当前位置:网站首页>TIDB数据库特性总结
TIDB数据库特性总结
2022-07-01 05:46:00 【进击的Coders】
文章目录
前言
项目需要使用TIDB,首先需要部署一个TIDB的集群环境,因此就打算学习一下TIDB数据库,方便以后使用。
一、TIDB数据库介绍
1.1数据管理技术发展阶段
- 人工管理阶段:没有磁盘等存储设备、,数据量小,由用户直接管理。
- 文件系统阶段:有磁盘等存储设备,将数据存放在磁盘中。
- 数据库系统阶段:将数据存放于数据库中,使用数据库管理工具对数据统一进行管理。
1.2 数据库分类
数据库大约是上世纪六七十年代提出来的,目的是为了提高数据管理的效率。按照发展顺序,数据库大概可以分为以下几种:
- 层次和网状数据管理系统:可以理解为是用指针来表示数据之间的关系。
- 关系型数据库(RDBMS):是最常用的数据库,可以理解为使用二维表来表示和维护数据之间的关系。促进了数据库的小型化和普及化。
- 新一代数据库:新一代数据库主要是为了解决关系型数据库的性能、扩展性、伸缩性等问题,有以下几种:
ORDBMS:面向对象的数据库技术,如PostGreSQL。
NoSQL(Not only SQL):意思是不仅仅是SQL,提倡运用非关系型的数据存储,普遍选择牺牲掉复杂的SQL支持以及ACID事务来换取弹性扩展的能力,通常不保证强一致性。非结构化数据库如(1)键值存储数据库:Redis。(2)列式存储数据库:HBase。(3)文档型数据库:MongoDB。(4)图数据库:Neo4j。
NewSQL:这类数据库不仅具有NoSQL数据库对海量数据的存储管理能力,还保持了传统数据库的ACID和SQL等特性,例如:TiDB
由此可见TIDB属于NewSQL范畴,是最新的数据库技术。
1.2 如何学习TiDB
本次对TIDB的学习主要包括以下几个部分,排列顺序即学习路线:
- TIDB的特点和应用场景。
- TIDB安装部署。
- TIDB集群化部署。
- TIDB的SQL操作。
- TIDB数据库迁移。
二、TIDB特点和使用场景
2.1.MySQL存在问题
当MySQL单表数据量超过5000时,性能就会急剧下降,通常使用分库分表的方式进行解决。分库分表虽然能够使MySQL性能稳定可控,将单表拆分成小表之后,能够水平扩展,部署到多台服务器上,进而提升整个集群的QPS、TPS、Latency等数据库服务指标。但是存在如果服务器宕机,有事务不一致的风险。分表之后,对SQL语句有一定限制,对业务方功能需求大打折扣。分表之后,需要维护的对象呈指数增长(MySQL实例数、需要执行的SQL变更数量 )
为避免MySQL数据库的问题,选用NewSQL,NewSQL数据库具有如下特点:
- 无限水平扩展能力
- 分布式强一致性,确保数据100%安全。
- 完整的分布式事务处理能力与ACID特性。
TiDBB是NewSQL技术中心具有代表性的开源产品。
2.2.TiDB数据库特点
TIDB是开源分布式关系型数据库是一款定位于在线事务处理OLTP/在线分析处理OLAP的融合型数据库产品,实现一键水平伸缩,强一致性的多副本数据安全,分布式事务,实时OLAP等重要特性。同时兼容MySQL协议和生态,迁移便捷,运维成本极地。可以将TIDB看做MySQL的加强版和分布式版本
TIDB数据库具备分布式强一致性事务、在线弹性水平扩展、故障自恢复的高可用、跨数据中心等核心特性,是大数据时代理想的数据库集群和云数据库解决方案。
TIDB的设计目标是100%的OLTP场景和80%的OLAP场景,更复杂的OLAP分析可以通过TiSpark项目来完成。
- 在线事务处理(OLTP):强调短时间内大量事务操作,强调支持短时间内大量并发的事务操作(增删改查)的能力,每个操作涉及的数据量都很小。强调的是事务的强一致性(银行转账)。例如“双十一期间,可能有几十万用户在同一秒内下订单,后台数据库要能够并发的、以近乎实时的速度处理这些订单请求”
- 在线事务分析(OLAP):偏向于复杂的只读查询,读取海量数据进行分析计算,查询时间往往很长。例如“双十一结束,淘宝的运营人员对订单进行分析挖掘,找出市场规律”,这种分析坑你需要读取所有的历史订单进行计算,耗时数十秒甚至数十分钟。代表产品:GreenPlum、TeraData,AnalyticDB
2.3TIDB架构特性
三个核心组件:TIDB Server, PD Server, TIKV Server。另外有两个附加的组件:TiSpark,TIDB Operator。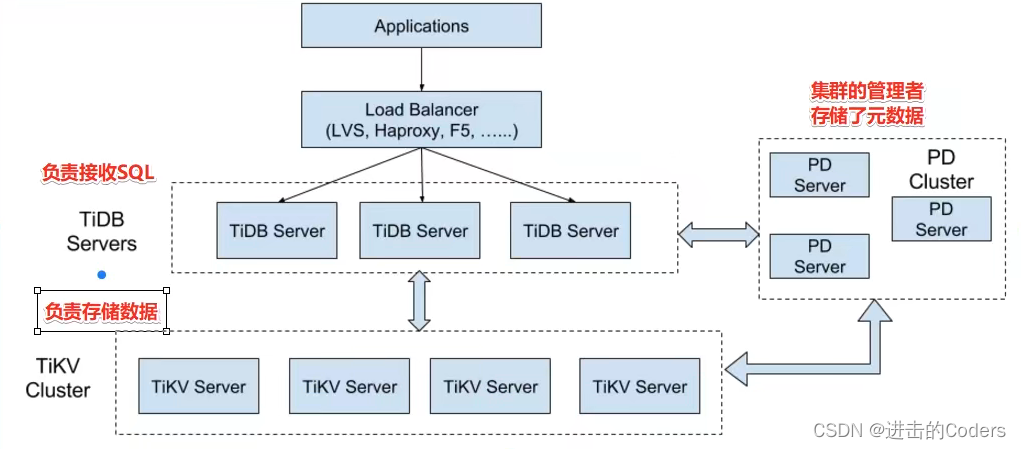
- PD Server:是整个集群的管理者,主要(1)存储元数据,(2)进行负载均衡,(3)分配全局唯一的事务ID。
- TIDB Server:负责接收SQL请求,通过PD中存储的元数据找到数据存在哪个TiKV上,并与TiKV进行交互,将结果返回给客户端。
- TiKV Server:负责真正存储数据的,本质上是一个KV存储引擎。
- TiSpark:用来解决用户的复杂的OLAP查询需求的组件。
- TiDB Operator:用来方便云上部署的组件。

2.4 TiDB 核心特性
- 高度兼容MySQL:在大多数情况下,无需修改代码就可以从MySQL轻松迁移至TIDB,分库分表之后的MySQL集群仍然可以通过TIDB工具进行实时迁移。
- 分布式事务支持:100%支持ACID事务。
- 一站式HTAP解决方案:混合的事务处理和分析处理。
- 云原生的SQL数据库:TIDB是为云而设计的,支持公有、私有和混合云配合TIDB Operator项目可以实现自动化运维、使部署、配置和维护变得十分简单。
- 水平弹性扩展:(存储能力和计算能力)通过简单的增加新节点即可实现TIDB的水平扩展,按需扩展吞吐或存储,轻松应对高并发、海量数据场景。
- 真正的金融级的高可复用:相比于传统主从(M-S)复制方案,基于Raft的多数派选举协议可以提供金融级的100%数据强一致性保证,且在不丢失大多数副本的前提下,可以实现故障的自动回复(anto-failover),无需人工接入。
2.4.1水平扩展性
水平扩展是TIDB的一大特点,这里说的水平扩展包括两个方面:计算能力和存储能力。
TIDB server负责处理SQL请求,随着业务的增长,可以简单的添加TIDB Server的节点提高整体的处理能力,提供更高的吞吐。
TiKV负责存储数据,随着数据量的增长,可以部署更多的TiKV server节点解决数据Scale的问题。
PD会在TiKV节点之间以Region为单位做调度,将部分数据迁移到新的节点上。
所以在业务的早期,可以只部署少量的服务实例(推荐至少部署三个TiKV,三个PD,两个TIDB),随着业务的增长,按照需求添加TiKV和TIDB实例。
2.4.2高可用性
高可用性:高可用性是TIDB的另一大特点,TIDB/TiKV/PD这三个组件都能容忍部分实例失效,不影响整个集群的可用性。
1、TIDB:TIDB是无状态的,访问第一台、第二台或者第三台都是一样的,可以多部署几个,前端通过负载均衡组件对外提供服务,单个实例失效之后,可以重启这个实例或者部署一个新的实例。
2、PD:PD是一个集群,通过Raft协议保持数据的一致性,单个实例失效时,如果这个实例不是Raft的leader,那么服务完全不受影响,如果是Raft的leader,那么会重新选取一个新的Raft leader,自动回复服务,PD在选举过程中,无法对外提供服务,这个时间大概是三秒。推荐至少部署三个PD实例,单个实例失效之后,重启这个实例或者添加新的实例。
3、TiKV:TiKV是一个集群,也是通过Raft协议保持数据的一致性(副本数量可以配置,默认是保存三份副本),通过PD做负载均衡调度,单个节点失效时,会影响这个节点上存储的所有的Region。对于Region中的Leader节点,会中断服务,等待重新选举。对于Region中的Follower节点,不会影响服务。当某个TiKV节点失效,并且在一段时间内无法回复(默认30min),PD会将其上的数据迁移到其他的TiKV节点上。
2.5 TIDB的存储和计算能力
TIDB的存储和计算分别由TiKV和TIDB Server完成。
存储能力TiKV Server通常是3+的,TIDB每份数据缺省为三副本。TiKV集群存储的数据格式是KV的,在TIDB中,并不是将数据直接存储在HDD/SSD上,而是通过RocksDB实现了TB级别的本地存储方案,着重提一点:RocksDB和HBASE一样,都是通过LSM树作为存储方案,避免了B+树叶子节点膨胀带来的大量随机读写,从而提高了整体的吞吐量。
计算能力TIDB Server本身是无状态的,意味着当计算能力成为瓶颈的时候,可以直接扩容机器,对用户是透明的。理论上TIDB Server的数量并没有上限限制。
2.6 TIDB特性总结
TIDB作为新一代的NewSQL数据库,在数据库领域已经逐步站稳脚跟,结合了Etcd/MySQL/HDFS/HBase/Spark等技术的突出特点,随着TIDB的大面积推广,会逐渐弱化OLTP/OLAP的界限,并简化目前冗余的ETL流程,引起新一轮的技术浪潮。一言蔽之,TIDB未来可期。
3 TIDB部署
TIDB生产环境对系统以及内存、CPU都有要求,如果不满足是不能安装的,因此在V4.0之前推荐使用docker compose进行部署)(如果你只是想测试TIDB,体验TIDB的特性,或者用于开发环境,你可以使用Docker Compose在本地快速部署TIDB集群,该部署方式不适用于生产环境)。不过在V4.0以及后,TIDB开发了自己的集群部署管理工具——TiUP,TiUP是当前TIDB推荐使用的集群部署管理工具,因此在V4.0之后,推荐大家使用TiUP来进行部署测试或者实际部署。TiUP是TIDB4.0版本引入的集群运维工具,通过TiUP可以进行TIDB的日常维护工作,包括部署、启动、关闭、销毁、弹性扩缩容和升级TIDB集群,以及管理TIDB集群参数。
本人的腾讯云服务器是linux系统CPU为amd64架构,2核4g,6m带宽,但是在进行单机部署模拟生产环境集群时,会卡死,根本无法进行,因此笔者使用了虚拟机进行部署,为虚拟机开辟了大量的内存,最终在解决了一些坑之后,成功部署,下篇博客将详细讲解单机模拟部署生产环境集群,遇到的坑和解决方法。
总结
这篇博客对TIDB进行了介绍,并对数据库的发展和分类,以及当前使用广泛的MySQL数据库的瓶颈进行了阐述。TIDB是一个开源分布式关系型数据库,是NewSQL的一个代表。TIDB具有很多优秀的特性,例如:实现一键水平伸缩,强一致性的多副本数据安全,分布式事务,实时OLAP等重要特性。一言以蔽之:TIDB未来可期,下篇博客将介绍单机模拟部署生产环境集群的方法,遇到的坑和解决方式。
边栏推荐
- C language beginner level - realize the minesweeping game
- Codeforces Round #803 (Div. 2)vp
- HDU - 1024 Max Sum Plus Plus(DP)
- QT write custom control - self drawn battery
- SQL必会题之留存率
- Scope data export mat
- win10、win11中Elan触摸板滚动方向反转、启动“双指点击打开右键菜单“、“双指滚动“
- 不是你脑子不好用,而是因为你没有找到对的工具
- Code shoe set - mt3114 · interesting balance - explain it with examples
- 如何添加葫芦儿派盘
猜你喜欢

芯片,建立在沙粒上的帝国!

HCM 初学 ( 三 ) - 快速输入PA70、PA71 浏览员工信息PA10

Build 2022 上开发者最应关注的七大方向主要技术更新

穿越派·派盘 + Mountain Duck = 数据本地管理

Some errors encountered in MySQL data migration

Multi table operation - foreign key cascade operation

喊我们大学生个人云服务特供商

Summary of common components of applet

ssm+mysql二手交易网站(论文+源码获取链接)

A little assistant for teenagers' physiological health knowledge based on wechat applet (free source code + project introduction + operation introduction + operation screenshot + Thesis)
随机推荐
Some errors encountered in MySQL data migration
MySQL数据迁移遇到的一些错误
穿越派与贸大合作,为大学生增添效率
It's not that you have a bad mind, but that you haven't found the right tool
Chip, an empire built on sand!
SQL必会题之留存率
【知识点总结】卡方分布,t分布,F分布
How to transmit and share 4GB large files remotely in real time?
Crossing sect · paipan + Siyuan notes = private notebook
码蹄集 - MT3114 · 有趣的平衡 - 用样例通俗地讲解
教务管理系统(免费源码获取)
tese_Time_2h
喊我们大学生个人云服务特供商
SystemVerilog学习-10-验证量化和覆盖率
Know the future of "edge computing" from the Nobel prize!
论文学习记录随笔 多标签之GLOCAL
OpenGL ES: (1) OpenGL ES的由来 (转)
OneFlow源码解析:算子签名的自动推断
2022.6.30-----leetcode. one thousand one hundred and seventy-five
libpng12.so.0: cannot open shared object file: No such file or directory 亲测有效