当前位置:网站首页>UC Berkeley proposes a multitask framework slip
UC Berkeley proposes a multitask framework slip
2022-07-03 21:36:00 【Doctor of artificial intelligence】
above Artificial intelligence algorithms and Python big data Get more dry goods
On the top right ··· Set to star *, Get resources the first time
Just for academic sharing , If there is any infringement , Contact deletion
Reproduced in : Almost Human
To explore CV Whether self supervised learning in the field will affect NLP field , From the University of California, Berkeley and Facebook AI Researchers in the Institute have proposed a new framework combining language supervision and image self supervision SLIP.
Recent studies have shown that , On challenging visual recognition tasks , Self supervised pre training can improve supervised learning .CLIP As a new method of supervised learning , It has shown excellent performance in various benchmark tests .
In recent days, , In order to explore whether the momentum of self supervised learning of images will enter the field of language supervision , From the University of California, Berkeley and Facebook AI Researchers at the Institute investigated CLIP Whether formal language supervision also benefits from image self supervision . The study notes that , It is not clear whether combining the two training goals will make performance stronger , But these two goals require the model to encode different and contradictory information about the quality of the image , This will cause interference .

Address of thesis :https://arxiv.org/abs/2112.12750v1
Project address :https://github.com/facebookresearch/SLIP
To explore these issues , This study proposes a multi task framework combining language supervision and self supervision SLIP(Self-supervision meet Language-Image Pre-training), And in YFCC100M Pre training on a subset of SLIP Model , The characterization quality was evaluated under three different settings : Zero sample migration 、 Linear classification and end-to-end fine tuning . Except for one group 25 Beyond the Classification Benchmark , The study is still ImageNet The performance of downstream tasks is evaluated on the data set .
This research is based on different model sizes 、 Experiments on training plans and pre training data sets further verify its findings . The research results finally show ,SLIP Significantly improved performance in most evaluation tests , This shows that self-monitoring has universal utility in the context of language monitoring . Besides , The researchers analyzed the various components of the method in more detail , For example, the selection of pre training data sets and data processing methods , The evaluation limitations of such methods are discussed .
SLIP frame
This research proposes a framework combining language supervision and image self supervision SLIP, To learn visual representations without category labels . During pre training , Build a separate view of each input image for the language supervision and image self supervision branches , Then feedback through the shared image encoder . During the training process, the image encoder learns to represent visual input in a semantically meaningful way . Then the study measures the quality of these learning representations by evaluating their utility in downstream tasks .
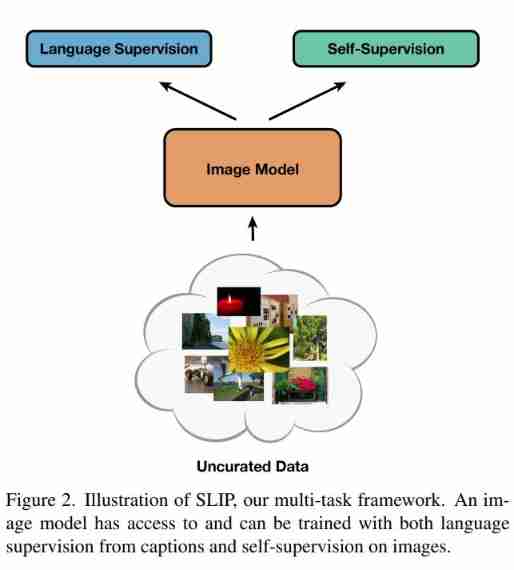
Method
The following algorithm 1 An overview of SLIP-SimCLR. stay SLIP During each forward pass in , All images are fed back through the same encoder .CLIP and SSL The goal is calculated on the correlation embedding , Then it is summed up as a single scalar loss , By readjusting SSL Goals to balance these two goals . The study will SLIP-SimCLR Referred to as SLIP.

SLIP Increased the number of image processing , This leads to about 3 Times more activation , Therefore, it will expand the memory occupation of the model and slow down the forward transfer speed in the training process .
Improved training process
CLIP The authors of mainly use include 400M Images - Train large private data sets of text , This reduces the need for regularization and data enhancement . It's happening again CLIP when , The researchers found some simple adjustments mainly for data enhancement . When in YFCC15M When pre training on , These adjustments significantly improve performance .
The study improved the training process , Use the improved ResNet-50 Realized 34.6% Zero samples of migrate to ImageNet, More than the original result 31.3%, by comparison , Another study CLIP Reappearance in ImageNet [29] It has been realized. 32.7% The accuracy of . The experiment of this study mainly focuses on vision Transformer Model (ViT) series , Because they have powerful extension behavior [17]. And the study used the improved process to train all ViT Model , In order to set a strong baseline for the evaluation and comparison of the methods proposed in this study .
Evaluation experiments
ImageNet Classification task
The study evaluated the model in three different settings ImageNet Performance on : Zero sample migration 、 Linear classification and end-to-end fine tuning .
The zero sample migration task directly evaluates the performance of the model on the Classification Benchmark after pre training , Without updating any model weights . By simply selecting the class closest to the input image , The model supervised by contrast language can be used as an image classifier ;
Linear classification , Also known as linear detection , It is a standard evaluation method for evaluating unsupervised or self supervised representations . Train the ultimate classification layer of random initialization , Freeze all other model weights at the same time ;
Last , Another way to evaluate the quality of representations is , When fine tuning the model end-to-end , Evaluate whether the pre training model can improve the performance of supervised learning .
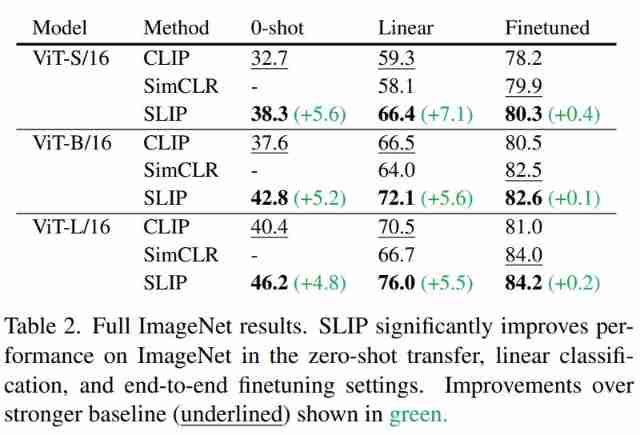
A common evaluation setting in self supervised learning is ImageNet( namely ImageNet-1K) Upper training model and linear classifier , Even if there is no label , It is also a highly planned and class balanced dataset . surface 1 stay YFCC15M and ImageNet Upper use SimCLR and MoCo v3 Training ViT-B/16. stay ImageNet The linear classification and end-to-end fine tuning are evaluated on the model . When in YFCC15M instead of ImageNet When pre training on ,SimCLR and MoCo v3 The accuracy of linear classification has decreased 10% above , Sharp performance degradation .

The following table 2 Three sizes of Vision Transformer And all three ImageNet Set up CLIP、SimCLR and SLIP The results of the assessment of . All the models are in YFCC15M On training 25 individual epoch. The study found that language supervision and image self supervision are SLIP Interact constructively in , The performance of these two methods is improved separately .
Expansion of model scale and computation
In this part , Researchers have explored the use of greater computational effort ( Train longer ) And larger visual models ,SLIP How has your performance changed . They noticed ,YFCC15M Upper 100 A training epoch Corresponding ImageNet1K Upper 1200 A training epoch.
The following table 3 The results show that , Whether it's increasing training time , Or increase the size of the model ,SLIP Can achieve good expansion .

Other benchmarks
In the table below 4 in , The researchers evaluated a set of downstream image classification tasks zero-shot Transfer learning performance . These datasets span many different fields , Including daily scenes ( Such as traffic signs )、 Professional field ( Such as medical and satellite images )、 Video frame 、 Rendered text with or without visual context .
On these datasets , We see , Larger models and uses SLIP Longer training usually improves zero-shot The accuracy of transfer learning .

Other pre training data sets
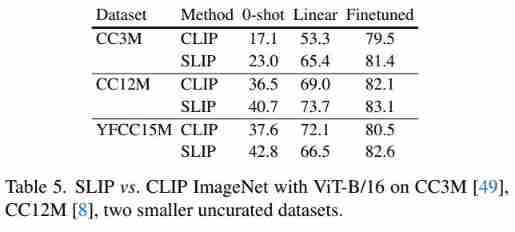
except YFCC15M outside , The researchers also used two other images - Text data set ——CC12M and CC3M—— Experiments were carried out . The following table 5 Shown , They are CC12M and CC3M Use at the same time SLIP and CLIP Training ViT-B/16, And with them before YFCC15M Compare the data obtained on . Of all the ImageNet Evaluation setting ,SLIP All ratio CLIP There is room for improvement . It is worth noting that , stay CC12M instead of YCC15M Pre training SLIP Will produce a lower zero-shot Accuracy rate , But it will actually bring higher linearity and fine tuning performance .CLIP Let people see more amazing 1.6% The fine tuning performance of .
Other self-monitoring frameworks
The author mentioned in his paper ,SLIP Many different self-monitoring methods are allowed . They SimCLR Different alternatives to ——MoCo v3、BYOL and BeiT stay ViT-B/16 Several experiments were carried out on .
The following table 6 Show , None of the three alternatives performs as well SLIP-SimCLR. The most surprising result is , Even though BEiT It is the strongest self-monitoring method tested here , but SLIP-BEiT Your performance is the worst . This may be due to the large input difference between the pre training and deployment stages . For all that , All these suboptimal SLIP The variant is still better than CLIP High performance .

------------------
Statement : This content comes from the Internet , The copyright belongs to the original author
Picture source network , It does not represent the position of the official account . If there is any infringement , Contact deletion
AI Doctor's personal wechat , There are still a few vacancies


How to draw a beautiful deep learning model ?
How to draw a beautiful neural network diagram ?
Read all kinds of convolutions in deep learning
Let's have a look and support 
边栏推荐
- 上周内容回顾
- Visiontransformer (I) -- embedded patched and word embedded
- 全网都在疯传的《老板管理手册》(转)
- 十大券商开户注册安全靠谱吗?有没有风险的?
- No matter how hot the metauniverse is, it cannot be separated from data
- Global and Chinese market of recycled yarn 2022-2028: Research Report on technology, participants, trends, market size and share
- 17 websites for practicing automated testing. I'm sure you'll like them
- UI automation test: selenium+po mode +pytest+allure integration
- Go learning notes (4) basic types and statements (3)
- Idea shortcut word operation
猜你喜欢

treevalue——Master Nested Data Like Tensor
@Transactional注解失效的场景
Getting started with postman -- environment variables and global variables

Mysql - - Index

Goodbye 2021, how do programmers go to the top of the disdain chain?

内存分析器 (MAT)

Leetcode daily question 540 A single element in an ordered array Valentine's Day special article looking for a single dog in a pile of lovers ~ the clown is myself

How to choose cache read / write strategies in different business scenarios?

Basic preprocessing and data enhancement of image data
![抓包整理外篇——————autoResponder、composer 、statistics [ 三]](/img/bf/ac3ba04c48e80b2d4f9c13894a4984.png)
抓包整理外篇——————autoResponder、composer 、statistics [ 三]
随机推荐
Qualcomm platform WiFi update disconnect end open event
90 后,辞职创业,说要卷死云数据库
Compilation Principle -- syntax analysis
90 後,辭職創業,說要卷死雲數據庫
Experience summary of database storage selection
treevalue——Master Nested Data Like Tensor
flink sql-client 退出,表就会被清空怎么办?
Collections SQL communes
抓包整理外篇——————autoResponder、composer 、statistics [ 三]
Basic preprocessing and data enhancement of image data
十大券商开户注册安全靠谱吗?有没有风险的?
Xai+ network security? Brandon University and others' latest "interpretable artificial intelligence in network security applications" overview, 33 page PDF describes its current situation, challenges,
Rhcsa third day operation
Mysql - - Index
MySQL——规范数据库设计
仿网易云音乐小程序
leetcode-540. A single element in an ordered array
淺析 Ref-NeRF
MySQL——索引
Global and Chinese market of telematics boxes 2022-2028: Research Report on technology, participants, trends, market size and share