当前位置:网站首页>干货!半监督预训练对话模型 SPACE
干货!半监督预训练对话模型 SPACE
2022-07-05 16:23:00 【AITIME论道】
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!

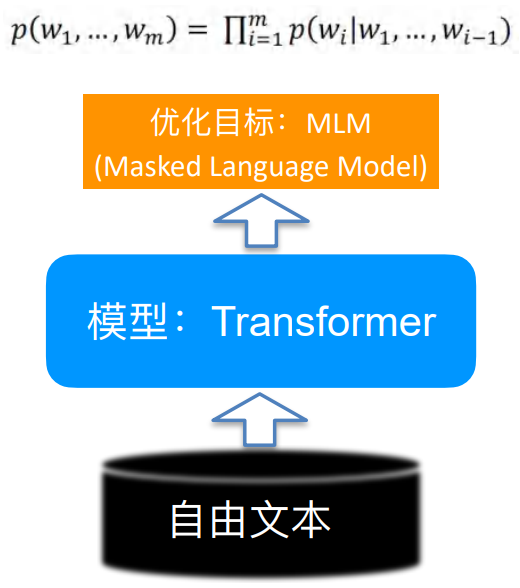
如何将人类先验知识低成本地融入到预训练模型中一直是个NLP的难题。在本工作中,达摩院对话智能团队提出了一种基于半监督预训练的新训练范式,通过半监督方法将少量有标对话数据和海量无标对话数据一起进行预训练,利用一致性正则化损失函数将标注数据中蕴含的对话策略知识注入到预训练模型中去,从而学习出更好的模型表示。
新提出的半监督预训练对话模型SPACE(Semi-Supervised Pre-trAined Conversation ModEl)首先围绕对话策略知识展开了研究,实验表明,SPACE1.0 模型在剑桥MultiWOZ2.0,亚马逊MultiWOZ2.1等经典对话数据集上能够取得5%+显著效果提升,并且在各种低资源设置下,SPACE1.0 比现有sota 模型都具有更强的小样本学习能力。
本期AI TIME PhD直播间,我们邀请到阿里巴巴达摩院高级算法工程师——戴音培,为我们带来报告分享《半监督预训练对话模型 SPACE》。

戴音培:
阿里巴巴达摩院高级算法工程师,硕士毕业于清华大学电子工程系,研究领域为自然语言处理及对话智能(Conversational AI),具体方向包括对话理解、对话管理和大规模预训练对话模型等。在 ACL / AAAI / SIGIR/ ICASSP 等会议上发表多篇论文并多次担任 ACL / EMNLP / NAACL / AAAI 等会议审稿人。
Pre-trained Conversation Model (PCM)
最近的预训练语言模型Pre-trained Language Model(PLM)可谓是异常火爆,那我们为何还要研究预训练对话模型呢?尽管前者在许多任务上都能带来一定程度的效果提升,但有文章表明通过一些损失函数的设计可以得到更好的预训练模型。预训练对话模型就是针对下游的对话任务设计的模型,其能够在预训练语言模型基础之上得到更好的提升。
预训练语言模型vs.预训练对话模型
• Pre-trained Language Model (PLM) 预训练语言模型
• 需要回答什么样的句⼦更像⾃然语⾔
• Pre-trained Conversation Model (PCM) 预训练对话模型
• 需要回答给定对话历史,什么样的回复更合理
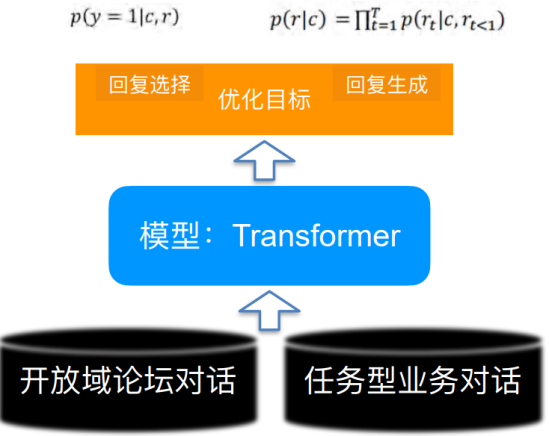
相比plain text,对话有哪些特点?

Backgrounds
• Task-oriented dialog (TOD) systems help accomplish certain tasks
本研究主要是建立在任务型对话的基础上,相比于普通闲聊对话需要完成特定的任务。

如上图所示,一共包含对话理解、对话策略和对话生成一共三个类任务。
预训练对话模型汇总

面向理解的预训练对话模型
• 在对话理解任务上,预训练对话模型(ConveRT和ToD-BERT)⽐预训练语⾔模型提升10%+;
• 在表征学习上,预训练对话模型也能学到更好的表示,有更好的聚类效果;
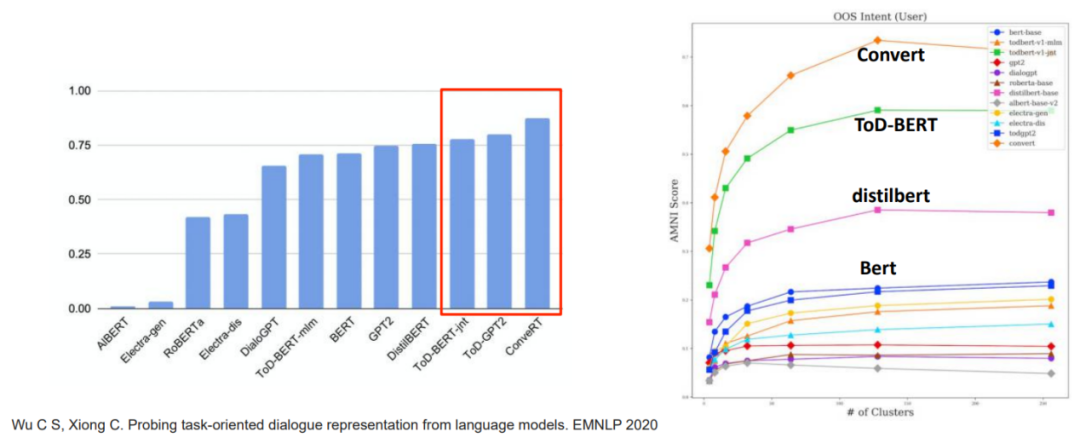
预训练对话模型汇总

面向生成的预训练对话模型
• Facebook对话质量⼈⼯评测
• 评估⽅法:A/B test, Human-to-human vs. human-to-bot, bot包括Facebook系列Chatbot
• 从2018年到2020年,facebook系列模型在A/B test胜率从23%提升到49%
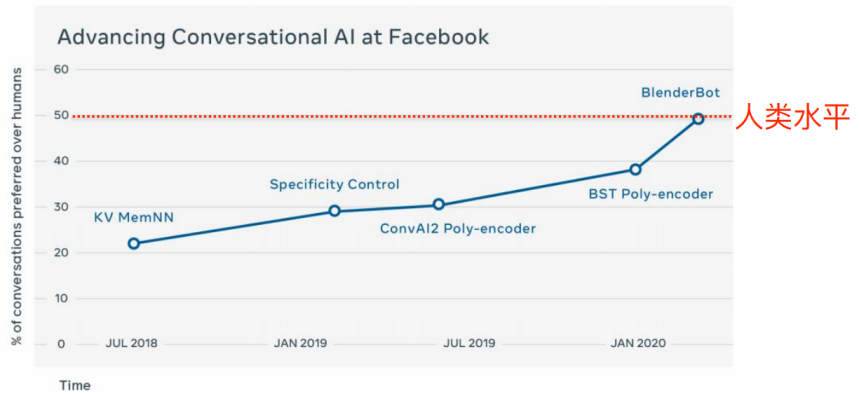
预训练对话模型汇总

目前的问题在于对对话策略鲜有研究,该如何对其进行更好的建模呢?
Pre-trained Objectives for PCM
• 观察1:当前的 PCMs 普遍都集中在理解和⽣成的基础建模

我们可以发现,理解和⽣成的模型基于⾃监督学习,不依赖特定知识且简单成本低,因此也可以得到快速的拓展。
怎么建模对话策略?
• 观察2: Dialog act (DA) as explicit policy
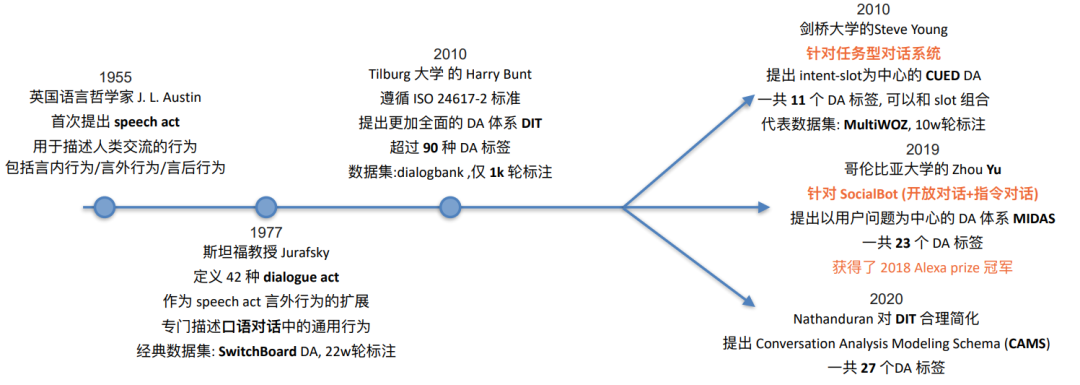
我们接下来,主要思考的是如何刻画统一的对话动作体系来建模对话策略并融入到预训练对话模型之中。
半监督预训练对话模型 SPACE
• 动机:如何融⼊额外⼈类标注知识,显式利⽤⾼层对话语义信息?
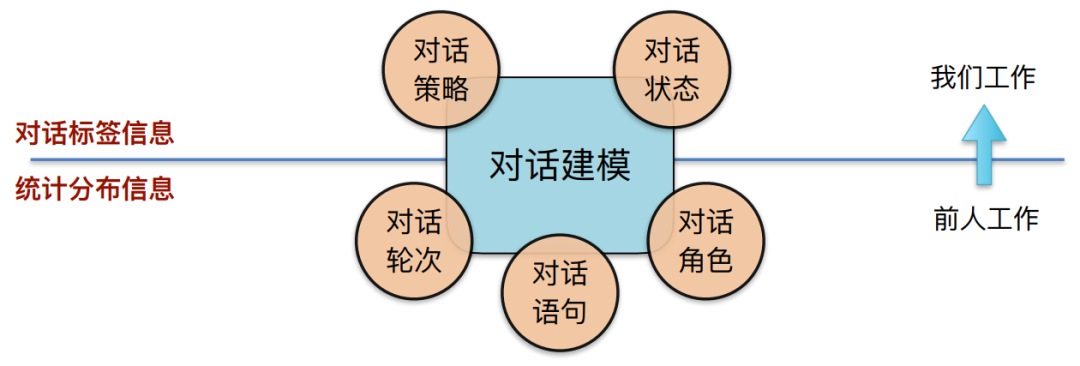
我们之前对对话标签信息并没有做到很好利用。我们的工作希望可以将上图中的二者结合起来,既能够用的低层次的统计分布信息,也能够用到高层次的对话标签信息。
• 提出利⽤半监督预训练,充分结合有标和⽆标对话数据
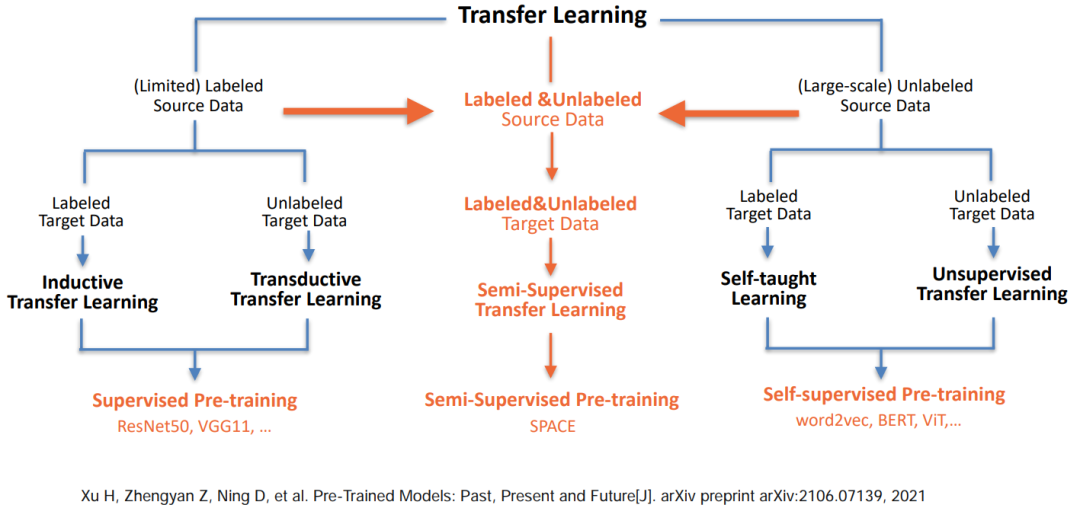
在这里,我们结合前人的工作提出了半监督预训练,希望可以同时更好的利用有标和无标数据,得到一个更好的预训练对话模型。接下来,我们要看下不同数据集对话动作标签体系不一致的问题。
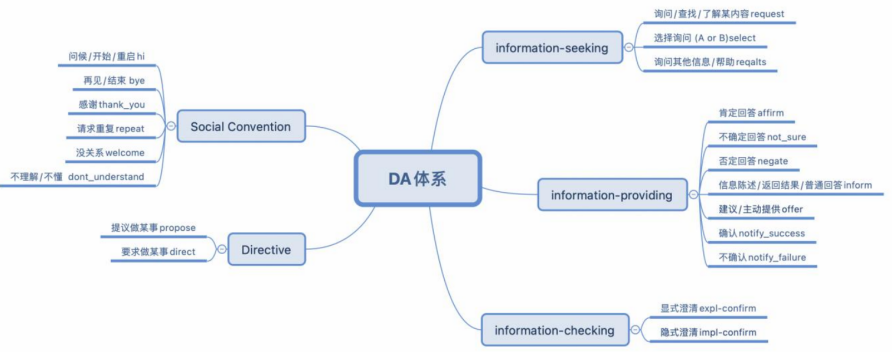
准备工作:定义英文任务型对话 DA 体系
• Method: Propose unified DA schema for TOD
• UniDA: 共5⼤类,20个标签,综合考虑常⻅对话动作(暂不考虑语⾳类)
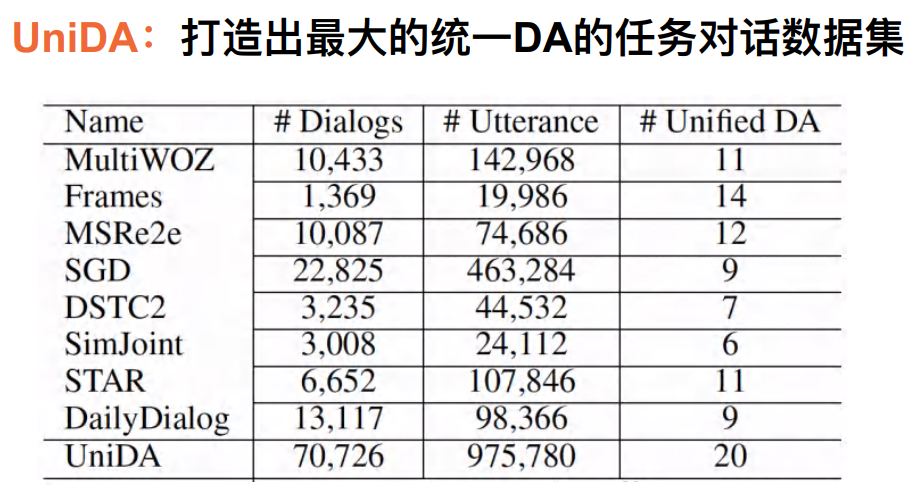
准备工作:构建预训练对话数据集
• ⽬标:构建⾯向任务型对话的统⼀DA体系的数据
• 难点:体系庞杂、数据量有限
目前我们一共汇总了8个数据集,希望打造一个有统一对话动作的标签体系。
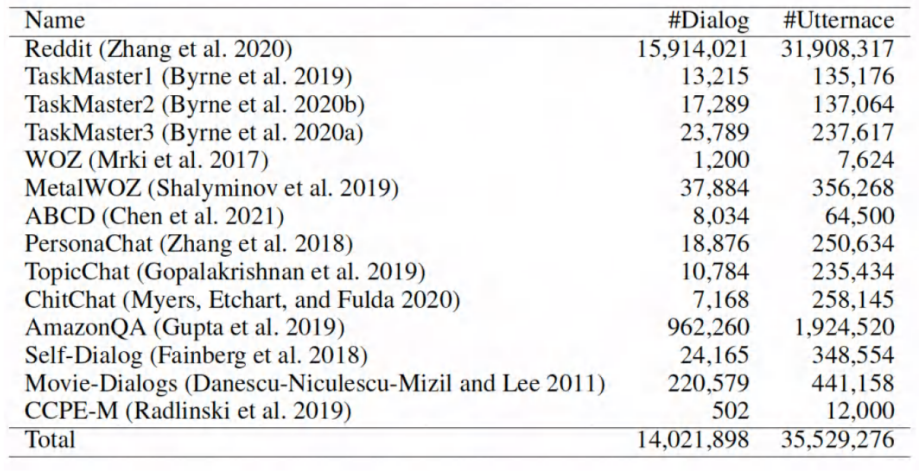
准备工作:构建预训练对话数据集
• ⽬标:⼤规模⽆标注对话语料 UnDial
使用对话策略知识 — 定义 DA 预测任务
• 显式建模对话策略:给定对话历史,预测下⼀轮系统端的DA
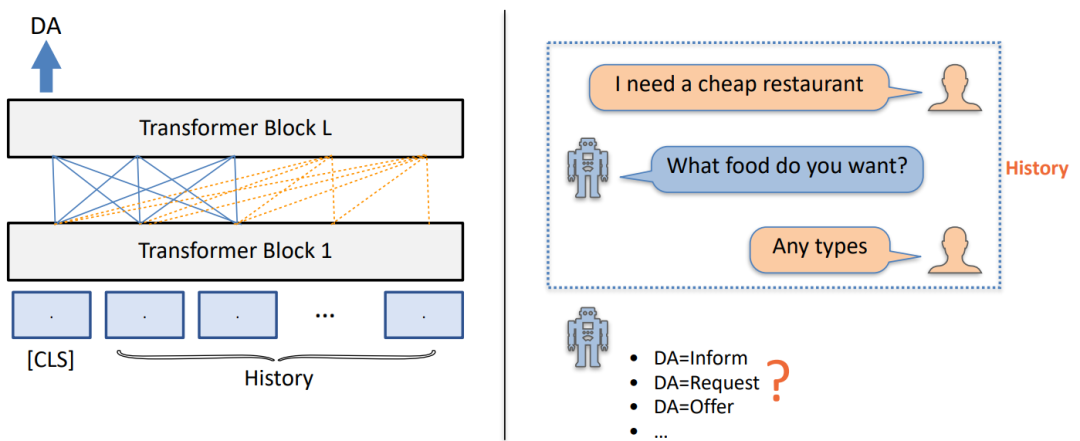
通过我们实现整理的数据,我们就可以将有标数据利用起来去训练对话模型。
模型输入表征结构
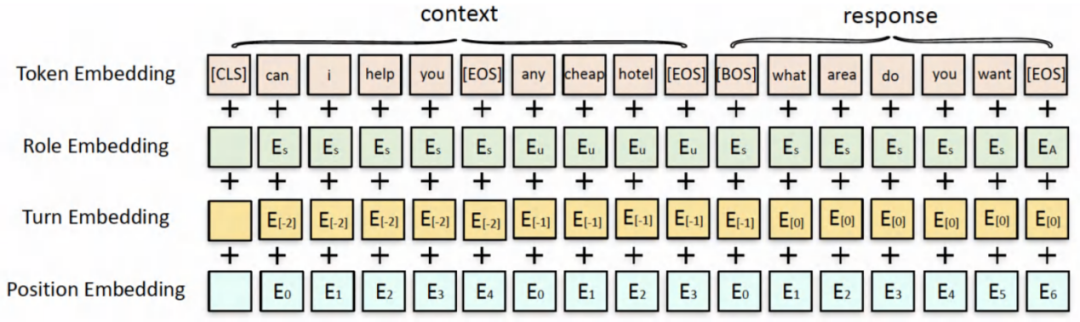
以上,就是我们整理好的数据,设计好的DA有监督loss以及与训练对话模型输入的表征。接下来,我们希望能够利用半监督预训练的方法来学习出更好的模型。
探索半监督预训练方法
探索半监督预训练
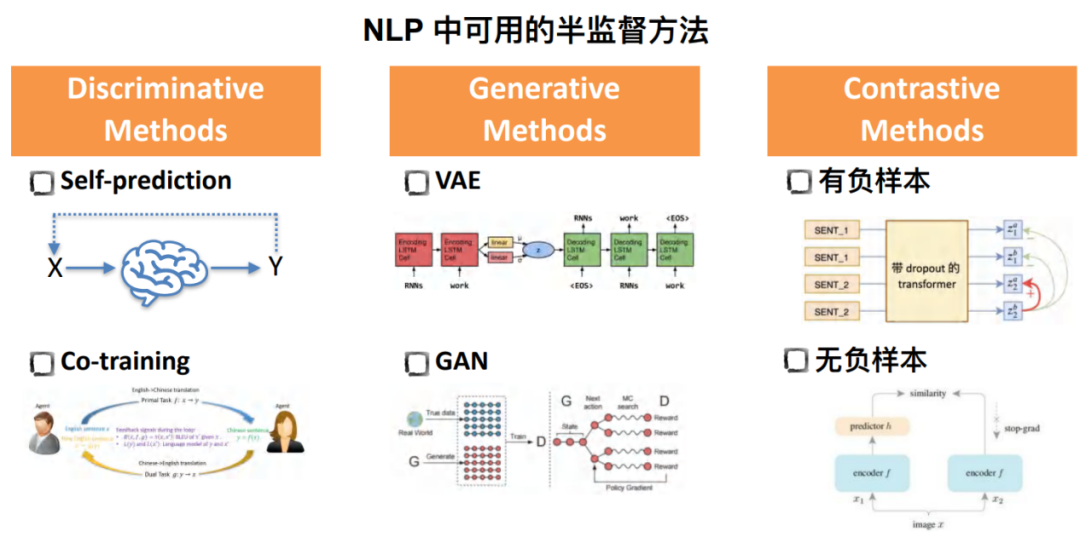
目前,半监督方法一共可以分为三大类:
• Discriminative Methods
该方法种最有代表性的就是自预测的表示,即模型在一小批有标数据上学习后通过在无标数据上采取自预测的表示,给无标数据打上伪标签从而实现二次训练。
对于Co-training方法,一共有两个模型。其输入和输出分别是对方的输出和输入。
• Generative Methods
之前普遍采样VAE和GAN的方法,如VAE是基于隐变量的建模在对话中产生response。
• Contrastive Methods
对比学习常见的分类是基于是否构造负样本,其好处也是能在某种程度上实现自监督的学习。
我们的半监督预训练探索方案1:基于自预测的方法
• 将有监督 loss 和⾃监督 loss 进⾏简单混合
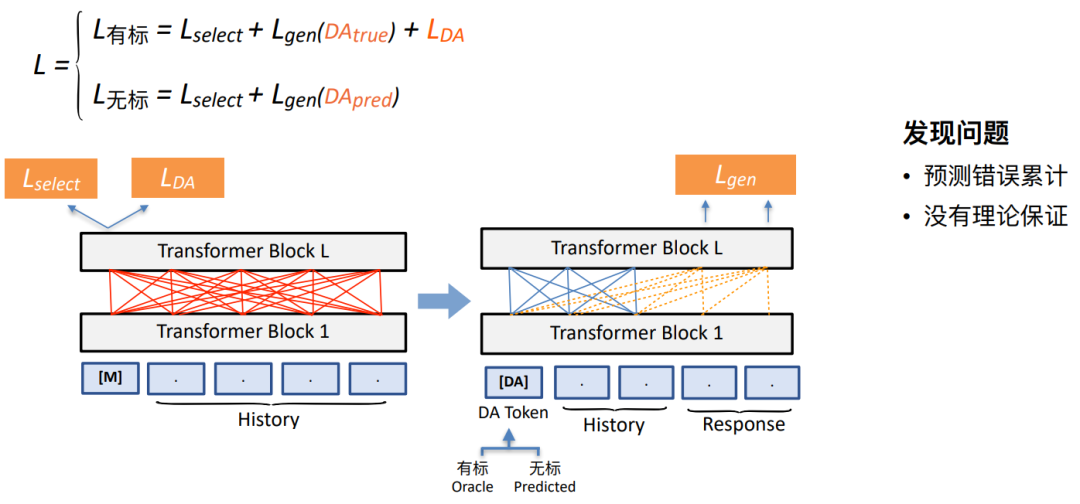
无论是有标还是无标数据,这里都有个loss命名为Lselect,用来代表对话理解的作用。如上图所示,我们的模型是在左侧的理解端给定History的情况下,用这两个loss去预测下一轮DA的标签,记作LDA。无标数据上由于没有DA标签,我们需要自预测的方法先将DA标签预测出来并放在DA token的位置,和History合在一起产生对话的回复。
然而,这也可能会出现过拟合的问题。我们在此基础之上尝试采用如下第二种方案。
我们的半监督预训练探索方案2:基于VAE的⽅法
• 基于 PLATO 改进,利⽤少量有监督知识指导隐空间靠近显式DA空间• 基于 PLATO 改进,利⽤少量有监督知识指导隐空间靠近显式DA空间
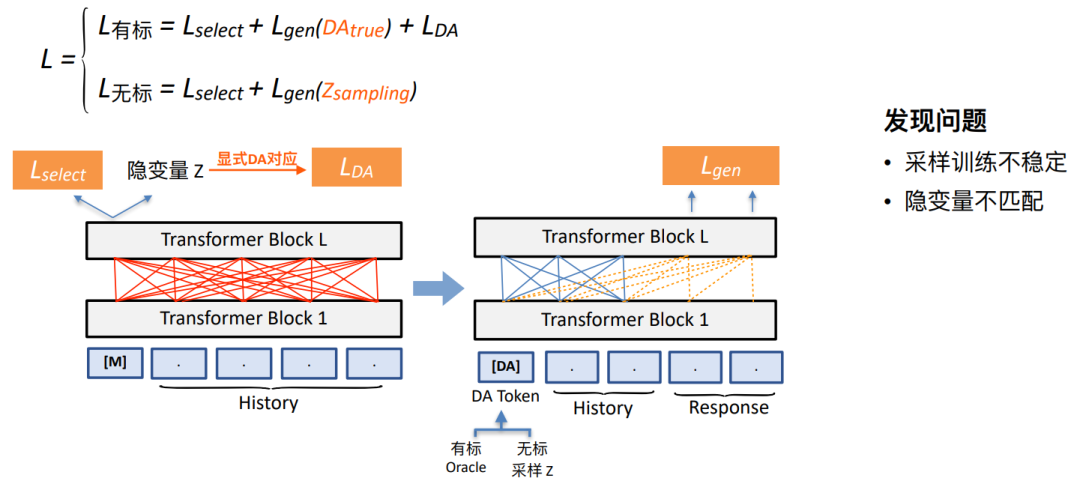
我们在此方法种通过采样将DA标签送到DA token位置,实现对话预测。有标数据上我们采用Oracle标签,无标数据我们将采样。
然而,我们发现当前方法的性能还是非常有限。
基于对比学习半监督的预训练对话模型
• 简化预测过程,消除 DA 不确定性错误累计
• 对预测DA分布直接进行对比学习
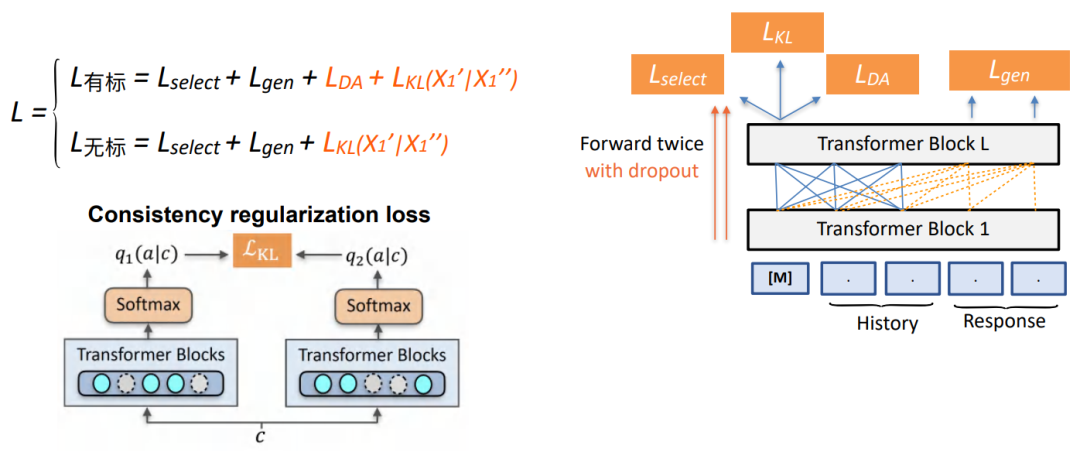
我们采用对比学习的方法,主要针对无标数据上如何建造更好的loss从而使得DA预测结果正则化约束。给定同一个输入,通过两次drop out得到在预测的DA分布上的不同分布,并使得这两个分布足够接近。
基于对比学习半监督的预训练对话模型
• ⼀致性正则半监督训练示意图
• Under low density assumption
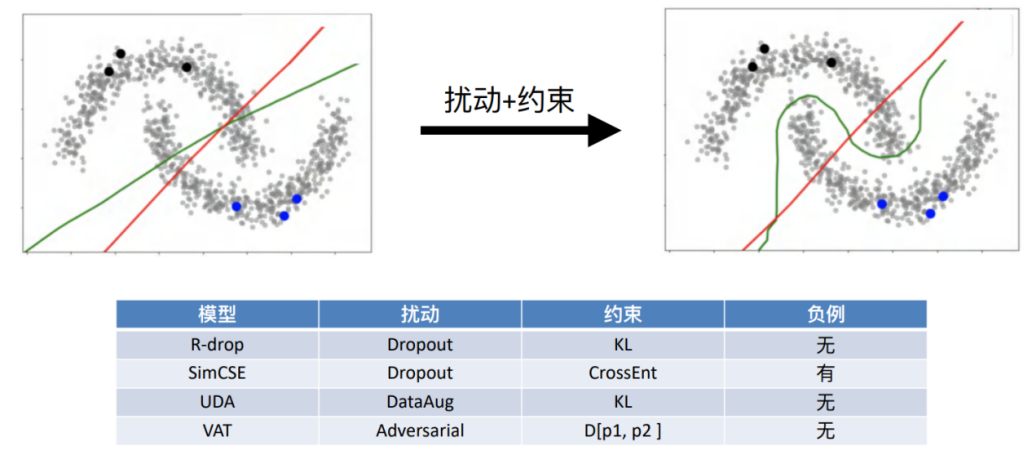
假设我们语义空间满足可分,则通过扰动+约束的手段一定可以得到该分布的特点。不同的算法,如R-drop、SimCSE等方法都是在一致性正则的框架之下,不过扰动的方法和约束的目标不一致。
半监督预训练对话模型 SPACE
• Method: Learn policy from UniDA and UnDial via semi-supervised pre-training 提出了 SPACE 系列模型 1.0 版本 (GALAXY)
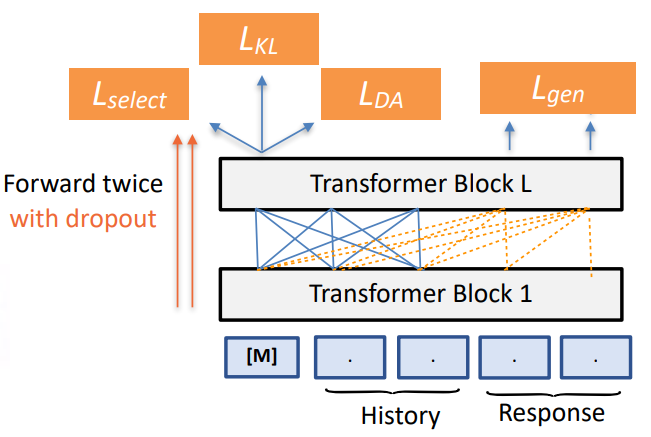
• Based on UniLM Architecture.
• Pre-training optimization:
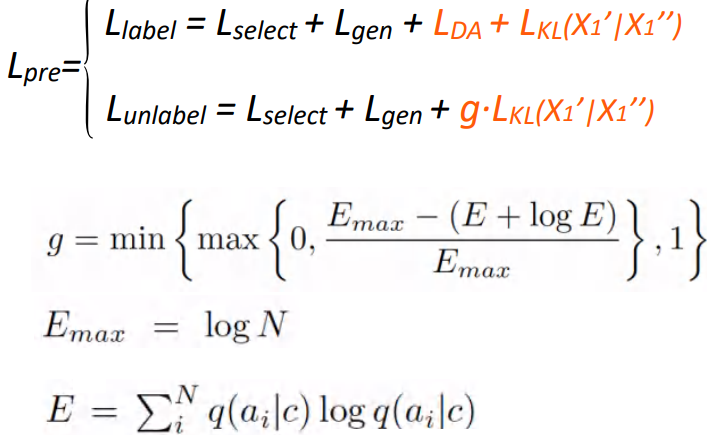
无论有标无标都会加上一个一致性正则的loss,在无监督的数据上加入一个门机制。通过约束无标数据上预设的不符合分布,我们可以检测模型在无标数据上分类结果的熵。如果熵大于某个阈值,我们就约束其得分尽可能地小,避免在大量无监督数据上可能会存在某些对话数据不太符合我们设想的数据,这样就能剔除某些噪声数据。
以上是预训练的优化过程,在下游任务fine-tuning过程中我们会保留对话回复生成的loss,同时如果下游任务包含DA标签,我们还会加上LDA来进行学习并利用好数据集的特性;而如果下游任务不包含DA标签,我们就不加LDA,只用回复生成的loss来实现。
实验与分析
实验准备:下游任务
• 任务对话数据集 MultiWOZ
• EMNLP2018 best resource paper, 35+ team
• 领域丰富:餐馆、酒店、⽕⻋等 7 个领域
• 数据量⼤:10k sessions ⼈⼈众包对话
• 任务多样:
• 理解: Dialog State Tracking(DST)
• 策略:Policy optimization • 端到端: End-to-end modelling
• 指标:
• Inform: 提供Entity是否正确,衡量对话理解效果
• Success: 最终任务是否完成,衡量对话策略效果
• BLUE: 每轮回复相关度得分,衡量对话⽣成效果
• Combine score: (Inform+Success)/2+BLU
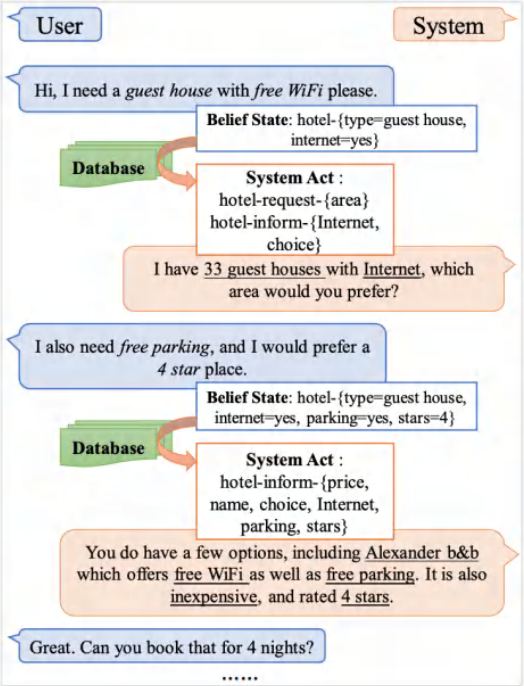
实验准备:下游输入输出
• 借鉴 UBAR 思路

在整个下游任务中,我们在输入用户语句之后会用模型去预测一个中间标签。之后我们会将预测标签重新作为输入放到用户的句子之后,不断迭代、补充、预测...我们就可以把完成的对话历史包含中间标签重新作为输入,以此保持对话的一致性。
半监督预训练对话模型 SPACE
在端到端对话建模的任务上,我们在4个数据集上取得了SOTA的结果。
• Overall Results: New SOTA on End-to-End Dialog Modeling

• Overall Results: New SOTA on End-to-End Dialog Modeling
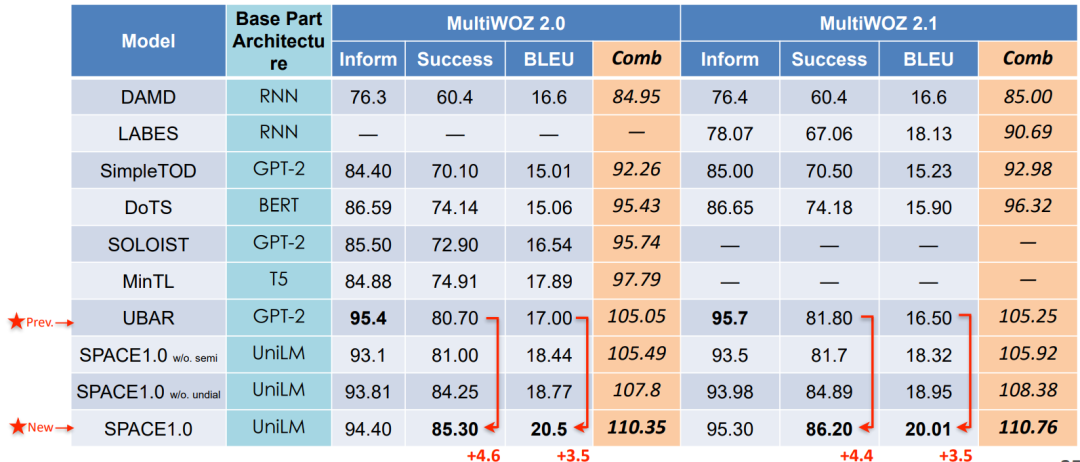
从上图可以看到,我们的模型相对之前的SOTA模型在整体指标上的提升主要是来自用来衡量对话策略生成的Success和BLEU上。
可以这样理解,因为我们的模型有效建模了对话策略,因此在衡量对话策略的Success上相对之前模型有了显著提升。又因为对话策略选的好,所以后续的对话生成也更加合理。我们的模型在整体混和指标上也达到了最好的效果。
• Low-Resource Results on MultiWOZ2.0
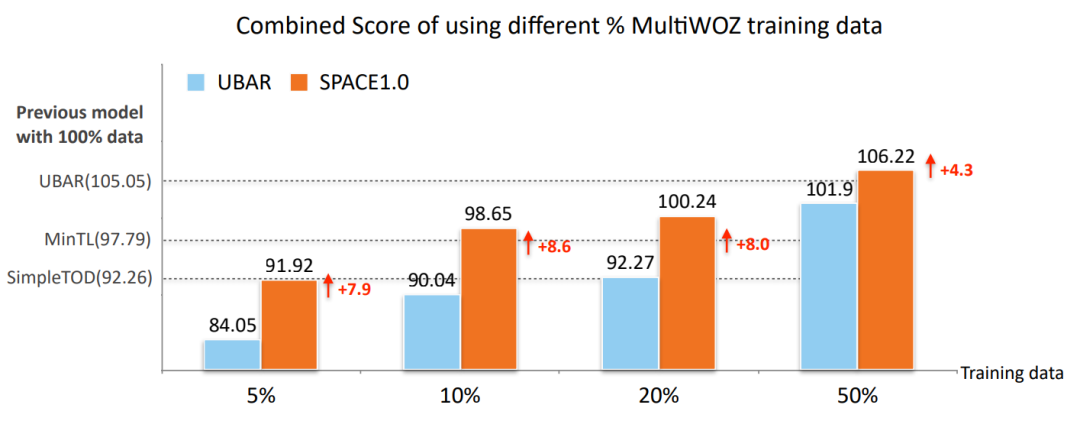
由上图可以看到,我们的模型利用较少的数据就可以通过预训练的方式得到更好的对话表示,从而适配整个下游任务。
• Other Comparison
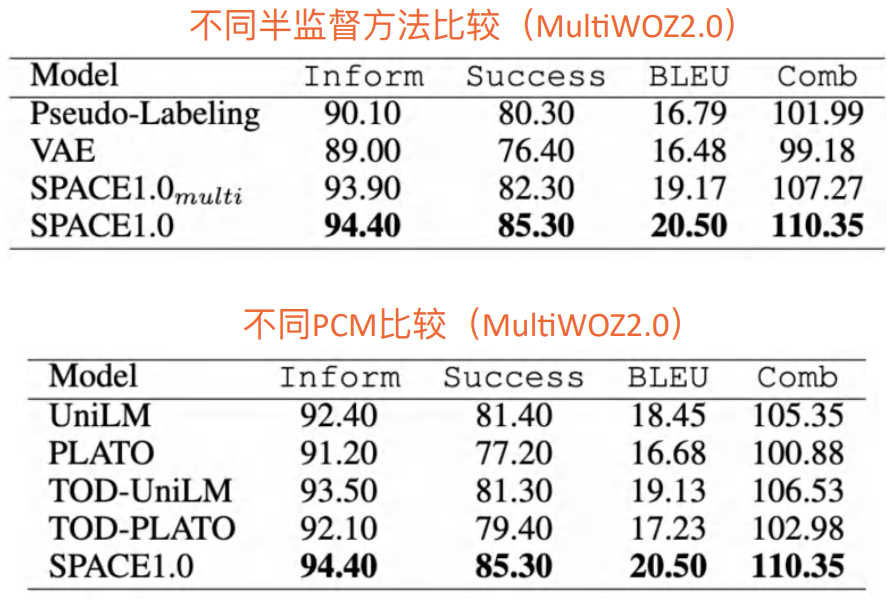
我们发现,我们的模型无论是在什么样的适配上都能得到最好的效果。
• Case Study

我们的模型因为在预训练的时候就能使其预测下一轮的能力增强,因此SPACE模型就可以预测出最好的DA标签。由于对话策略选择的正确,所以SPACE模型在预测对话生成上就能达成一个很好的效果。
为什么一致性正则方法有效?

在有标数据上,我们有2个loss,一个是DA loss,一个是KL的一致性正则loss;在无标数据上,也有1个KL的一致性正则loss。由于在有标数据上存在KL loss能够实现一定程度的正则化loss,很有可能整个DA分布将会过拟合到有标数据上。
然而,如果只利用无标数据的KL loss,则很有可能会学出一个频繁解,即无论什么数据都会学出同一种分布——预测到同一类。这样就会导致无标数据的KL loss直接降为0,因此我们整个训练loss同时包含有标和无标,有标数据上的LDA loss可以防止塌缩的现象。
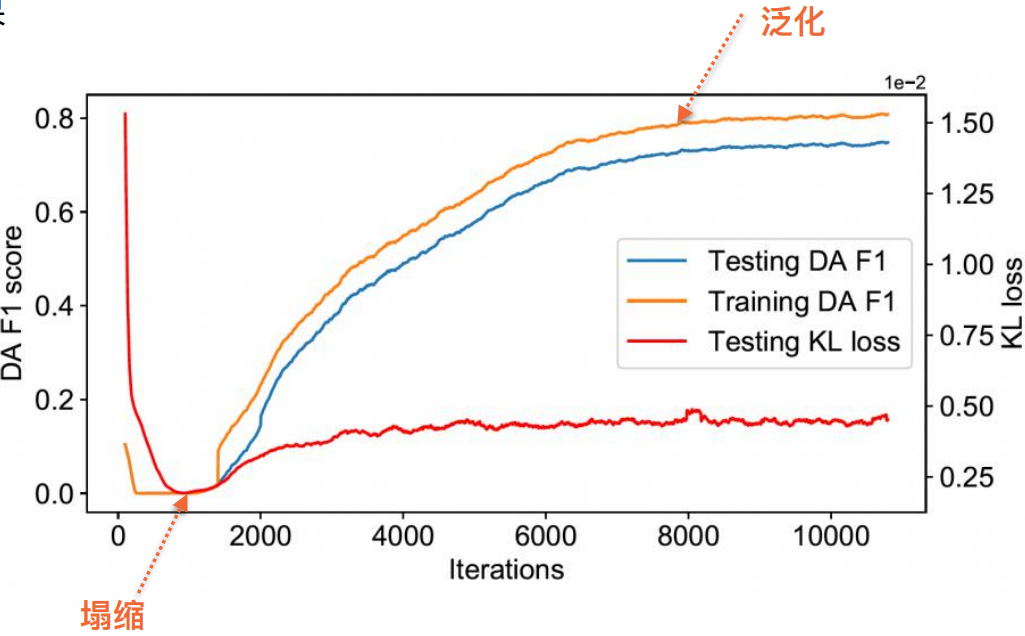
总结与展望
• 我们首次将对话策略通过半监督方式注入到预训练对话模型之中,并在多个数据集上去得到SOTA结果。
• 我们还提出了使用半监督作为预训练手段,从而训练出更好的预训练模型出来。其实我们的方法不仅可以利用对话策略,还可以利用很多和对话、NLP相关的各种领域
提
醒
论文题目:
SPACE 1.0 - A Generative Pre-trained Model for Task-Oriented Dialog with Semi-Supervised Learning and Explicit Policy Injection
论文链接:
https://arxiv.org/abs/2111.14592
点击“阅读原文”,即可观看本场回放
整理:林 则
作者:戴音培
活动推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了700多位海内外讲者,举办了逾300场活动,超260万人次观看。

我知道你
在看
哦
~

点击 阅读原文 查看回放!
边栏推荐
- File operation --i/o
- 麻烦问下,DMS中使用Redis语法是以云数据库Redis社区版的命令为参考的嘛
- tf.sequence_mask函数讲解案例
- [js] 技巧 简化if 判空
- Google Earth Engine(GEE)——Kernel核函数简单介绍以及灰度共生矩阵
- Jarvis OJ 远程登录协议
- Seaborn draws 11 histograms
- 【剑指 Offer】61. 扑克牌中的顺子
- 清晰还原31年前现场,火山引擎超清修复Beyond经典演唱会
- Hiengine: comparable to the local cloud native memory database engine
猜你喜欢
If you can't afford a real cat, you can use code to suck cats -unity particles to draw cats
Jarvis OJ Telnet Protocol
Flet教程之 09 NavigationRail 基础入门(教程含源码)

飞桨EasyDL实操范例:工业零件划痕自动识别

深耕5G,芯讯通持续推动5G应用百花齐放

Etcd 构建高可用Etcd集群
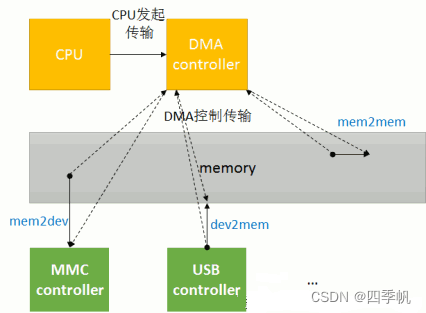
拷贝方式之DMA
Bs-xx-042 implementation of personnel management system based on SSM
Clear restore the scene 31 years ago, volcanic engine ultra clear repair beyond classic concert
HiEngine:可媲美本地的云原生内存数据库引擎
随机推荐
[deep learning] [original] let yolov6-0.1.0 support the txt reading dataset mode of yolov5
【刷題篇】鹅廠文化衫問題
How does win11 change icons for applications? Win11 method of changing icons for applications
Clear restore the scene 31 years ago, volcanic engine ultra clear repair beyond classic concert
Global Data Center released DC brain system, enabling intelligent operation and management through science and technology
JSON转MAP前后数据校验 -- 自定义UDF
如何将mysql卸载干净
BS-XX-042 基于SSM实现人事管理系统
【学术相关】多位博士毕业去了三四流高校,目前惨不忍睹……
Keras crash Guide
[61dctf]fm
scratch五彩糖葫芦 电子学会图形化编程scratch等级考试三级真题和答案解析2022年6月
Can you help me see what the problem is? [ERROR] Could not execute SQL stateme
Spring Festival Limited "forget trouble in the year of the ox" gift bag waiting for you to pick it up~
yarn 常用命令
Win11 prompt: what if the software cannot be downloaded safely? Win11 cannot download software safely
Fleet tutorial 09 basic introduction to navigationrail (tutorial includes source code)
挖财股票开户安全吗?怎么开股票账户是安全?
用键盘输入一条命令
[61dctf]fm