当前位置:网站首页>Experience summary of database storage selection
Experience summary of database storage selection
2022-07-03 20:57:00 【Amoy Technology】

We always encounter problems related to data storage in our work Bug The repair order , There will be some problems related to data model design and storage in the development and design of new requirements . After several selection and discussion of storage scheme design, it is found that a more comprehensive thinking framework is needed .
Many storage schemes commonly used in daily development are “ si ” Of , With experience 、 Habitual selection , But there is little research on their detailed characteristics or constraints .
In addition to the storage scheme you can use at hand , We should also pay attention to more appropriate storage solutions in the market .
Certain technical pre research and reserve can help better technical scheme design in the future .
So I wrote this article , Throw out my summary and thinking , I hope to make some more advanced in the future ( appropriate ) Technology is introduced into business development , Help business development .
The purpose of storage selection is still for our use scenarios and user services , Therefore, you need to answer some questions before model selection Business indicators & Technical indicators Problems in , So that we can know the application environment of storage selection .
User volume : What is the estimated number of users ? Millions or billions ?
Data volume : How much data is estimated ? How much can the average daily increment be ?
Reading and writing preferences : Whether to read more data or write more data ?
Data scenarios : Strong transactional or analytical requirements ?
Operational performance requirements : What is the amount of concurrency ? peak 、 Average 、 What are the respective estimates of the trough ?
The classification methods of databases are very diverse , There are great differences due to different reference dimensions , Here are some common classifications .
| Database type | Common databases |
|---|---|
Relational type | MySQL、Oracle、DB2、SQLServer etc. . |
Non relational | Hbase、Redis、MongodDB etc. . |
Line storage | MySQL、Oracle、DB2、SQLServer etc. . |
The column type storage | Hbase、ClickHouse etc. . |
Distributed storage | Cassandra、Hbase、MongodDB etc. . |
Key value storage | Memcached、Redis、MemcacheDB etc. . |
Graphic storage | Neo4J、TigerGraph etc. . |
Document storage | MongoDB、CouchDB etc. . |
Easy to understand
It can be logically expressed by two-dimensional table structure , Relatively reticular 、 Layers and other models are easier to understand . Strictly follow the data format and length specifications , Data in behavioral units , A row of data represents an entity information , The attributes of each row of data are the same .It is easy to operate
General purpose SQL Language makes it very convenient to operate relational database , Support join And so on ,Sql + Two dimensional relation is the most incomparable advantage of relational database , This ease of use is very close to developers .Transaction features
Support ACID characteristic , Consistency between data can be maintained , This is a very important reason to use relational databases , Like bank transfer , Zhang San to Li Si 100 Yuan , Three buckles 100 element , Li SIgA 100 element , And must succeed or fail at the same time , Otherwise, the user's capital will be damaged .The data is stable
Data persistence to disk , No risk of data loss .Stable service
The most commonly used relational database products MySql、Oracle Excellent server performance , Stable service , Usually there are few downtime exceptions .
The bottleneck of the database under gaobingfa is obvious
Data is stored in rows , Even if it only works on one of the columns , It also reads the entire row of data from the storage device into memory , Lead to IO Higher . write in / In case of frequent updates , Databases often appear CPU soar 、Sql Slow execution 、 The client reports abnormal conditions such as insufficient database connection pool , And the performance bottleneck is increased CPU、 Replace the SSD 、 Continue to buy servers and databases for sub database processing ROI Not high , Limited by its own characteristics , It may take a lot of money to achieve the desired effect . So for example, ten thousand people kill every second , It is absolutely impossible for us to deduct inventory directly through the database , It is necessary to make a flow funnel .It costs a lot to maintain indexes
In order to provide rich query capabilities , Generally, a hotspot table has multiple secondary indexes , Once you have a secondary index , The addition of data must be accompanied by the addition of all secondary indexes , The update of data must be accompanied by the update of all secondary indexes , This inevitably reduces the reading and writing ability of relational databases , And the more indexes, the worse reading and writing ability . Except that data files inevitably take up space , Index takes up a lot of space .The cost of maintaining data consistency is high
Data consistency is the core of relational databases , But also in order to maintain the cost of data consistency is very big . We all know SQL The standard defines different isolation levels for transactions , From low to high is read uncommitted 、 Read submitted 、 Repeatable degrees 、 Serialization , The lower the transaction isolation level , The more concurrent exceptions are possible , But generally speaking, the stronger the concurrency can be provided . So in order to ensure transaction consistency , Database needs to provide concurrent control and fault recovery , The former is used to reduce concurrent exceptions , The latter can ensure that the transaction and database state will not be destroyed when the system is abnormal . For concurrency control , The core idea is to lock , No matter optimistic lock or pessimistic lock , As long as the higher level of isolation provided , So the performance of reading and writing must be worse .All kinds of problems brought about by horizontal expansion are difficult to deal with
As the business expands , One way is to make a sub database of the database , After doing the sub Treasury , Data migration (1 The data of each database is typed according to certain rules 2 Library )、 Cross Library join、 Distributed transaction processing is a problem to consider , Especially distributed transaction processing , There is no particularly good solution in the industry right now .Table structure expansion is not convenient
Because the database stores structured data , So the table structure schema Is constant , It's inconvenient to expand , If you need to modify the table structure , You need to perform DDL(data definition language) Statement modification , The modification will result in a lock table , Some services are not available .Full text search is weak
for example like “% China is great %”, You can only search for “2019 China is really great in , love one 's country ”, Can't search for “ China is so great ” Such a text , I don't have the ability of word segmentation , And like The query in “% China is great ” Under such search conditions , Unable to hit index , It will reduce the query efficiency greatly .
NoSql The full name is Not Only SQL, Non relational database in general , It is a supplement to relational database , Pay special attention to adding these two words , It means NoSql It's not the opposite of a relational database , They have their own advantages and disadvantages , Learn from others' strong points and close the gap , Choosing the right storage engine in the right scenario is the right way . Let's take a look at the common NoSql And their representative products , And for each NoSql The advantages and disadvantages and applicable scenarios are analyzed , It's easy to be familiar with every kind of NoSql Characteristics , Convenient technology selection .
KV type NoSql As the name implies, it is a non relational database stored in the form of key value pairs , It's the simplest 、 The easiest to understand is also the most familiar one NoSql.Redis、MemCache Is one of the representatives ,Redis again KV type NoSql The most widely used NoSql,KV Type database to Redis For example , There are two main advantages to sum up :
Data is based on memory , Efficient reading and writing
KV Type data , The time complexity is O(1), Fast query speed
therefore ,KV type NoSql The biggest advantage is high performance , utilize Redis Self contained BenchMark Do benchmarking ,TPS Accessible 10 Ten thousand , Very strong performance . alike Redis And all of it KV type NoSql All of them have obvious shortcomings :
Only according to the K check V, Not according to the V check K
The query method is single , Only KV The way , Conditional queries are not supported , The only way to do this is data redundancy , But it's a huge waste of storage space
Memory is limited , Can't support massive data storage
because KV type NoSql The storage of is based on memory , There's a risk of losing data ( There are persistent storage schemes )
in summary ,KV type NoSql The most suitable scenario is the cached scenario :Read far more than write
Strong reading ability
There is no need for persistence , Data loss can be tolerated
For data that reads far more than writes , Introduce a layer of cache , Every read reads from the cache , Can't read from cache , Then go to the database to get , Write to cache after fetching , There's usually no big problem with having a failure mechanism for data . Generally speaking , Caching is the first choice of performance optimization and the most effective solution .
▐ Search type NoSql( representative —-ElasticSearch)
Traditional relational database mainly through index to achieve the purpose of fast query , But in the context of full-text search , There is nothing index can do ,like Query can not meet all the fuzzy matching requirements , Second, the use of restrictions is too large and improper use is easy to cause slow query , Search type NoSql The birth of relational database is to solve the problem of weak full-text search ability ,ElasticSearch It's a search type NoSql The representative product of .
The principle of full-text search is inverted index , Let's see what an inverted index is . To say inverted index, let's see what is a forward index , The traditional forward index is a document –> Keyword mapping , for example ”Tom is my friend” this sentence , It will be divided into ”Tom”、”is”、”my”、”friend” Four words , Scan documents while searching , Find out if you meet the conditions . The principle of this method is very simple , But its retrieval efficiency is too low , There is little practical value .
Inverted index is the opposite , It's a keyword –> Mapping of documents , for instance , Now here are four short sentences :
"Tom is Tom"
"Tom is my friend"
"Thank you, Betty"
"Tom is Betty's husband"
Search engines will cut a sentence into N Key words , And maintain the number of times that keywords appear in each text by their dimensions . So next search ”Tom” When , because Tom The word is in ”Tom is Tom”、”Tom is my friend”、”Tom is Betty’s husband” In all three sentences , So all three records will be retrieved , And because ”Tom is Tom” In this sentence ”Tom” There is 2 Time , So this record is right ”Tom” This word has the best match , First show . This is the basic principle of search engine inverted index , Suppose a keyword appears in a document , So there are two parts in the inverted index :
file ID
The location situation that appears in this document
We can draw inferences from one example , We search ”Betty Tom” The same is true of these two words , Search engines will ”Betty Tom” It's divided into ”Tom”、”Betty” Two words , According to the satisfaction rate specified by the developer , For example, satisfaction rate = 50%, So as long as one of the two words appears in the record, the record will be retrieved , Then show it according to the matching degree .
Search type NoSql With ElasticSearch For example , Its advantages are :
Support participle scene 、 Full text search , This is different from the biggest feature of relational database
Support condition query , Support aggregation operations , Like a relational database Group By, But it's more powerful , Suitable for data analysis
There is no risk of data loss when writing files , In the cluster environment, it is convenient to scale horizontally , Can carry PB Level of data
High availability , Automatically discover new or failed nodes , Restructuring and rebalancing data , Make sure the data is secure and accessible
Again ,ElasticSearch There are also obvious disadvantages :
Performance depends on memory , It's also the most important thing to pay attention to when using , Eat hardware resources very much 、 Eat memory , Big data 64G + SSD Basically standard , Double the memory of the same configuration , It costs a lot more money in a month . as for ElasticSearch Memory is mainly used in the following places :
a. Indexing Buffer----ElasticSearch be based on Luence,Lucene The inverted index of is generated in memory first , And then on a regular basis Segment File The way to brush the disk , Every Segment File In fact, it is a complete inverted index
b. Segment Memory---- Inverted index is based on keywords ,Lucene stay 4.0 After that, all keywords will be replaced with FST This way of data structure loads all keywords into memory at startup , Speed up query , The official advice is to leave at least half of the system memory for Lucene
c. All kinds of cache ----Filter Cache、Field Cache、Indexing Cache etc. , Used to improve query analysis performance , for example Filter Cache Used to cache used Filter The result set
d. Cluter State Buffer----ElasticSearch Designed for each Node Can respond to user requests , So every Node There is a copy of the cluster state in the memory of , The status information of a large cluster may be very largeThere is a delay between reading and writing , The data written is almost 1s Looks will be read to ( Many indexes need to be maintained when writing data )
Data structure flexibility is not high , Once the field is created, the type cannot be modified , If a field in the created data table is not full-text indexed , Want to add , Then we can only delete the whole table and rebuild it .
therefore , Search type NoSql The most applicable scenario is conditional search, especially full-text search , As an alternative to relational databases , Usually search NoSql It will also act as a layer of cache , To protect relational databases .
in addition , Search database also has a very important application scenario . We can think of , Once the database has been divided into databases and tables , The aggregation operation that can be done in a single table 、 Whether all statistical operations are invalid ? For example, I divide the order form into 16 Databases ,1024 A watch , Then the order data is scattered in 1024 Zhang biaozhong , I'd like to make a statistics of which order with the highest amount of single transaction in Zhejiang Province was made yesterday ? I 'd like to sort all the orders from yesterday in chronological order to show you how to do it ? This is the search type NoSql Another great function of , We can uniformly type the data after the sub table in the search type NoSql in , Using search NoSql The ability of searching and aggregating the whole data .
▐ Determinant NoSql( representative —-HBase)
Determinant NoSql It has the same concept as relational database , The difference is that relational databases are organized by rows , The data field takes up space even if it has no value , Columnar storage is quite another way , It organizes data by column , The advantage is that :
Only the specified columns will be read when querying , Will not read all columns
Save space on storage , Null values are not stored , Sometimes there are a lot of duplicate data in a column ( Especially enumeration data , Gender 、 Status, etc ), This kind of data can be compressed
Columns of data are organized together , One disk IO A column of data can be read into memory at one time
One of the most representative technologies in the era of big data HBase Is the determinant NoSQL Product realization of , The main advantages are :
Mass data storage ,PB Level data can be stored anywhere , Bottom based HDFS(Hadoop file system ), Data persistence
Good read-write performance , As long as there's no abuse causing data hotspots , There is basically no problem in reading and writing
Horizontal expansion is one of the most convenient in both relational and non relational databases , Just add new machines to realize the linear growth of data capacity , And it can be used on cheap servers , Cost savings
It can store structured or semi-structured data
There is no single point of failure , High availability
The number of columns is theoretically unlimited ,HBase It only requires the number of families , Suggest 1~3 individual
The main shortcomings are :
HBase yes Hadoop Part of ecology , So it's a heavier product , Rely on a lot of Hadoop Components , Data size is not necessary , Operation and maintenance is a little complicated .
Paging queries... Are not supported , Because we can't count the total number of data .
KV Type storage , Conditional queries are weak ,HBase stay Scan In the case of scanning a batch of data, prefix matching is provided API Of , Conditional queries unless more than one... Is defined RowKey Data redundancy .
therefore HBase The comparison applies to KV A scenario where data growth cannot be estimated in the future , in addition HBase It still needs some experience , Mainly reflected in RowKey On the design of .
▐ Document type NoSql( representative —-MongoDB)
Document type NoSql It refers to the storage of semi-structured data as documents NoSql, Document type NoSql Usually, the JSON perhaps XML Format storage data , So the document type NoSql It's not Schema Of , Because there is no Schema Characteristics of , We can store and read data at will , So the document type NoSql The emergence of is to solve the problem of inconvenient expansion of relational database table structure .
MongoDB It's a document NoSql The representative product of , And it's all NoSql One of the star products in the product , Many of its concepts are similar to relational databases , therefore , about MongDB, We just need to understand it as a Free-Schema A relational database of , The main advantages are :
There are no predefined fields , It's easy to expand fields
Compared to a relational database , Excellent reading and writing performance , A query that hits a secondary index is no slower than a relational database , For the query of non index field, it is the overall winner
The disadvantage is :
Transaction operation is not supported , although Mongodb4.0 Then claim support for the business , But the effect remains to be seen
Association queries between multiple tables do not support ( Although there are ways to embed documents ),join Query still needs multiple operations
It takes up a lot of space , This is MongDB The design of , Spatial pre allocation mechanism + After deleting data, the space will not be released , Only with db.repairDatabase () To repair to release
I haven't found MongoDB There are relational databases such as MySql Of Navicat This kind of mature operation and maintenance tool
To make a long story short ,MongDB To a large extent, we can benchmark the relational database , But it's better to deal with those who don't have join、 There are no strong consistency requirements and tables Schema Ever changing data .
Through the above discussion and analysis, we have a basic selection framework guidance in mind , In fact, it's good to answer two core questions when selecting a database :
When to choose relational database , When to choose non relational database
If you choose a non relational database , What kind of non relational database to use
NoSQL Databases are sacrificed ACID Features to get higher performance , Suppose that the table data has strong transaction characteristics , Then this kind of data is not suitable for non relational databases . Besides , choose NoSQL The database should also be based on the company's technology stack framework 、 Business features 、 Operation and maintenance costs and other aspects to consider whether to adopt .

Relational databases and NoSQL Database selection , There are often several indicators to consider :
Data volume
Concurrency
The real time
Consistency requirements
Distribution and type of reading and writing
Security
O & M costs
Common software system database selection reference is as follows :
Background management system - Such as operation system , Less data , The amount of concurrency is small , Relational databases are preferred .
High flow system - Such as e-commerce single product page , Consider selecting relational database in the background , The foreground will consider choosing memory database .
Log system - The original data consider the column selection database , Log search consider choosing search engine .
Search system - For example, search in the website , Non universal search , Such as product search , Consider selecting relational database in the background , The front desk will consider choosing a search engine .
Transactional systems - Such as inventory , transaction , Bookkeeping , Consider choosing a relational database + K-V database ( As caching )+ Distributed transactions .
Offline computing - Such as a large number of data analysis , Consider a columnar database or relational database .
Real time computing - Such as real-time monitoring , You can choose memory database or column database .
In design practice , Be demand based 、 Business Driven Architecture , Whatever you choose RDB/NoSQL, It must be demand-oriented , The final data storage scheme must be a comprehensive design with various trade-offs .
We are the new product platform technology team of Alibaba Taoxi Technology Department , Relying on Amoy big data, a complete set of consumer insights is being established 、 Macro and market segment analysis 、 Competitive analysis 、 Market strategy research 、 Product innovation mechanism and other new product R & D and innovation incubation platforms , For the brand 、 Businesses and industries provide large-scale new product incubation and operation capabilities , New product Incubation Mechanism and operation strategy , Finally, a set of market research driven by big data will be established 、 A full link new product operation platform from new product research and development to new product launch and marketing . Send an email to tianhang.th#alibaba-inc.com( When sending an email , Please put # Replace with @)
Big Taobao Technology New Year greetings
“ Tiger tiger tiger ”
Paper red envelope delivery

Focus on ” Amoy Technology “ reply " Red envelopes “ You can get the collection method
(2 month 28 Japan 18:00 end )




边栏推荐
- C 10 new feature [caller parameter expression] solves my confusion seven years ago
- Rhcsa third day notes
- First knowledge of database
- 电子科技大学|强化学习中有效利用的聚类经验回放
- In 2021, the global foam protection packaging revenue was about $5286.7 million, and it is expected to reach $6615 million in 2028
- Recommendation of books related to strong foundation program mathematics
- 2166. Design bit set
- 强化學習-學習筆記1 | 基礎概念
- Wireless network (preprocessing + concurrent search)
- Go learning notes (4) basic types and statements (3)
猜你喜欢

Single page application architecture

内存分析器 (MAT)

Go learning notes (4) basic types and statements (3)

强基计划 数学相关书籍 推荐
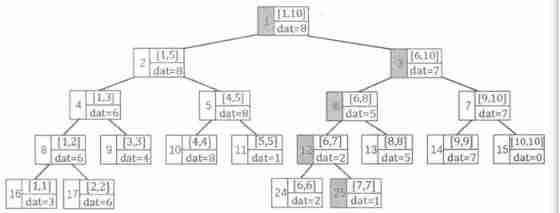
Line segment tree blue book explanation + classic example acwing 1275 Maximum number

Basic preprocessing and data enhancement of image data

2022 melting welding and thermal cutting examination materials and free melting welding and thermal cutting examination questions

Hcie security Day10: six experiments to understand VRRP and reliability
Preliminary practice of niuke.com (11)
thrift go
随机推荐
AI enhanced safety monitoring project [with detailed code]
In 2021, the global foam protection packaging revenue was about $5286.7 million, and it is expected to reach $6615 million in 2028
Measurement fitting based on Halcon learning -- Practice [1]
强基计划 数学相关书籍 推荐
浅议.NET遗留应用改造
运维各常用命令总结
Node MySQL serialize cannot rollback transactions
Operate BOM objects (key)
Basic knowledge of dictionaries and collections
Qt6 QML Book/Qt Quick 3D/基础知识
Fingerprint password lock based on Hal Library
LabVIEW training
Ask and answer: dispel your doubts about the virtual function mechanism
Task of gradle learning
内存分析器 (MAT)
Kubernetes 通信异常网络故障 解决思路
What is the maximum number of concurrent TCP connections for a server? 65535?
Strange way of expressing integers (expanding Chinese remainder theorem)
Gauss elimination solves linear equations (floating-point Gauss elimination template)
[secretly kill little buddy pytorch20 days -day02- example of image data modeling process]