当前位置:网站首页>Beautiful soup parsing and extracting data
Beautiful soup parsing and extracting data
2022-07-05 08:44:00 【m0_ forty-six million ninety-three thousand eight hundred and t】
Catalog
Two 、 Parse and get the desired content in the web page
1.2 Downward traversal of tag tree .contents and .children And .descendants
1.3 Up traversal of tag tree .parent .parents
1.5 Extract information :.string、.strings、.stripped_strings
3.2 Get the attribute value in the node
One 、 install Beautiful soup
This article is also inspired by Cui Qingcai , Then I sorted it out according to my own ideas , So I won't repeat the content here . You can refer to cuiqingcai's website . Put a link here :https://cuiqingcai.com/5548.html
Two 、 Parse and get the desired content in the web page
Beautiful Soup It is a powerful library integrating parsing and extracting data ( It supports python In the standard library HTML Parser , It also supports some third-party parsers (lxml,html5li)) the BeautifulSoup After the parsing , It will be complicated HTML The document is transformed into a complex tree structure , Each label corresponds to a node , Every node is python object , also BeautifulSoup Provides common traversal , lookup , How to modify the parse tree , It can be downloaded from HTML or XML Extract data from files .
First look python Comparison of supported parsers :
| Parser | Usage method | advantage | Inferiority |
|---|---|---|---|
| Python Standard library html.parser | BeautifulSoup(markup, "html.parser") |
|
|
lxml HTML Parser Need to install lxml library | BeautifulSoup(markup, "lxml") |
|
|
lxml XML Parser Need to install lxml library |
|
|
|
html5lib Need to install html5lib library | BeautifulSoup(markup, "html5lib") |
|
|
Recommended lxml As a parser , Because it's more efficient . stay Python2.7.3 Previous versions and Python3 in 3.2.2 Previous version , Must install lxml or html5lib, Because of those Python Version of the standard library built in HTML The analytical method is not stable enough .
Na Jing BeautifulSoup All objects after parsing can be summarized as 4 Kind of :
Tag(Tagl Among the objects are name Properties and attrs attribute )
NavigableString
BeautifulSoup
Comment
namely :
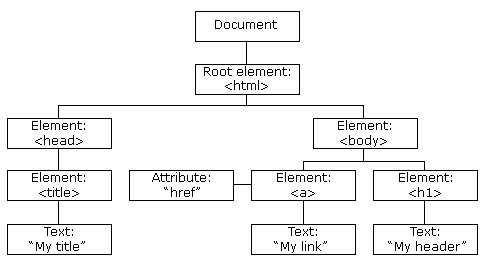
Yes HTML The basic people all know ,HTML The most important thing in is the label , Different labels have different functions , There are attributes and element contents in the tag , So we start with labels , Step by step analysis beautiful soup How to extract HTML Data .
1、 Traversal of tag tree
1.1 soup.<tag>
Want to get tags and their contents , The easiest way is to tell it what you want tag Of name. Anything that exists in HTML All tags in grammar can be used soup.<tag> Visit to get , When HTML There are multiple identical in the document <tag> Corresponding content ,soup.<tag> Return to the first .
such as :
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<div cless='out_wrapper'>
<div>
<h1>The Dormouse's story</h1>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
</div>
</div>
</body>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.title)
print(soup.head)
print(soup.p)The operation results are as follows :
<title>The Dormouse's story</title>
<div class="out_wrapper">
<div>
<h1>The Dormouse's story</h1>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
</div>
</div>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.
</p> Look at the results : First print out title node Add the text inside , Next , We tried to choose again div node , The result also returns nodes Add all the contents inside , And notice though HTML There are two in the web page div But the result only outputs the outermost layer, which is the first one found div. Last , I chose p node . At this time, it should be noted that the output result is only the first p Nodes and their contents , The back ones p Node is not selected . in other words , When there are multiple nodes , This selection method will only output the first matching node , Other internal or rear nodes will not output .
1.2 Downward traversal of tag tree .contents and .children And .descendants
Beautiful Soup In addition to returning the tag and its contents according to the name of the tag , Many properties are also provided for us to traverse the tag tree , such as .contents and .chaldren,.descendants All are tag Object properties , among .contents Attributes can take tag The direct child nodes of are output in a list ;.children Properties and .descendants What's returned is the generator ..children The return is tag A generator of direct descendants of tags ,.descendants The return is tag Label all descendants of the generator
for example :
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<div class='out_wrapper'>
<div>
<h1>The Dormouse's story</h1>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
</div>
</div>
</body>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')# Instantiation
print(soup.p.contents)
print('------'*10)
print(soup.p.children)
for i,child in enumerate(soup.p.children):
print(i,child)
['Once upon a time there were three little sisters; and their names were\n
', <a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>, ',\n ', <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, ' and\n ', <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>, ';\n
and they lived at the bottom of a well.\n ']
------------------------------------------------------------
<list_iterator object at 0x000001FDBC52A430>
0 Once upon a time there were three little sisters; and their names were
1 <a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>
2 ,
3 <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>
4 and
5 <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
6 ;
and they lived at the bottom of a well. According to the results, we can see : When we want to get p Child nodes of , The result is returned in the form of a list p All of the labels Direct child nodes ; So .contents The result of the attribute is a list of direct child nodes ..children Property returns the generator , Through traversal, we can get tag All child nodes in the tag . ( Remember here : It's not just labels that count as child nodes , String is also )
Then you will find the child nodes , Let's see how to find the descendant node : Page content unchanged
print(soup.div.descendants)
for i,child in enumerate(soup.div.descendants):
print(i,child)Output results :
<generator object Tag.descendants at 0x0000018CAAB76900>
0
1 <div>
<h1>The Dormouse's story</h1>
<p class="story">Once upon a time there were three little sisters; and their
names were
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
</div>
2
3 <h1>The Dormouse's story</h1>
4 The Dormouse's story
5
6 <p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.
</p>
7 Once upon a time there were three little sisters; and their names were
8 <a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>
9 Elsie
10 ,
11 <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>
12 Lacie
13 and
14 <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
15 Tillie
16 ;
and they lived at the bottom of a well.
17
18 <p class="story">...</p>
19 ...
20
21You can see through the results .descendants What is returned is a generator type , Then we traverse , Future generations will output from generation to generation , The last generation goes all the way to the content in the element .
1.3 Up traversal of tag tree .parent .parents
Or the content of the webpage above , This time we come to get a Labeled .parent
print(soup.a.parent)Output results :
<p class="story">Once upon a time there were three little sisters; and their
names were
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.
</p>According to the results, we can get .parent Attribute can output the label's immediate parent node and all its contents . Guess .parents What should be returned is a generator , Traverse to get all the ancestor nodes of the tag . Check it out
print(soup.a.parents)
print('------'*10)
for i,child in enumerate(soup.a.parents):
print(i,child)<generator object PageElement.parents at 0x000002AE6F105890>
------------------------------------------------------------
0 <p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.
</p>
1 <div>
<h1>The Dormouse's story</h1>
<p class="story">Once upon a time there were three little sisters; and their
names were
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
</div>
2 <div cless="out_wrapper">
<div>
<h1>The Dormouse's story</h1>
<p class="story">Once upon a time there were three little sisters; and their
names were
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
</div>
</div>
3 <body>
<div cless="out_wrapper">
<div>
<h1>The Dormouse's story</h1>
<p class="story">Once upon a time there were three little sisters; and their
names were
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
</div>
</div>
</body>
4 <html><head><title>The Dormouse's story</title></head>
<body>
<div cless="out_wrapper">
<div>
<h1>The Dormouse's story</h1>
<p class="story">Once upon a time there were three little sisters; and their
names were
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
</div>
</div>
</body>
</html>
5 <html><head><title>The Dormouse's story</title></head>
<body>
<div cless="out_wrapper">
<div>
<h1>The Dormouse's story</h1>
<p class="story">Once upon a time there were three little sisters; and their
names were
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
</div>
</div>
</body>
</html>The result proves our conjecture :.parents The return is a generator , Traversal can get all the ancestor nodes of the tag .
I have to emphasize again here , We write here soup.a.parent, What we found was ~ first a label .
Finally, let's take a look at Parallel traversal of the label book , Look for brother nodes
1.4 Parallel traversal of label tree : .next_sibling and .previous_sibling And .next_siblings and .previous_siblings
Let's look at an example : The content of the web page has not changed , But I adjusted the format , hold a The spaces between labels have been deleted , because Beautiful Soup When parsing, spaces also count
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<div class='out_wrapper'>
<div>
<h1>The Dormouse's story</h1>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>and<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
</div>
</div>
</body>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.a.next_sibling)
print('------'*10)
print(soup.a.previous_sibling)
print('------'*10)
for i,child in enumerate(soup.a.next_siblings):
print(i,child)
print('------'*10)
print(type(soup.a.previous_siblings))
print('------'*10)
for i,child in enumerate(soup.a.previous_siblings):
print(i,child)
print('------'*10)
It is not difficult for us to reach such a conclusion by outputting the results : next_sibling and previous_sibling Get the next... Of the node respectively One And on One Brother element ,next_siblings and previous_siblings Then return the generators of all the previous and subsequent sibling nodes respectively .
Through the above three sections , We learn to pass :
Down traversal :.contents and .children And .descendants
Up traversal : .parent .parents
Parallel traversal : .next_sibling and .previous_sibling And .next_siblings and .previous_siblings
Three traversal methods , adopt tag Tag attributes to traverse the tag tree , But did you find out tag These three traversal methods of tag properties , All you get is the whole label , Failed to help us get the element content in the tag directly , That is, the element node . What should I do if I want to get the element node ?
1.5 Extract information :.string、.strings、.stripped_strings
.string and .strings All are NavigableString Object properties , Through them, you can get the text content in the tag .
Let's start with an example :
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<div class='out_wrapper'>
<div>
<h1>The Dormouse's story</h1>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>and<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
</div>
</div>
</body>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.h1.string)
print(type(soup.h1.string))
print('------'*10)
print(soup.p.string)
print(type(soup.div.string))
print('------'*10)
print(soup.a.string)
print(type(soup.a.string))
Output results :
The Dormouse's story
<class 'bs4.element.NavigableString'>
------------------------------------------------------------
None
<class 'NoneType'>
------------------------------------------------------------
Elsie
<class 'bs4.element.Comment'>According to the output , We need to make the following points :
1.string and strings And .stripped_strings Properties are all NavigableString Object properties , But because of Comment The object is of a special type NavigableString object . So you can also use string perhaps .strings And .stripped_strings Property to get the annotation text content contained in the node element .
2. If tag only one NavigableString type /comment Child node of type , So this tag have access to .string Get the child node :
3. If tag Contains multiple child nodes ,tag You can't be sure .string Method should call the contents of which child node , here .string The output of is None , As in this example, output p.string, Now we all know , here Beautiful Soup What we found was the first p, So this one p There are multiple child nodes ,Beautiful Soup Unable to determine which content to output , Therefore, the output results None. Is there anyone who has the same question as me :”p There is only one string in the tag ? That's equivalent to only one NavigableString Child nodes of type ? Then why output None? Let's take another look with this question .strings To output p All strings in the tag .strings What's returned is the generator , So let's go through it :
for str in soup.p.strings:
print(str)Output results :
Once upon a time there were three little sisters; and their names were
,
Lacie
and
Tillie
;
and they lived at the bottom of a well.Then output the result through this , Do you have a deeper understanding .string or .strings It's locked tag All strings of each child node under the tag . therefore p.string I don't know which one to output .
Finally, let me mention .stripped_strings This attribute can remove redundant blank content . It's advanced .strings 了 .
So that's all we have to say about common Traverse the document tree Of attribute 了 . That's the question , If I want to get all div label , Or I just want to get the one without any attribute value div Tag or I just want to choose to have a special ip Value or class Label of the value ( Here, for example. id='link2' Of a label ,class='story' Second of p label ), It seems a little laborious to traverse the document tree with attribute method . So let's look at beautiful soup Advanced Search document tree Of Method .
2、 Search of tag tree
2.1 find() and find_all()
Beautiful Soup A lot of search methods are defined , Here we can focus on find() and find_all() Method ; that find() Methods and find_all() Method usage is similar to , So let's introduce find_all() Method .
You can put a string 、 list 、 Regular expressions 、True、 Or a method is passed as a parameter find_all() In the method ,find_all() It will query all qualified elements according to your needs .
find_all Of API as follows :
find_all(self, name=None, attrs={}, recursive=True, text=None,limit=None, **kwargs):
(1)name Parameters :
adopt name Parameters , We can find according to the node name Label class elements , The result is a list type .
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<div class='out_wrapper'>
<div>
<h1>The Dormouse's story</h1>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
</div>
</div>
</body>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.find_all(name='p'))
print('------'*10)
print(soup.find_all(name=['a','p']))
print('------'*10)
print(type(soup.find_all(name='p')[0]))
for tag in soup.find_all(name='p'):
print(tag.find_all(name='a'))
Output results :
[<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.
</p>, <a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>, <p class="story">...</p>]
------------------------------------------------------------
<class 'bs4.element.Tag'>
[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
[]Here we call twice find_all(), The first time I introduced name Parameter is p, That returns a length of 2 One of contains all p List of tags . The second time it was introduced name The parameter is a list ['a','p'], The returned result is that the document contains all a label and p List of tags .
Also note that each element in the list is a Tag type , Therefore, you can further call tag Methods and properties in objects .
(2)attrs
adopt attrs Parameters , We can find according to the node attributes Label class elements ,attrs The parameter value is of dictionary type , The result is a list type .
example :
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.find_all(attrs={'id':'link1'}))
print('------'*10)
print(soup.find_all(attrs={'class':['out_wrapper','story']}))result :
[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]
------------------------------------------------------------
[<div class="out_wrapper">
<div>
<h1>The Dormouse's story</h1>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
</div>
</div>, <p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.
</p>, <p class="story">...</p>]You can see that we also called twice find_all() Method , The first time I want to query id yes link1 All nodes of , The result returns a length of 1 A list of , The second time I want to query the class name is out_wrapper and story All nodes of , therefore attrs Parameter value of class The value of is passed into a list , The result is a list of three elements , Just the label we want .
call find() and find_all() Method , Pass in the corresponding parameter , You can search the entire document tree , We have found what we want .
(3)keyword Parameters
Due to the use attrs To find the node we want, this method is commonly used , therefore Beautiful Soup It also provides us with a convenient way to write : about id,class And so on , We don't have to attrs To pass on , And use it directly id=‘link1'. The principle behind it is keyword Parameters are working , If the parameter of the name we specify is not Beautiful Soup Built in parameter name in search , that Beautiful Soup When searching, this parameter will be regarded as the specified name Tag To search for , So let's say we type in id='link1', that Beautiful Soup Search for each tag Of ”id” attribute .
for example :
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')# Instantiation
print(soup.find_all(id='link1'))
print('------'*10)
print(soup.find_all(class_=True))Output results :
[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]
------------------------------------------------------------
[<div class="out_wrapper">
<div>
<h1>The Dormouse's story</h1>
<p class="story">Once upon a time there were three little sisters; and
their names were
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
</div>
</div>, <p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.
</p>, <a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>, <p class="story">...</p>]What I want to explain is , because class stay python Is a keyword in , So we need to be able to class Add an underline to distinguish :class_=True, The returned result is all contained in the document tree class Attribute Tag A list of components , There are 6 individual Tag Element of type .
Use multiple parameters with specified names to filter tag Multiple attributes of :
for example :
import re
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.find_all(href=re.compile("elsie"), id='link1'))Output results :
[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]Small tip, In the future, I want to base it on frequently-used Attribute positioning , Then we can directly adopt this omission attrs Methods , If the attribute we want to locate is not commonly used , You can use attrs How to tell Beautiful Soup I want to find according to the attribute .
such as :
from bs4 import BeautifulSoup
data_soup = BeautifulSoup('<div data-foo="value">foo!</div>','lxml')
print(data_soup.find_all(data-foo="value"))Output results :
SyntaxError: expression cannot contain assignment, perhaps you meant
"=="? Then we change attrs:
print(data_soup.find_all(attrs={'data-foo':"value"}))Output results :
[<div data-foo="value">foo!</div>](4)recursive Parameters
call tag Of find_all() When the method is used ,Beautiful Soup Will retrieve the current tag All descendants of , For example, in the example just now classs_=true, The result returns the entire document tree species containing class Attribute tag, If you only want to search Current tab Direct child of , You can use parameters recursive=False , The returned result is still a list type .
For example, the document just now :
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
soup_body=soup.body
print(soup_body.find_all(class_=True,recursive=False))
Output results :
[<div class="out_wrapper">
<div>
<h1>The Dormouse's story</h1>
<p class="story">Once upon a time there were three little sisters; and
their names were
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
</div>
</div>]You can see , add recursive=False after , The result is only output body The direct child node under the label has class Attribute tag.
(5)limit Parameters
that find_all There is another method limit Parameters , When the number of search results reaches limit When the limit , Stop searching and return results , The result is a list type .
for example :
Or the document above :
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.find_all(class_=True,limit=1))Output results :
[<div class="out_wrapper">
<div>
<h1>The Dormouse's story</h1>
<p class="story">Once upon a time there were three little sisters; and
their names were
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
</div>
</div>]You can see , We still want to search all kinds of documents and books that contain class Label for property , There should be 6 individual Tag
But now I set limit=1, Therefore, the output result is only 1 individual Tag.
(6)string Parameters
adopt string Parameter can search the document according to the string content , The result is a list type .
for example :
It is still the document above :
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.find_all('a',string='Lacie'))Output results :
[<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]So far ,find_all() Methods 6 We will finish introducing the parameters , You can feel find_all() Very powerful, right . that find_all() Almost Beautiful Soup The most commonly used search method in . therefore Beautiful Soup It also provides abbreviations , You can omit the method name , for example :
Or the document tree above
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup(id='link1'))
print('------'*10)
print(soup.find_all(id='link1'))Output results ;
[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]
------------------------------------------------------------
[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]You can see soup(id='link1') And soup.find_all(id='link1') It's the same .
Finally, let's talk about find() Method ,find*() Of API as follows :
find(self, name=None, attrs={}, recursive=True, text=None,**kwargs)
You can see ,find() Methods and find_all() The parameters of the method are similar , Just not limit, Why? ? because find() Methods and find_all() Methods compared , Just missing one all, in other words find() Method , The return is The first matching element . Watch out! ,find() Method returns the element , It's not a list , And it's the first matching element . That's equivalent to default limit=1 Yes .
for example :
Or the document tree above :
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.find(class_=True))Output results :
<div class="out_wrapper">
<div>
<h1>The Dormouse's story</h1>
<p class="story">Once upon a time there were three little sisters; and
their names were
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
</div>
</div>What I call here is find Method , Then still use attribute search class_=True The label of , The only result returned is class='out_wrapper' The label of .
The last thing to say is this Beautiful Soup It also provides us with additional 10 Search methods , Among them are 5 And find_all() Have the same parameters , Yes 5 individual find() There are the same parameters , The difference is only that they search for different parts of the document .
find_all and find() Search only the child nodes of the current node , Sun node
find_parents() and find_parent(): The former searches all ancestor nodes , The latter searches for direct parent nodes
find_next_siblings and find_next_sibling: The former searches all sibling nodes behind the node , The latter searches the first sibling node behind the node
find_previous_siblings and find_previous_sibling: The former searches all the sibling nodes in front of the node , The latter searches the first sibling node in front of the node .
find_all_next() and find_next(): Both search all nodes behind this node , The former returns all qualified nodes , The latter returns the first eligible node .
find_all_previous() and find_previous(): Both search all nodes in front of this node , The former returns all qualified nodes , The latter returns the first eligible node .
But here's the thing : Only find_all() and find() Support recursive Parameters
2.2 CSS Selectors
Beautiful Soup Another kind of selector is also provided , That's it CSS Selectors , If the CSS If you are familiar with grammar , You can also use CSS Selector to choose what we want .
Use CSS When selecting , Only need to use Tag or Beautiful Soup Object call .select() Method , And will CSS The corresponding selector in the grammar ( Element selector ,id Selectors , Class selectors , Intersection selector , Union selector , Family selector , Attribute selector , Pseudo class selector ) As a parameter .select() The method can ,CSS The result returned by the selector is the list type .
for example :
from bs4 import BeautifulSoup
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<div class='out_wrapper'>
<div>
<h1>The Dormouse's story</h1>
<p class="story test">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
</div>
<ul class='list1' id='list-1'>
<li class='element'>How</li>
<li class='element'>are</li>
<li class='element'>you</li>
<li class='element'>?</li>
</ul>
<ul class='list2' id='list-2'>
<li class='element'>Fine</li>
<li class='element'>thank you </li>
<li class='element'>and you? </li>
</ul>
</div>
</body>
"""
soup = BeautifulSoup(html, 'lxml')
print(soup.select('#list-1'))
print('------'*10)
print(soup.select('#list-1 .element'))
print('------'*10)
print(soup.select('#link1,#link2,#link3'))
print('------'*10)
print(soup.select('.story.test'))
print('------'*10)
print(soup.select('#link1+a'))
print('------'*10)
print(soup.select('#link1~a'))
print('------'*10)
print(soup.select('a[href]'))
print('------'*10)
print(soup.select('a[href="http://example.com/elsie"]'))
print('------'*10)
print(soup.select('h1+p>:last-child'))
print('------'*10)
print(type(soup.select('#link1~a')[0]))Output results :
[<ul class="list1" id="list-1">
<li class="element">How</li>
<li class="element">are</li>
<li class="element">you</li>
<li class="element">?</li>
</ul>]
------------------------------------------------------------
[<li class="element">How</li>, <li class="element">are</li>, <li class="element">you</li>, <li class="element">?</li>]
------------------------------------------------------------
[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
------------------------------------------------------------
[<p class="story test">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.
</p>]
------------------------------------------------------------
[<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
------------------------------------------------------------
[<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
------------------------------------------------------------
[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
------------------------------------------------------------
[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]
------------------------------------------------------------
[<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
------------------------------------------------------------
<class 'bs4.element.Tag'>In the program above , We use class selectors , Descendant selector in family selector , Union selector , Intersection selector , The adjacent brother selector in the family selector and the universal brother selector in the family selector , Attribute selector , Pseudo class selector ; The returned results are consistent with CSS A list of selector nodes . for example soup.select('#list-1 .element') It's the choice id by list-1 The attribute under the element of is element All the descendants of , We can also see through the output results id by list-1 The attribute under the element is element All descendants of have been exported .
The last sentence prints out the types of elements in the list . You can see , The type is still Tag type . Therefore, we can nest and select the elements in the output list .
3. Extract information
In fact, this part should not be introduced here , But whether it is traversal or search , After getting the desired node, you can then extract the information in the label node , So I want to introduce how to extract information from tags after traversal and search . When introducing the traversal of the label tree , We introduced how to call . string Property to get the value of the text , So how to get the value of node attribute ? How to get the node name ? Now let's sort out how to extract the information in the tag node .
How to extract the attribute value and node name of a node .
3.1 Get node name
Every tag They all have their own names , adopt .name To get :
example :
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<div class='out_wrapper'>
<div>
<h1>The Dormouse's story</h1>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>and<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
</div>
</div>
</body>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')# Instantiation
print(soup.h1.parent.name)Output results :
div3.2 Get the attribute value in the node
Each node may have multiple attributes , such as id and class etc. , After selecting this node element , You can call .attrs Get all the properties of this node .
example :
It is still the document above :
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.div.attrs)
print('------'*10)
print(soup.find('a').attrs)
print('------'*10)
print(soup.select('p.story>:nth-child(2)')[0].attrs)
Output results :
{'class': ['out_wrapper']}
------------------------------------------------------------
{'href': 'http://example.com/elsie', 'class': ['sister'], 'id': 'link1'}
------------------------------------------------------------
{'href': 'http://example.com/lacie', 'class': ['sister'], 'id': 'link2'} You can see ,attrs The return result is The dictionary form , It combines all the attributes and attribute values of the selected node into a dictionary . What needs to be noted here is , Some return a string , Some return results are a list of strings . such as ,herf The value of the property is unique , The result is a single string . And for class, A node element may have more than one class, So the list is returned . In the actual process , We should pay attention to the judgment type .
If you want to get the specific attribute value of a certain attribute , That is equivalent to getting a key value from the dictionary , Just add the attribute name in square brackets . such as , To get class Property value of property , You can go through attrs['class'] To get ; It can also be done without writing attrs, Put square brackets directly after the node element , You can get the attribute value by passing in the attribute name . A sample of :
It is still the document above :
print(soup.a.attrs['id'])
print('------'*10)
print(soup.find('a')['class'])Output results :
link1
------------------------------------------------------------
['sister']3.3 Get content
It has been introduced above through .string To get the content in the tag node , I won't go into that here , But it needs to be emphasized that : Whether it is traversing the tag tree or searching the tag tree , When you locate the tag you want , Can pass again .string Property to get the string content of the label node .
In addition, there is another way get_text(),get_text() To get to the tag It contains All text content , Including children and grandchildren tag The content in , And take all the results as Unicode String returns : Examples are as follows :
from bs4 import BeautifulSoup
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<div class='out_wrapper'>
<div>
<h1>The Dormouse's story</h1>
<p class="story test">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
</div>
</div>
</body>
"""
soup = BeautifulSoup(html, 'lxml') # Instantiation
print(soup.select('.story'))
print('------'*10)
print(soup.select('.story')[0].get_text())
print('------'*10)
print(soup.select('.story')[0].get_text('/'))
print('------'*10)
print(soup.select('.story')[0].get_text('/',strip=True))
The output is as follows :
[<p class="story test">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.
</p>, <p class="story">...</p>]
------------------------------------------------------------
Once upon a time there were three little sisters; and their names were
,
Lacie and
Tillie;
and they lived at the bottom of a well.
------------------------------------------------------------
Once upon a time there were three little sisters; and their names were
/,
/Lacie/ and
/Tillie/;
and they lived at the bottom of a well.
------------------------------------------------------------
Once upon a time there were three little sisters; and their names were/,/Lacie/and/Tillie/;
and they lived at the bottom of a well.The above example not only verifies get_text() Method , still get_text() Two parameters are added to the method , Among them through get_text('/')
And its output results we know , adopt get_text('/',strip=True) And the result we know , We can set strip Parameter is True To remove the front and back blanks of the obtained text content .
Here we are ,Beautiful Soup The usage of is basically introduced , For details, please refer to the document :https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/#id42
边栏推荐
- Yolov4 target detection backbone
- Guess riddles (9)
- Example 007: copy data from one list to another list.
- 每日一题——输入一个日期,输出它是该年的第几天
- Array,Date,String 对象方法
- Latex improve
- Count of C # LINQ source code analysis
- It cold knowledge (updating ing~)
- location search 属性获取登录用户名
- Example 003: a complete square is an integer. It is a complete square after adding 100, and it is a complete square after adding 168. What is the number?
猜你喜欢

Example 005: three numbers sorting input three integers x, y, Z, please output these three numbers from small to large.
Bluebridge cup internet of things basic graphic tutorial - GPIO input key control LD5 on and off

猜谜语啦(3)

我从技术到产品经理的几点体会
每日一题——输入一个日期,输出它是该年的第几天
L298N module use
![[牛客网刷题 Day4] JZ55 二叉树的深度](/img/f7/ca8ad43b8d9bf13df949b2f00f6d6c.png)
[牛客网刷题 Day4] JZ55 二叉树的深度
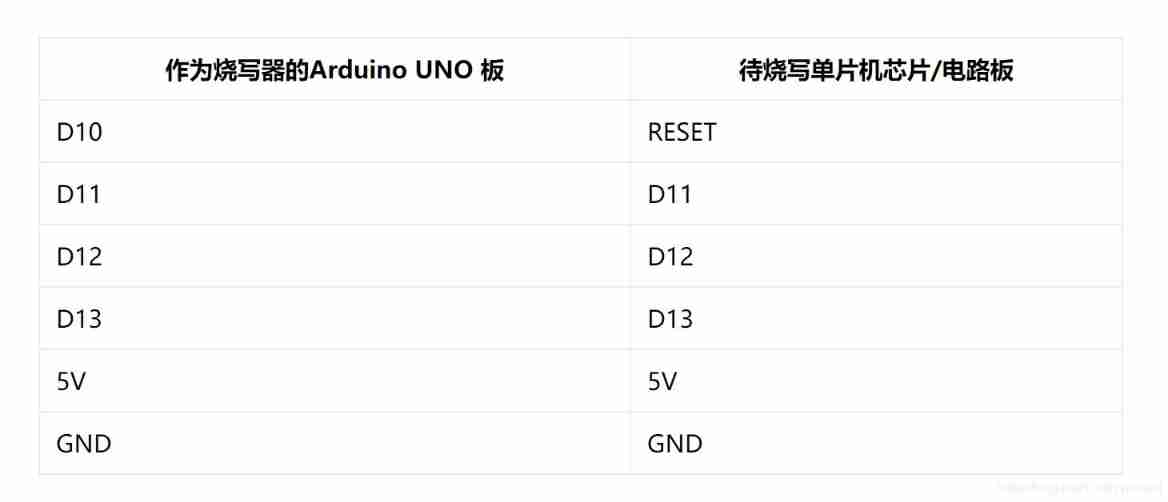
Arduino burning program and Arduino burning bootloader
Guess riddles (6)
Redis implements a high-performance full-text search engine -- redisearch
随机推荐
Digital analog 1: linear programming
猜谜语啦(8)
图解网络:什么是网关负载均衡协议GLBP?
golang 基础 —— golang 向 mysql 插入的时间数据和本地时间不一致
RT-Thread内核快速入门,内核实现与应用开发学习随笔记
L298N module use
Latex improve
Yolov4 target detection backbone
Run menu analysis
Cmder of win artifact
696. 计数二进制子串
PIP installation
资源变现小程序添加折扣充值和折扣影票插件
asp.net(c#)的货币格式化
Guess riddles (11)
Example 007: copy data from one list to another list.
JS asynchronous error handling
深度学习模型与湿实验的结合,有望用于代谢通量分析
Lori remote control commissioning record
Basic number theory -- Euler function