当前位置:网站首页>探索Cassandra的去中心化分布式架构
探索Cassandra的去中心化分布式架构
2022-07-07 04:16:00 【守护石】
关系型模型之父Edgar F. Codd,在1970年Communications of ACM 上发表了《大型共享数据库数据的关系模型》,成为了永恒的经典,关系模型的语义设计易于理解,语法上嵌套、闭环、完整,因此在数据库领域,关系模型普及与流行了数年之久。
在此之后,IT世界涌现了很多非常著名的RDBMS(关系型数据库系统),包括了Oracle、MySQL、SQLServer、DB2、PostgreSQL等。
1. 传统关系型数据库的分布式瓶颈
但是RDBMS的技术发展由于架构上的限制,遇到了很多问题,例如:关系模型的约束必须在设计前明确定义好属性,这就难以像很多NoSQL一样,具有灵活可变的模式,很难适应敏捷迭代的需要。
其实最难解决的一个问题,就是数据表的分布式化。
为什么会导致如此现象呢?
本质上,由于关系模型在前期设计上的强关联,导致表表之间的连接关系变得极为紧密。
例如:有一种比较普遍的业务场景中连接操作,通过A->B->C的关联查找,然而这种关联所形成的链,就将A、B、C紧密地捆绑在了一起。
那么这种紧密关系带来了什么问题呢?
那就是RDBMS在设计之初,很难去考虑到数据表在分布式网络环境中的通讯解耦设计,而只是单纯的数据表本地文件的IO扫描,而且在过去低带宽的网络环境中,模型关系的分布式化,更是难以想象。
如下图所示:
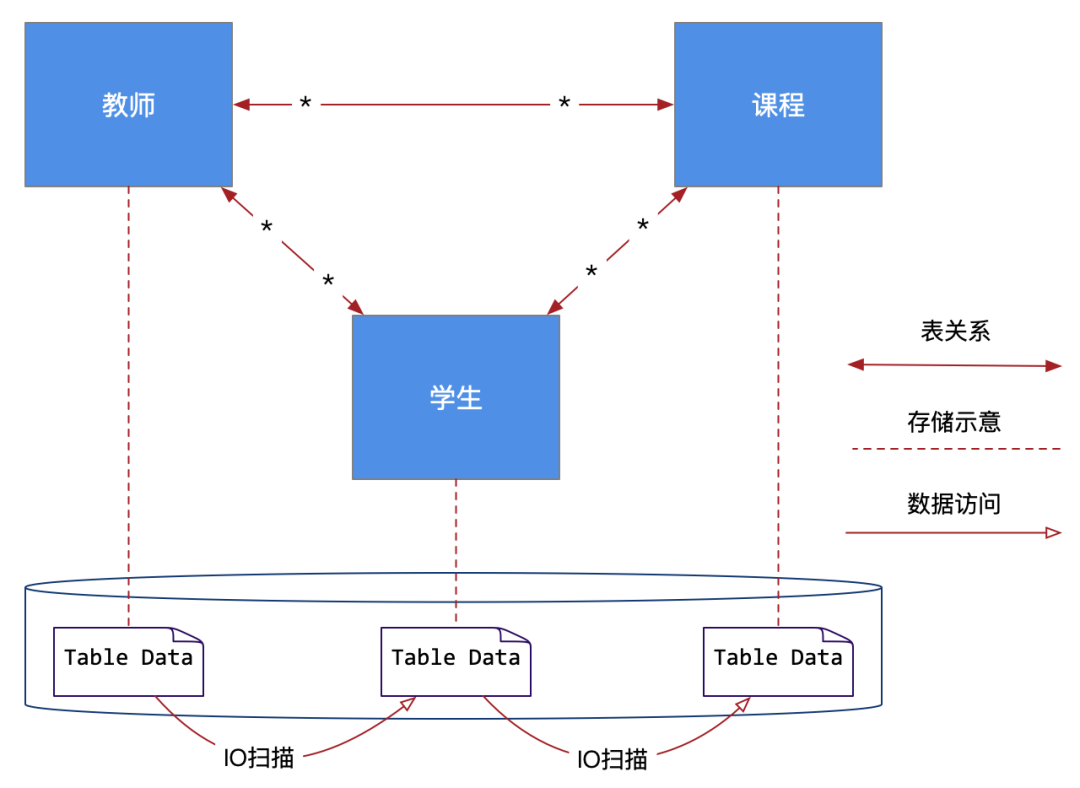
我们从上图可以看到,教师、学生和课程这三张表具有多对多的紧密关系(其中还有一些未展示的中间表),那么这种紧密的关系投射到具体的数据库物理文件上,就是图中多个物理上的表文件(Table Data),当我们查询时,就是通过关系逻辑对这些表文件进行了频繁的IO扫描。
在这种模式下,我们会发现一个问题,这些表实际上很难跨数据库而分布式拆分,也就是说,RDBMS很难以分布式形式,把教师表放到服务器1的数据库1上,学生表放到服务器2的数据库2上,课程表放到服务器3的数据库3上。
而且更难做到的是:将1万名学生总共10万次课程活动所产生的学生上课数据分拆成10个1万条数据表,再将表分布在不同的数据库中。
如下图所示:
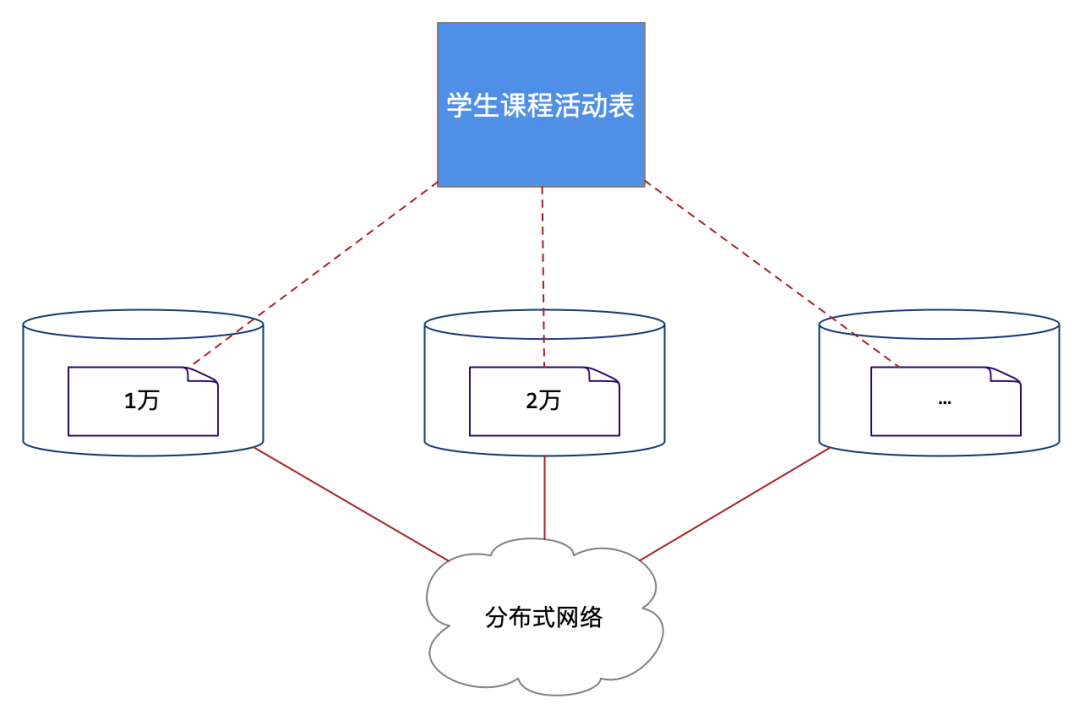
我们提出一个假设:如果能将学生课程活动表拆分到分布式网络中多个数据库实例当中,那么就极大地降低了单台数据库的负载。这对于访问量和数据量已经规模化的应用系统来说至关重要。
然而对于RDBMS来说,这种假设的目标实现是一件非常痛苦且困难的事情,例如:我们可以在网上搜索到大量关于MySQL分库分表的文章,这类文章的主题都是在对RDBMS进行分布式化的分区操作。
但是这种操作并非数据库天然所支持,必须组建专业的数据工程师团队,耗费大量的时间对数据库进行精密地调节,必须自己去解决分布式集群的诸多问题,例如:容错、复制、分区、一致性、分布式事务等等,其难度可想而知,所以这不是一般技术企业所能承担的巨大维护成本。
随着互联网时代的发展,互联网应用系统面向高并发、海量数据的规模化趋势愈演愈烈,RDBMS对于数据表进行分布式化的瓶颈也越来越明显,这也就促成了NoSQL在互联网等领域快速发展,接下来我们重点看看NoSQL的解决方案。
2. 中心化分布式架构的弊端
2.1 Hadoop分布式文件系统(HDFS)
谈到大数据领域的分布式数据库体系,必然绕不开Hadoop,Hadoop实际上是一个系统生态,基于Hadoop生态的各种分布式数据库都依赖于一个数据底座——HDFS,其实最早Google发明了GFS分布式文件系统之后,进行了论文发表,然后在开源界才产生了Hadoop分布式文件系统(HDFS)。
如下图所示:GFS/HDFS的特点表现在顺序的、成块的、无索引的向文件块中写入数据,并在集群环境中按块(block)均匀分布存储,需要使用时,再通过MapReduce、Spark这些批处理引擎发起并行任务,按块,批次地读取分析。这样就把写入和并行读取的性能发挥到了极致,具备了任何建立索引的数据库都无法比拟的读写速度。
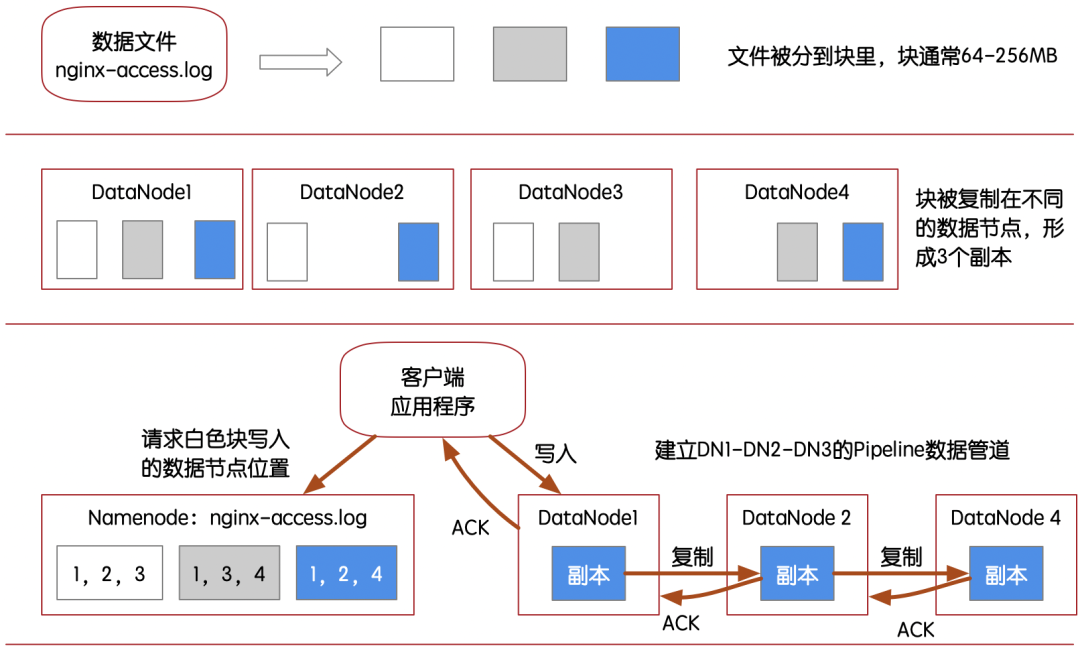
HDFS在对多个数据节点(DataNode)协调写入数据的过程中,一定是由一个中心化的服务进行了全局调度,那就是NameNode节点。
也就是说NameNode节点会是一个单点风险,若出现了故障,整个HDFS分布式文件系统集群就会出现崩溃。
因此HDFS为了NameNode的高可用(HA),实现了极为复杂的NameNode HA架构。
但是,在同一时刻,只可能有一个NameNode为所有数据的写入提供调度支撑,也就是说从并发负载的角度,NameNode始终会是一个瓶颈。
由于HDFS是整个Hadoop生态的数据底座,那么Hadoop的分布式架构就始终围绕在分布式中心化的路线上前进,然而中心化架构最大的问题就在于无论上层建筑如何变化,传导到数据底座后,HDFS作为中心管理者,一定会在高并发、大规模访问情况下成为瓶颈。
另外从集群节点的伸缩扩展方面也有隐患,问题来自于元数据在NameNode内存中可能会出现溢出。
2.2 大规模结构化的分布式数据库(HBase)
然而HDFS是面向成块的大文件数据,无索引地追加读写,也就不具有数据随机查找能力,另外缺少结构化设计机制,像集合的数据项扫描、统计和分析就无法独立支撑,必须构建上层数据库系统合作来完成,因此就产生了鼎鼎大名的HBase。
如下图所示:我们可以从图中看到HBase的数据底座完全依赖HDFS,也就是说数据如何物理上分布是由HDFS所决定。
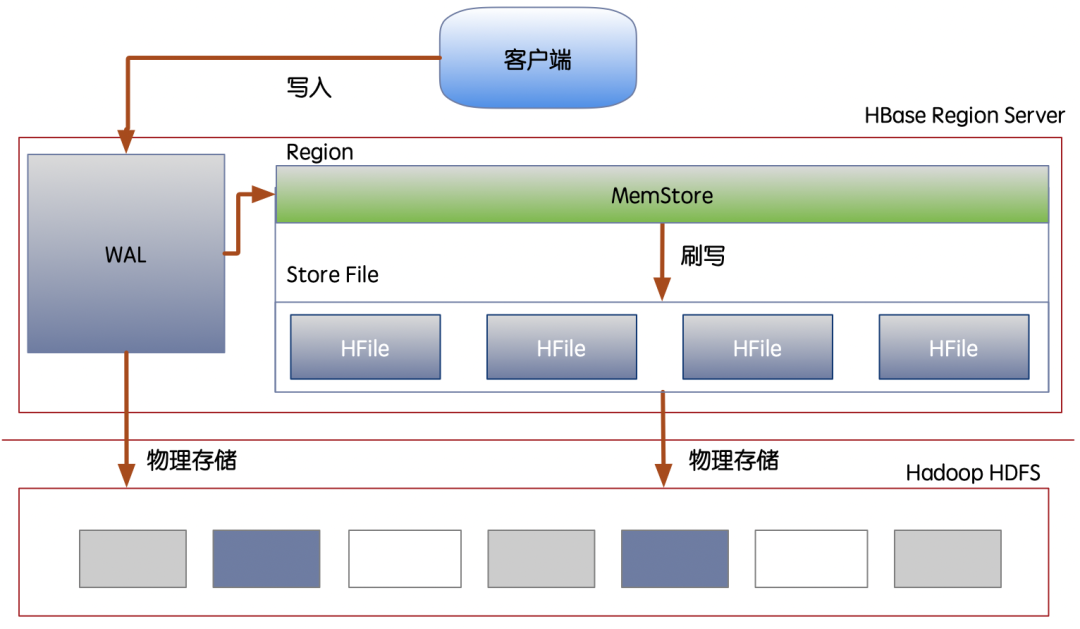
HBase实现了全局排序的K-V模型,满足海量数据的存放条件下通过行键定位结果,能达到毫秒级响应的数据库,或者通过主键排序扫描实现了统计分组。
尽管HBase对于大规模结构化数据的写入、排序扫描和聚合分析有着巨大的性能优势,但是HBase的查找设计目标并不是解决二次索引的大范围查找。
我们再看HBase完成数据切分的办法——Region切分,当Region(我们可以理解为数据表)追加数据超出阀值后,就要进行Region拆分,然后拆分出的新Region分布到别的RegionServer中。
这里有两个问题:
1)同一时刻向Region写入新数据的服务器必须是唯一的,那么这里就会出现RegionServer的高并发访问瓶颈。
2)由于分布式架构设计上的约束,使得HBase不具有二级索引,在随机查找过程中,只能根据全局的Region排序进行扫描,这就无法承载Web应用的数据随机查找的实时性。
因此HBase一般会作为大规模数据流形式导入的OLAP系统。
3. 去中心化分布式架构解析
那么到底有没有一种面向海量的结构化数据存储,可以实现大规模Web应用支撑的分布式数据库架构呢?
既能突破RDBMS的数据表在分布式过程中的瓶颈,又能解决Hadoop/HBase在高可用性问题上的隐患,同时还能满足高并发、大规模、大范围的随机查找要求。
答案是有的!
就是那篇改变互联网发展进程的论文《Dynamo: Amazon's Highly Available Key-value Store》,这篇论文源自于Amazon,对于自家数据库的架构设计的经验总结。
鼎鼎大名的分布式开源数据库Cassandra在分布式设计方面也完全继承了这篇论文的设计思想,只不过在数据模型方面又借鉴了Google BigTable的数据模型。
Cassandra分布式核心思想就是去中心化,形成了分布式系统世界的独特一面。
我们重点就是去解析这种去中心化的分布式架构的一些核心技术,到底有多么厉害,为什么可以解决我们前面所述的三个问题:
- 支撑大规模的结构化数据
- 解决数据表的分布式读写存放
- 满足高并发、大规模、大范围的随机查找。
3.1 什么是去中心化?
去中心化不同于中心化的核心特质在于任一服务实例在集群网络中都是以级别对等、点对点的形式存在,这就不存在服务节点在集群中的等级划分,也就是说,任何一个Cassandra服务节点,从维护者的角度都是一样的角色,那么这就极大降低了维护者运维的复杂性。
例如:我们对于Cassandra数据库的所有节点都可以称之为数据节点,集群中承担了相同的角色。
但是HBase/HDFS就不一样了,HDFS集群分为:NameNode、DataNode、JournalNode、ZKFC、Zookeeper等承担了集群的不同角色;HBase集群又分为:HMaster、HRegionServer、Zookeeper等承担了集群的不同角色。
从维护者的角度,肯定是集群角色统一的情况下更易于维护。
去中心化的另外一个特点就是高可用性非常好,伸缩性也很好,集群扩展几乎是无限制的。
对于没有一个中心节点进行调度的情况下,又能保证如此优异的高可用性、伸缩性,那么它是怎么做到的呢?
从原理上Cassandra主要表现为四个方面的特征:
- 利用一致性哈希环机制实现数据的分区分布和扩容缩容的数据迁移。
- 利用gossip协议在对等节点的网络传播下保持集群状态一致性。
- 利用anti-entropy(反熵)机制实现数据读取过程中节点之间的比对,保证数据一致性。
- 基于hinted handoff机制,按照最终一致性的模式,可以极大提升集群可用性。
以上这些特征都是集群中网络节点在对等条件下,基于共识机制,而非管理调度所形成的状态协同。
在这种机制之下,集群就具有的非常优异的高可用性以及伸缩性,也就是说,对于整个集群来讲,无论是扩容增加了很多网络节点,还是突然故障减少了很多网络节点,网络节点间的关系都是弱关联,也就难以对其它节点形成健康影响,对于用户几乎是无感知的。
从去中心化的特点,我们再对比一下HBase以及所依赖的Hadoop HDFS,这种基于中心化的集中式调度管理,HBase就存在HMaster的集群单点故障风险,因此一般HBase的HMaster可以有一个或多个HA热备,尽管引入HA后的HBase集群依然很健壮,只是必然引入更高的部署复杂度,底层依赖的HDFS NameNode HA在服务部署复杂性方面则更甚之。
而增加分布式系统的复杂性只会带来更复杂和不确定的运维问题。
3.2 分区机制
Cassandra在实现去中心化架构的过程中,关键应用目标就是在结构化数据的大规模写入能力的基础之上,还能支撑大范围的海量数据的随机查找,这点就完全区别于HBase了,事实上HBase是对于OLAP业务场景的支撑上做到了一种分布式极致的表现。
但是Cassandra则完全进入到了另一种状态,那就是对于大规模的OLTP业务实现了强力支撑,可以在毫秒级、秒级、亚秒级的范围承诺读、写以及分布式事务的SLA(服务级别协议)。
一致性Hash环
如下图所示:Cassandra的分布是基于一致性哈希所形成的环状结构。
每个节点就好像分布在一个环形上。每个节点都是对等的,在读写过程中,每个节点面对客户端都是协调节点,并与其他所有节点直接形成单跳,这也是Amazon Dynamo论文中关键的分布式架构设计。
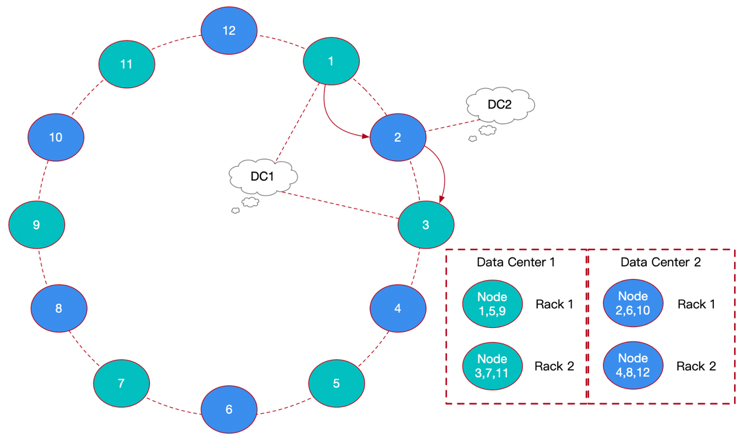
从上图中我们可以看到12个节点分布在Data Center1,Data Center2两个数据中心的四个机架(Rack)上,并通过DynamoDB集群的一致性哈希环联系在了一个分布式数据库中。
上图是数据写入过程的示例,首个副本定位在节点1(DC1,Rack1)上,然后第二个副本就会继续顺着环寻找,并定位在节点2(DC2,Rack1)上,最后第三个副本就需要在DC1中优先寻找到Rack2的节点位置,正好定位在节点3(DC1,Rack2)上。 通过环顺时针寻找定位,三个副本在DC1、DC2中分别存放,在DC1的Rack1、Rack2上交替存放。
通过使用这种跨数据中心(DC)的副本配置机制,使集群具有了更强的容灾能力,对大型应用平台的支撑也更具均衡负载和高可用优势;同一个DC的数据副本会在不同Rack节点上交替存放,以便巩固数据在集群分布的安全性。
那么进行了这种Hash分区之后,从均衡负载的角度将又带来哪些优势呢?我们接着看。
均衡负载案例
如下图所示:这是一个互联网医疗平台的应用场景。
我们应用了Cassandra,对表进行了复合主键设计,Group为Hash分区键,id为排序键。
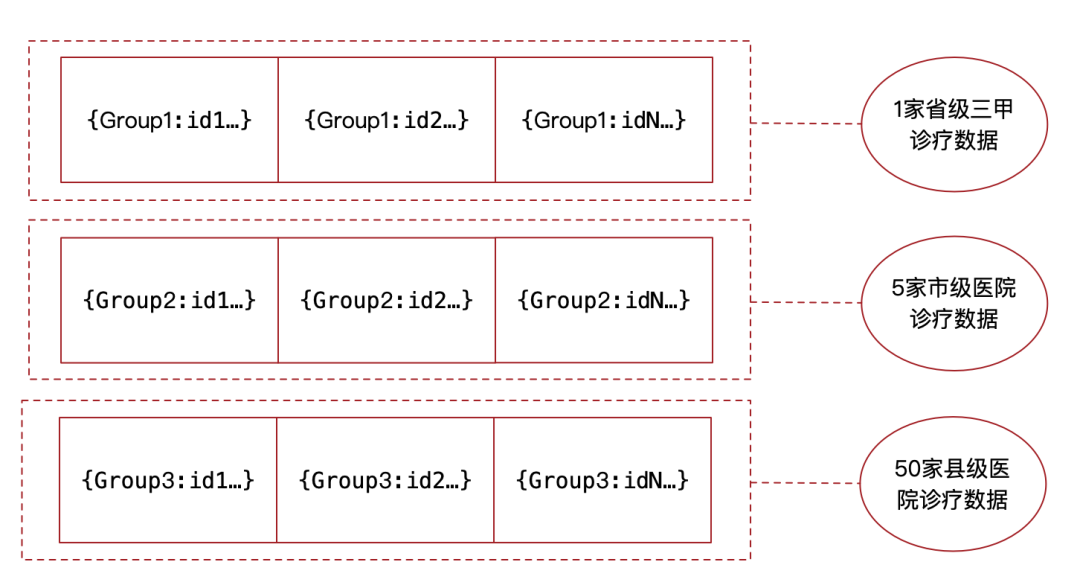
由于我们在Cassandra中存储了很多家医院的大量医生与患者之间的诊疗数据,传统RDBMS诊疗表会存在单点写入,无法进行均衡负载的瓶颈。
但是Cassandra的这种Hash分区则不同,我们可以将诊疗数据分区到3台不同的数据节点上进行读写,其中设置访问量最大的1家三甲医院的Hash分区键为Group1,5家市级医院的访问量足以对标省级三甲医院,将此5家组成Hash分区键Group2,其他50家县级医院的访问量也形成了足够的访问量,组成Hash分区键Group3。
那么通过Hash分区形式,就可以对所有诊疗数据按照医院分组的形式进行了数据切分,均衡负载到了3台服务器的Cassandra数据节点当中。
其次我们使用诊疗号(id)作为排序键,只要是同一分区的诊疗数据,无论是扫描哪一家医院的诊疗数据,都可以根据id进行排序扫描,基于排序数据也更易于统计分析。
故障转移
如下图所示:在一致性哈希环中我们设置了4个节点,那么哈希范围就被定义为:Node1-Node2,Node2-Node3,Node3-Node4,Node4-Node1。
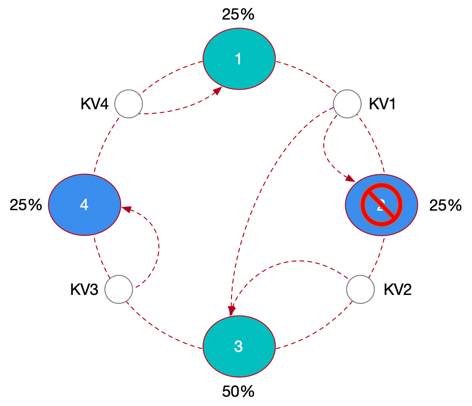
只要KV数据的主键Hash值落在某个范围内,就会顺时针找到范围尾部的节点落地。可是问题来了,节点2因为故障下线,通过备份机制我们可以将节点2的数据还原回来,但根据一致性哈希算法,只能转移到节点3上,那么节点3就承载了整个集群50%的数据量,这显然就出现数据分布的严重倾斜了。
因此Cassandra在一致性Hash的基础上又增加了虚拟节点,例如:Cassandra的默认分区策略就会创建1024个虚拟节点(Token),将-2^63~2^63-1的范围值进行平均切分,这1024个Token又被平均分配给这4个节点,这就形成了所有节点在一致性哈希环中交替且均匀出现的现象,这样如果再出现上述图中的故障,故障节点2上的副本数据就不会在恢复的时候,全压在节点3上,而是在节点1、3、4上平均地消化掉。
总之
Cassandra使用分区键进行Hash分区实现了数据在不同数据节点中的均衡负载,又通过改进型的一致性Hash算法与结构,使得数据节点无论是扩容还是缩容,都使得集群整体数据的变化迁移很小,而且还优雅地形成了多数据中心的异地容灾机制。
我们在看待Cassandra的核心优势上,就在于去中心化的这种对等节点所形成的大规模数据访问的均衡性,以及伸缩性的低成本维护特性,其实本质上,它们都是非常有利于云厂商形成无服务化的分布式数据库服务。
3.3 一致性
Amazon Dynamo论文的初衷是创建一个最终一致性的分布式数据库系统,但是同样也支持分布式的强一致性。
同样,对于Cassandra的应用,我不建议将强一致性作为主要应用考虑层面,因为强一致性对于网络带宽,客户端请求延时都有较大的资源消耗以及不可预估的问题。
那么什么是分布式的一致性呢?
CAP定理
我们在研究和应用分布式架构的过程中,对于CAP理论是必须作为基础概念去强化理解的。
CAP:一致性(Consistency),可用性(Availability)和分区容错性(Partition Tolerance)。
我可以这样去理解CAP:对于集群系统,网络分区无法访问的现象在将来是必然会发生的,当发生故障的时间里,正好要进行着一个分布式业务,例如多副本复制,就一定会出现不同节点的数据不一致。
那么我们为了保证分区容错性,我们只能有两种选择:
第一种情况就是等待故障的节点分区恢复,否则就不给客户端反馈,证明我们保证了强一致性。
第二种情况就是不等故障节点分区恢复了,先返回客户端当前已经写入完成的消息,等故障节点恢复后,再自行恢复数据,证明我们保证了高可用性。
因此当分区需要容错的情况下,我们只有CP或者AP两种选项。
对于高可用性系统,我们重点保证AP;对于强一致性系统,我们重点保证CP(HBase就是强一致性设计)。
一致性方法对比
我们前面说了,Cassandra主要满足最终一致性,也就是说当数据写完一个节点或复制不超过集群副本数量一半,写入成功的结果就可以反馈客户端,因此,复制未全部完成的期间,很可能其他节点或另一半的节点还在为另一个客户端的读取提供过期的数据。
其实Cassandra还有一种叫QUORUM级别的一致性,只有超过一半的节点写入成功后才反馈客户端成功,同样读取的时候也必须超过一半的节点一致才返回读取结果,那么读写一旦产生交集,客户端始终读取到的数据是写入成功的数据,其实这种模式是在最终一致性和强一致性之间最佳的一种平衡。
如下图所示:

上图第一种情况就是Cassandra的QUORUM级别,读取副本时,必须读取3个节点,如果3个节点是不一致的,它必须等待最后一个旧的节点被复制成功,3个节点才会一致,才能返回结果。
上图第二种情况就是典型的最终一致性了,这是个写入不到一半节点就返回成功的案例,当第一个客户端写入节点成功返回后,在没有复制到另一半节点的情况下,第二个客户端可能读取到数据依然是两外2个节点的过期数据。
总之
最终一致性必然带来了更少的网络资源消耗,也降低了网络分区出错的不可预估性,提升了集群的高可用性。但是可能会读取过期的数据。
那么什么样的应用场景会适合最终一致性呢?其实最常见的一个场景就是:购物车!
购物车可能在很小的几率情况下,读取到自己过期的数据,但是并不影响用户的最终使用体验,因为购物车并不是电商流程的终点,但一定是最频繁操作的业务之一,而最终只有订单确定了才算数。
同样像:社交网络、游戏、自媒体、物联网都是这种情况,这种规模化的联机数据业务,并不一定非得要保证读写的强一致性,一旦出现读写不一致,也许再访问一次,数据就是正确了,但是集群保证了在大规模访问场景下快速地响应客户,在这一点上,具有RDBMS无法比拟的天然优势。
4. 最后
分布式去中心化架构思想不仅应用于海量规模的结构化数据的分布式数据库系统,其实在其他领域也有应用。
例如:作为内存字典的Redis也具有Redis Cluster这种去中心化的分布式架构,Redis Cluster的主要价值也是为了更好的负载高并发的业务,例如:秒杀、抢单,完全可以先在Redis Cluster中完成,再同步到RDBMS当中。
但是无论是Redis Cluster,还是Cassandra,作为去中心化的分布式架构,都离不开为了维护集群节点对等的状态一致性,使用了类似病毒传播的Gossip协议,从一定程度,会给集群网络带来比较大的状态传播压力,另外基于共识的协议,如果集群网络节点出现步调不一致故障,对于运维人员的排查判断也会造成诸多不便。
作为云技术厂商对于去中心化的集群状态维护能力是远远大于普通企业团队或个人的,因此对于去中心化的集群架构,我更建议两种应用场景:
1)对于普通小团队的小型项目,进行小规模集群应用,可以考虑部署Cassandra集群,维护非常方便,也能快速支撑起一些海量数据查询业务,例如:很多政府类型与科研类型的项目。
2)对于具有一定数据规模量,且访问并发量较大的中大型的互联网项目,可以考虑直接上云,使用云厂商提供的Cassandra服务,因为集群中的节点数量较多的情况下,故障率会同步提升,但自主运维并不是一件容易的事情。
无论你会怎么选,作为分布式去中心化架构下的数据库,为我们在互联网应用业务的规模化发展支撑上,提供了一种很不错的选择。
本文原创,转载文章,务必联系作者!
边栏推荐
- Leetcode-206. Reverse Linked List
- [performance pressure test] how to do a good job of performance pressure test?
- C language (high-level) data storage + Practice
- leetcode:105. 从前序与中序遍历序列构造二叉树
- 242. Bipartite graph determination
- Wx is used in wechat applet Showtoast() for interface interaction
- BGP experiment (1)
- 测试周期被压缩?教你9个方法去应对
- @component(““)
- How do I get the last part of a string- How to get the last part of a string?
猜你喜欢
numpy中dot函数使用与解析
记一个并发规则验证实现
机器人技术创新与实践旧版本大纲
English translation is too difficult? I wrote two translation scripts with crawler in a rage
四、高性能 Go 语言发行版优化与落地实践 青训营笔记
After the interview, the interviewer roast in the circle of friends

IO stream file

How can a 35 year old programmer build a technological moat?

Outsourcing for four years, abandoned
【webrtc】m98 screen和window采集
随机推荐
Live broadcast platform source code, foldable menu bar
海思芯片(hi3516dv300)uboot镜像生成过程详解
[semantic segmentation] - multi-scale attention
【Unity】物体做圆周运动的几个思路
Is the test cycle compressed? Teach you 9 ways to deal with it
IO stream file
L'externalisation a duré trois ans.
按键精灵采集学习-矿药采集及跑图
242. Bipartite graph determination
My ideal software tester development status
深度学习花书+机器学习西瓜书电子版我找到了
Mutual conversion between InputStream, int, shot, long and byte arrays
07_ Handout on the essence and practical skills of text measurement and geometric transformation
Model application of time series analysis - stock price prediction
外包幹了三年,廢了...
微信小程序中使用wx.showToast()进行界面交互
【性能压测】如何做好性能压测?
【斯坦福计网CS144项目】Lab4: TCPConnection
After 95, Alibaba P7 published the payroll: it's really fragrant to make up this
Six methods of flattening arrays with JS