当前位置:网站首页>[NLP] a detailed generative text Abstract classic paper pointer generator
[NLP] a detailed generative text Abstract classic paper pointer generator
2022-07-02 19:47:00 【Demeanor 78】
Write it at the front
Pointer-Generator Network And Microsoft's Unilm It's Xiaomiao 20 Studied in Automatic text summarization Two papers in the direction series , Up to now, I still think they are very worth reading . Today we share Pointer-Generator Networks.
In short ,Pointer-Generator Networks Of this paper idea And the motivation behind it is persuasive . It throws questions directly , Give solutions , And the solution motiviation And its own description will not confuse people , Strong acceptance .
It should be noted that ,Pointer-Generator Networks It is aimed at Long text summary (multi-sentences summaries、longer-text summarization), instead of Short text summary (headline、short-text summarization).
Key words of this article : Automatic text summarization 、 The text generated 、copy Mechanism 、attention
Title of thesis :《Get To The Point:Summarization with Pointer-Generator Networks》
Thesis link :https://arxiv.org/abs/1704.04368
Code address :https://www.github.com/abisee/pointer-generator
1. background
1.1 Why do you want to make a text summary
In a nutshell Information overload , Plus time is money . You may not want to read an article that you may not be interested in at the same time .
This is the time , We need it NLP Of Technology . You can use Abstract / key word / Entity recognition And other technologies to process the article to get some General information . Although the information is short , But it expresses the main idea of the article 、 The key information , It can give readers a general understanding of the article , Help readers Filtering information , Then choose the articles you are more interested in and learn the details .
1.2 The main technical route of the text summary
Automatic text summarization There are two main technical routes : Draw out and Generative .
(1) Extract text summary
Extract text summary It is usually to extract phrases from the original / word / Sentence formation summary , It can also be regarded as a binary classification problem or an importance ranking problem .
Its advantages are Precise generalization and correct grammar . however , The result of extraction is not consistent with that in most cases, people make a summary after reading / General pattern : Based on understanding , May use The words in the original text , May also use Neologism ( Words that do not appear in the original ) To express , That is, certain Word flexibility .
(2) Generative text summary
And Generative text summary Similar tasks include : Tag generation 、 Keyword generation etc. . Usually , Generative The model basis of the task is seq2seq/encoder+decoder, That is, a sequence to sequence generation model .attention After a , The basic generative model is seq2seq+attention.
Its advantage is that compared with the extraction type Use words more flexibly , Because the resulting words may never appear in the original . in general , It is consistent with the mode that we write summaries or summaries for the articles after reading : Based on the understanding of the original , And retell the story in a shorter sentence than the original .
2. problem
According to the first 1 Described in part , It seems that generative form is superior to extractive form . It's not , Because we haven't mentioned the shortcomings of generative . That section , Let's take a look at the weakness of the generative formula ?
2.1 The basic principle of generative formula
The basic modeling idea of generating class model is Language model :
This is a Sequence generation The process : Every time step( Time step ) All in one fixed vocabulary( Preset fixed vocabulary ) Choose a word . actually , Each time step is doing multi classification , We calculate the probability of each word in the fixed vocabulary under the current conditions , To choose the words that should appear under the current time step .
2.2 The problem of generative model
in general , Extraction technology, after all, uses the content of the original , So usually It has an advantage in the correctness of grammar and the accuracy of summarizing the original ; The flexibility of generative model leads to the common problems of generative model : Easy to repeat ; It is uncontrollable to restore facts : Maybe the meaning of idioms is incomplete / Discontinuous sentences , Or it is far from the original meaning ;OOV problem .
(1) OOV
Since it is fixed vocabulary, Then there must be words out of the fixed vocabulary. let me put it another way , The generation model exists OOV problem : Can't generate OOV The word , Only words in the fixed vocabulary can be generated .
(2) Repeatability
Another point is Repeatability , The model may be in some time step The previous generation time step Words that have been generated .
(3) Semantic incoherence 、 Low grammatical logic 、 Restatement accuracy is not high
Go every step fixed vocabulary Selected words , The final summary , There will be semantic incoherence in the generated summary 、 Semantics are not smooth . Compared with the extraction , The more serious problem is that the accuracy of the restatement of the original text is not high .
3. The core idea
So how to solve these problems of generative model , To improve the quality of the generated summary ?
Actually , We can see that these shortcomings of generative formula are compared with that of extractive formula . Then fusion extraction mode , Is it possible to retain the flexibility of generative , And the quality of the generated summary is closer to the extracted quality benchmark ?
The answer is yes . Then how to do it ?
3.1 hybird pointer-generator network
Incorrect semantics for restatement / Precise questions , It's also aimed at OOV problem , Designed a fusion model pointer-generator.
The basis of the model is still seq2seq+attention, This part serves as generator; Besides , Introduced pointer. therefore , It can be based on pointer Choose words from the original , Can also be based on generator Generative word .
Notice the generator In essence, the choice of words , But it is based on a fixed thesaurus through softmax To choose . The thesaurus itself is statistically constructed from the training data when training the model .
3.2 coverage-mechinism
For repetitive problems , Designed coverage-mechinism. Its essence is to track and record in the current step Words that have been selected before , This can be in the follow-up step Weaken the attention to this part when generating words , So as to reduce the repetition problem .
4. Model details
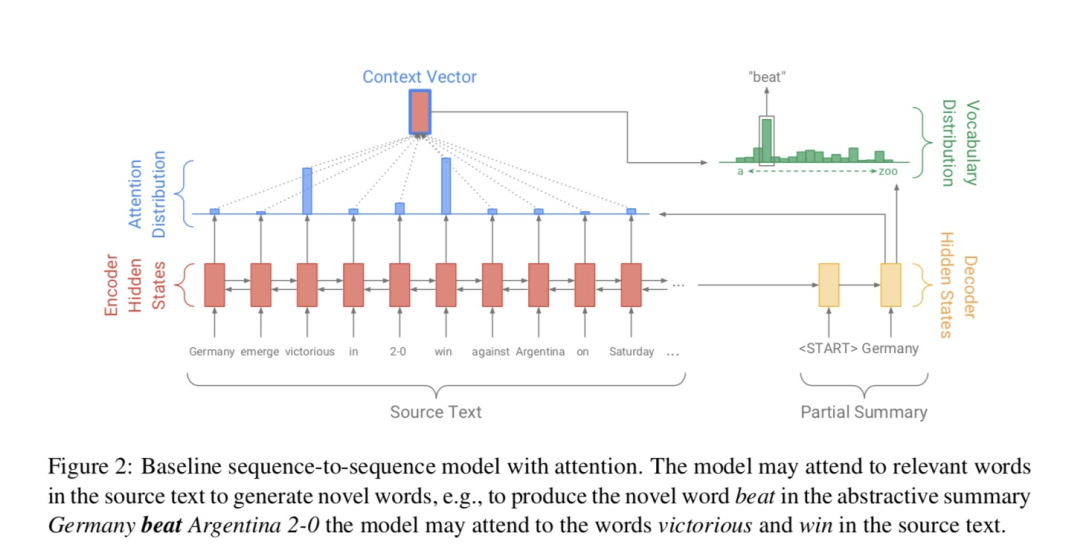
4.1 baseline model:seq2seq+attention
This part mainly shares his thoughts , There is no need to repeat the relevant formula .
Encoder (encoder): Bidirectional sequence model , Such as two-way lstm/rnn.
decoder (decoder): Because the decoding process is a Markov process , Make sure you don't see future information , Therefore, the decoder is generally a unidirectional sequence model , Such as One way lstm/rnn.
Attention mechanism (attention): Based on the current decoding step decoder state And encoder all the time hidden state Calculation attention score, That is, all the time of the encoder hidden state The degree of concern . Then based on attention score Weighted encoder end hidden state Form the current decoding step context vector. The decoding step is based on this context vector And the current decode state To generate words .
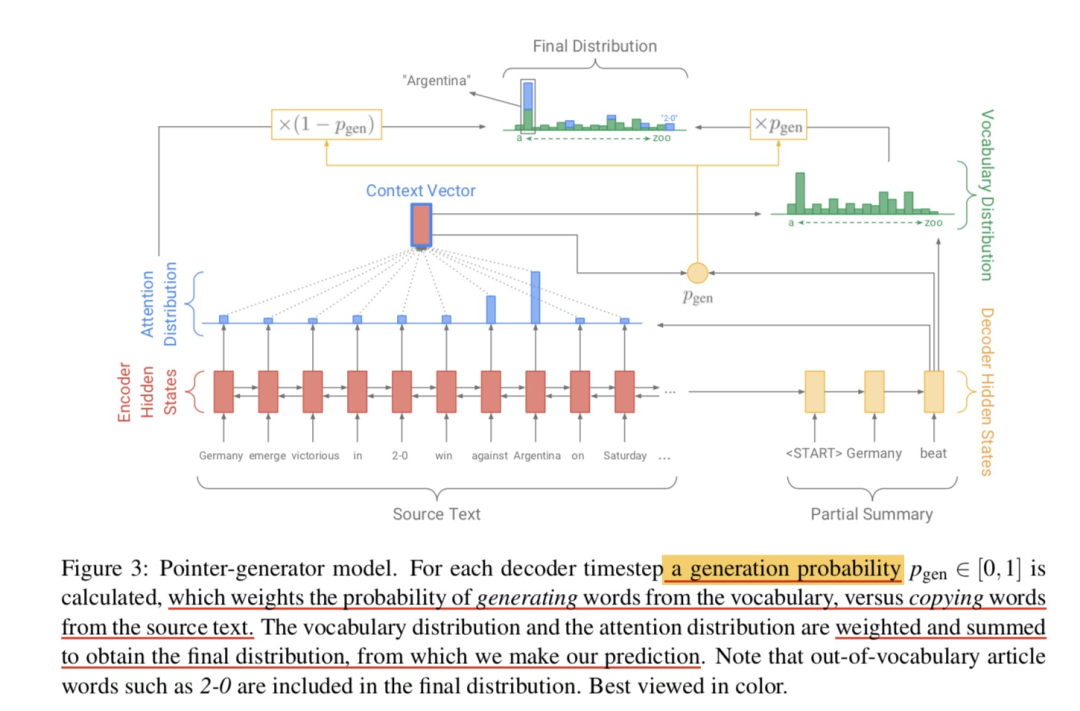
4.2 pointer-generator network
(1) Ideas
Extract the content of the original , Add one more pointer Can , Its function is to tell us the current time step Which word should be chosen from the original .
On the other hand , We cannot lose the flexibility of generation . Then the problem can be like this
Turn it into this :
among , Is a generative model , It's an extraction model . That is to say, each time step We use generation to obtain a certain probability of words , We use extraction to obtain a certain probability .
Further, it can be more soft, It's not either or , It is Weighted voting of both . How to do it? ?
(2) solution
When deciding which word to generate , Take the weighted sum of the two :
402 Payment Required
among :
Generative model , That is... In the formula , The way of calculation and baseline model Agreement ;
Extraction model , utilize pointer To achieve , That is, in the formula , Here is simply calculated by using the generation model attention Sum up , Indicates the sum of attention to the word at all locations .
The use of contex vector and decode state、decode input To calculate , Represents the weight of the generative ; Represents the weight of the extraction .
This is the equivalent of Expand Thesaurus 了 , Use the words in the article to be abstracted to put fixed vocabulary become extened vocabulary, The model has the ability to generate OOV The word .
about OOV For words , its , So it's using pointer Get from the original ; And for Words that do not appear in the original Come on , We naturally have it , So it depends on generator Get from the fixed vocabulary . For words that appear both in the original text and in the thesaurus , Of course, the two parts work together .
4.3 coverage-mechinism
(1) Ideas
Said so much , There is another problem to be solved , Namely repetition( Repeatability problem ).
How to solve it . The simple and intuitive way is Track the words that have been used before , In this way, repetition can be avoided or slowed down to a certain extent .
(2) solution
How do you do that , Is to use a coverage vector, Calculate the total attention received by each word before the current time step . What about here? , It mainly accumulates each time step attention score:
This can be understood as :pointer The part of is not to use attention score To choose words ( choose attention score Big words ), So I remember this , And then add one Penalty for loss To punish the repetition of words :
Obviously only attention and coverage vector There are great differences in every position , This loss can be minimized ( There is an upper bound loss ). So this loss can be avoided attention Duplication : That is, the current time step is ignored as much as possible, and the words that are highly concerned before the current time step ( Words that are most likely to have been chosen ).
Besides , about generator part , What we can do is improve attention The calculation of :
Each step , Put the previous one coverage vector Take into account , Let it work : Expect to generate different attention score, So as to produce different context vector, Then it's different when decoding and generating words .
Finally, the loss of each step is the sum of two parts , Part is extraction , The other part is the negative log likelihood of the generating formula :
402 Payment Required
And the total loss is :
summary
Okay , About generative Abstract paper pointer-generator Networks That's it . If this article helps you , Welcome to thumb up & Looking at & Share , This is for me to continue to share & It's very important to create quality articles . thank !

Past highlights
It is suitable for beginners to download the route and materials of artificial intelligence ( Image & Text + video ) Introduction to machine learning series download Chinese University Courses 《 machine learning 》( Huang haiguang keynote speaker ) Print materials such as machine learning and in-depth learning notes 《 Statistical learning method 》 Code reproduction album machine learning communication qq Group 955171419, Please scan the code to join wechat group
边栏推荐
- Understanding and function of polymorphism
- What are the benefits of multi terminal applet development? Covering Baidu applet, Tiktok applet, wechat applet development, and seizing the multi platform traffic dividend
- AcWing 1135. 新年好 题解(最短路+搜索)
- AcWing 383. Sightseeing problem solution (shortest circuit)
- zabbix5客户端安装和配置
- AcWing 383. 观光 题解(最短路)
- 《架构整洁之道》读书笔记(下)
- AcWing 1126. 最小花费 题解(最短路—dijkstra)
- AcWing 1125. 牛的旅行 题解(最短路、直径)
- Py之interpret:interpret的简介、安装、案例应用之详细攻略
猜你喜欢

MySQL function
浏览器缓存机制概述
Notes on hardware design of kt148a voice chip IC

KT148A语音芯片ic的用户端自己更换语音的方法,上位机
Windows2008r2 installing php7.4.30 requires localsystem to start the application pool, otherwise 500 error fastcgi process exits unexpectedly
Génération automatique de fichiers d'annotation d'images vgg

AcWing 340. 通信线路 题解(二分+双端队列BFS求最短路)
搭建哨兵模式reids、redis从节点脱离哨兵集群

Py's interpret: a detailed introduction to interpret, installation, and case application

Refactoring: improving the design of existing code (Part 1)
随机推荐
Génération automatique de fichiers d'annotation d'images vgg
Function high order curry realization
Gmapping code analysis [easy to understand]
Refactoring: improving the design of existing code (Part 2)
Implementation of online shopping mall system based on SSM
AcWing 1126. 最小花费 题解(最短路—dijkstra)
MySQL表历史数据清理总结
《架构整洁之道》读书笔记(下)
AcWing 903. 昂贵的聘礼 题解(最短路—建图、dijkstra)
PXE installation "recommended collection"
AcWing 1137. 选择最佳线路 题解(最短路)
MySQL
函数高阶-柯里化实现
KT148A语音芯片ic的软件参考代码C语言,一线串口
Py's interpret: a detailed introduction to interpret, installation, and case application
Build a master-slave mode cluster redis
AcWing 1127. Sweet butter solution (shortest path SPFA)
Kt148a voice chip IC user end self replacement voice method, upper computer
Embedded (PLD) series, epf10k50rc240-3n programmable logic device
KT148A语音芯片ic的用户端自己更换语音的方法,上位机