当前位置:网站首页>Pytorch dataloader implements minibatch (incomplete)
Pytorch dataloader implements minibatch (incomplete)
2022-07-03 05:48:00 【code bean】
Take the book back 《pytorch Build the simplest version of neural network 》 Not used last time miniBatch, Input all the data for training at one time .
This pass DataLoader Realization miniBatch
import torch
import numpy as np
from torch.utils.data import Dataset, DataLoader
class DiabetesDataset(Dataset):
def __init__(self, filepath):
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32)
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:, :-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
dataset = DiabetesDataset('diabetes.csv')
train_loader = DataLoader(dataset=dataset,
batch_size=749,
shuffle=False,
num_workers=1)
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
self.activate = torch.nn.ReLU()
# __call__() This function will be called in !
def forward(self, x):
# x = self.activate(self.linear1(x))
# x = self.activate(self.linear2(x))
# x = self.activate(self.linear3(x))
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
# model Is callable ! Realized __call__()
model = Model()
# Specify the loss function
# criterion = torch.nn.MSELoss(size_average=Flase) # True
# criterion = torch.nn.MSELoss(reduction='sum') # sum: Sum up mean: Averaging
criterion = torch.nn.BCELoss(reduction='mean') # Two class cross entropy loss function
# -- Specify optimizer ( In fact, it is the algorithm of gradient descent , be responsible for ), The optimizer and model Associated
# optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01) # This one is very accurate , Other things are not good at all
# optimizer = torch.optim.Rprop(model.parameters(), lr=0.01)
# for epoch in range(5000):
# y_pred = model(x_data) # Directly put the whole test data into
# loss = criterion(y_pred, y_data)
# print(epoch, loss.item())
# optimizer.zero_grad() # It will automatically find all the w and b Clear ! The role of the optimizer ( Why is this put in loss.backward() You can't clear it later ?)
# loss.backward()
# optimizer.step() # It will automatically find all the w and b updated , The role of the optimizer !
#
if __name__ == '__main__':
for epoch in range(1000):
for i, data in enumerate(train_loader, 0):
# 1. Prepare data
inputs, labels = data
# 2. Forward
y_pred = model(inputs)
loss = criterion(y_pred, labels)
print(epoch, i, loss.item())
# 3. Backward
optimizer.zero_grad()
loss.backward()
# 4. Update
optimizer.step()
# test
xy = np.loadtxt('diabetes_test.csv', delimiter=',', dtype=np.float32)
x_data = torch.from_numpy(xy[:, :-1])
y_data = torch.from_numpy(xy[:, -1])
x_test = torch.Tensor(x_data)
y_test = model(x_test) # forecast
print('y_pred = ', y_test.data)
# Compare the predicted results with the real results
for index, i in enumerate(y_test.data.numpy()):
if i[0] > 0.5:
print(1, int(y_data[index].item()))
else:
print(0, int(y_data[index].item()))
Intercept key code :
train_loader = DataLoader(dataset=dataset,
batch_size=749,
shuffle=False,
num_workers=1)batch_size The size of each batch of training , If the total number of data pieces is 7490 strip , So at this time train_loader Will produce 10 individual batch.shuffle It's a shuffle , It is to disorder the order of data and then put the data into 10 individual batch in .
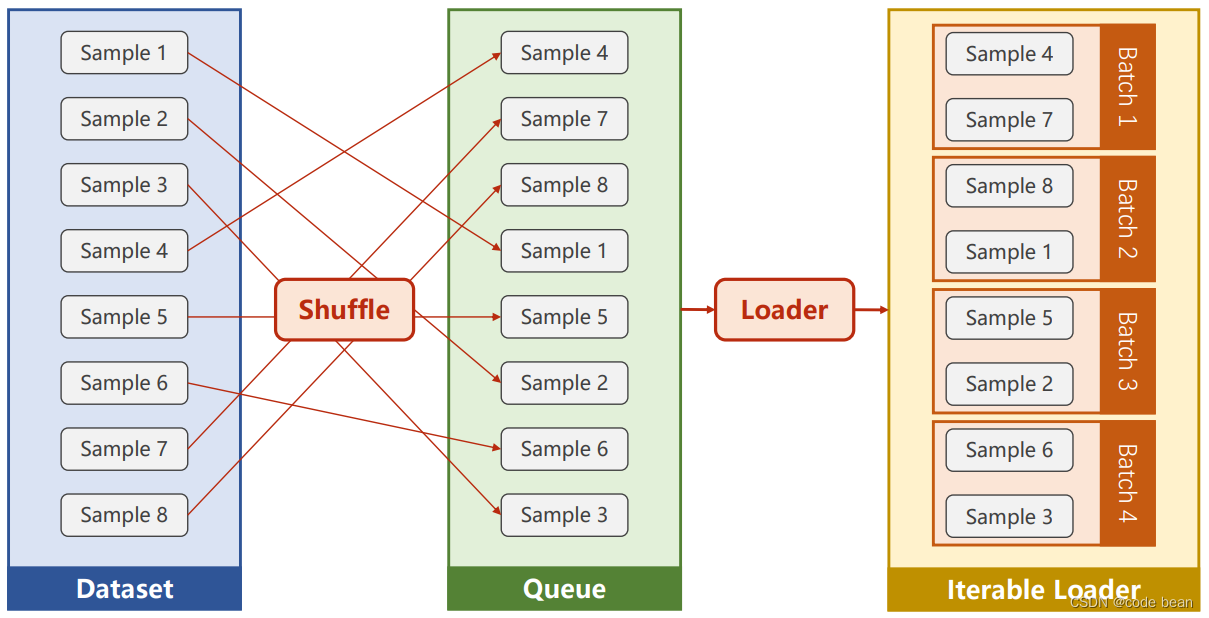
And now why do I , To put batch_size Set to 29, And set it not to shuffle . Because I want to compare with the previous process .
Because there are only 749 data , Then there will only be one batch, One batch Inside is all the data without disordering the order . This is the same as the previous training process .
I did this because I found , Used DataLoader After that, the training process became unusually slow , After changing to the above configuration , I thought the speed would be the same , But it's actually slow 10 More than !
What hurts more is , If batch_size Make it smaller ,loss There is no way to converge directly , If there are too many cyclic tests, an error is reported :
return _winapi.DuplicateHandle( PermissionError: [WinError 5] Access denied
this DataLoader How to use it ? Which God will give you some advice ?
边栏推荐
- 一起上水碩系列】Day 9
- 伯努利分布,二项分布和泊松分布以及最大似然之间的关系(未完成)
- 2022.7.2day594
- "C and pointer" - Chapter 13 advanced pointer int * (* (* (*f) () [6]) ()
- Altaro virtual machine replication failed: "unsupported file type vmgs"
- 32GB Jetson Orin SOM 不能刷机问题排查
- [teacher Zhao Yuqiang] MySQL high availability architecture: MHA
- Configure DTD of XML file
- Apache+php+mysql environment construction is super detailed!!!
- 2022.6.30DAY591
猜你喜欢

【一起上水硕系列】Day 7 内容+Day8

一起上水碩系列】Day 9

理解 期望(均值/估计值)和方差

Life is a process of continuous learning
![[teacher Zhao Yuqiang] redis's slow query log](/img/a7/2140744ebad9f1dc0a609254cc618e.jpg)
[teacher Zhao Yuqiang] redis's slow query log

@Import annotation: four ways to import configuration classes & source code analysis
mapbox尝鲜值之云图动画

Kubernetes resource object introduction and common commands (V) - (configmap)

Beaucoup de CTO ont été tués aujourd'hui parce qu'il n'a pas fait d'affaires
How to create and configure ZABBIX
随机推荐
Can altaro back up Microsoft teams?
CAD插件的安裝和自動加載dll、arx
PHP notes are super detailed!!!
Txt document download save as solution
为什么网站打开速度慢?
[Shangshui Shuo series together] day 10
Solve the problem of automatic disconnection of SecureCRT timeout connection
Communication - how to be a good listener?
Personal outlook | looking forward to the future from Xiaobai's self analysis and future planning
Today, many CTOs were killed because they didn't achieve business
Solve the 1251 client does not support authentication protocol error of Navicat for MySQL connection MySQL 8.0.11
Redis encountered noauth authentication required
Shanghai daoning, together with American /n software, will provide you with more powerful Internet enterprise communication and security component services
Ansible firewall firewalld setting
[function explanation (Part 2)] | [function declaration and definition + function recursion] key analysis + code diagram
pytorch 搭建神经网络最简版
Qt读写Excel--QXlsx插入图表5
Use telnet to check whether the port corresponding to the IP is open
Altaro virtual machine replication failed: "unsupported file type vmgs"
理解 YOLOV1 第一篇 预测阶段