当前位置:网站首页>【CV-Learning】语义分割
【CV-Learning】语义分割
2022-08-04 05:29:00 【小梁要努力哟】
语义分割
定义:给图像的每个像素分配类别标签,不区别实例,只考虑像素类别。

旧思路(滑动窗口)
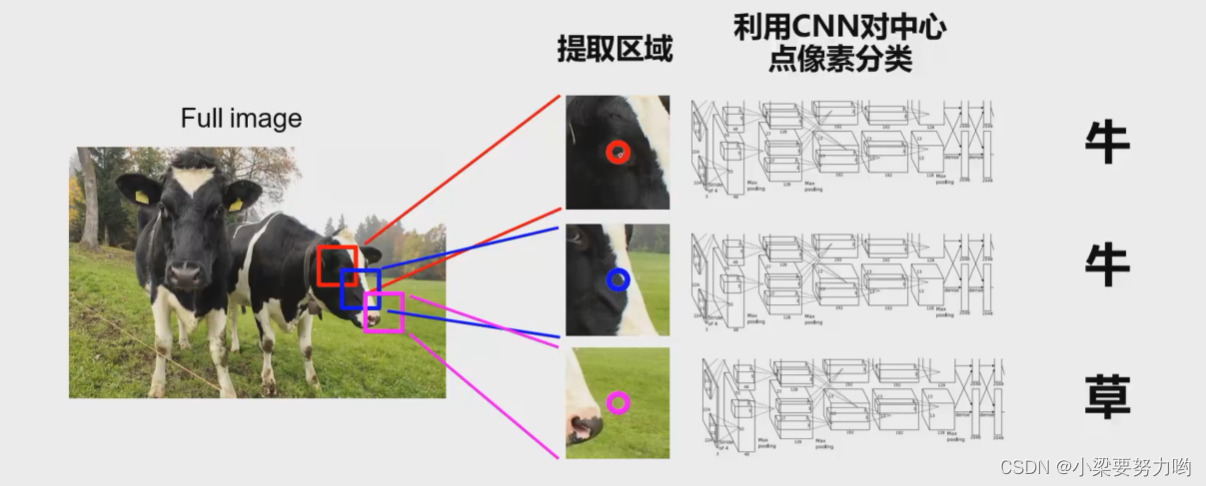
思路:以某一个像素点为中心,选取一个区域,对该区域进行分类。
问题:效率太低,重叠的区域特征反复被计算。
新思路(全卷积)
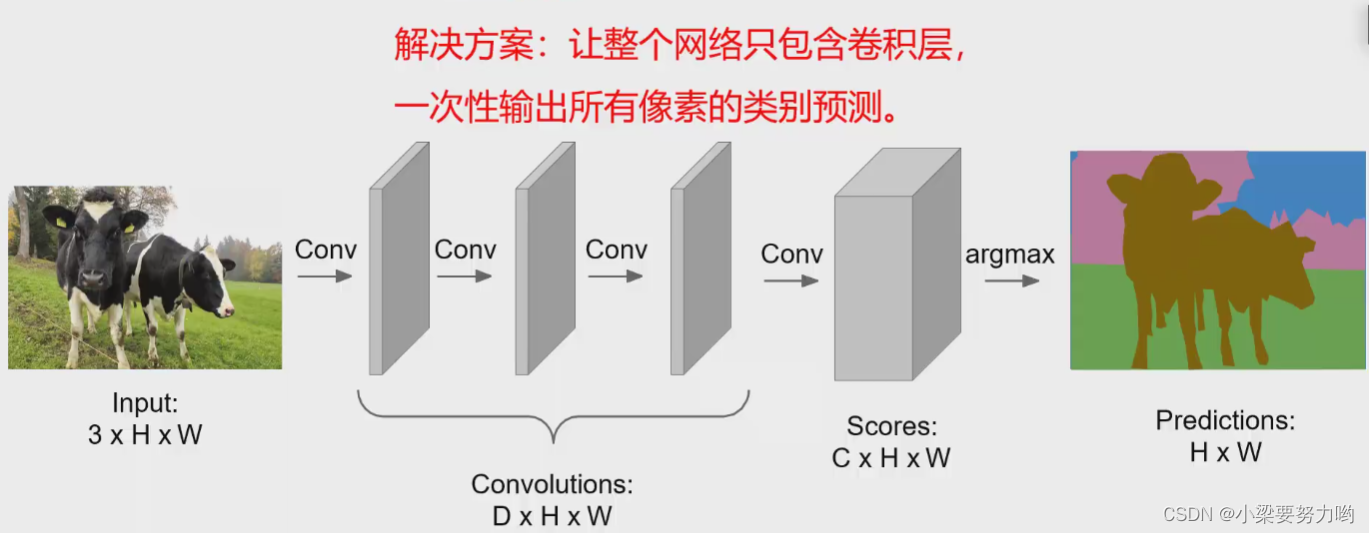
思路:在Convolutions时进行pooling,使得图像尺寸及深度不变,之后得到深度为C的Scores,其中每个深度代表一个类别,可以对每个像素进行类别判断。最终通过判断每个像素的交叉熵损失之和,进行反馈对总损失进行控制,使其越低越好。
问题:Convolutions处理过程中保持图像的原始分辨率,对显存的需求十分庞大。于是可以对Convolutions过程进行优化处理,得到性能的提升。
性能提升
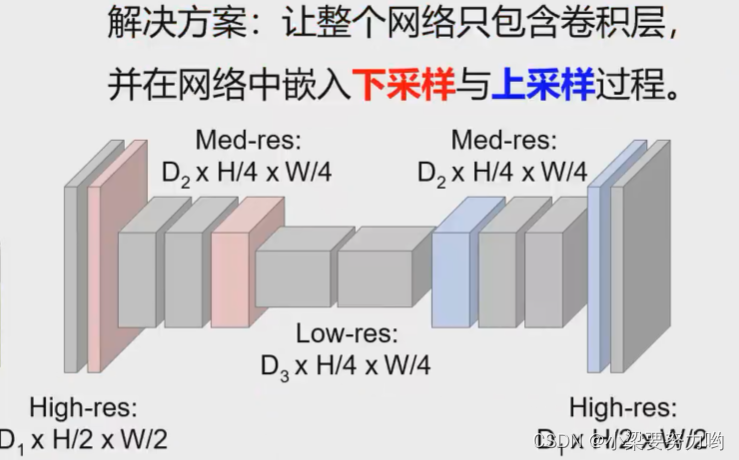
思路:在Convolutions过程中,先进行下采样,提取到高级的语义特征,之后再通过上采样将原本的学习回来,建立高级语义到类标的映射。
下采样
pooling、strided convolution
上采样t
unpooling or strided transpose convolution
硬编码上采样
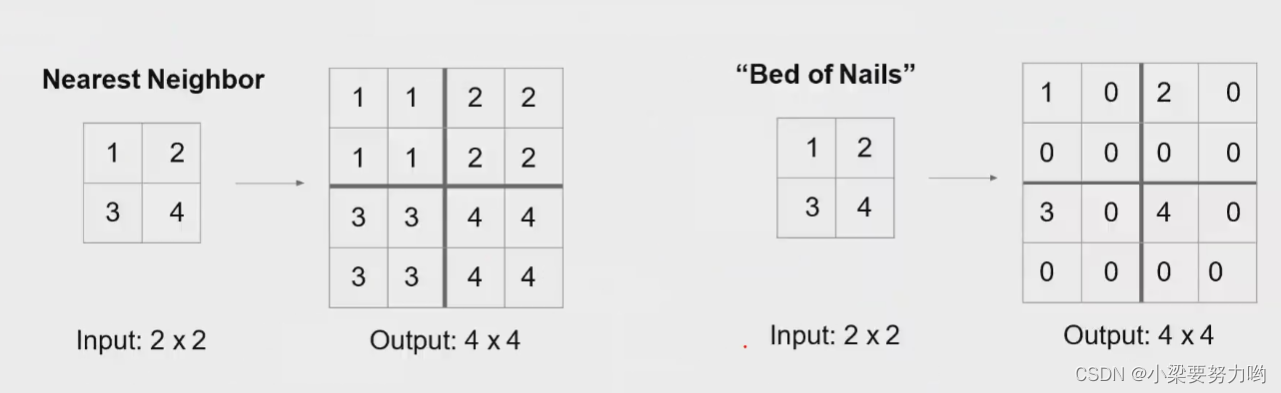
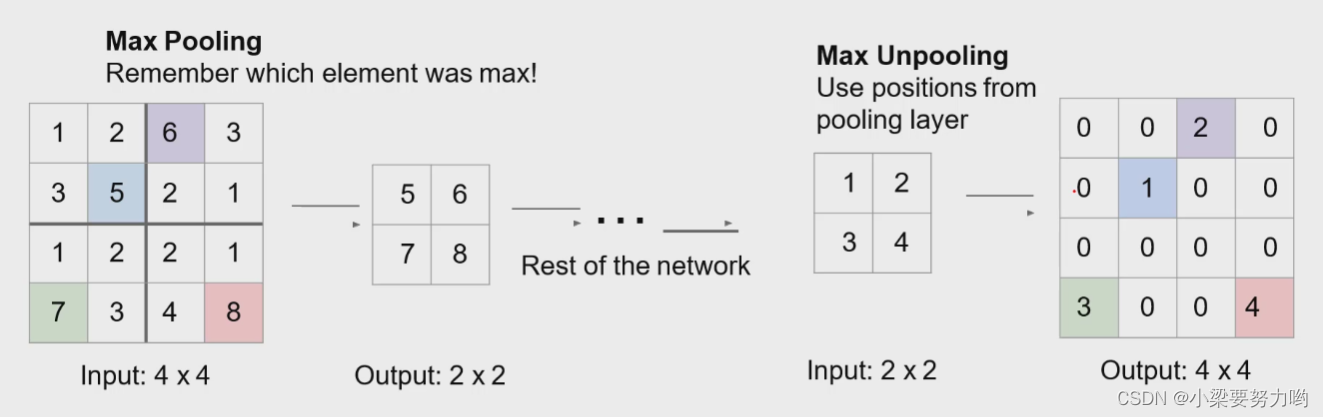
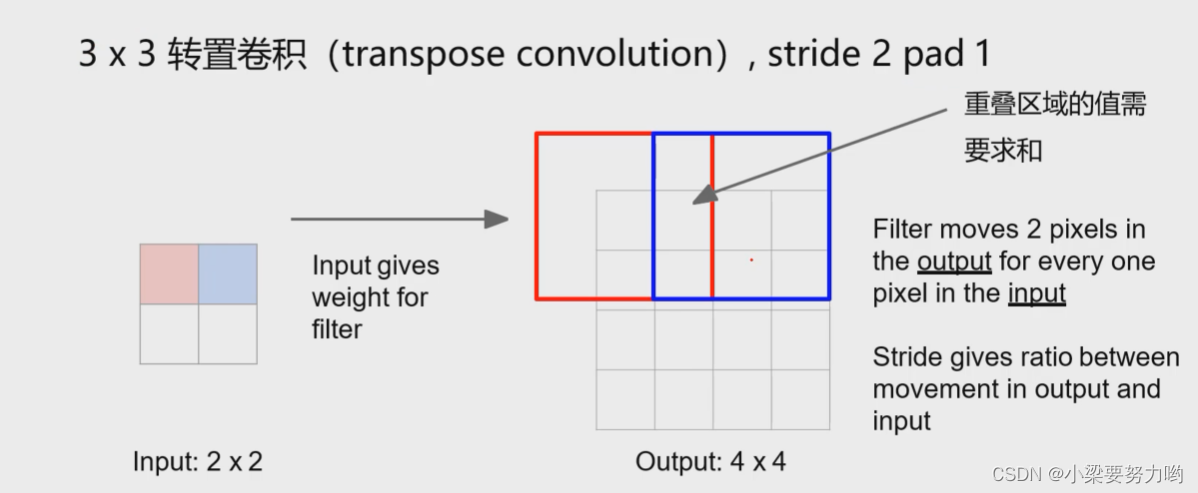
可学习的上采样(转置卷积Transpose convolution)
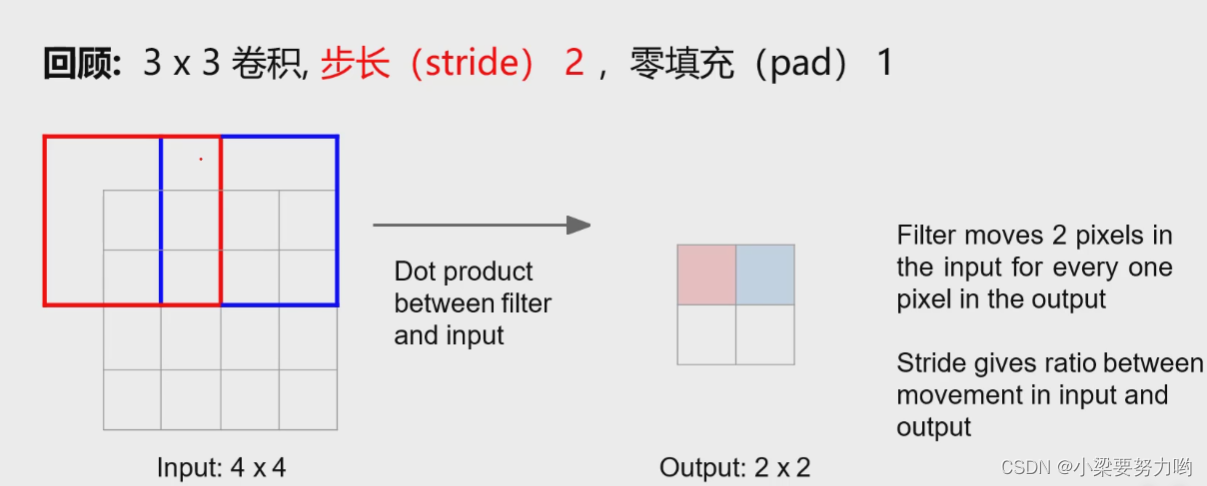
下采样
上采样
一维上采样例子
Filter为滤波器核,是一个可以学习的矩阵。
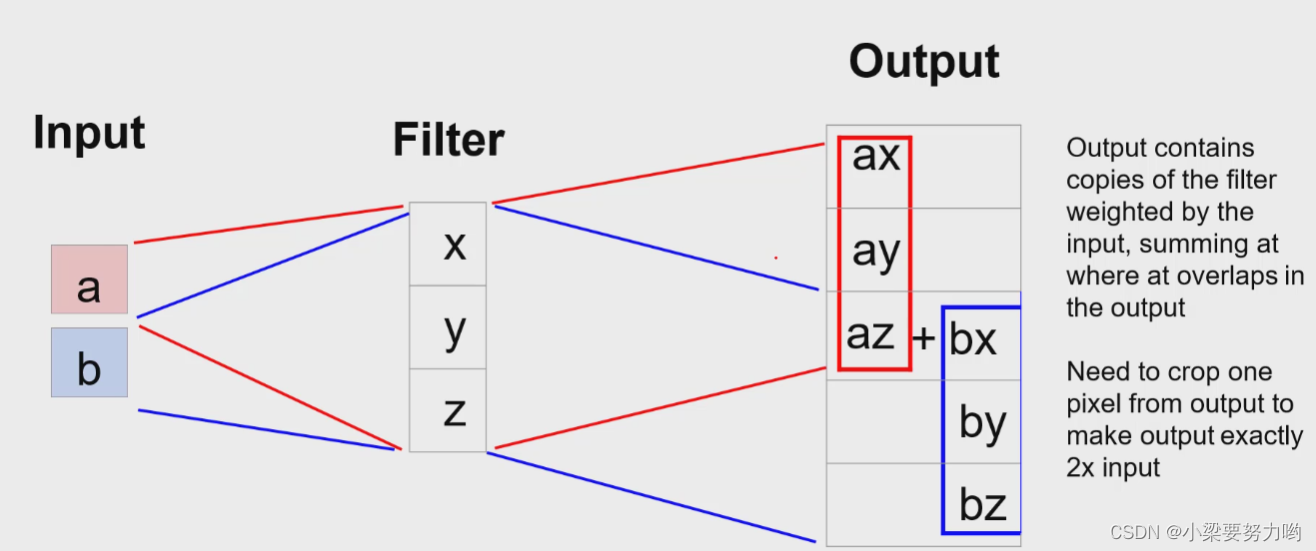
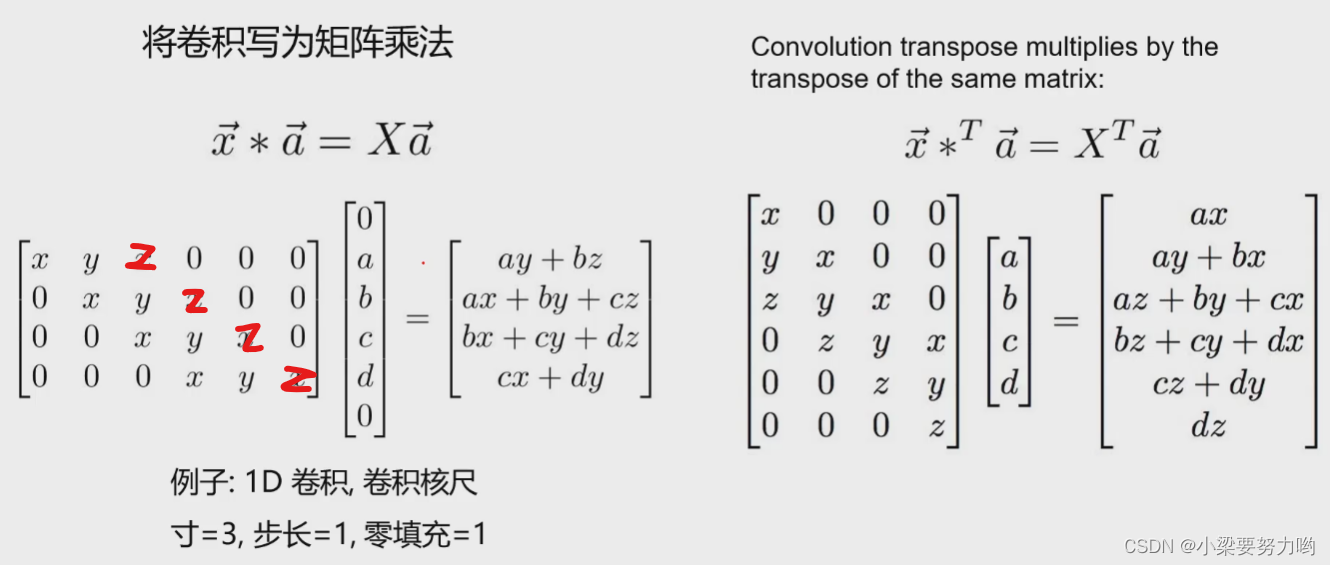
卷积与矩阵相乘(一维)
以下图例均为先进行下采样,然后进行上采样复原。
例1:步长为1
例2:步长为2

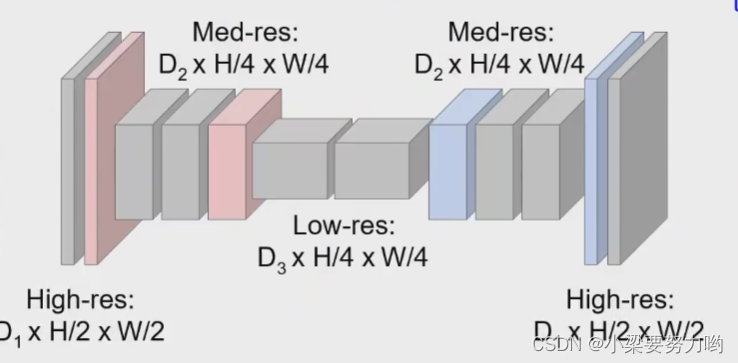
UNET
上采样是根据下采样得到的高级语义得到的,但是有时候高级语义效果并不好,还需要使用低级语义。
针对这个问题,提出了UNET,将下采样过程中的低级语义整合到上采样过程中,从而使得效果更好。
整合思路:
1.将左边红色的特征通道进行拷贝,与上采样后的特征通道拼起来。
2.将左边红色的特征通道通过卷积处理后,与上采样后的特征通道拼起来。
边栏推荐
猜你喜欢


随机推荐
编程Go:学习目录
SQL练习 2022/7/1
Kubernetes基础入门(完整版)
关系型数据库-MySQL:体系结构
Kubernetes集群安装
自己学习爬虫写的基础小函数
Zend FrameWork RCE1
关系型数据库-MySQL:多实例配置
sklearn中的pipeline机制
SQL的性能分析、优化
字典特征提取,文本特征提取。
完美解决keyby造成的数据倾斜导致吞吐量降低的问题
(十一)树--堆排序
iptables防火墙
关系型数据库-MySQL:二进制日志(binlog)
【go语言入门笔记】12、指针
逻辑回归---简介、API简介、案例:癌症分类预测、分类评估法以及ROC曲线和AUC指标
ISCC2021——web部分
MySQL事务详解(事务隔离级别、实现、MVCC、幻读问题)
PHP课堂笔记(一)