当前位置:网站首页>项目总结--01(接口的增删改查;多线程的使用)
项目总结--01(接口的增删改查;多线程的使用)
2022-07-03 05:53:00 【程序员DD】
1.一开始在进行项目分工的时候,其实觉得有些接口其实还是很好写的,一开始设计出设计的时候还是考虑的有点偏差,把项目的一些问题还有表结构考虑的偏简单了
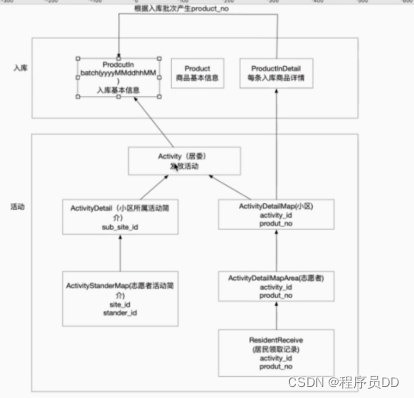
在进行这个设计的时候,其实有些模块的设计思想还是非常不错的,但是表结构和一些理念设计的还是有些偏差,业务理解上有些问题,导致在写代码的时候,会出现频繁的返工的情况,通过上述的总结,表和表直接的链接的关系示意图。
2.首先要明确的项目背景,背景主要是这个防疫产品的物资需要结合实际的情况要进行分发工作,其实从活动的角度进行考虑的话,整个防疫的产品线表结构的先分清楚。
产品族的概念是建立在产品入库的这个操作,会在ProductIn这个表中进行入库操作,这个产品就是此次防疫的活动产品信息,同样就是居委(Activity)所代表的活动的数据来源,
3.居委的动作是分发活动,他的下级是分发给小区(ActivityDetailMap),这个层级关系的架构类似于从同一个居委的活动,可以隶属于不同的小区,小区在往下分发就是志愿者(ActivityDetailMapArea)同一个小区就有不同的志愿者,来进行物资到楼栋的商品信息的转发,这个转发操作其实是分配物资的操作,到居民领取记录(ResidenReceiv)居民领取记录;
4.在居委的下级,会有ActivityDetail(小区活动详情信息介绍),这个就会有一个Sub_sit_id他这个关联的居委的下级,就是小区,就是居委隶属的小区,同样就会有一个ActivityStandrMap(志愿者活动简介)通过分析楼组长内的活动性
整个项目的后台分发为了两个端,一个是一级的管理端,还有一个就是二级的管理端,一级的管理端可以理解为对应的居委端,二级的管理端就小区端,后面介绍就先从自己负责的小区端,自底向上进行介绍
小区端接口介绍
接口列表:
1.分页列表: /activityarea/page
2.小区商品明细:/activityarea/product
3.分配任务:/activityarea/distribution
4.分配任务列表:/activityarea/distribution_list
5.查询本次分配商品明细:/activityarea/find_detail
6.发放统计:/statistics/secondary/grant/count
7.发放统计列表:/statistics/secondary/grant/page
1.分页列表: /activityarea/page
//统计分页列表的流程,这个是统计小区的分页统计,一般情况这个时候需要注意的是通常在进行业务操作的时候都批处理操作,基本上不会用到findById这种然后直接返回一个entity实体这种操作,大部分都是直接返回一个list集合去接的操作,这样的话在进行控制的时候可以更好的避免,因为出现多条数据的问题,而造成数据返回异常的状态
===========================================================================================
在接口中进行业务的queryPage操作通常情况下都是第一个列表接口都是分页操作,这个返回的接口的类型一定事包装给前端的Page<DTO>,入参一定有Page,size,这种参数类型,在进行查询的时候的操作步骤,一般就是如下的步骤,
1.创建DTO对象,构建Specification<Entity>=quereySpecification,动态查询方式,构建完动态查询方式之后一般会返回Specification对象
2.构建Pageable对象,这个里面通常用的就是PageRequest.of(page-1,size,Sort.by...)这种分页对象的写法这种都是固定的写法
3.执行findAll的操作,通常来说就将specification,pageabl两个对象作为入参,放入findAll()方法里面,返回对象Page<Entity> 一个分页对象,这个分页对象分页的时候,一定分页的是数据库中entity实体的对象,还需要将分页对象包装成DTO给前端返回,这样前端才可以用。
4.这个其实Page<Entity>对象直接取转是转换不成的,可以通过Page<Entity>.geteConten,这样子就可以获取到对应的List<Entity>对应的集合,在结合stream().map(DTO:NEW).collect(Collectors.toList);
这种方式就可以将对应的Page<Entity>间接的转为为List<DTO>
5.得到List<DTO>之后,还需要将List<DTO>在转换为Page<DTO>,这个操作,则需要有PageImpl(List<DTO>,Page<Entity>.getPageable,Page<Entity>.getTotalElement);这种方式进行转换,这个参数里面,通过分析,三个入参,List<DTO>,pag对象,page总数
-----PageImpl
public PageImpl(List<T> content, Pageable pageable, long total) {
super(content, pageable);
this.total = (Long)pageable.toOptional().filter((it) -> {
return !content.isEmpty();
}).filter((it) -> {
return it.getOffset() + (long)it.getPageSize() > total;
}).map((it) -> {
return it.getOffset() + (long)content.size();
}).orElse(total);
}
分析这个方法可以看到,第一个入参是List<DTO>,第二个入参是Page,第三个是总数,super方法中调用的我构造则,就是直接
public Chunk(List<T> content, Pageable pageable) {
Assert.notNull(content, "Content must not be null!");
Assert.notNull(pageable, "Pageable must not be null!");
this.content.addAll(content);
this.pageable = pageable;
这个里面pageabl这个是什么,通过分析可以直接的看到,主要是当前页,当前页数量,排序字段,
default Pageable getPageable() {
return PageRequest.of(this.getNumber(), this.getSize(), this.getSort());
}
结合分析之后这个返回的PageImpl()就可以直接将List<DTO>,转换成Pag<DTO>了
6.在返回给前端的时候,响应的处理也是PageReponse<DTO>,这样返回给前端的就是一个页对象
==================================================================================
业务要点:
1.首先的findIds()这种操作一定是批处理操作
2.当DTO字段和实体字段不匹配的时候,DTO字段有的是从实体里面的ID关联其他表要进行赋值的时候,就需要往DTO里面取塞值才行;
3.这个时候需要遍历DTO,里面的每一个类,然后给每一个类去set对应的属性值操作,通常这个时候,需要结合其他的repository.findByID这种操作去进行,但是要注意的是,不要去在foreach里面取进行查询的逻辑,放在外面操作;就是补充DTO缺失字段名;
List<String> activityIds = activityDetails.stream().map(ActivityDetail::getActivityId).collect(Collectors.toList());
List<Activity> activityList = activityRepository.findAllByIdIn(activityIds);
Map<String, Activity> activityMap = activityList.stream().collect(Collectors.toMap(Activity::getId, Function.identity()));
4.主要是这三行,分别为获Page<Entity>中对应的要关联塞值的Id,构成一个IDS,然后再通过一个findByIDIn就可以拿到对应的你需要关联的ID的List<关联ID的Entity>,之后在通过List<关联的ID的Entity>.stream().collection(Collectors.toMap(Activity::getId,Function.identity))这种方式就可以得到一个map,就是一个ID,对应的一个关联的IDentity,这样在foreach里面就好判断了,直接通过map(l.getId)的形式拿到实体,直接就可以进行set操作
2./activityarea/product
这个业务要点其实是比较简单的和上面的分页查询类似,直接通过一个动态查询,在结合对应的需要补充塞值的字段,添加进去就可以了3.分配任务:/activityarea/distribution
业务要点:
这个对象在构建的时候其实是一个保存操作,即要保存一个对象的时候,需要有很多的东西需要进行记录的
这个接口在进行操作的时候,需要进行操作的地方主要有的步骤分为了下面的几个步骤
1.前端传过来的是一个dto,里面有list{dto,dto},的这种形式,所以我在进行保存的时候,就需要将这个类进行设计,设计的时候就需要用到内部类的思想
public class ActivityDistributionAreaDTO {
@ApiModelProperty(value = "活动id")
private String activityId;
private List<ActivityToSecondaryAreaDTO> list;
@Data
@NoArgsConstructor
public static class ActivityToSecondaryAreaDTO {
@ApiModelProperty(value = "小区/居委站点id")
private String siteId;
@ApiModelProperty(value = "管理员Id")
private String adminId;
@ApiModelProperty(value = "管理员姓名")
private String adminName;
@ApiModelProperty(value = "站点名称")
private String siteName;
@ApiModelProperty(value = "备注")
private String remarks;
@ApiModelProperty(value = "发放数量")
private Integer count;
}
这个内部类的思想,通过这个id,可以关联出对应的list 一个总的列表集合,这个时候,需要注意的一点是,这个内部类的设计思想理念是,一个活动可以在下面挂多个子活动,并且是动态添加的,这个时候需要进行遍历这个dto里面list的里面的size的数量,就是遍历这个内部类list,因为这个内部类是一个list,在进行遍历这个子集合的时候,需要进行创建对象然后再封装,
dto.getList().forEach(d -> {
ActivityStanderMap asm = new ActivityStanderMap();
asm.setId(RandomGenerator.buildUUID());
asm.setSiteId(d.getSiteId());
asm.setBatchNo(activityDetailMapList.get(0).getBatch());
asm.setActivityId(dto.getActivityId());
asm.setStanderId(d.getAdminId());
asm.setActivityStatus(ActivityStatus.ING);
asm.setDelFlag(false);
asm.setAdminId(d.getAdminId());
asmList.add(asm);
for (int i = 0; i < d.getCount(); i++) {
if (d.getCount() > activityDetailMapList.size()) {
throw new BaseException("分配物资数大于可分配物资");
} else {
ActivityDetailMap owner = activityDetailMapList.get(i);
callList.add(owner);
ActivityDetailMapArea map = new ActivityDetailMapArea();
map.setId(RandomGenerator.buildUUID());
//每个小区的物资编号
map.setStanderId(d.getAdminId());
map.setSiteId(d.getSiteId());
map.setAdminId(d.getAdminId());
map.setDelFlag(false);
map.setActivityId(dto.getActivityId());
map.setBatchNo(owner.getBatch());
map.setProductId(owner.getProductId());
map.setProductNo(owner.getProductNo());
map.setStatus(ProductDistribute.NO);
detailMapList.add(map);
}
}
这个业务逻辑在设计的时候,可以看到一个是asm这个对象,需要往一个asmmap这个表里面存,同样的根据当前的detailMap里面新增数据6.发放统计:/statistics/secondary/grant/count
业务要点:这个发放统计分为了一个数量,和一个查询当前发放的业务的列表。
这个时候需要结合具体的业务去进行分析,当前有存在的业务用JPA的方式取实现不了,所有就要JPA有统计的方式countByXXAndXX(),这种方式进行,通常来说在进行统计的时候,集合当前状态会自动进行分组
具体的就是
select
count(student0_.id) as col_0_0_
from
student student0_
where
student0_.name=?
当有不满足当前业务的时候,就需要进行分析结合具体的SQL进行拼接,数据的来源格式
7.发放统计列表:/statistics/secondary/grant/page
业务要点:这个数据统计在进行列表展示的时候,其实还是非常难的,
这个里面有一个操作就是JPA在执行对应的countGroupBySitIdAndActivityIdIn()这种格式的时候就需要进行一些操作,就通过@Query进行操作的
select count(distinct resident_id) as count,
rr.activity_id as activityId
from tb_resident_receive rr
where rr.site_id = ?1
and (?2 is null or rr.activity_id = ?2 )
group by rr.activity_id
通过分组聚合进行统计就可以了,这个操作是先进行筛选,在进行分组,在进行聚合操作,这个时候聚合操作返回出来的是VO对象,这个VO是一个接口,接口中的方法要符合JPA规范,符合规范的要求就是通过GETXX的方式来获取对应的属性的字段映射SQL里面查询处理的字段。多线程的写法介绍
private void patchInsert(List<ActivityDetailMapArea> details) {
// 注入线程池
ExecutorCompletionService<Integer> completionService = new ExecutorCompletionService<Integer>(
threadPoolTaskExecutor);
if (CollectionUtils.isEmpty(details)) {
throw new BaseException("入库商品数不能为空");
}
int poolSize = threadPoolTaskExecutor.getCorePoolSize();
int count = details.size();
//todo 根据数量和线程池的关系计算每个线程多少数据量,暂定3的倍数
if (details.size() / 3 > poolSize) {
count = details.size() / poolSize;
}
/**
* partition()方法
* 例如 1001条数据 他会自动帮你分成两个数组 第一个数组1000条 第二个数组1条
* 不需要我们再像以前一样 通过for循环处理截取
*/
List<List<ActivityDetailMapArea>> lists = Lists.partition(details, count);
lists.forEach(item -> {
//根据lists大小确认要多少个线程 给每个线程分配任务
completionService.submit((Callable) () -> {
// 批量插入数据库
return activityDetailMapAreaRepository.saveAll(item);
});
});
}
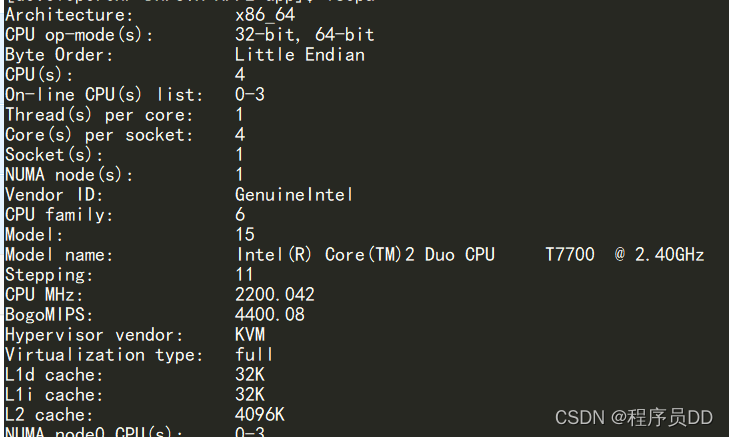
多线程的线程配置
结合实际中的配置,可以看出图中的服务器配置是,四核单线程的,在配置CPU核心线程数的时候
public class ThreadConfig {
/**
* corePoolSize:线程池维护线程的最少数量
* keepAliveSeconds:允许的空闲时间
* maxPoolSize:线程池维护线程的最大数量
* queueCapacity:缓存队列
* rejectedExecutionHandler:对拒绝task的处理策略:默认丢弃任务并抛出RejectedExecutionException异常
*/
@Bean
public Executor getExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(50);
executor.setMaxPoolSize(100);
executor.setQueueCapacity(10);
executor.initialize();
return executor;
}
1、核心线程数配置个数:看IO密集型,还是CPU密集型
(1)一般平时cpu使用率4%以下,都是IO密集型,IO密集型核心线程数设置大小具体看实践,目前项目里核心线程数设置50,最大线程数可以和核心线程数相同,队列配置大一些,使永远触发不到最大线程数
(2)如果是大量计算CPU使用率过高,属于CPU密集型,CPU密集型以4C8G为例,核心线程数一般设置4,最大线程数可以和核心线程数相同,队列配置大一些,使永远触发不到最大线程数
2、核心线程数销毁:
(1)默认情况下,keep-alive 策略仅适用于超过 corePoolSize 线程的情况,没有任务会进行空跑, 和线程池生命周期一样, 除非线程池shutdown;但是方法allowCoreThreadTimeOut(boolean)也可用于将此超时策略应用于核心线程,只要 keepAliveTime 值不为零即可
这个是在线程中进行多线程处理操作,这个处理的操作的主要流程是针对对应的具体的开一个单独的线程去执行保存操作的,避免出现大量的单线程的保存操作造成阻塞的情况。下面来着重分析一下这个多线程的写法
1.需要用的多线程的去另外开启一个线程去单独操作的是,就需要进行单独的去从线程池中去拿线程,这个ExecuorCompletionServic这个Service就是单独的用线程池的方式取注入的。
2.设置线程池的中的核心线程数,有一个关系是根据数量和线程池的关系计算每个线程处理多少数据量,暂定3的倍数,后面在进行提交保存的时候,通过lists的来确认多少个线程,即就是给每个线程分配的任务书.
3.通过completionService.submit()在这个方法中,会调用Callable 会有一个抽象方法进行提交,在这里执行批量插入数据库的操作,就可以了
4.下面来分析一下对应的completionServie.submit()
CompletionService 的实现原理也是内部维护了一个阻塞队列,当任务执行结束就把任务的执行结果加入到阻塞队列中,不同的是 CompletionService 是把任务执行结果的 Future 对象加入到阻塞队列中,而上面的示例代码是把任务最终的执行结果放入了阻塞队列中,这个底层的原理还需要进行深入的研究一下,现在在这个submit方法里面就可以直接通过Callable进行转换就可以了。
5.在SpringBoot 微服务里面,还有一种通过多线程的方法来进行对方法实现多线程的处理,就@Async,spring-boot 自带的注解
使用async注解表示该方法为异步方法,需要注意以下问题:
1.spring boot 项目使用时需要在启动类开启异步方式,增加 @EnableAsync 注解
2.被async注解的方法返回值只能是void或者使用Future包装一下,比如返回值Future(String)
3.异步线程使用的是默认线程数8个,如果有多个异步线程需要注意内存溢出问题
4.async注解有个value值来区分不同的线程,实际项目使用有多个异步线程时需要增加value值
6.还有一种在项目中创建线程的方式
@Transactional(rollbackFor = Exception.class)
public void commit(String userId, VersionCommitInputDTO commitInputDTO) {
String organId = commitInputDTO.getOrganId();
Standard standard = standardRepository.findFirstByOrganIdAndDelFlagIsFalseOrderByVersionDesc(organId);
String version = versionUp(standard.getVersion());
String name = standard.getName();
// 异步生成文档path
FutureTask<String> futureTask = new FutureTask<>(() -> {
List<StandardOutputDTO> versions = getVersions(userId, organId, version, commitInputDTO.getRemarks());
return documentPath(organId, name, version, versions);
});
ThreadPool.THREAD_POOL_IO_CALLERRUNS.execute(futureTask);
//提交 待提交
interfaceService.commit(userId, organId);
Standard newStandard = new Standard();
newStandard.setName(name);
newStandard.setId(RandomGenerator.randomUUID());
newStandard.setOrganId(organId);
newStandard.setVersion(version);
newStandard.setStandardCount(interfaceRepository.countByOrganIdAndInterfaceTypeAndDelFlagIsFalse(organId, InterfaceType.STANDARD));
newStandard.setCustomCount(interfaceRepository.countByOrganIdAndInterfaceTypeAndDelFlagIsFalse(organId, InterfaceType.CUSTOM));
newStandard.setRemarks(commitInputDTO.getRemarks());
newStandard.setLastUpdateUser(userId);
newStandard.setDelFlag(Boolean.FALSE);
try {
String path = futureTask.get(10, TimeUnit.SECONDS);
newStandard.setDocumentPath(path);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
log.error("get document path InterruptedException {}", e.getMessage());
} catch (ExecutionException e) {
log.error("commit document path error {}", e.getMessage());
} catch (TimeoutException e) {
log.error("get document path TimeoutException {}", e.getMessage());
}
standardRepository.save(newStandard);
}/**
* 线程池
* 如何确认合适的线程数量?
* 如果是CPU密集型应用,则线程池大小设置为N+1 (N为CPU总核数)
* 如果是IO密集型应用,则线程池大小设置为2N+1 (N为CPU总核数)
* 线程等待时间(IO)所占比例越高,需要越多线程。
* 线程CPU时间所占比例越高,需要越少线程。
*/
public class ThreadPool {
/**
* 获取CPU核心数
*/
private static final int CORE_POOL_SIZE;
static {
CORE_POOL_SIZE = Runtime.getRuntime().availableProcessors();
}
private static final ThreadFactory NAMED_THREAD_FACTORY = new ThreadFactoryBuilder()
.setNameFormat("windhp-pool-%d").build();
public static final ExecutorService THREAD_POOL_IO_CALLERRUNS = new ThreadPoolExecutor(
CORE_POOL_SIZE,
2 * CORE_POOL_SIZE + 1,
10L,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(64),
NAMED_THREAD_FACTORY,
//调用者线程中直接执行被拒绝任务的run方法
new ThreadPoolExecutor.CallerRunsPolicy());
}在这个方法中,最主要的方法就是就是通过对应的FutureTask这种方式进行创建
FutureTask<String> futureTask = new FutureTask<>(() -> {
List<StandardOutputDTO> versions = getVersions(userId, organId, version, commitInputDTO.getRemarks());
return documentPath(organId, name, version, versions);
});
ThreadPool.THREAD_POOL_IO_CALLERRUNS.execute(futureTask);边栏推荐
- [teacher Zhao Yuqiang] redis's slow query log
- 2022.DAY592
- [trivia of two-dimensional array application] | [simple version] [detailed steps + code]
- redis 遇到 NOAUTH Authentication required
- [function explanation (Part 2)] | [function declaration and definition + function recursion] key analysis + code diagram
- Apple submitted the new MAC model to the regulatory database before the spring conference
- chromedriver对应版本下载
- How does win7 solve the problem that telnet is not an internal or external command
- CAD插件的安装和自动加载dll、arx
- 理解 YOLOV1 第一篇 预测阶段
猜你喜欢
![[explain in depth the creation and destruction of function stack frames] | detailed analysis + graphic analysis](/img/df/884313a69fb1e613aec3497800f7ba.jpg)
[explain in depth the creation and destruction of function stack frames] | detailed analysis + graphic analysis

Convolution operation in convolution neural network CNN
Apache+php+mysql environment construction is super detailed!!!

大二困局(复盘)

今天很多 CTO 都是被幹掉的,因為他沒有成就業務
Maximum likelihood estimation, divergence, cross entropy

Redhat7 system root user password cracking
Sophomore dilemma (resumption)

【一起上水硕系列】Day 10
![[set theory] relational closure (relational closure related theorem)](/img/6a/b6dca7abf592f8d8ab1d6aecc43381.jpg)
[set theory] relational closure (relational closure related theorem)
随机推荐
Intel's new GPU patent shows that its graphics card products will use MCM Packaging Technology
伯努利分布,二项分布和泊松分布以及最大似然之间的关系(未完成)
redis 无法远程连接问题。
MySQL startup error: several solutions to the server quit without updating PID file
Redis encountered noauth authentication required
Personal outlook | looking forward to the future from Xiaobai's self analysis and future planning
ES 2022 正式发布!有哪些新特性?
Configure DTD of XML file
中职网络子网划分例题解析
[teacher Zhao Yuqiang] calculate aggregation using MapReduce in mongodb
Beandefinitionregistrypostprocessor
期末复习(DAY7)
Detailed explanation of contextclassloader
Installation du plug - in CAD et chargement automatique DLL, Arx
Complete set of C language file operation functions (super detailed)
Linux登录MySQL出现ERROR 1045 (28000): Access denied for user ‘root‘@‘localhost‘ (using password: YES)
Understand expectations (mean / estimate) and variances
Solve the problem of automatic disconnection of SecureCRT timeout connection
Pytorch builds the simplest version of neural network
AtCoder Beginner Contest 258(A-D)