01 整體思考
提到流批一體,不得不提傳統的大數據平臺 —— Lambda 架構。它能够有效地支撐離線和實時的數據開發需求,但它流和批兩條數據鏈路割裂所導致的高開發維護成本以及數據口徑不一致是無法忽視的缺陷。
通過一套數據鏈路來同時滿足流和批的數據處理需求是最理想的情况,即流批一體。此外我們認為流批一體還存在一些中間階段,比如只實現計算的統一或者只實現存儲的統一也是有重大意義的。
以只實現計算統一為例,有一些數據應用的實時性要求比較高,比如希望端到端的數據處理延時不超過一秒鐘,這對目前開源的、適合作為流批統一的存儲來說是一個很大的挑戰。以數據湖為例,它的數據可見性與 commit 的間隔相關,進而與 Flink 做 checkpoint 的時間間隔相關,此特性結合數據處理鏈路的長度,可見做到端到端一秒鐘的處理並不容易。因此對於這類需求,只實現計算統一也是可行的。通過計算統一去降低用戶的開發及維護成本,解决數據口徑不一致的問題。

在流批一體技術落地的過程中,面臨的挑戰可以總結為以下 4 個方面:
- 首先是數據實時性。如何把端到端的數據時延降低到秒級別是一個很大的挑戰,因為它同時涉及到計算引擎及存儲技術。它本質上屬於性能問題,也是一個長期目標。
- 第二個挑戰是如何兼容好在數據處理領域已經廣泛應用的離線批處理能力。此處涉及開發和調度兩個層面的問題,開發層面主要是複用的問題,比如如何複用已經存在的離線錶的數據模型,如何複用用戶已經在使用的自定義開發的 Hive UDF 等。調度層面的問題主要是如何合理地與調度系統進行集成。
- 第三個挑戰是資源及部署問題。比如通過不同類型的流、批應用的混合部署來提高資源利用率,以及如何基於 metrics 來構建彈性伸縮能力,進一步提高資源利用率。
- 最後一個挑戰也是最困難的一個:用戶觀念。大多數用戶對於比較新的技術理念通常僅限於技術交流或者驗證,即使驗證之後覺得可以解决實際問題,也需要等待合適的業務來試水。這個問題也催生了一些思考,平臺側一定要多站在用戶的視角看待問題,合理地評估對用戶的現有技術架構的改動成本以及用戶收益、業務遷移的潜在風險等。
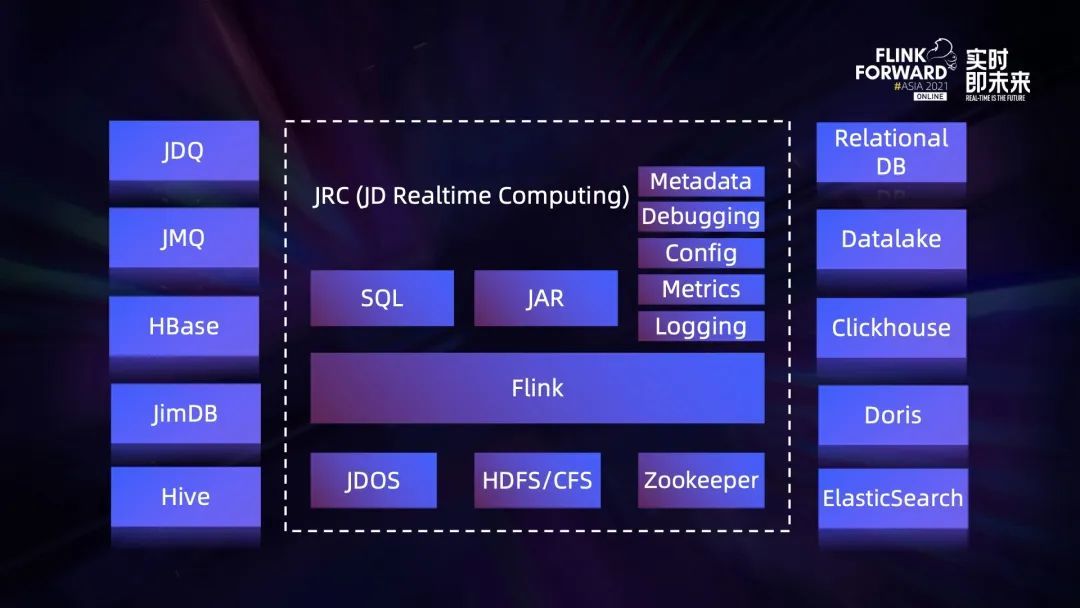
上圖是京東實時計算平臺的全景圖,也是我們實現流批一體能力的載體。中間的 Flink 基於開源社區版本深度定制。基於該版本構建的集群,外部依賴包含三個部分,JDOS、HDFS/CFS 和 Zookeeper。
- JDOS 是京東的 Kubernetes 平臺,目前我們所有 Flink 計算任務容器化的,都運行在這套平臺之上;
- Flink 的狀態後端有 HDFS 和 CFS 兩種選擇,其中 CFS 是京東自研的對象存儲;
- Flink 集群的高可用是基於 Zookeeper 構建的。
在應用開發方式方面,平臺提供 SQL 和 Jar 包兩種方式,其中 Jar 的方式支持用戶直接上傳 Flink 應用 Jar 包或者提供 Git 地址由平臺來負責打包。除此之外我們平臺化的功能也相對比較完善,比如基礎的元數據服務、SQL 調試功能,產品端支持所有的參數配置,以及基於 metrics 的監控、任務日志查詢等。
連接數據源方面,平臺通過 connector 支持了豐富的數據源類型,其中 JDQ 基於開源 Kafka 定制,主要應用於大數據場景的消息隊列;JMQ 是京東自研,主要應用於在線系統的消息隊列;JimDB 是京東自研的分布式 KV 存儲。

在當前 Lambda 架構中,假設實時鏈路的數據存儲在 JDQ,離線鏈路的數據存在 Hive 錶中,即便計算的是同一業務模型,元數據的定義也常常是存在差异的,因此我們引入統一的邏輯模型來兼容實時離線兩邊的元數據。
在計算環節,通過 FlinkSQL 結合 UDF 的方式來實現業務邏輯的流批統一計算,此外平臺會提供大量的公用 UDF,同時也支持用戶上傳自定義 UDF。針對計算結果的輸出,我們同樣引入統一的邏輯模型來屏蔽流批兩端的差异。對於只實現計算統一的場景,可以將計算結果分別寫入流批各自對應的存儲,以保證數據的實時性與先前保持一致。
對於同時實現計算統一和存儲統一的場景,我們可以將計算的結果直接寫入到流批統一的存儲。我們選擇了 Iceberg 作為流批統一的存儲,因為它擁有良好的架構設計,比如不會綁定到某一個特定的引擎等。
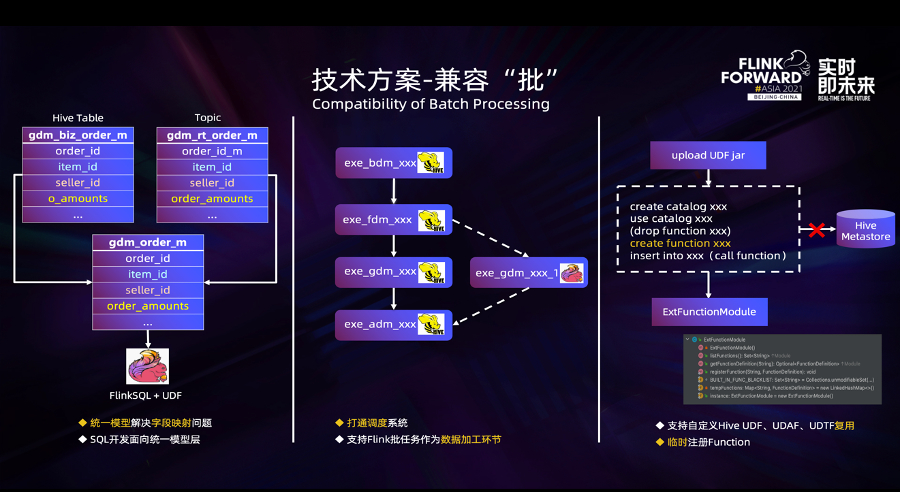
在兼容批處理能力方面,我們主要進行了以下三個方面的工作:
第一,複用離線數倉中的 Hive 錶。
以數據源端為例,為了屏蔽上圖左側圖中流、批兩端元數據的差异,我們定義了邏輯模型 gdm_order_m 錶,並且需要用戶顯示地指定 Hive 錶和 Topic 中的字段與這張邏輯錶中字段的映射關系。這裏映射關系的定義非常重要,因為基於 FlinkSQL 的計算只需面向這張邏輯錶,而無需關心實際的 Hive 錶與 Topic 中的字段信息。在運行時通過 connector 創建流錶和批錶的時候,邏輯錶中的字段會通過映射關系被替換成實際的字段。
在產品端,我們可以給邏輯錶分別綁定流錶和批錶,通過拖拽的方式來指定字段之間的映射關系。這種模式使得我們的開發方式與之前有所差异,之前的方式是先新建一個任務並指定是流任務還是批任務,然後進行 SQL 開發,再去指定任務相關的配置,最後發布任務。而在流批一體模式下,開發模式變為了首先完成 SQL 的開發,其中包括邏輯的、物理的 DDL 的定義,以及它們之間的字段映射關系的指定,DML 的編寫等,然後分別指定流批任務相關的配置,最後發布成流批兩個任務。
第二,與調度系統打通。
離線數倉的數據加工基本是以 Hive/Spark 結合調度的模式,以上圖中居中的圖為例,數據的加工被分為 4 個階段,分別對應數倉的 BDM、FDM、GDM 和 ADM 層。隨著 Flink 能力的增强,用戶希望把 GDM 層的數據加工任務替換為 FlinkSQL 的批任務,這就需要把 FlinkSQL 批任務嵌入到當前的數據加工過程中,作為中間的一個環節。
為了解决這個問題,除了任務本身支持配置調度規則,我們還打通了調度系統,從中繼承了父任務的依賴關系,並將任務自身的信息同步到調度系統中,支持作為下遊任務的父任務,從而實現了將 FlinkSQL 的批任務作為原數據加工的其中一個環節。
第三,對用戶自定義的 Hive UDF、UDAF 及 UDTF 的複用。
對於現存的基於 Hive 的離線加工任務,如果用戶已經開發了 UDF 函數,那麼最理想的方式是在遷移 Flink 時對這些 UDF 進行直接複用,而不是按照 Flink UDF 定義重新實現。
在 UDF 的兼容問題上,針對使用 Hive 內置函數的場景,社區提供了 load hive modules 方案。如果用戶希望使用自己開發的 Hive UDF,可以通過使用 create catalog、use catalog、create function,最後在 DML 中調用的方式來實現, 這個過程會將 Function 的信息注册到 Hive 的 Metastore 中。從平臺管理的角度,我們希望用戶的 UDF 具備一定的隔離性,限制用戶 Job 的粒度,减少與 Hive Metastore 交互以及產生髒函數元數據的風險。
此外,當元信息已經被注册過,希望下次能在 Flink 平臺端正常使用,如果不使用 if not exist 語法,通常需要先 drop function,再進行 create 操作。但是這種方式不够優雅,同時也對用戶的使用方式有限制。另一種解决方法是用戶可以注册臨時的 Hive UDF,在 Flink1.12 中注册臨時 UDF 的方式是 create temporary function,但是該 Function 需要實現 UserDefinedFunction 接口後才能通過後面的校驗,否則會注册失敗。
所以我們並沒有使用 create temporary function,而是對 create function 做了一些調整,擴展了 ExtFunctionModule,將解析出來的 FunctionDefinition 注册到 ExtFunctionModule 中,做了一次 Job 級別的臨時注册。這樣的好處就是不會污染 Hive Metastore,提供了良好的隔離性,同時也沒有對用戶的使用習慣產生限制,提供了良好的體驗。
不過這個問題在社區 1.13 的版本已經得到了綜合的解决。通過引入 Hive 解析器等擴展,已經可以把實現 UDF、GenericUDF 接口的自定義 Hive 函數通過 create temporary function 語法進行注册和使用。
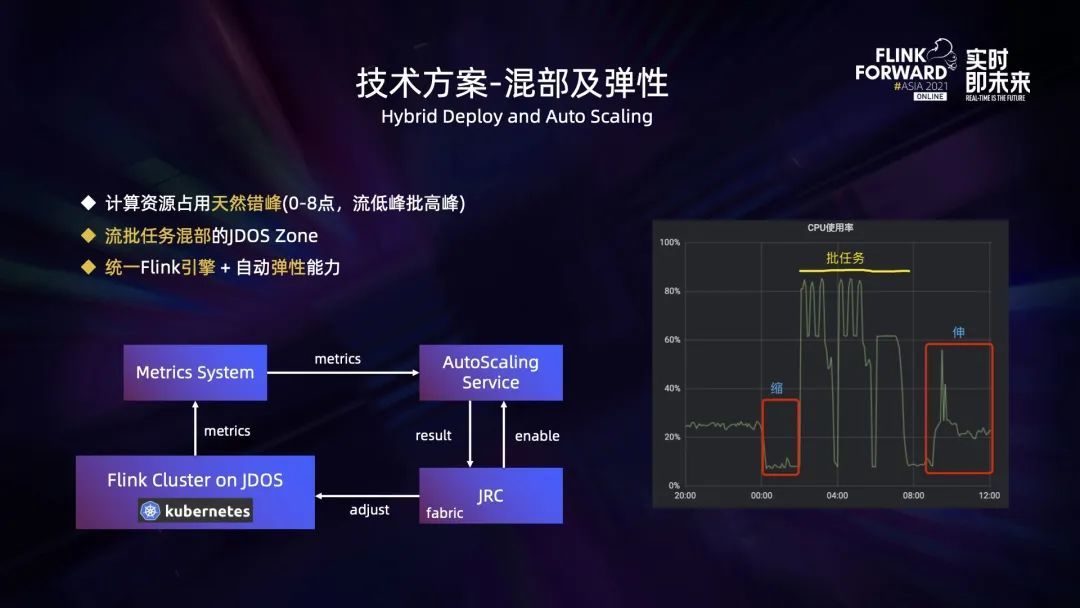
資源占用方面,流處理和批處理是天然錯峰的。對於批處理,離線數倉每天 0 點開始計算過去一整天的數據,所有的離線報錶的數據加工會在第二天上班前全部完成,所以通常 00:00 到 8:00 是批計算任務大量占用資源的時間段,而這個時間段通常在線的流量都比較低。流處理的負載與在線的流量是正相關的,所以這個時間段流處理的資源需求是比較低的。上午 8 點到晚上 0 點,在線的流量比較高,而這個時間段批處理的任務大部分都不會被觸發執行。
基於這種天然的錯峰,我們可以通過在專屬的 JDOS Zone 中進行不同類型的流批應用的混部來提昇資源的使用率,並且如果統一使用 Flink 引擎來處理流批應用,資源的使用率會更高。
同時為了使應用可以基於流量進行動態調整,我們還開發了自動彈性伸縮的服務 (Auto-Scaling Service)。它的工作原理如下:運行在平臺上的 Flink 任務上報 metrics 信息到 metrics 系統,Auto-Scaling Service 會基於 metrics 系統中的一些關鍵指標,比如 TaskManager 的 CPU 使用率、任務的背壓情况等來判定任務是否需要增减計算資源,並把調整的結果反饋給 JRC 平臺,JRC 平臺通過內嵌的 fabric 客戶端將調整的結果同步到 JDOS 平臺,從而完成對 TaskManager Pod 個數的調整。此外,用戶可以在 JRC 平臺上通過配置來决定是否為任務開啟此功能。
上圖右側圖錶是我們在 JDOS Zone 中進行流批混部並結合彈性伸縮服務試點測試時的 CPU 使用情况。可以看到 0 點流任務進行了縮容,將資源釋放給批任務。我們設置的新任務在 2 點開始執行,所以從 2 點開始直到早上批任務結束這段時間,CPU 的使用率都比較高,最高到 80% 以上。批任務運行結束後,在線流量開始增長時,流任務進行了擴容,CPU 的使用率也隨之上昇。
更多內容請看:
https://blog.stackanswer.com/articles/2022/07/01/1656663988707.html
![[CTF] AWDP summary (WEB)](/img/4c/574742666bd8461c6f9263fd6c5dbb.png)