当前位置:网站首页>MLPerf Training v2.0 榜单发布,在同等GPU配置下百度飞桨性能世界第一
MLPerf Training v2.0 榜单发布,在同等GPU配置下百度飞桨性能世界第一
2022-07-05 07:45:00 【飞桨PaddlePaddle】
本文已在飞桨公众号发布,查看请戳链接:
MLPerf Training v2.0 榜单发布,在同等GPU配置下百度飞桨性能世界第一
在6月30日最新发布的MLPerf Training v2.0榜单里,百度使用飞桨框架(PaddlePaddle)和百度智能云百舸计算平台提交的BERT Large模型GPU训练性能结果,在同等GPU配置下的所有提交结果里排名第一,超越了高度定制优化且长期处于榜单领先位置的NGC PyTorch框架,向全世界展现了飞桨框架的性能优势。
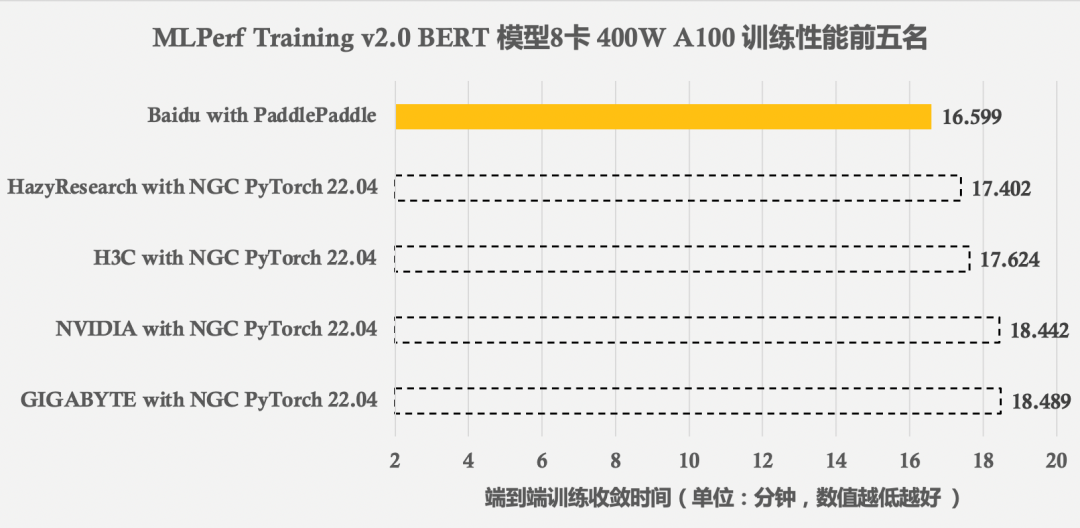
图1 MLPerf Training v2.0 BERT模型效能前五名训练成果
图1展示了MLPerf Training v2.0 BERT模型在8卡NVIDIA GPU A100(400W功耗,80G显存)下前五名的训练性能结果,百度飞桨方案比其他提交结果快 5%-11%不等。
“世界第一” 背后的黑科技
飞桨在BERT模型8卡GPU训练上创造了世界最优的训练性能,这来自于飞桨框架基础性能与分布式技术的领先性,以及飞桨与NVIDIA GPU的深度协同优化。
对于深度学习模型训练任务,从数据读取到模型计算,从底层算子到上层分布式策略,从多设备负载均衡到全流程调度机制,都会影响最终训练性能。飞桨基于领先的架构设计和长期的实践打磨,在高性能训练方面做出了系统性的优化工作,主要体现在如下几个方面:
数据读取和模型训练的负载均衡
针对分布式训练经常出现的负载不均衡问题,将模型训练和数据读取、预处理分配到不同设备上进行,确保异构算力物尽其用,实现数据IO和计算的平衡。
变长序列输入模型的计算加速
针对变长序列输入模型大多采用的padding填充对齐方式带来的冗余计算问题,提供对变长输入和对应模型结构的高效支持,让GPU算力资源专注于有效计算,尤其是对Transformer类模型计算效率提升明显。
高性能算子库和融合优化技术
针对框架基础性能优化的极致需求,研发了高性能算子库PHI,充分优化GPU内核实现,提升算子内部计算的并行度,并通过算子融合降低仿存开销,发挥GPU的极限性能。
高加速比的混合并行训练策略
针对传统数据并行性能、显存瓶颈受限的问题,实现了融合数据并行、模型并行、分组参数切片并行等策略的混合并行分布式训练策略,部分场景下可实现超线性加速的分布式训练性能。
全流程异步调度
针对模型训练过程各环节存在的同步频率高、时间重叠度低等问题,设计异步调度机制,保证模型收敛的同时去除大部分同步操作,实现数据处理、训练和集合通信等各环节近乎全异步调度,提升端到端极致性能。
助力大模型 技术创新和产业落地
百度一直重视大模型的技术研发,并致力于推动大模型的产业落地。大模型训练需要深度学习框架在高性能分布式训练方面提供强有力支撑。
飞桨分布式训练从产业实践出发,不断强化领先优势,相继发布了业界首个通用异构参数服务器架构、4D混合并行训练策略、端到端自适应分布式训练架构等多项亮点技术,并根据不同的模型结构和稀疏稠密等特性充分打磨,可支撑包括计算机视觉、自然语言处理、个性化推荐、科学计算在内的广泛领域的不同算法在异构硬件上实现高性能训练,有效助力大模型技术创新探索的快速迭代。
飞桨领先的分布式技术和高性能训练特色,支持了基于飞桨的软硬件方案在MLPerf上持续获得优异表现,支撑了多个业界领先的文心大模型发布,如全球首个知识增强千亿大模型“鹏城-百度·文心”,知识增强的电力行业NLP大模型“国网-百度·文心”,知识增强的金融行业NLP大模型“浦发-百度·文心”,以及国产硬件集群上AlphaFold2千万级别蛋白质结构分析模型。
结语
飞桨在MLPerf Training v2.0榜单中获得了BERT模型训练性能世界第一的瞩目成绩。这不仅得益于飞桨框架在性能优化领域的长期耕耘,更离不开硬件生态的助力。近年来,飞桨的技术实力深受广大硬件厂商认可,合作日趋紧密,软硬一体协同发展,生态共创硕果累累。前不久(5月26日),NVIDIA与飞桨合作推出的NGC-Paddle正式上线。同时在本次MLPerf榜单中,Graphcore也通过使用飞桨框架取得了优异成绩。未来,飞桨将继续打造性能优势,在软硬协同性能优化和大规模分布式训练方面持续技术创新,为广大用户提供更加便捷、易用、性能优异的深度学习框架。
MLPerf介绍
MLPerf是由AI领域世界知名的学术研究者和产业专家发起的人工智能领域基准测试标杆。MLPerf旨在提供一个公平、实用的基准测试平台,展示业界领先的AI软硬件系统的最佳性能,其测试结果已获得AI领域的普遍认可。世界上几乎所有主流的硬件生产商和软件服务提供商都会参考MLPerf发布的结果构建自己的基准测试系统,以测试其开发的新的AI加速芯片和深度学习框架在MLPerf模型上的性能表现。
直播预告
7月6日(星期三)20:00,飞桨总架构师于佃海和飞桨资深研发工程师曾锦乐将通过直播,为大家揭秘同等GPU配置下,百度飞桨性能「世界第一」背后的关键技术。
关注飞桨公众号,后台回复【学习】进行报名,直播间还有更多好礼等你来拿!
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~
本文同步分享在 博客“飞桨PaddlePaddle”(CSDN)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
边栏推荐
- 行测--资料分析--fb--高照老师
- 数字孪生实际应用案例-风机篇
- Global and Chinese markets for waste treatment air switches 2022-2028: Research Report on technology, participants, trends, market size and share
- 通过sql语句统计特定字段出现次数并排序
- Leetcode solution - number of islands
- Cookie operation
- Threads and processes
- Basic series of SHEL script (II) syntax + operation + judgment
- Apple system shortcut key usage
- Day08 ternary operator extension operator character connector symbol priority
猜你喜欢
Openxlsx field reading problem

Build your own random wallpaper API for free

Embedded AI intelligent technology liquid particle counter
How to deal with excessive memory occupation of idea and Google browser

I 用c l 栈与队列的相互实现
Line test -- data analysis -- FB -- teacher Gao Zhao
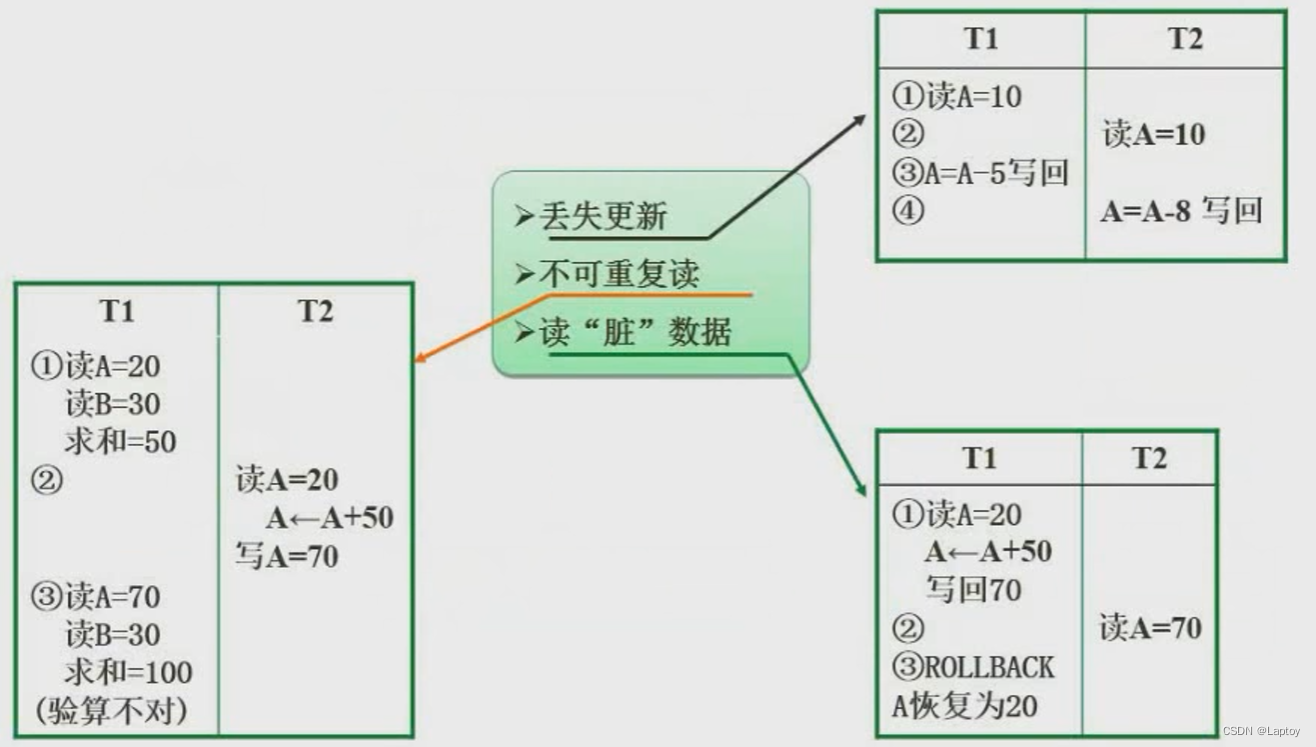
软件设计师:03-数据库系统
CADD course learning (5) -- Construction of chemosynthesis structure with known target (ChemDraw)

Daily Practice:Codeforces Round #794 (Div. 2)(A~D)
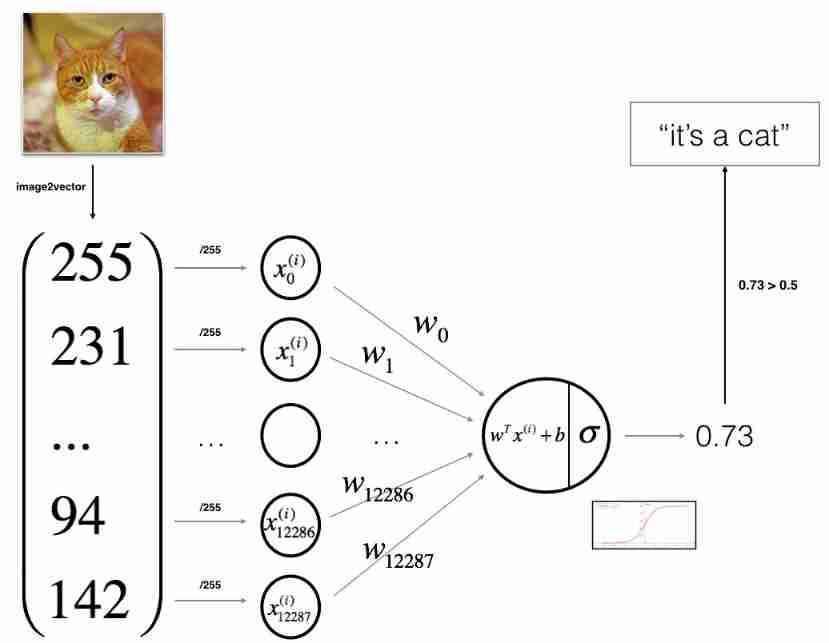
Logistic regression: the most basic neural network
随机推荐
Good websites need to be read carefully
MySQL - storage engine
Oracle-触发器和程序包
Cygwin installation
万字详解八大排序 必读(代码+动图演示)
Global and Chinese markets of nano biosensors 2022-2028: Research Report on technology, participants, trends, market size and share
STM32 knowledge points
editplus
行测--资料分析--fb--高照老师
Efficiency difference: the add method used by the set directly and the add method used by the set after judgment
Practical application cases of digital Twins - fans
MySql——存储引擎
Use go language to read TXT file and write it into Excel
Basic knowledge of public security -- FB
[idea] common shortcut keys
Idea to view the source code of jar package and some shortcut keys (necessary for reading the source code)
The number of occurrences of numbers in the offer 56 array (XOR)
Oracle triggers and packages
Function of static
String alignment method, self use, synthesis, newrlcjust