当前位置:网站首页>深度学习中数据到底要不要归一化?实测数据来说明!
深度学习中数据到底要不要归一化?实测数据来说明!
2022-08-03 11:31:00 【GIS与Climate】
在做超分这种回归类的模型时候,对于数据要不要做标准化预处理,网上也没个专业的说法,令人头大。

CV里面一般的图像都是0-255的范围,这个比较好处理了,不好进行标准化就直接除以255进行归一化,但是在其他领域的话,有时候数据集的极差比较大,比如降雨这种。

那么,在深度学习中处理图像数据的时候,到底要不要对数据进行标准化?
下面记录一些自己的实验。
测试
按照控制变量法的原理来做,其他的参数都不进行调整,只调整2个部分:
是否对输入数据(X)做标准化? 是否在网络中加入BN层?
模型使用FSRCNN(之前文章复现过),按照上面两个变量的组合,一共有4种情况,分别进行试验。
1. 既不做标准化,也不加BN层
对输入数据不做任何处理,直接扔进网络,效果GG,直接没算出来loss:
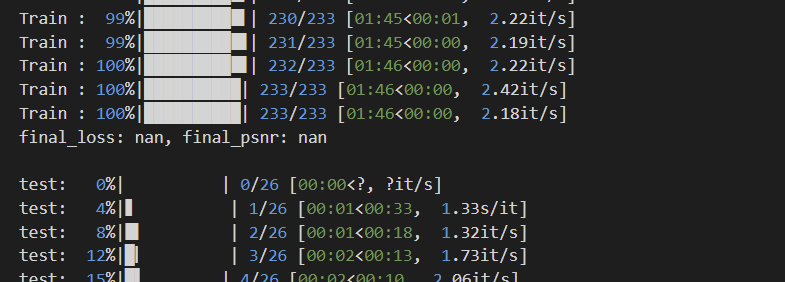
感觉是loss太大,溢出了。
2. 对X做标准化,不加BN层
对X做标准化处理,模型中不加BN层,loss直接算不出来,GG:
3. 不对X做标准化,加上BN层
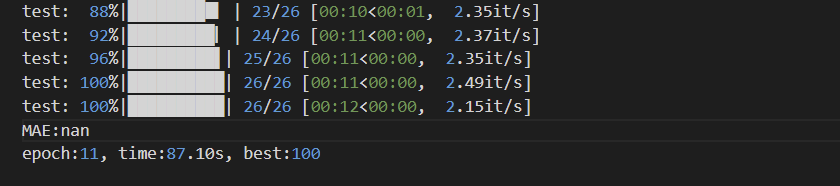
不对输入的X做任何处理,仅在模型的卷积层后加上BN层,其效果如下:
训练100个epoch的误差曲线:
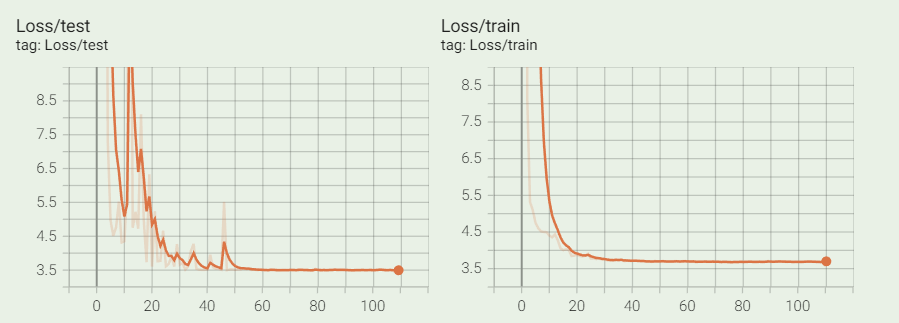
看起来是正常的,没有问题。
4. 对X做标准化,且加上BN层
对输入的X数据做标准化(减去mean,除以std),且在模型中加上BN层。
结果显示第一个epoch可以计算出loss,但是验证集的loss非常的大:
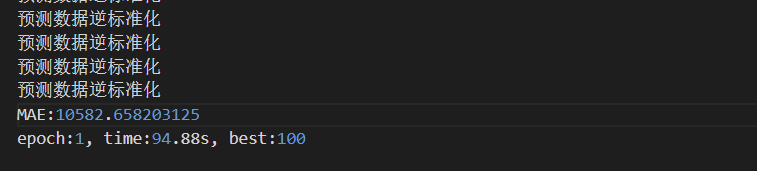
可以说完全超出了可接受的程度。
GG。
补充测试
上面的测试中发现,如果对输入的X做了标准化,最后的loss就会很大。考虑到仅对输入的X做了标准化,并没有对Y做,所以补充下对Y也做标准化的测试(均值和方差就直接用X的)。
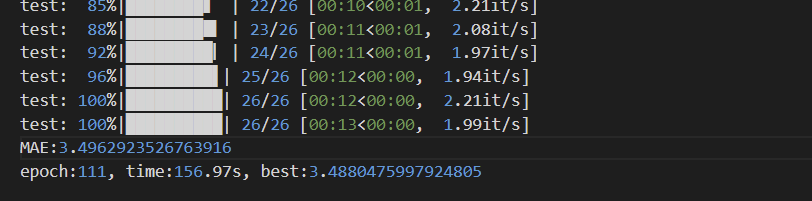
5. 对X和Y都做标准化,不加BN层
对输入的X和Y都进行标准化,但是模型中不加BN层,训练集的loss相比之前不对Y进行标准化的测试小了很多:
误差是正常的,跟上面不对输入X做处理,模型中加上BN层的误差差不多,但是收敛的更快了。
6. 对X和Y都做标准化,加上BN层
用同样的mean和std对X和Y做标准化,且模型中加上BN层,效果如下:
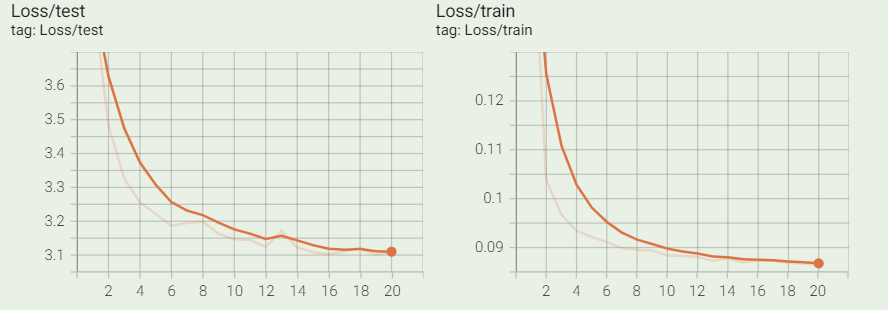
可以看到收敛的更快,误差跟不加差不多。
总结
通过上面的几个测试可以发现:
如果不对输入数据做任何处理的情况下,模型中加入BN层,有助于正确计算loss和使得模型收敛,但是收敛速度要慢一点; 如果要对输入数据做预处理,根据上面的测试结果,是需要对X和Y都做相同的处理才可以得到理想的结果; BN层可以提升模型的效果; 对X和Y做合理的预处理也可以提升模型的效果。
思考与个人感悟
为什么对输入数据做标准化有助于提升模型的效果,且为什么应该对X和Y做同样的处理?
上面我测试的案例是一个回归问题,且X和Y的数值范围相差不大。如果用地理学的角度来解释,个人觉得深度学习模型学习的是一种end-to-end的映射关系,存在一个尺度问题,如果只对X或者Y做预处理,会使得两端的空间(指的是特征空间)差异变大,需要学习的映射就会变得更加的隐晦。而同时对X和Y进行预处理,压缩了这种特征空间的变异性,所以使得要被学习到的映射变得简单了,或者说变的更加的“可视化”。
举个例子。就好比:
(1)在用google earth看地球(漫游)的时候,如果你的视野高度放的很高(根据目标的不同,选一个合同的视野高度),你确实可以看到两个地方的宏观差异,但是细节差异看不清楚(对应的就是对X和Y都不做预处理的情况,这时候的模型效果就会很差,因为关注的是细节信息);
(2)如果只对X或者Y做预处理,就好比两个人同时在google earth上进行漫游,但是一个人视野高度特别低,一个视野高度特别高,这时候就算两个人同时将视野聚焦于同一个城市/地区,两者看到的纹理也是不一样的,这种情况就不好进行对比(对应上面只对X做预处理,不对Y做,这时候模型效果也很差,因为无法建立起有效的联系);
(3)同时对X和Y做标准化的情况就好比固定了视野高度,且高度合适,不至于视野高度太高导致需要看的目标区域太大,看不清楚细节;又不至于视野高度太低,导致看到的细节太多。要知道细节太多,需要学习的映射就越复杂,学习的难度也会更高(对应上面对X和Y都做同样的预处理)。
为什么加入BN层有助于提升效果?
个人认为可以把BN层看作是一个(特征)尺度固定器,当两个end的特征空间差异过大的时候,将其简化;当差异过小的时候,就把尺度放大一点,有助于模型“看清”差异,起到了提升模型效果的作用。
根据上面的实验来看,看来深度学习跟人脑一样啊。。。越简单的映射学习起来越得心应手,如果太过于复杂的映射,可能就得多在模型上下功夫了。
(上面写的仅是针对个人案例的测试,其他的还是要按照通用做法来进行,比如机器学习中如果特征的尺度差异过大,肯定是必须要进行归一化的等等)

参考
【1】https://machinelearningmastery.com/how-to-improve-neural-network-stability-and-modeling-performance-with-data-scaling/
【2】https://inside-machinelearning.com/en/why-and-how-to-normalize-data-object-detection-on-image-in-pytorch-part-1/
【3】https://towardsdatascience.com/why-data-should-be-normalized-before-training-a-neural-network-c626b7f66c7d
【4】https://datascience.stackexchange.com/questions/22776/is-it-valuable-to-normalize-rescale-labels-in-neural-network-regression
边栏推荐
猜你喜欢

GET 和 POST 有什么区别?
![[Detailed explanation of binary search plus recursive writing method] with all the code](/img/51/c4960575a59f8ca7f161b310e47b27.png)
[Detailed explanation of binary search plus recursive writing method] with all the code
2022年五面蚂蚁、三面拼多多、字节跳动最终拿offer入职拼多多
CDH6.3.2开启kerberos认证

码率vs.分辨率,哪一个更重要?
VRRP协议的作用及VRRP+OSPF配置方法
Classical Architecture and Memory Classification of Embedded Software Components

后台图库上传功能

优维低代码:Provider 构件
【多线程的相关内容】
随机推荐
【LeetCode—第2题 两数之和 代码详解 】附有源码,可直接复制
记住用户名案例(js)
完全背包问题
最牛逼的集群监控系统,它始终位列第一!
LeetCode-1161. 最大层内元素和
Machines need tokens more than people
ERC20通证标准是什么?
云原生 Dev0ps 实践
LeetCode刷题笔记:622.设计循环队列
日常开发写代码原则
LyScript implements memory stack scanning
Objective - C code analysis of the deep and shallow copy
The effects of the background and the Activiti
[LeetCode—Question 2 Sum of Two Numbers Detailed Code Explanation ] The source code is attached, which can be copied directly
小身材有大作用——光模块寿命分析(二)
Polymorphism in detail (simple implementation to buy tickets system simulation, covering/weight definition, principle of polymorphism, virtual table)
矩阵的计算[通俗易懂]
Cookie和Session使用
【无标题】函数,对象,方法的区别
3分钟实现内网穿透(基于ngrok实现)