当前位置:网站首页>走进Redis,让你重新认识redis。绝不是表面
走进Redis,让你重新认识redis。绝不是表面
2022-07-30 21:08:00 【InfoQ】
为什么要使用缓存?
为什么Redis那么快
- C语言实现,效率高(因为C是面向过程的编程语言,并且更接近底层)
- 单线程避免了多线程情况下频繁的上下文切换
- 基于非阻塞的IO复用模型机制(这有兴趣的小伙伴可以了解一下IO多路复用的机制)
- 纯内存操作
- 丰富的数据结构(hash结构、跳跃表等)
- 还有一点是:偏向 计算向数据移动
如何去理解Redis的线程模型
file event handler- 多个socket
- IO多路复用程序
- 文件事件分派器
- 事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)

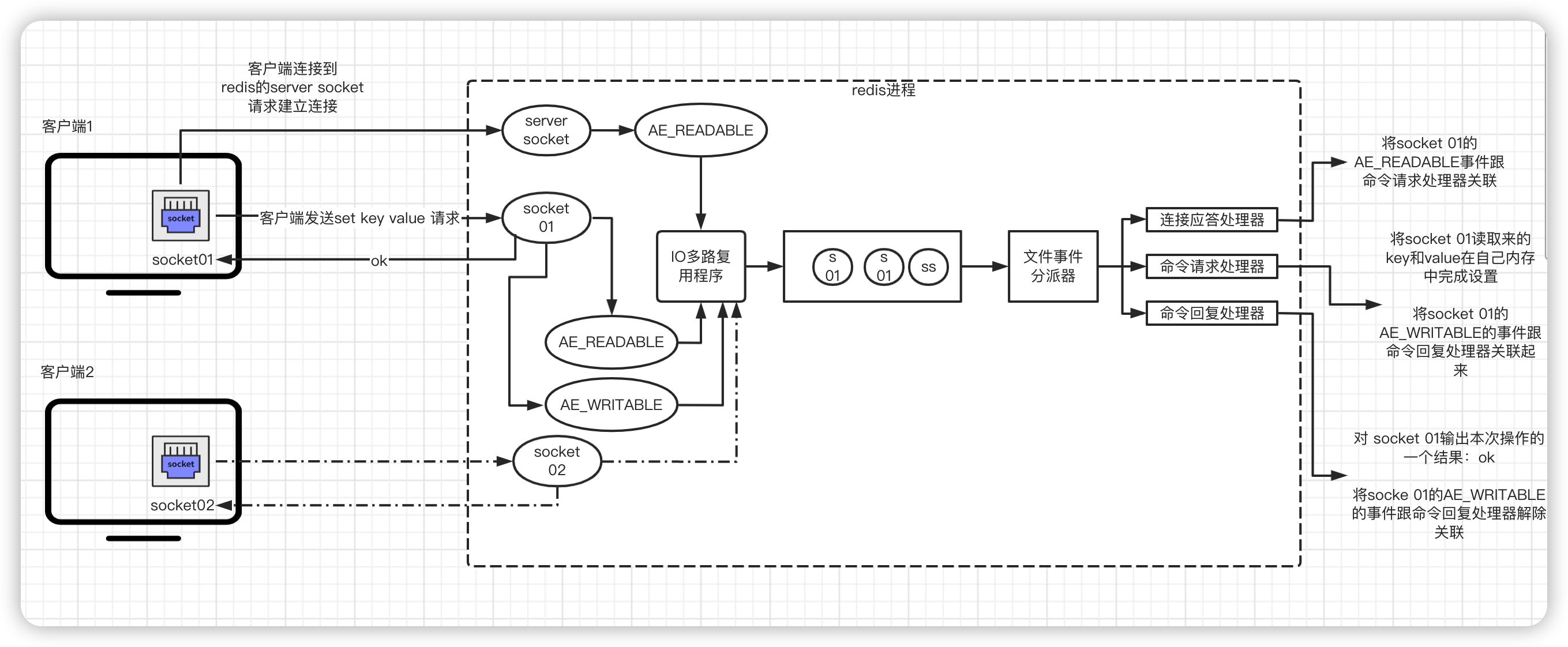
- 首先:客户端socket 01向redis 的server socket请求建立连接,此时Server Socket 会产生一个
AE_READABLE事件,IO多路复用程序监听到server socket产生的事件后,将该事件压入到队列中,文件事件分派器从队列中获取该事件交给连接应答处理器。连接应答处理器会创建一个能与客户端通信的socket 01,并将socket 01的AE_READABLE事件与命令请求处理器关联。
- 假设此时客户端发送了一个set key value的请求,此时Redis中的socket 01 会产生一个AE_READABLE事件,IO多路复用程序会将该事件压入队列中,此时事件分派器从队列中获取该事件,由于前面socke 01的AE_READABLE已经与命令请求处理器关联,因此事件分派器将事件交给命令请求处理器来处理。命令请求处理器读取socket 01的set key value 并在自己的内存中完成设置,操作完成后,它会将socket 01的AE_WRITABLE事件与命令回复处理器关联
- 如果此时客户端已经做好了接收返回结果的准备,那么Redis中的socket 01 会产生一个
AE_WRITABLE事件,同样压入队列中,事件分派器找到相关联的命令回复处理器,由命令回复处理器对socket 01 输入本次操作的一个结果,比如:ok。之后就会解除socket 01 的AE_WIRTABLE事件与命令回复处理器的关联。
- 以上就是完成了一次客户端与redis的通信
Redis 问什么要基于内存去操作数据?
硬盘:
- 寻址--毫秒ms级别的。
- 高传输带宽在传输大块连续数据时具有优势
- 高IOPS在传输小块不连续的数据时具有优势
- 磁盘的 IOPS,也就是在一秒内,磁盘进行多少次 I/O 读写。
- 磁盘的吞吐量(指的是硬盘或设备(路由器/交换机)在传输数据的时候数据流的速度即使同一块硬盘在写入不同大小的数据时、表现出来的带宽也是不同的),也就是每秒磁盘 I/O 的流量,即磁盘写入加上读出的数据的大小。
内存
- 纳秒ns级别的。秒=1000毫秒=1000*1000微妙=1000*1000*1000纳秒。在寻址上,磁盘比内存慢了10万倍。
Reids缺点:
- 由于是内存数据库,所以单台机器存储的数据量跟机器本身的内存大小有关。虽然redis本身有key过期策略,但是还是需要提前预估和节约内存。如果内存增长过快,需要定期删除数据
- 定时删除和定期删除为主动删除,Redis会定期主动淘汰一批已过去的key
- 惰性删除为被动删除,用到的时候才会去检验key是不是已过期,过期就删除过期的key
- 惰性删除是redis服务器内置策略(过期的key对aof文件没有任何影响,删除过期的key时系统会向aof文件追加一条del;如果key过期了但是没有删除,此时进行持久化操作这个key不会进入aof文件,因为没有发生修改指令)
- 如果进行完整重同步,由于需要生成rdb文件,并进行传输,会占用主机的CPU,并会消耗现网的带宽。不过redis2.8版本以后,已经有部分重同步的功能,但是还是有可能有完整重同步的。比如,新上线的从库
- 修改配置文件,进行重启,将硬盘中的数据加载进内存,时间比较久。在这个过程中,redis不能提供服务。
为什么使用Redis而不选择Memcache呢?
- Redis 和 Memcache 都是将数据存放在内存中,都是内存数据库。不过 Memcache 还可用于缓存其他东西,例如图片、视频等等
- Memcache 仅支持key-value结构的数据类型,Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,hash等数据结构的存储。
- 虚拟内存– Redis 当物理内存用完时,可以将一些很久没用到的value 交换到磁盘
- 分布式–设定 Memcache 集群,利用 magent 做一主多从; Redis 可以做一主多从。都可以一主多从
存储数据安全– Memcache 挂掉后,数据没了; Redis 可以定期保存到磁盘(持久化)
Memcache 的单个value最大 1m , Redis 的单个value最大 512m。
灾难恢复– Memcache 挂掉后,数据不可恢复; Redis 数据丢失后可以通过 aof 恢复
Redis 原生就支持集群模式, Redis3.0 版本中,官方便能支持Cluster模式了, Memcached 没有原生的集群模式,需要依赖客户端来实现,然后往集群中分片写入数据。
- Memcached 网络IO模型是多线程,非阻塞IO复用的网络模型,原型上接近于 nignx 。而 Redis使用单线程的IO复用模型,自己封装了一个简单的 AeEvent 事件处理框架,主要实现类epoll,kqueue 和 select ,更接近于Apache早期的模式。
为什么要使用缓存?
为什么Redis那么快
- C语言实现,效率高(因为C是面向过程的编程语言,并且更接近底层)
- 单线程避免了多线程情况下频繁的上下文切换
- 基于非阻塞的IO复用模型机制(这有兴趣的小伙伴可以了解一下IO多路复用的机制)
- 纯内存操作
- 丰富的数据结构(hash结构、跳跃表等)
- 还有一点是:偏向 计算向数据移动
如何去理解Redis的线程模型
file event handler- 多个socket
- IO多路复用程序
- 文件事件分派器
- 事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
- 首先:客户端socket 01向redis 的server socket请求建立连接,此时Server Socket 会产生一个
AE_READABLE事件,IO多路复用程序监听到server socket产生的事件后,将该事件压入到队列中,文件事件分派器从队列中获取该事件交给连接应答处理器。连接应答处理器会创建一个能与客户端通信的socket 01,并将socket 01的AE_READABLE事件与命令请求处理器关联。
- 假设此时客户端发送了一个set key value的请求,此时Redis中的socket 01 会产生一个AE_READABLE事件,IO多路复用程序会将该事件压入队列中,此时事件分派器从队列中获取该事件,由于前面socke 01的AE_READABLE已经与命令请求处理器关联,因此事件分派器将事件交给命令请求处理器来处理。命令请求处理器读取socket 01的set key value 并在自己的内存中完成设置,操作完成后,它会将socket 01的AE_WRITABLE事件与命令回复处理器关联
- 如果此时客户端已经做好了接收返回结果的准备,那么Redis中的socket 01 会产生一个
AE_WRITABLE事件,同样压入队列中,事件分派器找到相关联的命令回复处理器,由命令回复处理器对socket 01 输入本次操作的一个结果,比如:ok。之后就会解除socket 01 的AE_WIRTABLE事件与命令回复处理器的关联。
- 以上就是完成了一次客户端与redis的通信
Redis 问什么要基于内存去操作数据?
硬盘:
- 寻址--毫秒ms级别的。
- 高传输带宽在传输大块连续数据时具有优势
- 高IOPS在传输小块不连续的数据时具有优势
- 磁盘的 IOPS,也就是在一秒内,磁盘进行多少次 I/O 读写。
- 磁盘的吞吐量(指的是硬盘或设备(路由器/交换机)在传输数据的时候数据流的速度即使同一块硬盘在写入不同大小的数据时、表现出来的带宽也是不同的),也就是每秒磁盘 I/O 的流量,即磁盘写入加上读出的数据的大小。
内存
- 纳秒ns级别的。秒=1000毫秒=1000*1000微妙=1000*1000*1000纳秒。在寻址上,磁盘比内存慢了10万倍。
Reids缺点:
- 由于是内存数据库,所以单台机器存储的数据量跟机器本身的内存大小有关。虽然redis本身有key过期策略,但是还是需要提前预估和节约内存。如果内存增长过快,需要定期删除数据
- 定时删除和定期删除为主动删除,Redis会定期主动淘汰一批已过去的key
- 惰性删除为被动删除,用到的时候才会去检验key是不是已过期,过期就删除过期的key
- 惰性删除是redis服务器内置策略(过期的key对aof文件没有任何影响,删除过期的key时系统会向aof文件追加一条del;如果key过期了但是没有删除,此时进行持久化操作这个key不会进入aof文件,因为没有发生修改指令)
- 如果进行完整重同步,由于需要生成rdb文件,并进行传输,会占用主机的CPU,并会消耗现网的带宽。不过redis2.8版本以后,已经有部分重同步的功能,但是还是有可能有完整重同步的。比如,新上线的从库
- 修改配置文件,进行重启,将硬盘中的数据加载进内存,时间比较久。在这个过程中,redis不能提供服务。
为什么使用Redis而不选择Memcache呢?
- Redis 和 Memcache 都是将数据存放在内存中,都是内存数据库。不过 Memcache 还可用于缓存其他东西,例如图片、视频等等
- Memcache 仅支持key-value结构的数据类型,Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,hash等数据结构的存储。
- 虚拟内存– Redis 当物理内存用完时,可以将一些很久没用到的value 交换到磁盘
- 分布式–设定 Memcache 集群,利用 magent 做一主多从; Redis 可以做一主多从。都可以一主多从
存储数据安全– Memcache 挂掉后,数据没了; Redis 可以定期保存到磁盘(持久化)
Memcache 的单个value最大 1m , Redis 的单个value最大 512m。
灾难恢复– Memcache 挂掉后,数据不可恢复; Redis 数据丢失后可以通过 aof 恢复
Redis 原生就支持集群模式, Redis3.0 版本中,官方便能支持Cluster模式了, Memcached 没有原生的集群模式,需要依赖客户端来实现,然后往集群中分片写入数据。
- Memcached 网络IO模型是多线程,非阻塞IO复用的网络模型,原型上接近于 nignx 。而 Redis使用单线程的IO复用模型,自己封装了一个简单的 AeEvent 事件处理框架,主要实现类epoll,kqueue 和 select ,更接近于Apache早期的模式。
边栏推荐
猜你喜欢

C语言中指针没那么难~ (1)【文章结尾有资料】

Outsourcing worked for three years, it was abolished...

nVisual网络可视化管理平台功能和价值点
Image Restoration by Estimating Frequency Distribution of Local Patches

Niu Ke Xiaobaiyue Race 53 A-E
【深度学习】对迁移学习中域适应的理解和3种技术的介绍
2022-07-29 mysql/stonedb慢SQL-Q17-分析

深度学习模型训练前的必做工作:总览模型信息

Deep Non-Local Kalman Network for VideoCompression Artifact Reduction

Typescript 严格模式有多严格?
随机推荐
深入浅出边缘云 | 3. 资源配置
MySQL60题作业
用于视频压缩伪影消除的深度卡尔曼滤波网络
mysql deadlock
MySQL8重置root账户密码图文教程
[Nuxt 3] (十三) Nuxt 是如何工作的?
MySQL Workbench 安装及使用
MySQL笔记2(函数,约束,多表查询,事务)
bgp路由过滤
JDBC(详解)
Flink_CDC搭建及简单使用
HJ85 longest palindrome substring
js堆和栈
弹性盒子模型
LeetCode·每日一题·952.按公因数计算最大组件大小·并查集
【深度学习】对迁移学习中域适应的理解和3种技术的介绍
牛客小白月赛53 A-E
Motion Tuned Spatio-temporal Quality Assessmentof Natural Videos
Apache DolphinScheduler新一代分布式工作流任务调度平台实战-上
【限时福利】21天学习挑战赛 - MySQL从入门到精通