当前位置:网站首页>Causes and appropriate analysis of possible errors in seq2seq code of "hands on learning in depth"
Causes and appropriate analysis of possible errors in seq2seq code of "hands on learning in depth"
2022-07-05 08:53:00 【Qizi K】
About Mu God 《 Hands-on deep learning 》Seq2Seq The causes of possible errors in the code and appropriate analysis
Put the training results first :
Bathe God's 300 individual epoch:
go . => va au !, bleu 0.000
i lost . => j’ai perdu perdu ., bleu 0.783
he’s calm . => il est essaye il partie paresseux ., bleu 0.418
i’m home . => je suis chez tom chez triste pas pas pas , bleu 0.376
The following modification V1、V2 edition 100 individual epoch
V1
go . => va !, bleu 1.000
i lost . => j’ai perdu ., bleu 1.000
he’s calm . => il est riche ., bleu 0.658
i’m home . => je suis chez moi ., bleu 1.000
V2
go . => va !, bleu 1.000
i lost . => j’ai perdu ., bleu 1.000
he’s calm . => il est ., bleu 0.658
i’m home . => je suis chez moi ., bleu 1.000
Put all the changes before 、 The modified code :
decoder
【 Before amendment 】
class Seq2SeqDecoder(d2l.Decoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0, **kwargs):
super(Seq2SeqDecoder, self).__init__(**kwargs)
# The decoder should have its own embedding layer , Because translate one English and one French
self.embedding = nn.Embedding(vocab_size, embed_size)
# It is assumed that encoder Hidden layer size and decoder The size of the hidden layer is the same
self.rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers, dropout=dropout)
# Make one vocab_size The classification of
self.dense = nn.Linear(num_hiddens, vocab_size)
# enc The output of has two parts :outputs and state, as long as state
def init_state(self, enc_outputs, *args):
return enc_outputs[1]
# If there is no context operation , That is an ordinary rnn, There's no difference .
def forward(self, X, state):
# Put the time step ahead
X = self.embedding(X).permute(1, 0, 2)
''' Context operations . here state[-1] Get is “ In the top right corner ”H( This H Fusion and all information ) If state yes 【2,4,16】 Of , that state[-1] Namely 【1,4,16】 Of .repeat Repeat time steps . such , Every time step can use the last H Information , With new input X do concat operation ( This is why the decoder self.rnn yes ebd_size + num_hiddens Why ). If state[-1] yes 【1,4,16】, The time step is 7, After that, it is 【7,4,16】 Of (7 Time steps ,4 yes batch_size,16 yes state Number of hidden cells ). '''
context = state[-1].repeat(X.shape[0], 1, 1)
X_and_context = torch.cat((X, context), dim=2)
output, state = self.rnn(X_and_context, state)
# Adjust the dimension back (batch_size, num_step, vocab_Size)
output = self.dense(output).permute(1, 0, 2)
return output, state
【 After correction -V1】
See the following for correction reasons “ Training part ”
class Seq2SeqDecoder(d2l.Decoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0, **kwargs):
super(Seq2SeqDecoder, self).__init__(**kwargs)
# The decoder should have its own embedding layer , Because translate one English and one French
self.embedding = nn.Embedding(vocab_size, embed_size)
# It is assumed that encoder Hidden layer size and decoder The size of the hidden layer is the same
self.rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers, dropout=dropout)
# Make one vocab_size The classification of
self.dense = nn.Linear(num_hiddens, vocab_size)
# enc The output of has two parts :outputs and state, as long as state
def init_state(self, enc_outputs, *args):
return enc_outputs[1]
# If there is no context operation , That is an ordinary rnn, There's no difference .
def forward(self, X, enc_state, state=None):
# Put the time step ahead
X = self.embedding(X).permute(1, 0, 2)
''' Context operations . here state[-1] Get is “ In the top right corner ”H( This H Fusion and all information ) If state yes 【2,4,16】 Of , that state[-1] Namely 【1,4,16】 Of .repeat Repeat time steps . such , Every time step can use the last H Information , With new input X do concat operation ( This is why the decoder self.rnn yes ebd_size + num_hiddens Why ). If state[-1] yes 【1,4,16】, The time step is 7, After that, it is 【7,4,16】 Of (7 Time steps ,4 yes batch_size,16 yes state Number of hidden cells ). '''
context = enc_state[-1].repeat(X.shape[0], 1, 1)
X_and_context = torch.cat((X, context), dim=2)
output, state = self.rnn(X_and_context, state)
# Adjust the dimension back (batch_size, num_step, vocab_Size)
output = self.dense(output).permute(1, 0, 2)
return output, state
The key
# A key part :
def forward(self, X, enc_state, state=None):
# X: (batch_size, num_step, emb_size)
X = nn.Embedding(X).permute(1, 0, 2)
context = enc_state[-1].repeat(X.shape[0], 1, 1) # (num_step, batch_size, num_hidden)
X_and_Context = torch.cat((X, context), dim=2) # (num_step, batch_size, emb_size + num_hidden)
# If state == None, that nn.GRU.forward The second parameter in is None, It will generate automatically (num_layer, batch_size, num_hiddens) Of all the 0 tensor
output, state = self.rnn(X_and_Context, state) # (num_step, batch_size, num_hidden)
output = self.dense(output).permute(1, 0, 2)
return output, state
【 After correction -V2-My】
stay V1 On the basis of , Add modifications to this class :
#@save
class EncoderDecoder(nn.Module):
""" Encoder - Base class of decoder architecture """
def __init__(self, encoder, decoder, **kwargs):
super(EncoderDecoder, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
def forward(self, enc_X, dec_X, *args):
enc_outputs = self.encoder(enc_X, *args)
dec_state = self.decoder.init_state(enc_outputs, *args)
return self.decoder(dec_X, dec_state, dec_state)
【 Before revision The prediction part of the code 】
#@save
def predict_seq2seq(net, src_sentence, src_vocab, tgt_vocab, num_steps,
device, save_attention_weights=False):
""" Prediction from sequence to sequence model """
# When forecasting, it will net Set to evaluation mode
net.eval()
src_tokens = src_vocab[src_sentence.lower().split(' ')] + [
src_vocab['<eos>']]
enc_valid_len = torch.tensor([len(src_tokens)], device=device)
src_tokens = d2l.truncate_pad(src_tokens, num_steps, src_vocab['<pad>'])
# Add batch axis
enc_X = torch.unsqueeze(
torch.tensor(src_tokens, dtype=torch.long, device=device), dim=0)
enc_outputs = net.encoder(enc_X)
dec_state = net.decoder.init_state(enc_outputs, enc_valid_len)
# Add batch axis
dec_X = torch.unsqueeze(torch.tensor(
[tgt_vocab['<bos>']], dtype=torch.long, device=device), dim=0)
output_seq, attention_weight_seq = [], []
for _ in range(num_steps):
Y, dec_state = net.decoder(dec_X, dec_state)
# We use the morpheme with the highest probability of prediction , As the input of the decoder in the next time step
dec_X = Y.argmax(dim=2)
pred = dec_X.squeeze(dim=0).type(torch.int32).item()
# Save attention weight ( Discussed later )
if save_attention_weights:
attention_weight_seq.append(net.decoder.attention_weights)
# Once the sequence ends, the word element is predicted , The generation of the output sequence is completed
if pred == tgt_vocab['<eos>']:
break
output_seq.append(pred)
return ' '.join(tgt_vocab.to_tokens(output_seq)), attention_weight_seq
【 After revision Code 】
#@save
def predict_seq2seq(net, src_sentence, src_vocab, tgt_vocab, num_steps,
device, save_attention_weights=False):
""" Prediction from sequence to sequence model """
# When forecasting, it will net Set to evaluation mode
net.eval()
src_tokens = src_vocab[src_sentence.lower().split(' ')] + [
src_vocab['<eos>']]
enc_valid_len = torch.tensor([len(src_tokens)], device=device)
src_tokens = d2l.truncate_pad(src_tokens, num_steps, src_vocab['<pad>'])
# Add batch axis
enc_X = torch.unsqueeze(
torch.tensor(src_tokens, dtype=torch.long, device=device), dim=0)
enc_outputs = net.encoder(enc_X)
dec_state = net.decoder.init_state(enc_outputs, enc_valid_len)
# Add batch axis
dec_X = torch.unsqueeze(torch.tensor(
[tgt_vocab['<bos>']], dtype=torch.long, device=device), dim=0)
output_seq, attention_weight_seq = [], []
state = None # V2 The revision code of the version is replaced here with state = dec_state
for _ in range(num_steps):
Y, state = net.decoder(dec_X, dec_state, state)
# We use the morpheme with the highest probability of prediction , As the input of the decoder in the next time step
# dim=2 yes vocab dimension
dec_X = Y.argmax(dim=2)
pred = dec_X.squeeze(dim=0).type(torch.int32).item()
# Save attention weight ( Discussed later )
if save_attention_weights:
attention_weight_seq.append(net.decoder.attention_weights)
# Once the sequence ends, the word element is predicted , The generation of the output sequence is completed
if pred == tgt_vocab['<eos>']:
break
output_seq.append(pred)
return ' '.join(tgt_vocab.to_tokens(output_seq)), attention_weight_seq
Here is my experience of learning this part , And tidy up the mess , And answer why bathe God decoder There are also problems .
quote :
Sun Xiaochuan -7742 The dynamics of the - Bili, Bili (bilibili.com)
9.7. Sequence to sequence learning (seq2seq) — Hands-on deep learning 2.0.0-beta0 documentation (d2l.ai)—— Discussion area
First of all, it's about nn.RNN【nn.LSTM,nn.GRU Empathy 】.
nn.RNN() initialization Parameters needed when :(vocab_size,num_hiddens,num_layers)
While calling net() namely forward Method time , The parameters that need to be passed in are X Input and state Hidden state .
Initialize hidden state state Parameters needed when :(num_layers, batch_size, num_hiddens)
secondly ,train and predict There is an essential difference between :train The time is known num_step Of , Input X yes (batch_size, num_step) Of , So in decoder Call inside self.rnn() Actually, it was called only once !
# A key part :
def forward(self, X, enc_state, state=None):
# X: (batch_size, num_step, emb_size)
X = nn.Embedding(X).permute(1, 0, 2)
context = enc_state[-1].repeat(X.shape[0], 1, 1) # (num_step, batch_size, num_hidden)
X_and_Context = torch.cat((X, context), dim=2) # (num_step, batch_size, emb_size + num_hidden)
# If state == None, that nn.GRU.forward The second parameter in is None, It will generate automatically (num_layer, batch_size, num_hiddens) Of all the 0 tensor
output, state = self.rnn(X_and_Context, state) # (num_step, batch_size, num_hidden)
output = self.dense(output).permute(1, 0, 2)
return output, state
Why do you say that? ? Here can be written ” Start from scratch rnn" For the calculation function in :
We have permute 了 , Put the time dimension into the first dimension . stay nn.GRU.forward When called , There is actually a for Cyclic 【 It looks like this 】, Because the time step is known during training , So the hidden state is forward The time is Automatic concealment The update of :
# Calculation . Give a small batch , Count all the time steps inside , Get the output .
# input It includes all the time steps (X_0 To X_t),state Is the hidden state of the last operation , params Is a parameter that can be learned
def rnn(inputs, state, params):
W_xh, W_hh, b_h, W_hq, b_q = params
H, = state # Here is a tuple, But there is only one element
outputs = []
for X in inputs: # inputs It's a three-dimensional matrix :( Time step ,batch_size, one_hot Long ), In this way, the cycle will be divided into time steps , So the front should be transposed
H = torch.tanh(torch.matmul(X, W_xh) + torch.matmal(H, W_hh) + b_h)
Y = torch.matmul(H, W_hq) + b_q # Y Is the current time step to predict who the next word is , But here is a for loop , So we need to append
outputs.append(Y)
# cat Then there is a two-dimensional matrix , Think of it as n Matrices are stacked vertically . The number of columns is still vocab_size, The number of lines is batch_size * Time steps
return torch.cat(outputs, dim=0), (H, )
For the modified version V1, At the beginning , from 0 Handwriting rnn Be right, too state Do initialization all 0 operation (init_state function ), If The second parameter is passed None, Will not affect initialization ( And it didn't write at all when encoding state, By default, it will be initialized to 0).
For the modified version V2, The parameters passed in during training are the same , The effect is the same as that of Mu God , The implicit state of the decoder is initialized to the output of the encoder .
So for training , Mu God code 【 Before revision 】 It's also OK , because :
def forward(self, X, state):
# Put the time step ahead
X = self.embedding(X).permute(1, 0, 2)
''' Context operations . here state[-1] Get is “ In the top right corner ”H( This H Fusion and all information ) If state yes 【2,4,16】 Of , that state[-1] Namely 【1,4,16】 Of .repeat Repeat time steps . such , Every time step can use the last H Information , With new input X do concat operation ( This is why the decoder self.rnn yes ebd_size + num_hiddens Why ). If state[-1] yes 【1,4,16】, The time step is 7, After that, it is 【7,4,16】 Of (7 Time steps ,4 yes batch_size,16 yes state Number of hidden cells ). '''
context = state[-1].repeat(X.shape[0], 1, 1)
X_and_context = torch.cat((X, context), dim=2)
output, state = self.rnn(X_and_context, state)
# Adjust the dimension back (batch_size, num_step, vocab_Size)
output = self.dense(output).permute(1, 0, 2)
return output, state
Even if there is only one state, But the cycle of time step is self.rnn.forward Made in , therefore You can still guarantee that every input is X And the hidden state of the last encoder concat get up .【 Here's a long winded sentence , Because the time step is known during training , And we have repeat too state[-1],so…】
however For training, it's G 了 .
for _ in range(num_steps):
Y, dec_state = net.decoder(dec_X, dec_state)
# We use the morpheme with the highest probability of prediction , As the input of the decoder in the next time step
dec_X = Y.argmax(dim=2)
pred = dec_X.squeeze(dim=0).type(torch.int32).item()
# Save attention weight ( Discussed later )
if save_attention_weights:
attention_weight_seq.append(net.decoder.attention_weights)
# Once the sequence ends, the word element is predicted , The generation of the output sequence is completed
if pred == tgt_vocab['<eos>']:
break
output_seq.append(pred)
return ' '.join(tgt_vocab.to_tokens(output_seq)), attention_weight_seq
Because it's prediction , I don't know how long the time step is , Can only Write an explicit for loop ( Not before self.rnn.forward Implicit in for loop ), therefore net.decoder( That is to say forward function ) can Called more than once !!
That's in the original decoder When called , Just G 了 , because state Obviously, it changes every time … At this time, we can see dec_X( That is input ) yes batch_size = 1, num_step = 1 Of , So every time X_and_context Is not the same , The fundamental It's not the end result of the encoder , But last time decoder Output 【 forward In the function context And rnn Of initial hidden layer Coupled ( All input parameters are used state )】
So we have to separate ——enc_state Two things should be done :
1、 Initialize the decoder state;
2、 Add ( The addition here is concat,inception Type instead of resnet type )enc_state
So we're gonna Decoupling , Make two variables to record .【V1,V2 The effect is ok , But I think V2 Better , More reasonable 】:
state = dec_state
for _ in range(num_steps):
Y, state = net.decoder(dec_X, dec_state, state)
# We use the morpheme with the highest probability of prediction , As the input of the decoder in the next time step
# dim=2 yes vocab dimension
dec_X = Y.argmax(dim=2)
pred = dec_X.squeeze(dim=0).type(torch.int32).item()
# Save attention weight ( Discussed later )
if save_attention_weights:
attention_weight_seq.append(net.decoder.attention_weights)
# Once the sequence ends, the word element is predicted , The generation of the output sequence is completed
if pred == tgt_vocab['<eos>']:
break
output_seq.append(pred)
return ' '.join(tgt_vocab.to_tokens(output_seq)), attention_weight_seq
边栏推荐
- Chris LATTNER, the father of llvm: why should we rebuild AI infrastructure software
- kubeadm系列-01-preflight究竟有多少check
- [牛客网刷题 Day4] JZ32 从上往下打印二叉树
- Count of C # LINQ source code analysis
- 暑假第一周
- 使用arm Neon操作,提高内存拷贝速度
- Solution to the problem of the 10th Programming Competition (synchronized competition) of Harbin University of technology "Colin Minglun Cup"
- Halcon clolor_ pieces. Hedv: classifier_ Color recognition
- [daiy4] copy of JZ35 complex linked list
- Tips 1: Web video playback code
猜你喜欢
![[daiy4] copy of JZ35 complex linked list](/img/bc/ce90bb3cb6f52605255f1d6d6894b0.png)
[daiy4] copy of JZ35 complex linked list

Guess riddles (142)

Classification of plastic surgery: short in long long long

My experience from technology to product manager
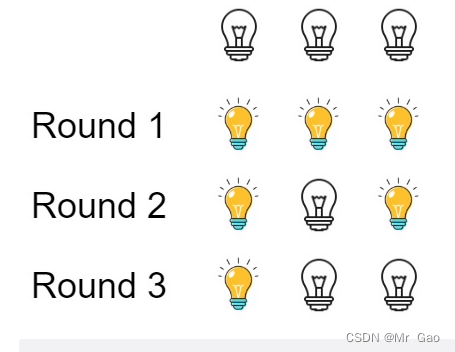
319. Bulb switch
![[Niuke brush questions day4] jz55 depth of binary tree](/img/f7/ca8ad43b8d9bf13df949b2f00f6d6c.png)
[Niuke brush questions day4] jz55 depth of binary tree
Confusing basic concepts member variables local variables global variables
Add discount recharge and discount shadow ticket plug-ins to the resource realization applet

Programming implementation of ROS learning 2 publisher node
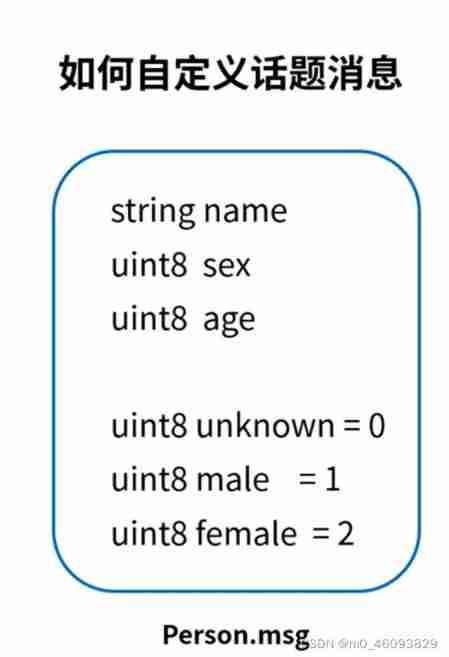
ROS learning 4 custom message
随机推荐
Digital analog 1: linear programming
JS asynchronous error handling
Array,Date,String 对象方法
File server migration scheme of a company
Latex improve
[牛客网刷题 Day4] JZ55 二叉树的深度
Golang foundation -- map, array and slice store different types of data
Wechat H5 official account to get openid climbing account
Codeforces Round #648 (Div. 2) E.Maximum Subsequence Value
Wheel 1:qcustomplot initialization template
AUTOSAR从入门到精通100讲(103)-dbc文件的格式以及创建详解
容易混淆的基本概念 成员变量 局部变量 全局变量
LLVM之父Chris Lattner:为什么我们要重建AI基础设施软件
Blue Bridge Cup provincial match simulation question 9 (MST)
RT thread kernel quick start, kernel implementation and application development learning with notes
C#图像差异对比:图像相减(指针法、高速)
Mathematical modeling: factor analysis
Mengxin summary of LCs (longest identical subsequence) topics
Oracle advanced (III) detailed explanation of data dictionary
Mengxin summary of LIS (longest ascending subsequence) topics