当前位置:网站首页>SAKT方法部分介绍
SAKT方法部分介绍
2022-07-07 12:12:00 【多尝试多记录多积累】
网络架构和嵌入解释: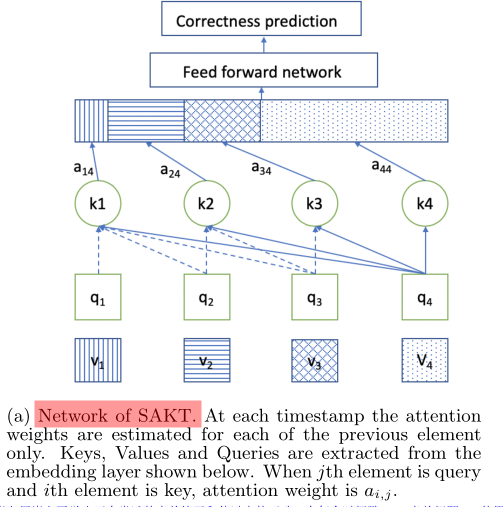
SAKT网络: 在每个时间戳处,仅对前面的每个元素估计注意权重。键、值和查询是从如下所示的嵌入层中提取的。当第j个元素为查询元素且第i个元素为关键元素时,注意权重为 a i j a_{ij} aij。
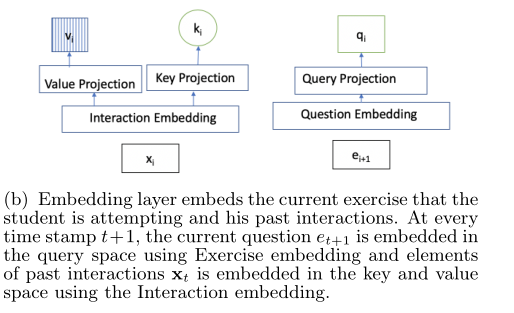
嵌入层: 嵌入学生正在尝试的当前练习和他过去的交互。在每次标记 t + 1 t+1 t+1 时,使用练习嵌入将当前问题 e t + 1 e_{t+1} et+1 嵌入到查询空间中,使用交互嵌入将过去交互的元素 x t x_t xt 嵌入到键和值空间中。
方法详细介绍:
模型目的: 根据学生1到 t 时刻 的习题作答情况,(即交互序列 X = x 1 , x 2 , . . . , x t X = x_1, x_2, ..., x_t X=x1,x2,...,xt,) 预测在 t + 1 t+1 t+1 时刻,习题 e t + 1 e_{t+1} et+1的回答情况(即预测出真实情况,正确的概率)。
交互元组: x t = ( e t , r t ) x_t = ( e_t, r_t) xt=(et,rt) : t t t 时刻习题 e t e_t et 的作答情况 r t r_t rt构成的。 x t x_t xt编号化时,用两者来表示,: y t = e t + r t × E y_t = e_t + r_t × E yt=et+rt×E , E E E是题目数量,可以看出交互编号,回答错误 时和题目编号同 y t = e t y_t = e_t yt=et,回答正确时,编号加上题目总数 y t = e t + E y_t = e_t + E yt=et+E。
嵌入层描述:
交互序列需要划分处理,保证所以的交互序列的长度一致,多则截断,短则填充。
因此交互序列由 y = ( y 1 , y 2 , . . . , y t ) y = (y_1, y_2, ...,y_t) y=(y1,y2,...,yt)变为 s = ( s 1 , s 2 , . . . , s n ) s = (s_1,s_2,...,s_n) s=(s1,s2,...,sn)。
训练一个交互嵌入矩阵 : M ∈ R 2 E × d M ∈ R^{2E×d} M∈R2E×d,其中 d 是潜在维度,用于获取交互嵌入。 s i s_i si的嵌入表示为 M s i M_{s_i} Msi
训练一个练习嵌入矩阵: E ∈ R E × d E ∈ R^{E×d} E∈RE×d, 用户获取练习嵌入。 e i e_i ei的嵌入表示为 E e i E_{e_i} Eei
位置编码:
为了对序列顺序进行编码,引入参数 P ∈ R n × d P ∈ R^{n×d} P∈Rn×d,加到交互嵌入中,形成新的编码。 P i P_i Pi 加入到第 i i i 个交互嵌入向量中,形成含有位置编码的交互嵌入向量。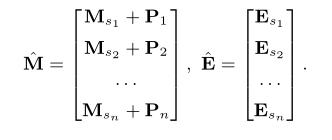
自注意力层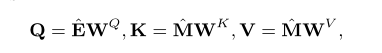
Q: 习题嵌入
K:作答交互嵌入
V :作答交互嵌入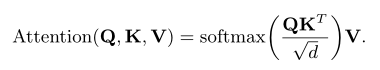
利用缩放点积的注意力机制
当前练习和之前的每一次作答交互 都有关系,计算出注意力权重。
多头
捕获不同子空间的信息。
因果关系
因为序列性的缘故,不能够知道被预测题目的信息,所以使用因果关系层掩盖从未来交互中学习到的权重。
前馈层
为了在模型中加入非线性并考虑不同潜在维度之间的相互作用,我们使用了前馈网络。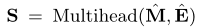
残差连接
利用低层信息
预测层
得到预测的概率
网络训练
交叉熵
边栏推荐
- Is the spare money in your hand better to fry stocks or buy financial products?
- Seven propagation behaviors of transactions
- 最长上升子序列模型 AcWing 1014. 登山
- PostgreSQL array type, each splice
- IP address home location query
- 【日常训练--腾讯精选50】231. 2 的幂
- Best practice | using Tencent cloud AI willingness to audit as the escort of telephone compliance
- mysql导入文件出现Data truncated for column ‘xxx’ at row 1的原因
- 请问,PTS对数据库压测有好方案么?
- Is it safe to open an account online now? Which securities company should I choose to open an account online?
猜你喜欢
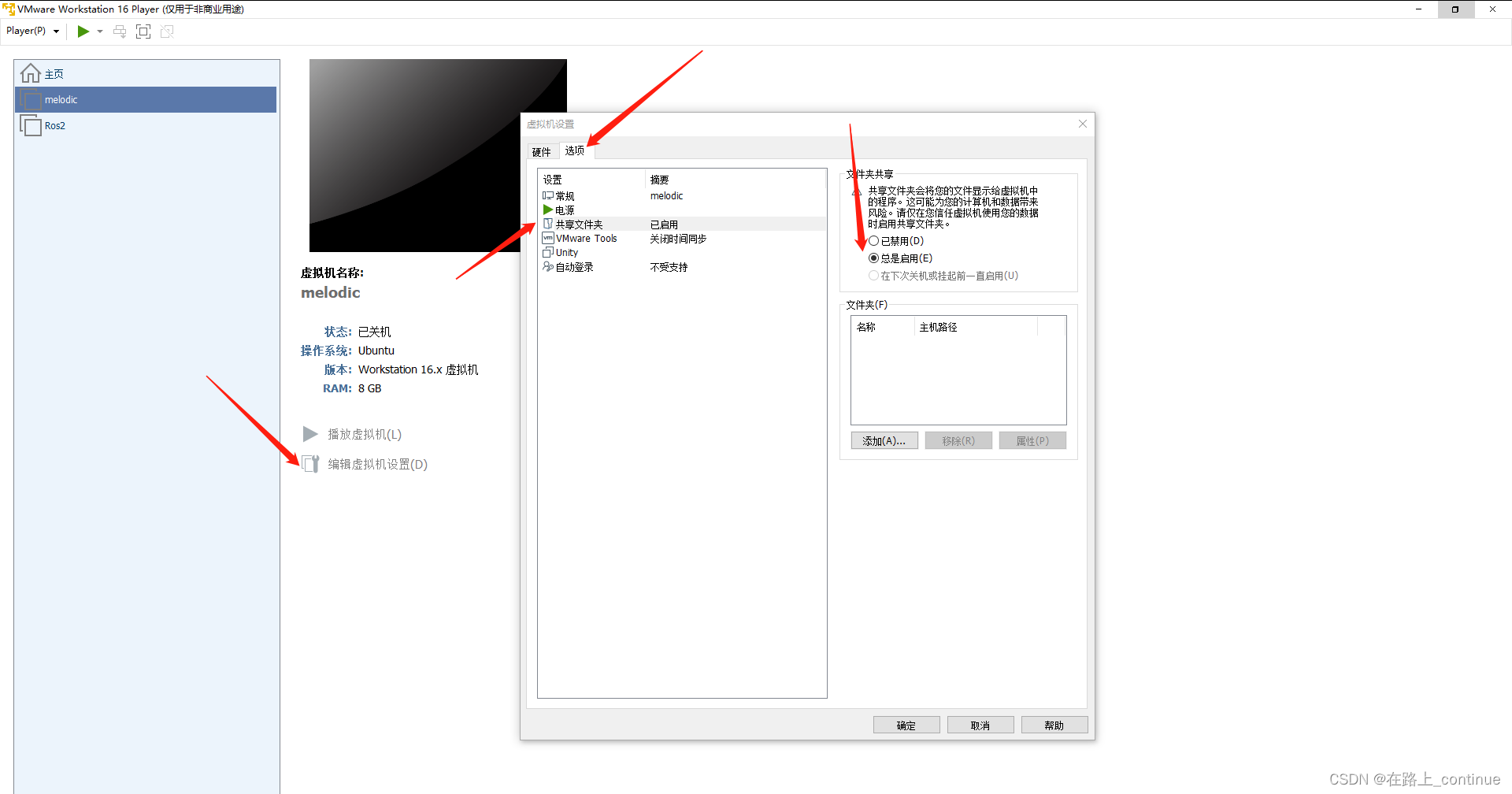
Vmware 与主机之间传输文件
Transferring files between VMware and host
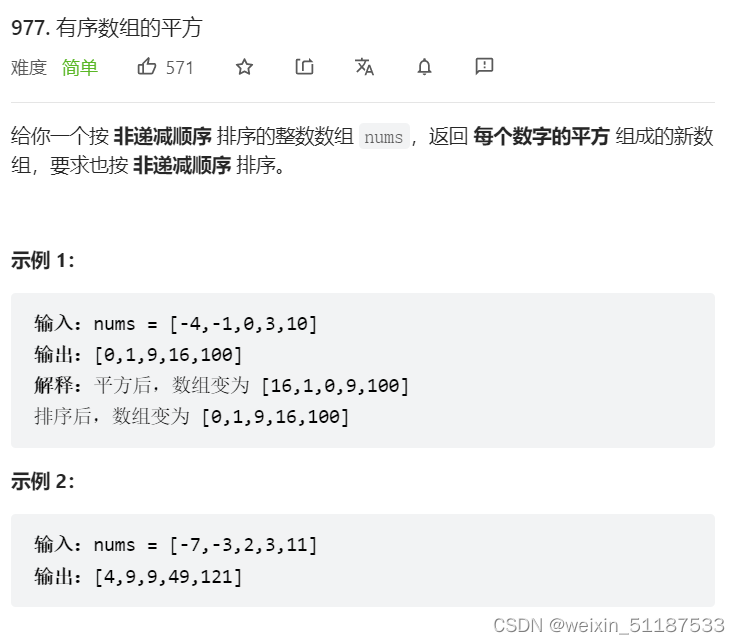
2022-7-6 Leetcode 977. Square of ordered array
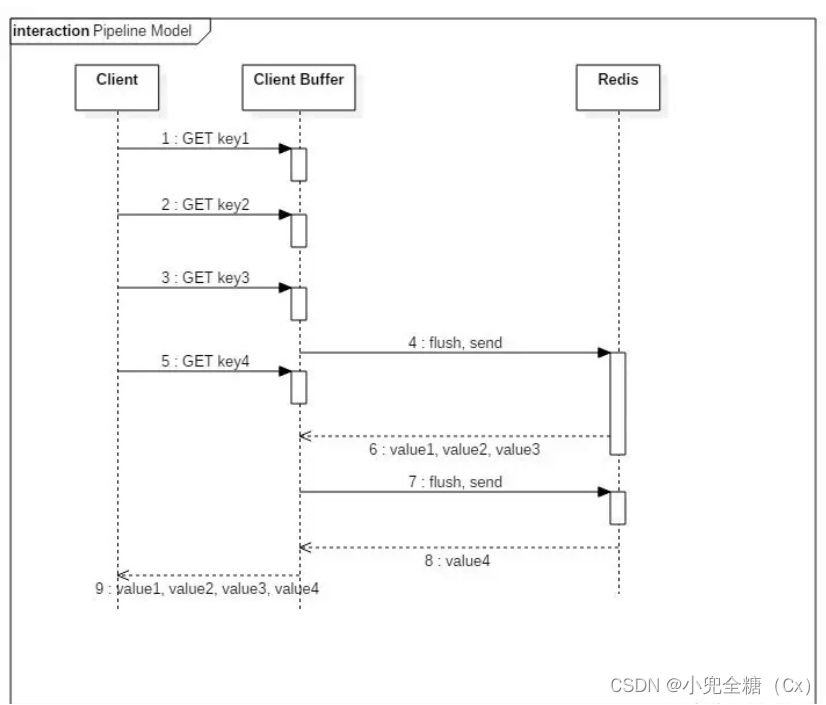
. Net core about redis pipeline and transactions

LeetCode简单题分享(20)
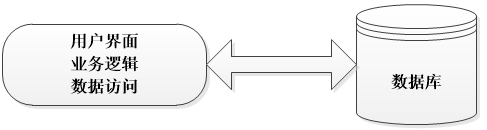
带你掌握三层架构(建议收藏)
![Supply chain supply and demand estimation - [time series]](/img/2c/82d118cfbcef4498998298dd3844b1.png)
Supply chain supply and demand estimation - [time series]
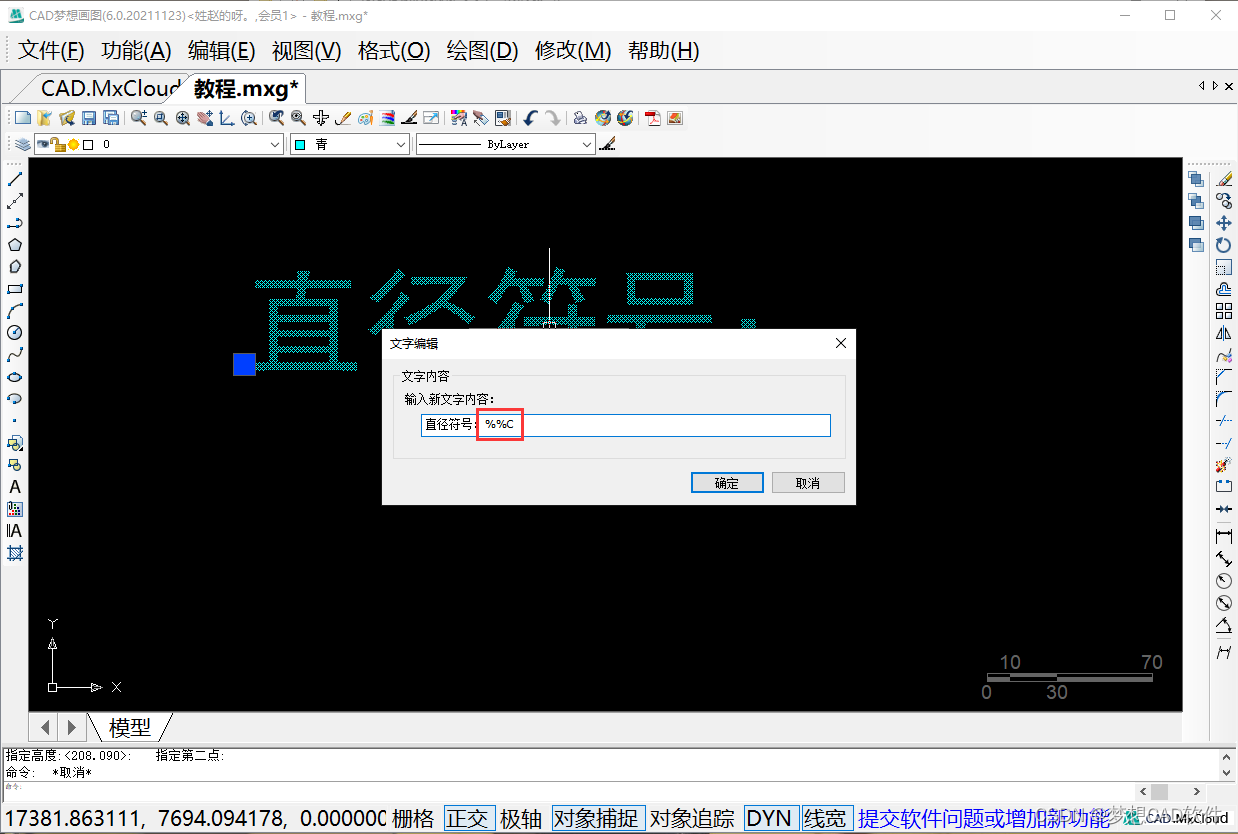
AutoCAD - how to input angle dimensions and CAD diameter symbols greater than 180 degrees?

Advanced Mathematics - Chapter 8 differential calculus of multivariate functions 1

2022-7-6 Leetcode27. Remove the element - I haven't done the problem for a long time. It's such an embarrassing day for double pointers
随机推荐
[1] Basic knowledge of ros2 - summary version of operation commands
使用day.js让时间 (显示为几分钟前 几小时前 几天前 几个月前 )
Realize the IP address home display function and number home query
How does MySQL control the number of replace?
What parameters need to be reconfigured to replace the new radar of ROS robot
手里的闲钱是炒股票还是买理财产品好?
[daily training -- Tencent select 50] 231 Power of 2
The reason why data truncated for column 'xxx' at row 1 appears in the MySQL import file
[high frequency interview questions] difficulty 2.5/5, simple combination of DFS trie template level application questions
Move base parameter analysis and experience summary
[fortress machine] what is the difference between cloud fortress machine and ordinary fortress machine?
FC连接数据库,一定要使用自定义域名才能在外面访问吗?
高等數學---第八章多元函數微分學1
Details of redis core data structure & new features of redis 6
Battle Atlas: 12 scenarios detailing the requirements for container safety construction
Common response status codes
docker部署oracle
Deep understanding of array related problems in C language
Excellent open source system recommendation of ThinkPHP framework
IP address home location query