当前位置:网站首页>PG优化篇--执行计划相关项
PG优化篇--执行计划相关项
2022-08-05 10:51:00 【51CTO】
ENABLE_*参数
在PostgreSQL中有一些以“ENABLE_”开头的参数,这些参数提供了影响查询优化器选择不同执行计划的方法。有时,如果优化器为特定查询选择的执行计划并不是最优的,可以设置这些参数强制优化器选择一个更好的执行计划来临时解决这个问题。一般不会在PostgreSQL中配置来改变这些参数值的默认值,因为通常情况下,PostgreSQL不会走错执行计划。PostgreSQL走错执行计划是统计信息收集得不及时导致的,可通过更频繁地运行ANALYZE来解决这个问题,使用“ENABLE_”只是一个临时的解决方法。
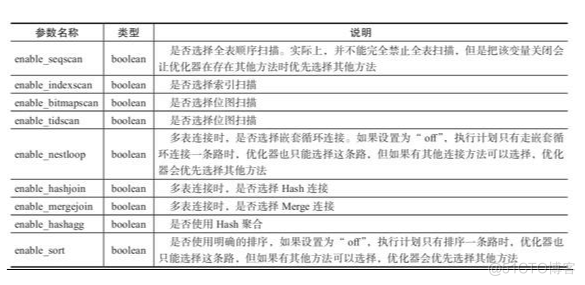
cost基准值参数
执行计划在选择最优路径时,不同路径的cost值只有相对意义,同时缩放它们将不会对不同路径的选择产生任何影响。默认情况下,它们以顺序扫描一个数据块的开销作为基准单位,也就是说,将顺序扫描的基准参数“seq_page_cost”默认设为“1.0”,其他开销的基准参数都对照它来设置。从理论上来说也可以使用其他基准方法,如以毫秒计的实际执行时间作基准,但这些基准方法可能会更复杂一些。
COST基准值参数
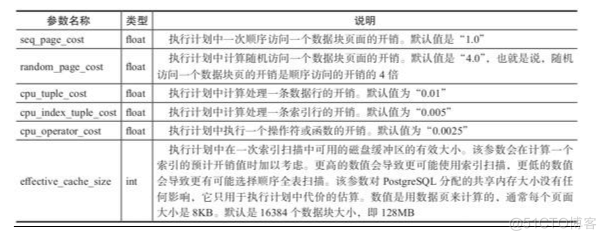
在上面的配置项中,“seq_page_cost”一般作为基准,不用改变。可能需要改变的是“random_page_cost”,如果在读数据时,数据基本都命中在内存中,这时随机读和顺序读的差异不大,可能需要把“random_page_cost”的值调得小一些。如果想让优化器偏向走索引,而不走全表扫描,可以把“random_page_cost”的值调得低一些。
统计信息的收集
信息主要是AutoVacuum进程收集的,用于查询优化时的代价估算。表和索引的行数、块数等统计信息记录在系统表“pg_class”中,其他的统计信息主要收集在系统表“pg_statistic”中。而Stats Collector子进程是PostgreSQL中专门的性能统计数据收集器进程,其收集的性能数据可以通过“pg_stat_*”视图来查看,这些性能统计数据对数据库活动的监控及分析性能有很大的帮助。
统计信息收集器配置项
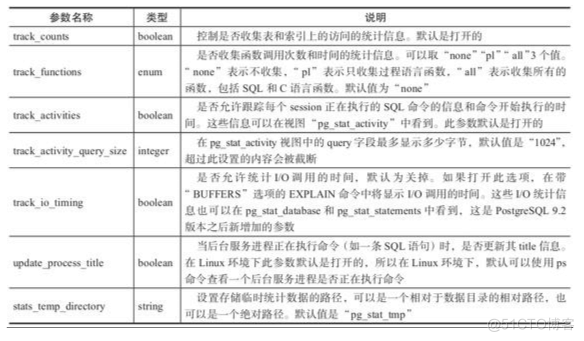
SQL执行的统计信息输出
可以使用以下4个boolean类型的参数来控制是否输出SQL执行过程的统计信息到日志中:
·log_statement_stats。
·log_parser_stats。
·log_planner_stats。
·log_executor_stats。
参数“log_statement_stats”控制是否输出所有SQL语句的统计信息,其他的参数控制每个SQL命令是否输出不同执行模块中的统计信息
手动收集统计信息
手动收集统计信息的命令是ANALYZE命令,此命令用于收集表的统计信息,然后把结果保存在系统表“pg_statistic”中。优化器可以使用收集到的统计信息来确定最优的执行计划。
在默认的PostgreSQL配置中,AutoVacuum守护进程是打开的,它能自动分析表、收集表的统计信息。当AutoVacuum进程关闭时,需要周期性地,或者在表的大部分内容变更后运行ANALYZE命令。准确的统计信息能帮助优化器生成最优的执行计划,从而改善查询的性能。比较常用的一种策略是每天在数据库比较空闲的时候运行一次VACUUM和ANALYZE命令。
ANALYZE命令的语法格式如下:
ANALYZE [ VERBOSE ] [ table [ ( column [, ...] ) ] ]
命令中的选项说明如下。
·VERBOSE:增加此选项将显示处理的进度以及表的一些统计信息。
·table:要分析的表名,如果不指定,则对整个数据库中的所有表进行分析。
·column:要分析的特定字段的名称。默认分析所有字段。
ANALYZE命令的应用示例
分析表“test01”中的“id1”和“id2”两个列
分析表“test01”中的所有列
ANALYZE命令只需在表上加一个读锁,因此它可以与表上的其他SQL命令并发执行。ANALYZE命令会收集表的每个字段的直方图和最常用数值的列表。
对于大表,ANALYZE命令只读取表的部分内容做一个随机抽样,不读取表的所有内容,这样就保证了即使是在很大的表上也只需要很少时间就可以完成统计信息的收集。统计信息只是近似的结果,即使表内容实际上没有改变,运行ANALYZE命令后EXPLAIN命令显示的执行计划中的COST值也会有一些变化。为了增加所收集的统计信息的准确度,可以增大随机抽样比例,这可以通过调整参数“default_statistics_target”来实现,该参数可在session级别设置,比如在分析不同的表时设置不同的值。在下面的示例中,假设表“test01”的行数较少,设置“default_statistics_target”为“500”,然后分析test01表,表“test02”行数较多,设置“default_statistics_target”为“10”,再分析test02表,命令如下:
也可以直接设置表的每个列的统计target值
ANALYZE命令的一个统计项是估计出现在每列的不同值的数目。仅仅抽样部分行,该统计项的估计值有时会很不准确,为了避免因此导致差的查询计划,可以手动指定这个列有多少个唯一值,其命令是“ALTER TABLE...ALTER COLUMN...SET (n_distinct=...)”,示例如下:
另外,如果表是有继承关系的其他子表的父表,还可以设置“n_distinct_inherited”,这样子表会继续父表的设置值,示例如下:
边栏推荐
- 用KUSTO查询语句(KQL)在Azure Data Explorer Database上查询LOG实战
- [Translation] Chaos Net + SkyWalking: Better observability for chaos engineering
- [Strong Net Cup 2022] WP-UM
- 导火索:OAuth 2.0四种授权登录方式必读
- L2-042 老板的作息表
- How OpenHarmony Query Device Type
- 如何选币与确定对应策略研究
- 2022杭电多校 第6场 1008.Shinobu Loves Segment Tree 规律题
- What are the standards for electrical engineering
- 《分布式云最佳实践》分论坛,8 月 11 日深圳见
猜你喜欢
Common operations of oracle under linux and daily accumulation of knowledge points (functions, timed tasks)
工程设备在线监测管理系统自动预警功能

产品太多了,如何实现一次登录多产品互通?

E-sports, convenience, efficiency, security, key words for OriginOS functions

一张图看懂 SQL 的各种 join 用法!
What are the standards for electrical engineering
Ali's new launch: Microservices Assault Manual, all operations are written out in PDF
gradle尚硅谷笔记

单片机:温度控制DS18B20

#yyds干货盘点#【愚公系列】2022年08月 Go教学课程 001-Go语言前提简介
随机推荐
Where is your most secretive personality?
Create a Dapp, why choose Polkadot?
Confessing in the era of digital transformation: Mai Cong Software allows enterprises to use data in the easiest way
Score interview (1)----related to business
PCB布局必知必会:教你正确地布设运算放大器的电路板
数据可视化(二)
登录功能和退出功能(瑞吉外卖)
2022杭电多校 第6场 1008.Shinobu Loves Segment Tree 规律题
产品太多了,如何实现一次登录多产品互通?
【 temperature warning program DE development 】 event driven model instance
The query that the user's test score is greater than the average score of a single subject
SMB + SMB2: Accessing shares return an error after prolonged idle period
RT - Thread record (a, RT, RT Thread version - Thread Studio development environment and cooperate CubeMX quick-and-dirty)
第五章:redis持久化,包括rdb和aof两种方式[通俗易懂]
提取人脸特征的三种方法
This notebook of concurrent programming knowledge points strongly recommended by Ali will be a breakthrough for you to get an offer from a big factory
[Strong Net Cup 2022] WP-UM
如何选币与确定对应策略研究
反射修改jsessionid实现Session共享
How does the official account operate and maintain?Public account operation and maintenance professional team