当前位置:网站首页>Gym安装、调用以及注册
Gym安装、调用以及注册
2022-07-25 13:14:00 【抓紧爬起来不许摆烂】
0 gym简介
gym是有openai研发,用于开发和比较强化学习算法的工具组件。
其提供了很多可以直接使用的标准强化学习环境。
1 安装
pip install gym
或
git clone https://github.com/openai/gym
cd gym
pip install -e .
2 调用
import gym
env = gym.make('CartPole-v0') # 调用环境
env.reset() # 对环境进行复位,回到初始状态
for_in range(1000): # 开启一个控制循环
env.render() # env显示
env.step(env.action_space.sample())# env take a random action,action from action_space当中随机采样的值
env.close()# 结束控制过程,关闭env
3 注册
虽然gym中有丰富的已经写好的环境,但我们不可能仅仅局限于这些环境当中。我们也可能遇到自己的问题,需要自己写一个环境,但也要基于一个这样的基本框架来运行。如何把自己的环境移入gym当中然后进行调用,就成为一个很关键的问题。这个问题可以称之为“注册”。
(1)找到gym的安装路径。可以在python目录下直接搜索site-packages文件夹,其中的gym文件夹就是gym安装目录
(2)使用提供的core.py替换gym中的同名文件(提供的core.py比原始文件多了些检验部分,这些检验部分主要用于检验创建的环境是否满足gym的要求)
(3)进入env/classic_control,添加grid_game.py文件。classic_control是根据grid_game内容所选择的分类,也可以选择其他的。
(4)修改env/classic_control/_init_.py文件。添加from gym.envs.classic_control.grid_game import GridEnv
(5)修改envs/_init_.py文件
添加register(
id='GridWorld-v0',
entry_point='gym.envs,classic_control:GridEnv',
max_episode_steps=200,
reward_threshold=100.0,
)
core.py
from gym import logger
import numpy as np
import gym
from gym import error
from gym.utils import closer
env_closer = closer.Closer()
# Env-related abstractions
class Env(object):
"""The main OpenAI Gym class. It encapsulates an environment with arbitrary behind-the-scenes dynamics. An environment can be partially or fully observed. The main API methods that users of this class need to know are: transform step reset render close seed And set the following attributes: action_space: The Space object corresponding to valid actions observation_space: The Space object corresponding to valid observations reward_range: A tuple corresponding to the min and max possible rewards Note: a default reward range set to [-inf,+inf] already exists. Set it if you want a narrower range. The methods are accessed publicly as "step", "reset", etc.. The non-underscored versions are wrapper methods to which we may add functionality over time. """
# Set this in SOME subclasses
metadata = {
'render.modes': []}
reward_range = (-np.inf, np.inf)
spec = None
# Set these in ALL subclasses
action_space = None
observation_space = None
def transform(self,state,action):
''' Run one timestep of the environment's dynamics. When end of episode is reached, you are responsible for calling `transform()` to reset args state. Accepts an state and action returns a tuple(observation,reward,done,info). Args: state (object):an state provided by the anvironment Returns: Returns: observation (object): agent's observation of the current environment reward (float) : amount of reward returned after previous action done (boolean): whether the episode has ended, in which case further step() calls will return undefined results info (dict): contains auxiliary diagnostic information (helpful for debugging, and sometimes learning) '''
pass
def step(self, action):
"""Run one timestep of the environment's dynamics. When end of episode is reached, you are responsible for calling `reset()` to reset this environment's state. Accepts an action and returns a tuple (observation, reward, done, info). Args: action (object): an action provided by the environment Returns: observation (object): agent's observation of the current environment reward (float) : amount of reward returned after previous action done (boolean): whether the episode has ended, in which case further step() calls will return undefined results info (dict): contains auxiliary diagnostic information (helpful for debugging, and sometimes learning) """
raise NotImplementedError
def reset(self):
"""Resets the state of the environment and returns an initial observation. Returns: observation (object): the initial observation of the space. """
raise NotImplementedError
def render(self, mode='human'):
"""Renders the environment. The set of supported modes varies per environment. (And some environments do not support rendering at all.) By convention, if mode is: - human: render to the current display or terminal and return nothing. Usually for human consumption. - rgb_array: Return an numpy.ndarray with shape (x, y, 3), representing RGB values for an x-by-y pixel image, suitable for turning into a video. - ansi: Return a string (str) or StringIO.StringIO containing a terminal-style text representation. The text can include newlines and ANSI escape sequences (e.g. for colors). Note: Make sure that your class's metadata 'render.modes' key includes the list of supported modes. It's recommended to call super() in implementations to use the functionality of this method. Args: mode (str): the mode to render with close (bool): close all open renderings Example: class MyEnv(Env): metadata = {'render.modes': ['human', 'rgb_array']} def render(self, mode='human'): if mode == 'rgb_array': return np.array(...) # return RGB frame suitable for video elif mode is 'human': ... # pop up a window and render else: super(MyEnv, self).render(mode=mode) # just raise an exception """
raise NotImplementedError
def close(self):
"""Override _close in your subclass to perform any necessary cleanup. Environments will automatically close() themselves when garbage collected or when the program exits. """
return
def seed(self, seed=None):
"""Sets the seed for this env's random number generator(s). Note: Some environments use multiple pseudorandom number generators. We want to capture all such seeds used in order to ensure that there aren't accidental correlations between multiple generators. Returns: list<bigint>: Returns the list of seeds used in this env's random number generators. The first value in the list should be the "main" seed, or the value which a reproducer should pass to 'seed'. Often, the main seed equals the provided 'seed', but this won't be true if seed=None, for example. """
logger.warn("Could not seed environment %s", self)
return
@property
def unwrapped(self):
"""Completely unwrap this env. Returns: gym.Env: The base non-wrapped gym.Env instance """
return self
def __str__(self):
if self.spec is None:
return '<{} instance>'.format(type(self).__name__)
else:
return '<{}<{}>>'.format(type(self).__name__, self.spec.id)
class GoalEnv(Env):
"""A goal-based environment. It functions just as any regular OpenAI Gym environment but it imposes a required structure on the observation_space. More concretely, the observation space is required to contain at least three elements, namely `observation`, `desired_goal`, and `achieved_goal`. Here, `desired_goal` specifies the goal that the agent should attempt to achieve. `achieved_goal` is the goal that it currently achieved instead. `observation` contains the actual observations of the environment as per usual. """
def reset(self):
# Enforce that each GoalEnv uses a Goal-compatible observation space.
if not isinstance(self.observation_space, gym.spaces.Dict):
raise error.Error('GoalEnv requires an observation space of type gym.spaces.Dict')
result = super(GoalEnv, self).reset()
for key in ['observation', 'achieved_goal', 'desired_goal']:
if key not in result:
raise error.Error('GoalEnv requires the "{}" key to be part of the observation dictionary.'.format(key))
return result
def compute_reward(self, achieved_goal, desired_goal, info):
"""Compute the step reward. This externalizes the reward function and makes it dependent on an a desired goal and the one that was achieved. If you wish to include additional rewards that are independent of the goal, you can include the necessary values to derive it in info and compute it accordingly. Args: achieved_goal (object): the goal that was achieved during execution desired_goal (object): the desired goal that we asked the agent to attempt to achieve info (dict): an info dictionary with additional information Returns: float: The reward that corresponds to the provided achieved goal w.r.t. to the desired goal. Note that the following should always hold true: ob, reward, done, info = env.step() assert reward == env.compute_reward(ob['achieved_goal'], ob['goal'], info) """
raise NotImplementedError()
# Space-related abstractions
class Space(object):
"""Defines the observation and action spaces, so you can write generic code that applies to any Env. For example, you can choose a random action. """
def __init__(self, shape=None, dtype=None):
self.shape = None if shape is None else tuple(shape)
self.dtype = None if dtype is None else np.dtype(dtype)
def sample(self):
""" Uniformly randomly sample a random element of this space """
raise NotImplementedError
def contains(self, x):
""" Return boolean specifying if x is a valid member of this space """
raise NotImplementedError
def to_jsonable(self, sample_n):
"""Convert a batch of samples from this space to a JSONable data type."""
# By default, assume identity is JSONable
return sample_n
def from_jsonable(self, sample_n):
"""Convert a JSONable data type to a batch of samples from this space."""
# By default, assume identity is JSONable
return sample_n
warn_once = True
def deprecated_warn_once(text):
global warn_once
if not warn_once: return
warn_once = False
logger.warn(text)
class Wrapper(Env):
env = None
def __init__(self, env):
self.env = env
self.action_space = self.env.action_space
self.observation_space = self.env.observation_space
self.reward_range = self.env.reward_range
self.metadata = self.env.metadata
self._warn_double_wrap()
@classmethod
def class_name(cls):
return cls.__name__
def _warn_double_wrap(self):
env = self.env
while True:
if isinstance(env, Wrapper):
if env.class_name() == self.class_name():
raise error.DoubleWrapperError("Attempted to double wrap with Wrapper: {}".format(self.__class__.__name__))
env = env.env
else:
break
def step(self, action):
if hasattr(self, "_step"):
deprecated_warn_once("%s doesn't implement 'step' method, but it implements deprecated '_step' method." % type(self))
self.step = self._step
return self.step(action)
else:
deprecated_warn_once("%s doesn't implement 'step' method, " % type(self) +
"which is required for wrappers derived directly from Wrapper. Deprecated default implementation is used.")
return self.env.step(action)
def reset(self, **kwargs):
if hasattr(self, "_reset"):
deprecated_warn_once("%s doesn't implement 'reset' method, but it implements deprecated '_reset' method." % type(self))
self.reset = self._reset
return self._reset(**kwargs)
else:
deprecated_warn_once("%s doesn't implement 'reset' method, " % type(self) +
"which is required for wrappers derived directly from Wrapper. Deprecated default implementation is used.")
return self.env.reset(**kwargs)
def render(self, mode='human'):
return self.env.render(mode)
def close(self):
if self.env:
return self.env.close()
def seed(self, seed=None):
return self.env.seed(seed)
def compute_reward(self, achieved_goal, desired_goal, info):
return self.env.compute_reward(achieved_goal, desired_goal, info)
def __str__(self):
return '<{}{}>'.format(type(self).__name__, self.env)
def __repr__(self):
return str(self)
@property
def unwrapped(self):
return self.env.unwrapped
@property
def spec(self):
return self.env.spec
class ObservationWrapper(Wrapper):
def step(self, action):
observation, reward, done, info = self.env.step(action)
return self.observation(observation), reward, done, info
def reset(self, **kwargs):
observation = self.env.reset(**kwargs)
return self.observation(observation)
def observation(self, observation):
deprecated_warn_once("%s doesn't implement 'observation' method. Maybe it implements deprecated '_observation' method." % type(self))
return self._observation(observation)
class RewardWrapper(Wrapper):
def reset(self):
return self.env.reset()
def step(self, action):
observation, reward, done, info = self.env.step(action)
return observation, self.reward(reward), done, info
def reward(self, reward):
deprecated_warn_once("%s doesn't implement 'reward' method. Maybe it implements deprecated '_reward' method." % type(self))
return self._reward(reward)
class ActionWrapper(Wrapper):
def step(self, action):
action = self.action(action)
return self.env.step(action)
def reset(self):
return self.env.reset()
def action(self, action):
deprecated_warn_once("%s doesn't implement 'action' method. Maybe it implements deprecated '_action' method." % type(self))
return self._action(action)
def reverse_action(self, action):
deprecated_warn_once("%s doesn't implement 'reverse_action' method. Maybe it implements deprecated '_reverse_action' method." % type(self))
return self._reverse_action(action)
grid_game.py
import logging
import numpy
import random
import gym
from gym import spaces
logger = logging.getLogger(__name__)
class GridEnv(gym.Env):
metadata = {
'render.modes': ['human', 'rgb_array'],
'video.frames_per_second': 2
}
def __init__(self):
self.states = [0, 1, 2, 3, 4, 5, 6, 7]
self.x = [140, 220, 300, 380, 460, 140, 300, 460]
self.y = [250, 250, 250, 250, 250, 150, 150, 150]
self.terminate_states = dict() # 终止状态
self.terminate_states[5] = 1
self.terminate_states[6] = 1
self.terminate_states[7] = 1
self.actions = ['n', 'e', 's', 'w']
self.rewards = dict() # 回报的数据结构为字典
self.rewards['0_s'] = -1.0
self.rewards['2_s'] = 1.0
self.rewards['4_s'] = -1.0
self.t = dict() # 状态转移的数据格式为字典
self.t['0_e'] = 1
self.t['0_s'] = 5
self.t['1_e'] = 2
self.t['1_w'] = 0
self.t['2_e'] = 3
self.t['2_s'] = 6
self.t['2_w'] = 1
self.t['3_e'] = 4
self.t['3_w'] = 2
self.t['4_s'] = 7
self.t['4_w'] = 3
self.action_space = spaces.Discrete(4)
self.observation_space = spaces.Discrete(8)
self.gamma = 0.8 # 折扣因子
self.viewer = None
self.state = None
def getTerminal(self):
return self.terminate_states
def getGamma(self):
return self.gamma
def getStates(self):
return self.states
def getAction(self):
return self.actions
def getTerminate_states(self):
return self.terminate_states
def setAction(self, s):
self.state = s
def _seed(self, seed=None):
self.np_random, seed = seeding.np_random(seed)
return seed
def _step(self, action):
# 系统当前状态
state = self.state
if state in self.terminate_states:
return state, 0, True, {
}
key = "%d_%s" % (state, self.actions[action]) # 将状态和动作组成字典的键值
# 状态转移
if key in self.t:
next_state = self.t[key]
else:
next_state = state
self.state = next_state
is_terminal = False
if next_state in self.terminate_states:
is_terminal = True
if key not in self.rewards:
r = 0.0
else:
r = self.rewards[key]
return next_state, r, is_terminal, {
}
def _reset(self):
self.state = self.states[int(random.random() * len(self.states))]
return self.state
def _render(self, mode='human', close=False):
if close:
if self.viewer is not None:
self.viewer.close()
self.viewer = None
return
screen_width = 600
screen_height = 400
if self.viewer is None:
from gym.envs.classic_control import rendering
self.viewer = rendering.Viewer(screen_width, screen_height)
# 创建网格世界
self.line1 = rendering.Line((100, 300), (500, 300))
self.line2 = rendering.Line((100, 200), (500, 200))
self.line3 = rendering.Line((100, 300), (100, 100))
self.line4 = rendering.Line((180, 300), (180, 100))
self.line5 = rendering.Line((260, 300), (260, 100))
self.line6 = rendering.Line((340, 300), (340, 100))
self.line7 = rendering.Line((420, 300), (420, 100))
self.line8 = rendering.Line((500, 300), (500, 100))
self.line9 = rendering.Line((100, 100), (180, 100))
self.line10 = rendering.Line((260, 100), (340, 100))
self.line11 = rendering.Line((420, 100), (500, 100))
# 创建第一个骷髅
self.kulo1 = rendering.make_circle(40)
self.circletrans = rendering.Transform(translation=(140, 150))
self.kulo1.add_attr(self.circletrans)
self.kulo1.set_color(0, 0, 0)
# 创建第二个骷髅
self.kulo2 = rendering.make_circle(40)
self.circletrans = rendering.Transform(translation=(460, 150))
self.kulo2.add_attr(self.circletrans)
self.kulo2.set_color(0, 0, 0)
# 创建金条
self.gold = rendering.make_circle(40)
self.circletrans = rendering.Transform(translation=(300, 150))
self.gold.add_attr(self.circletrans)
self.gold.set_color(1, 0.9, 0)
# 创建机器人
self.robot = rendering.make_circle(30)
self.robotrans = rendering.Transform()
self.robot.add_attr(self.robotrans)
self.robot.set_color(0.8, 0.6, 0.4)
self.line1.set_color(0, 0, 0)
self.line2.set_color(0, 0, 0)
self.line3.set_color(0, 0, 0)
self.line4.set_color(0, 0, 0)
self.line5.set_color(0, 0, 0)
self.line6.set_color(0, 0, 0)
self.line7.set_color(0, 0, 0)
self.line8.set_color(0, 0, 0)
self.line9.set_color(0, 0, 0)
self.line10.set_color(0, 0, 0)
self.line11.set_color(0, 0, 0)
self.viewer.add_geom(self.line1)
self.viewer.add_geom(self.line2)
self.viewer.add_geom(self.line3)
self.viewer.add_geom(self.line4)
self.viewer.add_geom(self.line5)
self.viewer.add_geom(self.line6)
self.viewer.add_geom(self.line7)
self.viewer.add_geom(self.line8)
self.viewer.add_geom(self.line9)
self.viewer.add_geom(self.line10)
self.viewer.add_geom(self.line11)
self.viewer.add_geom(self.kulo1)
self.viewer.add_geom(self.kulo2)
self.viewer.add_geom(self.gold)
self.viewer.add_geom(self.robot)
if self.state is None: return None
# self.robotrans.set_translation(self.x[self.state-1],self.y[self.state-1])
self.robotrans.set_translation(self.x[self.state], self.y[self.state])
return self.viewer.render(return_rgb_array=mode == 'rgb_array')
边栏推荐
- 若依如何实现用户免密登录配置方法?
- [six articles talk about scalablegnn] around www 2022 best paper PASCA
- B tree and b+ tree
- arm架构移植alsa-lib和alsa-utils一路畅通
- 备战2022 CSP-J1 2022 CSP-S1 初赛 视频集
- Detailed explanation of the training and prediction process of deep learning [taking lenet model and cifar10 data set as examples]
- 【AI4Code】CodeX:《Evaluating Large Language Models Trained on Code》(OpenAI)
- 从输入网址到网页显示
- ESP32-C3 基于Arduino框架下Blinker点灯控制10路开关或继电器组
- [Video] Markov chain Monte Carlo method MCMC principle and R language implementation | data sharing
猜你喜欢

Design and principle of thread pool

Seven lines of code made station B crash for three hours, but "a scheming 0"

Numpy简介和特点(一)
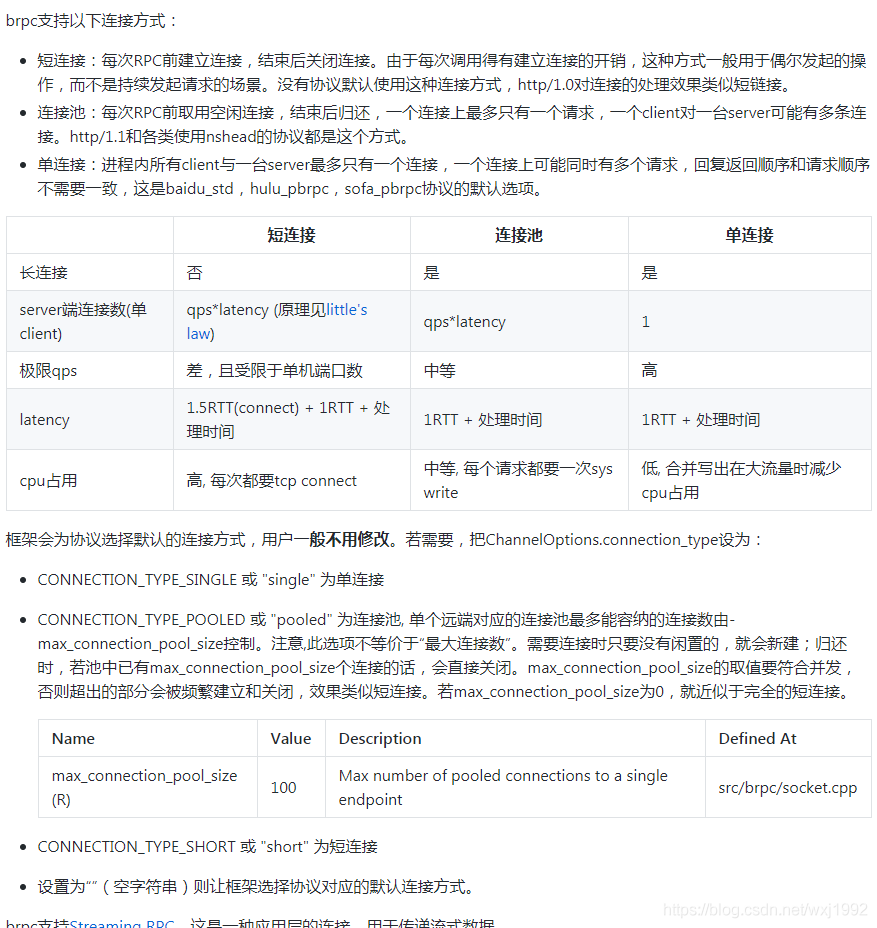
Brpc source code analysis (III) -- the mechanism of requesting other servers and writing data to sockets

web安全入门-UDP测试与防御

0716RHCSA

【CTR】《Towards Universal Sequence Representation Learning for Recommender Systems》 (KDD‘22)

MLIR原理与应用技术杂谈

安装mujoco报错:distutils.errors.DistutilsExecError: command ‘gcc‘ failed with exit status 1
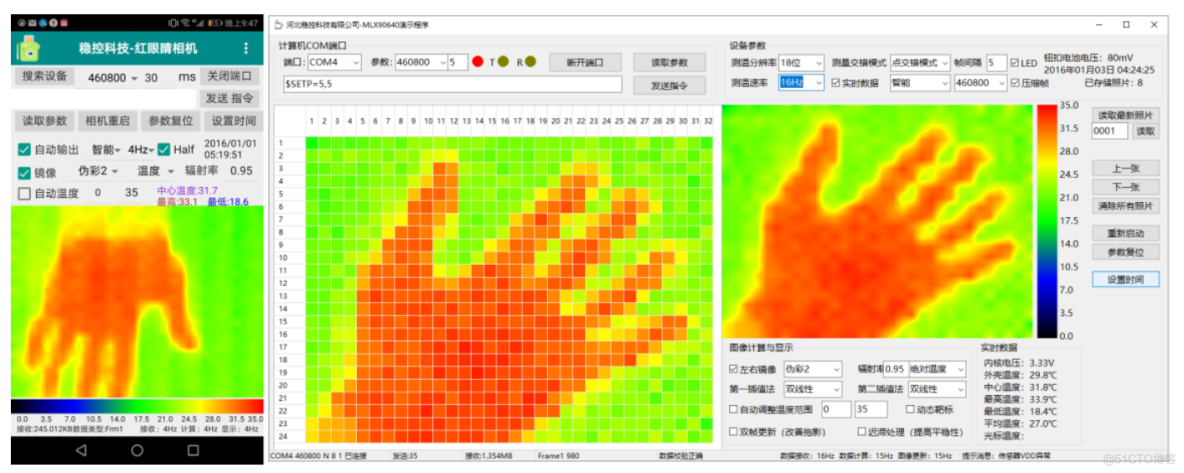
MLX90640 红外热成像仪测温传感器模块开发笔记(五)
随机推荐
Peripheral system calls SAP's webapi interface
程序员成长第二十七篇:如何评估需求优先级?
Docekr学习 - MySQL8主从复制搭建部署
Introduction to web security UDP testing and defense
一味地做大元宇宙的规模,已经背离了元宇宙本该有的发展逻辑
Introduction and features of numpy (I)
错误: 找不到或无法加载主类 xxxx
Seven lines of code made station B crash for three hours, but "a scheming 0"
[300 opencv routines] 239. accurate positioning of Harris corner detection (cornersubpix)
C#基础学习(二十三)_窗体与事件
【GCN-RS】Learning Explicit User Interest Boundary for Recommendation (WWW‘22)
并发编程之并发工具集
0716RHCSA
The programmer's father made his own AI breast feeding detector to predict that the baby is hungry and not let the crying affect his wife's sleep
【GCN-CTR】DC-GNN: Decoupled GNN for Improving and Accelerating Large-Scale E-commerce Retrieval WWW22
卷积神经网络模型之——LeNet网络结构与代码实现
Emqx cloud update: more parameters are added to log analysis, which makes monitoring, operation and maintenance easier
Substance designer 2021 software installation package download and installation tutorial
Programmer growth chapter 27: how to evaluate requirements priorities?
从输入网址到网页显示