当前位置:网站首页>高考分数线爬取
高考分数线爬取
2022-07-02 12:08:00 【jidawanghao】
import json
import numpy as np
import pandas as pd
import requests
import os
import time
import random
class School:
school_id:""
type:""
name:""
province_name:""
city_name:""
f211:""
f985:""
dual_class_name:""
#院校历年数据
#先循环获取每一页中的院校id,再从院校id进行准备的历年数据获取
def get_one_page(page_num):
heads={'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'}#请求头,这个还是可以懂的
url='https://api.eol.cn/gkcx/api/?access_token=&admissions=¢ral=&department=&dual_class=&f211=&f985=&is_doublehigh=&is_dual_class=&keyword=&nature=&page=%s&province_id=&ranktype=&request_type=1&school_type=&signsafe=&size=20&sort=view_total&top_school_id=[766,707]&type=&uri=apidata/api/gk/school/lists'
list=[]
df_all = pd.DataFrame()
for i in range(1, page_num): # 这个不用说了吧,用 i 来取代页码,从1到143
response = requests.get(url % (i), headers=heads) # 这个也不用说了,得到一个数据
print(response.text)
json_data = json.loads(response.text) # 获得json数据,不懂得可以百度,我也是复制大神的
#print(json_data)
# try: 这个用法百度一下,防止出错程序不往下运行
my_json = json_data['data']['item'] # 获得josn 数据的根目录
for my in my_json: # 做个循环,提取学校id 和学校名字
ss=School()
ss.school_id=my['school_id']
ss.name = my['name']
ss.province_name = my['province_name']
ss.city_name = my['city_name']
if my['f211']==1:
ss.f211=1
else: ss.f211=0
if my['f985']==1:
ss.f985=1
else: ss.f985=0
if my['dual_class_name']=="双一流":
ss.dual_class_name=1
else: ss.dual_class_name=0
ss.type=my['type_name']
li = {my['school_id']: my['name']} # 每个学校的id 和学校组成一个字典的键值对\
#2021
urlkzx = 'https://static-data.eol.cn/www/2.0/schoolprovinceindex/2021/%s/35/2/1.json' # 构造真是网址,
res = requests.get(urlkzx % (my['school_id']), headers=heads) # 得到数据,school_id来自于上一次爬取学校名称的循环
print(my['school_id'])
json_data=json.loads(res.text)
print(json_data)
if json_data!='':
data=json_data['data']['item'][0]
df_one = pd.DataFrame({
'学校id':my['school_id'],
'学校名称': ss.name,
'省份': ss.province_name,
'城市名称': ss.city_name,
'双一流': ss.dual_class_name,
'f985': ss.f985,
'f211': ss.f211,
'学校类型': ss.type,
'年份': data['year'],
'批次': data['local_batch_name'],
'类型': data['zslx_name'],
'最低分': data['min'],
'最低名次': data['min_section'],
'批次分数': data['proscore'],
}, index=[0])
print(df_one)
df_all = df_all.append(df_one, ignore_index=True)
#2020
urlkzx = 'https://static-data.eol.cn/www/2.0/schoolprovinceindex/2020/%s/35/2/1.json' # 构造真是网址,
res = requests.get(urlkzx % (my['school_id']), headers=heads) # 得到数据,school_id来自于上一次爬取学校名称的循环
print(my['school_id'])
json_data = json.loads(res.text)
if json_data != '':
data = json_data['data']['item'][0]
df_one = pd.DataFrame({
'学校id': my['school_id'],
'学校名称': ss.name,
'省份': ss.province_name,
'城市名称': ss.city_name,
'双一流': ss.dual_class_name,
'f985': ss.f985,
'f211': ss.f211,
'学校类型': ss.type,
'年份': data['year'],
'批次': data['local_batch_name'],
'类型': data['zslx_name'],
'最低分': data['min'],
'最低名次': data['min_section'],
'批次分数': data['proscore'],
}, index=[0])
print(df_one)
df_all = df_all.append(df_one, ignore_index=True)
#2019
urlkzx = 'https://static-data.eol.cn/www/2.0/schoolprovinceindex/2019/%s/35/2/1.json' # 构造真是网址,
res = requests.get(urlkzx % (my['school_id']), headers=heads) # 得到数据,school_id来自于上一次爬取学校名称的循环
print(my['school_id'])
json_data = json.loads(res.text)
if json_data != '':
data = json_data['data']['item'][0]
df_one = pd.DataFrame({
'学校id': my['school_id'],
'学校名称': ss.name,
'省份': ss.province_name,
'城市名称': ss.city_name,
'双一流': ss.dual_class_name,
'f985': ss.f985,
'f211': ss.f211,
'学校类型': ss.type,
'年份': data['year'],
'批次': data['local_batch_name'],
'类型': data['zslx_name'],
'最低分': data['min'],
'最低名次': data['min_section'],
'批次分数': data['proscore'],
}, index=[0])
print(df_one)
df_all = df_all.append(df_one, ignore_index=True)
#2018
urlkzx = 'https://static-data.eol.cn/www/2.0/schoolprovinceindex/2018/%s/35/2/1.json' # 构造真是网址,
res = requests.get(urlkzx % (my['school_id']), headers=heads) # 得到数据,school_id来自于上一次爬取学校名称的循环
print(my['school_id'])
json_data = json.loads(res.text)
if json_data != '':
data = json_data['data']['item'][0]
df_one = pd.DataFrame({
'学校id': my['school_id'],
'学校名称': ss.name,
'省份': ss.province_name,
'城市名称': ss.city_name,
'双一流': ss.dual_class_name,
'f985': ss.f985,
'f211': ss.f211,
'学校类型': ss.type,
'年份': data['year'],
'批次': data['local_batch_name'],
'类型': data['zslx_name'],
'最低分': data['min'],
'最低名次': data['min_section'],
'批次分数': data['proscore'],
}, index=[0])
print(df_one)
df_all = df_all.append(df_one, ignore_index=True)
return df_all
#院校信息数据
def detail(page_num):
heads = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'} # 请求头,这个还是可以懂的
url = 'https://api.eol.cn/gkcx/api/?access_token=&admissions=¢ral=&department=&dual_class=&f211=&f985=&is_doublehigh=&is_dual_class=&keyword=&nature=&page=%s&province_id=&ranktype=&request_type=1&school_type=&signsafe=&size=20&sort=view_total&top_school_id=[766,707]&type=&uri=apidata/api/gk/school/lists'
list = []
d2 = pd.DataFrame()
for i in range(1, page_num): # 用 i 来取代页码
response = requests.get(url % (i), headers=heads) # 得到一个数据
print(response.text)
json_data = json.loads(response.text) # 获得json数据
my_json = json_data['data']['item'] # 获得josn 数据的根目录
for my in my_json: # 做个循环,提取学校id 和学校名字
ss = School()
ss.school_id = my['school_id']
ss.name = my['name']
ss.province_name = my['province_name']
ss.city_name = my['city_name']
if my['f211'] == 1:
ss.f211 = 1
else:
ss.f211 = 0
if my['f985'] == 1:
ss.f985 = 1
else:
ss.f985 = 0
if my['dual_class_name'] == "双一流":
ss.dual_class_name = 1
else:
ss.dual_class_name = 0
ss.type = my['type_name']
li = {my['school_id']: my['name']} # 每个学校的id 和学校组成一个字典的键值对
# 2021
urlkzx = 'https://static-data.eol.cn/www/2.0/schoolprovinceindex/2020/%s/35/2/1.json' # 构造真是网址,
res = requests.get(urlkzx % (my['school_id']), headers=heads) # 得到数据,school_id来自于上一次爬取学校名称的循环
print(my['school_id'])
json_data = json.loads(res.text)
print(json_data)
if json_data != '':
data = json_data['data']['item'][0]
df2 = pd.DataFrame({
'学校id': my['school_id'],
'学校名称': ss.name,
'省份': ss.province_name,
'城市名称': ss.city_name,
'双一流': ss.dual_class_name,
'f985': ss.f985,
'f211': ss.f211,
'学校类型': ss.type,
}, index=[0])
print(df2)
d2 = d2.append(df2, ignore_index=True)
return d2
def get_all_page(all_page_num):
print(all_page_num)
# 存储表
df_all1 = pd.DataFrame()
# 调用函数
df_all = get_one_page(page_num=all_page_num)
# 追加
df_all1 = df_all1.append(df_all, ignore_index=True)
time.sleep(5)
return df_all1
def getdetail(all_page_num):
print(all_page_num)
# 存储表
d1 = pd.DataFrame()
# 调用函数
d2 = detail(page_num=all_page_num)
# 追加
d2 = d2.append(d1, ignore_index=True)
time.sleep(5)
return d2
df_school = get_all_page(100)
dd=getdetail(100)
df_school.to_excel('data.xlsx', index=False)
dd.to_excel('dd.xlsx', index=False)
边栏推荐
猜你喜欢

Semantic segmentation learning notes (1)

JVM architecture, classloader, parental delegation mechanism
How does the computer set up speakers to play microphone sound

Internet Explorer officially retired
Bing.com網站
【网络安全】网络资产收集

Leetcode skimming -- verifying the preorder serialization of binary tree # 331 # medium
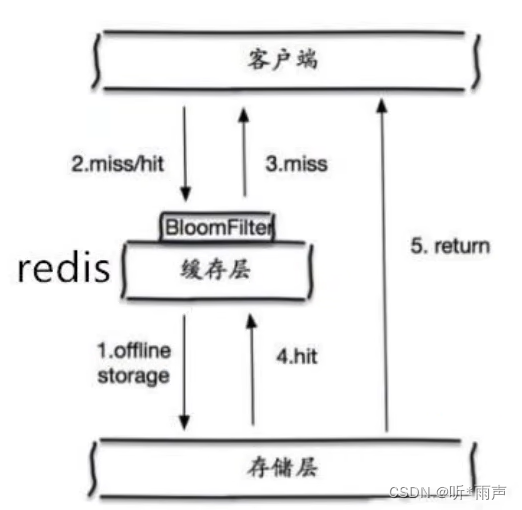
21_ Redis_ Analysis of redis cache penetration and avalanche
![[C language] explain the initial and advanced levels of the pointer and points for attention (1)](/img/61/1619bd2e959bae1b769963f66bab4e.png)
[C language] explain the initial and advanced levels of the pointer and points for attention (1)

How to find a sense of career direction
随机推荐
20_Redis_哨兵模式
11_Redis_Hyperloglog_命令
SQL transaction
YOLOV5 代码复现以及搭载服务器运行
Apprendre le Code de la méthode de conversion du calendrier lunaire grégorien en utilisant PHP
数据分析常见的英文缩写(一)
Steps for Navicat to create a new database
Tidb data migration scenario overview
哈夫曼树:(1)输入各字符及其权值(2)构造哈夫曼树(3)进行哈夫曼编码(4)查找HC[i],得到各字符的哈夫曼编码
16_ Redis_ Redis persistence
12_Redis_Bitmap_命令
19_ Redis_ Manually configure the host after downtime
Infra11199 database system
Application of CDN in game field
Base64 coding can be understood this way
Learn the method code example of converting timestamp to uppercase date using PHP
MySQL calculate n-day retention rate
02.面向容器化后,必须面对golang
13_Redis_事务
Engineer evaluation | rk3568 development board hands-on test