方法和字段。但是,scala中提供了object这个关键字用来实现单例模式,使用关键字object创建的对象为单例对象。
创建单例对象的语法格式如下:
object objextName
//创建单例对象 object SingletonObject{ def hello(): Unit = { println("Hello,This is Singleton Object") } } object Singleton { def main(args: Array[String]): Unit = { SingletonObject.hello() } }
在scala中,在一个源文件中有一个类和一个单例对象,若单例对象名与类名相同,则把这个单例对象称作伴生对象(companion object);这个类则被称为是单例对象的伴生类(companion class)。类和半身对象之间可以互相访问私有的方法和字段。
定义一个伴生对象Dog,演示操作类中的私有方法和字段。代码如下:
//创建类 //伴生类 class Dog{ val id = 666 private var name = "二哈" def printName(): Unit ={ //在Dog类中可以访问伴生对象Dog的私有字段 println(Dog.CONSTANT + name) } } //伴生对象 object Dog { //伴生对象中添加私有字段 private var CONSTANT = "汪汪汪..." def main(args: Array[String]): Unit = { val dog = new Dog dog.name = "二哈 666" dog.printName() } }
4. 特质
在scala中,Trait(特质)的功能类似于java中的接口,scala中的Trait可以被类和对象(Objects)使用关键字extends来继承。
创建特质的语法格式如下:
trait traitName
//定义特质 trait Animal{ //定义一个抽象方法(没有实现的方法) def speak() def listen(): Unit ={ } def run(): Unit ={ println("I am running") } } //定义类,继承特质 class People extends Animal{ override def speak(): Unit = { println("I am speaking English") } } object People { def main(args: Array[String]): Unit = { val people = new People people.speak() people.listen() people.run() } }
scala的模式匹配与样例类
1. 模式匹配
scala中的模式匹配是由match case组成的,它类似于java中的switch case,即对一个值进行条件判断,针对不同的条件,进行不同的处理。
表达式 match { case 模式1 => 语句1 case 模式2 => 语句2 case 模式3 => 语句3 }
定义一个方法matchTest(),方法的参数是一个整数字段,而方法的调用则是对参数进行模式匹配,若参数匹配的是1,则打印输出"one";若参数匹配的是2.则打印输出”two“,若参数匹配的是_,则打印输出"many",代码如下:
object PatternMatch { def main(args: Array[String]): Unit = { println(matchTest(1)) } def matchTest(x:Int):String = x match { case 1 => "one" case 2 => "two" case _ => "many" } }
2. 样例类
在scala中,使用case关键字来定义的类被称为样例类。样例类时一种特殊的类,经过优化可以被用于模式匹配。我们使用case定义样例类Person,并将该样例类应用到模式匹配中,代码如下:
object CaseClass { //定义样例类 case class Person(name:String, age:Int) def main(args: Array[String]): Unit = { //创建样例类对象 val alice = new Person("Alice", 25) val bob = new Person("Bob", 32) val charlie = new Person("charlie", 32) // val tom = Person("tom", 25) //使用样例类来进行模式匹配 for (person <- List(alice, bob, charlie)){ person match { case Person("Alice", 25) => println("Hi Alice") case Person("Bob", 32) => println("Hi Bob") case Person(name, age) => println("Name:" + name + "\t" + "age:" + age) } } } }



![Looting iii[post sequence traversal and backtracking + dynamic planning]](/img/9b/e9eeed138e46afdeed340bf2629ee1.png)