当前位置:网站首页>spark调优(三):持久化减少二次查询
spark调优(三):持久化减少二次查询
2022-07-07 14:13:00 【InfoQ】
1. 起因
2. 优化开始
df = sc.sql(sql)
df1 = df.persist()
df1.createOrReplaceTempView(temp_table_name)
subdf = sc.sql(select * from temp_table_name)
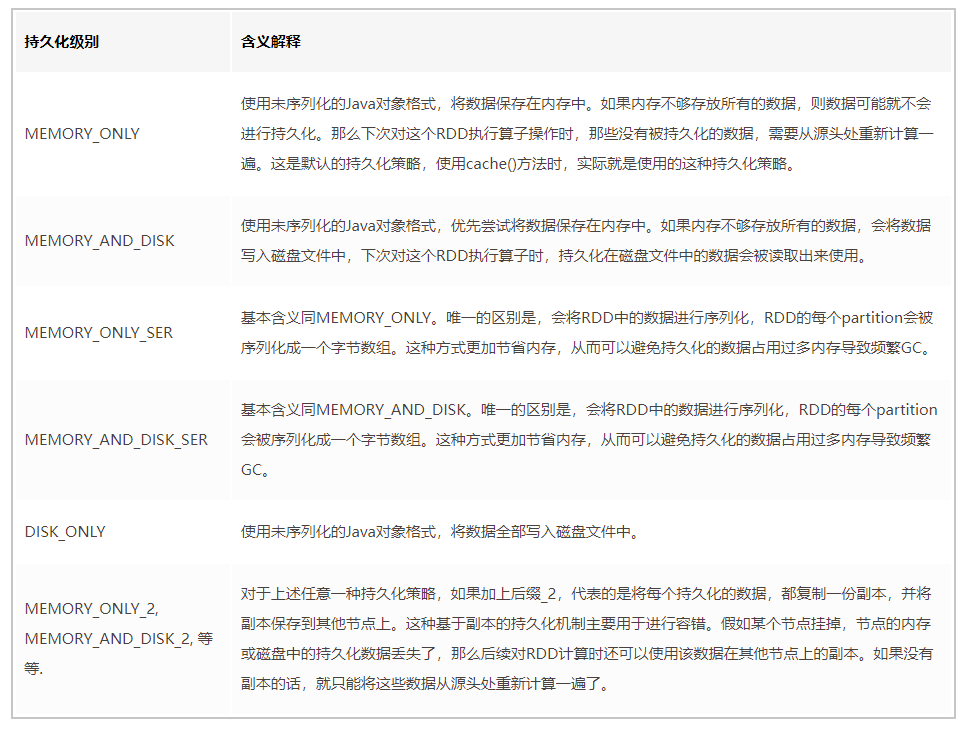
- 默认情况下,性能最高的当然是MEMORY_ONLY,但前提是你的内存必须足够足够大,可以绰绰有余地存放下整个RDD的所有数据。因为不进行序列化与反序列化操作,就避免了这部分的性能开销;对这个RDD的后续算子操作,都是基于纯内存中的数据的操作,不需要从磁盘文件中读取数据,性能也很高;而且不需要复制一份数据副本,并远程传送到其他节点上。但是这里必须要注意的是,在实际的生产环境中,恐怕能够直接用这种策略的场景还是有限的,如果RDD中数据比较多时(比如几十亿),直接用这种持久化级别,会导致JVM的OOM内存溢出异常。
- 如果使用MEMORY_ONLY级别时发生了内存溢出,那么建议尝试使用MEMORY_ONLY_SER级别。该级别会将RDD数据序列化后再保存在内存中,此时每个partition仅仅是一个字节数组而已,大大减少了对象数量,并降低了内存占用。这种级别比MEMORY_ONLY多出来的性能开销,主要就是序列化与反序列化的开销。但是后续算子可以基于纯内存进行操作,因此性能总体还是比较高的。此外,可能发生的问题同上,如果RDD中的数据量过多的话,还是可能会导致OOM内存溢出的异常。
- 如果纯内存的级别都无法使用,那么建议使用MEMORY_AND_DISK_SER策略,而不是MEMORY_AND_DISK策略。因为既然到了这一步,就说明RDD的数据量很大,内存无法完全放下。序列化后的数据比较少,可以节省内存和磁盘的空间开销。同时该策略会优先尽量尝试将数据缓存在内存中,内存缓存不下才会写入磁盘。
- 通常不建议使用DISK_ONLY和后缀为_2的级别:因为完全基于磁盘文件进行数据的读写,会导致性能急剧降低,有时还不如重新计算一次所有RDD。后缀为_2的级别,必须将所有数据都复制一份副本,并发送到其他节点上,数据复制以及网络传输会导致较大的性能开销,除非是要求作业的高可用性,否则不建议使用。
结束语
边栏推荐
- Mysql database basic operation DQL basic query
- Odoo integrated plausible embedded code monitoring platform
- Is it reliable to open an account on Tongda letter with your mobile phone? Is there any potential safety hazard in such stock speculation
- three.js打造酷炫下雪效果
- How to determine whether the checkbox in JS is selected
- Numpy -- epidemic data analysis case
- 47_ Contour lookup in opencv cv:: findcontours()
- [excelexport], Excel to Lua, JSON, XML development tool
- Limit of total fields [1000] in index has been exceeded
- laravel中将session由文件保存改为数据库保存
猜你喜欢
记一次项目的迁移过程
AE learning 01: AE complete project summary
分步式監控平臺zabbix

How does geojson data merge the boundaries of regions?

2022 the 4th China (Jinan) International Smart elderly care industry exhibition, Shandong old age Expo

【花雕体验】15 尝试搭建Beetle ESP32 C3之Arduino开发环境
C4D learning notes 1- animation - animation key frames
Unity3D_ Class fishing project, control the distance between collision walls to adapt to different models
Odoo integrated plausible embedded code monitoring platform
山东老博会,2022中国智慧养老展会,智能化养老、适老科技展
随机推荐
Three. JS introduction learning notes 12: the model moves along any trajectory line
Numpy --- basic learning notes
2022第四届中国(济南)国际智慧养老产业展览会,山东老博会
【HCSD大咖直播】亲授大厂面试秘诀-简要笔记
Mysql database basic operation DQL basic query
【知识小结】PHP使用svn笔记总结
SPI master rx time out中断
How to implement backspace in shell
prometheus api删除某个指定job的所有数据
Logback日志框架第三方jar包 免费获取
Xingruige database was shortlisted as the "typical solution for information technology application and innovation in Fujian Province in 2021"
Unity drawing plug-in = = [support the update of the original atlas]
What is the difference between IP address and physical address
Step by step monitoring platform ZABBIX
Multiplication in pytorch: mul (), multiply (), matmul (), mm (), MV (), dot ()
记一次项目的迁移过程
SysOM 案例解析:消失的内存都去哪了 !| 龙蜥技术
Good news! Kelan sundb database and Hongshu technology privacy data protection management software complete compatibility adaptation
融云斩获 2022 中国信创数字化办公门户卓越产品奖!
一个普通人除了去工厂上班赚钱,还能干什么工作?