当前位置:网站首页>Python crawler actual combat details: crawling home of pictures
Python crawler actual combat details: crawling home of pictures
2020-11-06 01:17:00 【itread01】
Preface
The text and pictures in this article are from the Internet , Just for learning 、 Communication use , It doesn't have any commercial use , The copyright belongs to the original author , If you have any problem, please contact us in time for handling
How to use python To implement a crawler ?
- Simulation browser
Request and access to website information
Extract the information we want from the source data Data screening
Store the screened data
What tools are needed to complete a crawler
- Python3.6
- pycharm Professional version
Target site
Home of pictures
https://www.tupianzj.com/
Crawler code
Import tool
python Self contained standard library
import ssl
System library Automatically create storage folder
import os
Download the package
import urllib.request
Network Library Third party package
import requests
Web page selector
from bs4 import BeautifulSoup
Default request https The website doesn't need certificate authentication
ssl._create_default_https_context = ssl._create_unverified_context
Simulation browser
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36',
}
Automatically create a folder
if not os.path.exists('./ Illustration material /'):
os.mkdir('./ Illustration material /')
else:
pass
Request operation
url = 'https://www.tupianzj.com/meinv/mm/meizitu/' html = requests.get(url, headers=headers).text
Do data extraction for the original data of the page
soup = BeautifulSoup(html, 'lxml')
images_data = soup.find('ul', class_='d1 ico3').find_all_next('li')
for image in images_data:
image_url = image.find_all('img')
for _ in image_url:
print(_['src'], _['alt'])
Download
try:
urllib.request.urlretrieve(_['src'], './ Illustration material /' + _['alt'] + '.jpg')
except:
pass
Renderings
版权声明
本文为[itread01]所创,转载请带上原文链接,感谢
边栏推荐
- TRON智能钱包PHP开发包【零TRX归集】
- Calculation script for time series data
- 如何将数据变成资产?吸引数据科学家
- Didi elasticsearch cluster cross version upgrade and platform reconfiguration
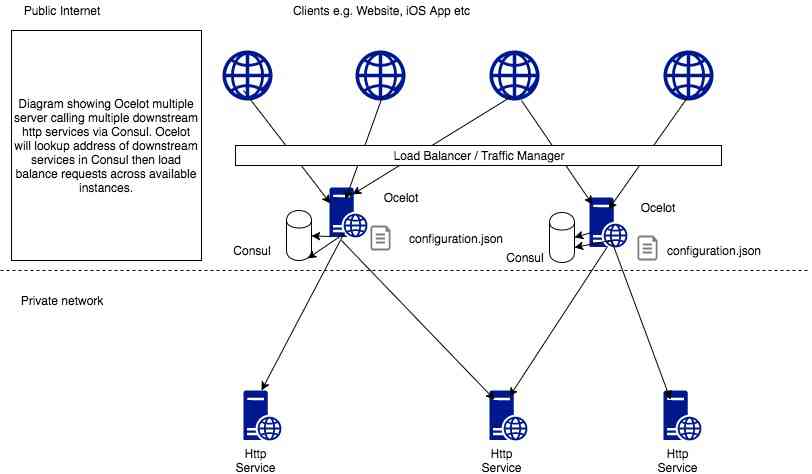
- Installing the consult cluster
- PLC模拟量输入和数字量输入是什么
- Vue 3 responsive Foundation
- Want to do read-write separation, give you some small experience
- Synchronous configuration from git to consult with git 2consul
- 有关PDF417条码码制的结构介绍
猜你喜欢


随机推荐
遞迴思想的巧妙理解
iptables基礎原理和使用簡介
Cocos Creator 原始碼解讀:引擎啟動與主迴圈
Menu permission control configuration of hub plug-in for azure Devops extension
TRON智能钱包PHP开发包【零TRX归集】
C++和C++程序员快要被市场淘汰了
Chainlink将美国选举结果带入区块链 - Everipedia
Cos start source code and creator
Serilog原始碼解析——使用方法
[C#] (原創)一步一步教你自定義控制元件——04,ProgressBar(進度條)
Query意图识别分析
容联完成1.25亿美元F轮融资
Filecoin主网上线以来Filecoin矿机扇区密封到底是什么意思
ipfs正舵者Filecoin落地正当时 FIL币价格破千来了
数据产品不就是报表吗?大错特错!这分类里有大学问
The difference between Es5 class and ES6 class
PN8162 20W PD快充芯片,PD快充充电器方案
简直骚操作,ThreadLocal还能当缓存用
快快使用ModelArts,零基礎小白也能玩轉AI!
H5 makes its own video player (JS Part 2)