当前位置:网站首页>【硬核干货】数据分析哪家强?选Pandas还是选SQL
【硬核干货】数据分析哪家强?选Pandas还是选SQL
2022-07-05 19:13:00 【欣一2002】
又是新的一周,今天小编打算来讲一下Pandas和SQL之间语法的差异,相信对于不少数据分析师而言,无论是Pandas模块还是SQL,都是日常学习工作当中用的非常多的工具,当然我们也可以在Pandas模块当中来调用SQL语句,通过调用read_sql()方法
想要获取本篇教程的源代码,可在公众号后台回复【20220704】即可获取
建立数据库
首先我们通过SQL语句在新建一个数据库,基本的语法相信大家肯定都清楚,
CREATE TABLE 表名 (
字段名称 数据类型 ...
)那么我们来看一下具体的代码
import pandas as pd
import sqlite3
connector = sqlite3.connect('public.db')
my_cursor = connector.cursor()
my_cursor.executescript("""
CREATE TABLE sweets_types
(
id integer NOT NULL,
name character varying NOT NULL,
PRIMARY KEY (id)
);
...篇幅有限,详细参考源码...
""")同时我们也往这些新建的表格当中插入数据,代码如下
my_cursor.executescript("""
INSERT INTO sweets_types(name) VALUES
('waffles'),
('candy'),
('marmalade'),
('cookies'),
('chocolate');
...篇幅有限,详细参考源码...
""")我们可以通过下面的代码来查看新建的表格,并且转换成DataFrame格式的数据集,代码如下
df_sweets = pd.read_sql("SELECT * FROM sweets;", connector)output
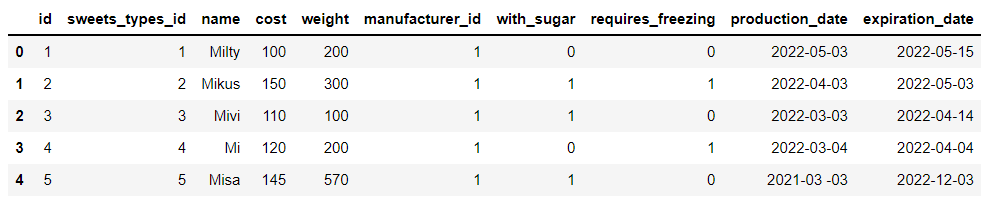
我们总共新建了5个数据集,主要是涉及到了甜品、甜品的种类以及加工和仓储的数据,而例如甜品的数据集当中主要包括的有甜品的重量、糖分的含量、生产的日期和过期的时间、成本等数据,以及
df_manufacturers = pd.read_sql("SELECT * FROM manufacturers", connector)output

加工的数据集当中则涉及到了工厂的主要负责人和联系方式,而仓储的数据集当中则涉及到了仓储的详细地址、城市所在地等等
df_storehouses = pd.read_sql("SELECT * FROM storehouses", connector)output

还有甜品的种类数据集,
df_sweets_types = pd.read_sql("SELECT * FROM sweets_types;", connector)output
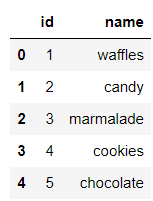
数据筛查
简单条件的筛选
接下来我们来做一些数据筛查,例如筛选出甜品当中重量等于300的甜品名称,在Pandas模块中的代码是这个样子的
# 转换数据类型
df_sweets['weight'] = pd.to_numeric(df_sweets['weight'])
# 输出结果
df_sweets[df_sweets.weight == 300].nameoutput
1 Mikus
6 Soucus
11 Macus
Name: name, dtype: object当然我们还可以通过pandas当中的read_sql()方法来调用SQL语句
pd.read_sql("SELECT name FROM sweets WHERE weight = '300'", connector)output

我们再来看一个相类似的案例,筛选出成本等于100的甜品名称,代码如下
# Pandas
df_sweets['cost'] = pd.to_numeric(df_sweets['cost'])
df_sweets[df_sweets.cost == 100].name
# SQL
pd.read_sql("SELECT name FROM sweets WHERE cost = '100'", connector)output
Milty针对文本型的数据,我们也可以进一步来筛选出我们想要的数据,代码如下
# Pandas
df_sweets[df_sweets.name.str.startswith('M')].name
# SQL
pd.read_sql("SELECT name FROM sweets WHERE name LIKE 'M%'", connector)output
Milty
Mikus
Mivi
Mi
Misa
Maltik
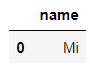
Macus当然在SQL语句当中的通配符,%表示匹配任意数量的字母,而_表示匹配任意一个字母,具体的区别如下
# SQL
pd.read_sql("SELECT name FROM sweets WHERE name LIKE 'M%'", connector)output

pd.read_sql("SELECT name FROM sweets WHERE name LIKE 'M_'", connector)output
复杂条件的筛选
下面我们来看一下多个条件的数据筛选,例如我们想要重量等于300并且成本价控制在150的甜品名称,代码如下
# Pandas
df_sweets[(df_sweets.cost == 150) & (df_sweets.weight == 300)].name
# SQL
pd.read_sql("SELECT name FROM sweets WHERE cost = '150' AND weight = '300'", connector)output
Mikus或者是筛选出成本价控制在200-300之间的甜品名称,代码如下
# Pandas
df_sweets[df_sweets['cost'].between(200, 300)].name
# SQL
pd.read_sql("SELECT name FROM sweets WHERE cost BETWEEN '200' AND '300'", connector)output
要是涉及到排序的问题,在SQL当中使用的是ORDER BY语句,代码如下
# SQL
pd.read_sql("SELECT name FROM sweets ORDER BY id DESC", connector)output

而在Pandas模块当中调用的则是sort_values()方法,代码如下
# Pandas
df_sweets.sort_values(by='id', ascending=False).nameoutput
11 Macus
10 Maltik
9 Sor
8 Co
7 Soviet
6 Soucus
5 Soltic
4 Misa
3 Mi
2 Mivi
1 Mikus
0 Milty
Name: name, dtype: object筛选出成本价最高的甜品名称,在Pandas模块当中的代码是这个样子的
df_sweets[df_sweets.cost == df_sweets.cost.max()].nameoutput
11 Macus
Name: name, dtype: object而在SQL语句当中的代码,我们需要首先筛选出成本最高的是哪个甜品,然后再进行进一步的处理,代码如下
pd.read_sql("SELECT name FROM sweets WHERE cost = (SELECT MAX(cost) FROM sweets)", connector)我们想要看一下是仓储的城市具体是有哪几个,在Pandas模块当中的代码是这个样子的,通过调用unique()方法
df_storehouses['city'].unique()output
array(['Moscow', 'Saint-petersburg', 'Yekaterinburg'], dtype=object)而在SQL语句当中则对应的是DISTINCT关键字
pd.read_sql("SELECT DISTINCT city FROM storehouses", connector)数据分组统计
在Pandas模块当中分组统计一般调用的都是groupby()方法,然后后面再添加一个统计函数,例如是求分均值的mean()方法,或者是求和的sum()方法等等,例如我们想要查找出在不止一个城市生产加工甜品的名称,代码如下
df_manufacturers.groupby('name').name.count()[df_manufacturers.groupby('name').name.count() > 1]output
name
Mishan 2
Name: name, dtype: int64而在SQL语句当中的分组也是GROUP BY,后面要是还有其他条件的话,用的是HAVING关键字,代码如下
pd.read_sql("""
SELECT name, COUNT(name) as 'name_count' FROM manufacturers
GROUP BY name HAVING COUNT(name) > 1
""", connector)数据合并
当两个数据集或者是多个数据集需要进行合并的时候,在Pandas模块当中,我们可以调用merge()方法,例如我们将df_sweets数据集和df_sweets_types两数据集进行合并,其中df_sweets当中的sweets_types_id是该表的外键
df_sweets.head()output
df_sweets_types.head()output
具体数据合并的代码如下所示
df_sweets_1 = df_sweets.merge(df_sweets_types, left_on='sweets_types_id', right_on='id')output
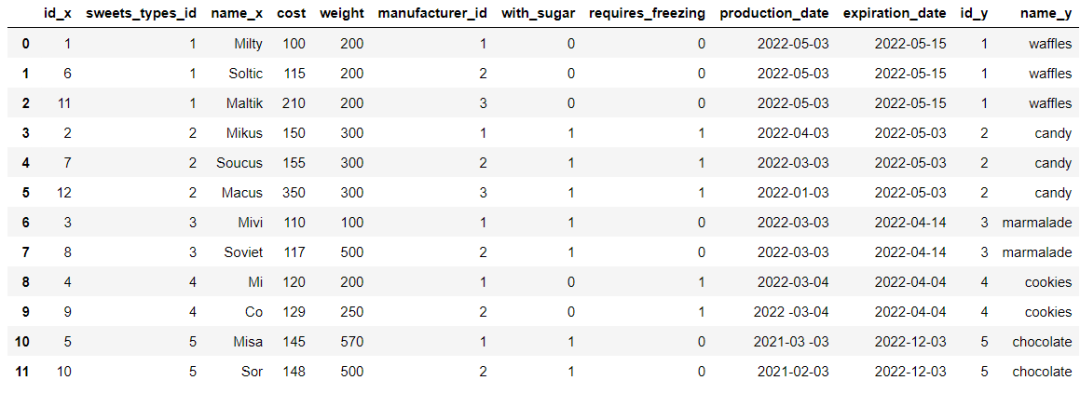
我们再进一步的筛选出巧克力口味的甜品,代码如下
df_sweets_1.query('name_y == "chocolate"').name_xoutput
10 Misa
11 Sor
Name: name_x, dtype: object而SQL语句则显得比较简单了,代码如下
# SQL
pd.read_sql("""
SELECT sweets.name FROM sweets
JOIN sweets_types ON sweets.sweets_types_id = sweets_types.id
WHERE sweets_types.name = 'chocolate';
""", connector)output

数据集的结构
我们来查看一下数据集的结构,在Pandas模块当中直接查看shape属性即可,代码如下
df_sweets.shapeoutput
(12, 10)而在SQL语句当中,则是
pd.read_sql("SELECT count(*) FROM sweets;", connector)output
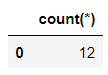
NO.1
往期推荐
Historical articles
【硬核原创】盘点Python爬虫中的常见加密算法,建议收藏!!
用Python当中Plotly.Express模块绘制几张图表,真的被惊艳到了!!
分享、收藏、点赞、在看安排一下?




边栏推荐
- 2022 the latest big company Android interview real problem analysis, Android development will be able to technology
- #夏日挑战赛#数据库学霸笔记,考试/面试快速复习~
- UWB超宽带定位技术,实时厘米级高精度定位应用,超宽带传输技术
- 面试官:Redis中集合数据类型的内部实现方式是什么?
- Apprentissage du projet MMO I: préchauffage
- How to convert word into PDF? Word to PDF simple way to share!
- Benefits of automated testing
- The binary string mode is displayed after the value with the field type of longtext in MySQL is exported
- PHP uses ueditor to upload pictures and add watermarks
- The problem of returning the longtext field in MySQL and its solution
猜你喜欢

100million single men and women supported an IPO with a valuation of 13billion
Reinforcement learning - learning notes 4 | actor critical
Teach you to deal with JS reverse picture camouflage hand in hand
2022 the latest big company Android interview real problem analysis, Android development will be able to technology
Go deep into the underlying C source code and explain the core design principles of redis
Blue sky drawing bed Apple quick instructions
MMO project learning 1: preheating
块编辑器如何选择?印象笔记 Verse、Notion、FlowUs
2022最新大厂Android面试真题解析,Android开发必会技术
Talking about fake demand from takeout order
随机推荐
Fuzor 2020軟件安裝包下載及安裝教程
Go语言 | 03 数组、指针、切片用法
IFD-x 微型红外成像仪(模块)关于温度测量和成像精度的关系
Millimeter wave radar human body sensor, intelligent perception of static presence, human presence detection application
Fundamentals of shell programming (Chapter 9: loop)
司空见惯 - 英雄扫雷鼠
Talking about fake demand from takeout order
机器学习基础(三)——KNN/朴素贝叶斯/交叉验证/网格搜索
Word finds red text word finds color font word finds highlighted formatted text
Oracle Chinese sorting Oracle Chinese field sorting
Fundamentals of shell programming (Part 8: branch statements -case in)
Go deep into the underlying C source code and explain the core design principles of redis
国海证券在网上开户安全吗?
决策树与随机森林
R语言可视化散点图(scatter plot)图、为图中的部分数据点添加标签、始终显示所有标签,即使它们有太多重叠、ggrepel包来帮忙
Tianyi cloud understands enterprise level data security in this way
华为让出的高端市场,小米12S靠徕卡能抢到吗?
Go语言 | 02 for循环及常用函数的使用
2022最新大厂Android面试真题解析,Android开发必会技术
uniapp获取微信头像和昵称