当前位置:网站首页>Oracle makes it clear at one time that a field with multiple separators will be split into multiple rows, and then multiple rows and columns. Multiple separators will be split into multiple rows, and
Oracle makes it clear at one time that a field with multiple separators will be split into multiple rows, and then multiple rows and columns. Multiple separators will be split into multiple rows, and
2022-07-07 08:47:00 【They call me technical director】
Catalog
One 、 A field with multiple separators splits multiple lines
3、 The writing of various separators
Two 、 Multiple rows, multiple columns, multiple separators, split multiple rows
3、 ... and 、 Handle more than 100 million ... Billion level data
3、 Statistics after converting multiple rows into single row split results
Preface :
During the big data demand analysis this time , Received a “ Simple ” The needs of , Count the workload of multiple inspectors . That is, when the finished product is tested , We need to analyze 80-90 Three test indicators to determine whether it is qualified , Only after it is qualified can it be released from the factory . Of course, these testing items should be completed , Requires multi person collaboration . For example, complete the detection of main content , Four people are needed , Completing the detection of impurities requires a lot of ghosts and monsters 6 people 、 The completion of particle size testing requires ethylene propylene glycol 5 people .... And so on. . Suppose there are altogether a, B, C, D, demons 8 people , Because of 80-90 Test items , They all involve the corresponding test items , But whose workload is saturated , There is no way to know who is unsaturated , Therefore, the information of test items and corresponding test personnel is saved in the table through form statistics , Just analyze , How many times does each person test each test item every day , You can analyze the corresponding workload saturation . Ha ha ha , Is this demand super easy~, However, the nightmare has just begun ...

One 、 A field with multiple separators splits multiple lines
First let's look at , How to split a row of data into multiple rows , Here we use REGEXP_SUBSTR This function of , adopt REGEXP_SUBSTR And corresponding regular expressions to accomplish our purpose of splitting .
In order to make everyone understand the code quickly , In the corresponding code [^] It means that it doesn't start with , That is, when we split , Only columns such as “1,2,3” The data of , Instead of splitting “,1,2,3” The data of , Among them “+” Represents multiple matches ,“|” Is or means , That is, when we have multiple separators, we can use , For example, split “1,2\3,4,5\6” Data is needed . The specific usage can be understood if you are interested oracle The contents of regular expressions .
1、 The first way to split
Code :
-- The first way to write it
SELECT
REGEXP_SUBSTR ('1,2,3',
'[^,]+',
1,
rownum)
FROM dual
CONNECT BY
rownum <= LENGTH ('1,2,3') - LENGTH (regexp_replace('1,2,3', ',', ''))+ 1;
effect :
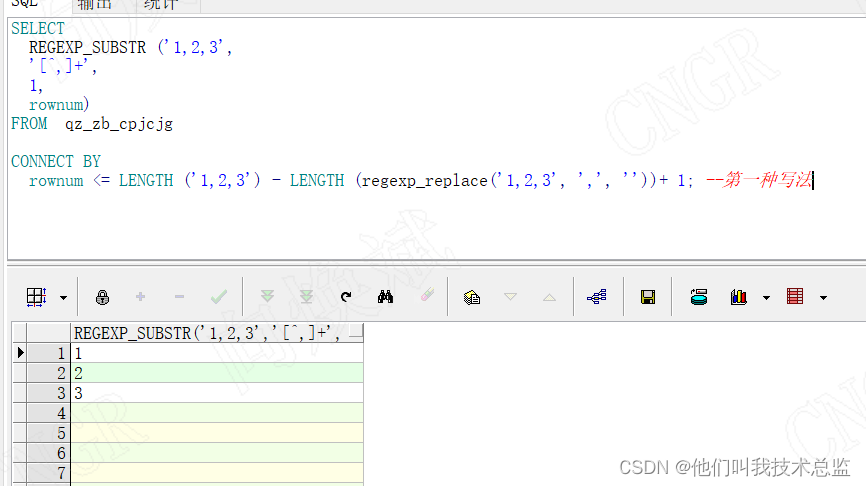
analysis :
As shown in the figure above, we succeeded , take ‘1,2,3’ Split into 1 2 3 Of 3 That's ok , But careful partners in this way will find that there are many empty lines . Therefore, it is strongly not recommended !!!
2、 The second way
Code :
-- The second way
SELECT
REGEXP_SUBSTR ('1,2,3','[^,]+',1,
rownum)
FROM dual
CONNECT BY REGEXP_SUBSTR ('1,2,3','[^,]+',1,LEVEL) is not null effect :
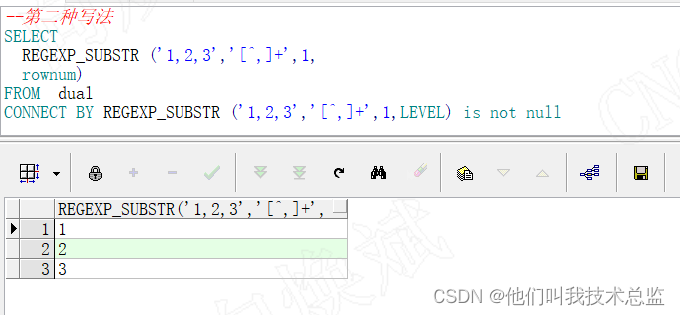
analysis :
This kind of writing code is simple , The result is consistent with our expectation , Only what we need ,1,2,3 Of 3 Row data . Therefore, this writing method is recommended .
3、 The writing of various separators
Code :
-- The second way
SELECT
REGEXP_SUBSTR ('1,2\3,4,5\6','[^,|\]+',1,
rownum)
FROM dual
CONNECT BY REGEXP_SUBSTR ('1,2\3,4,5\6','[^,|\]+',1,LEVEL) is not nulleffect :
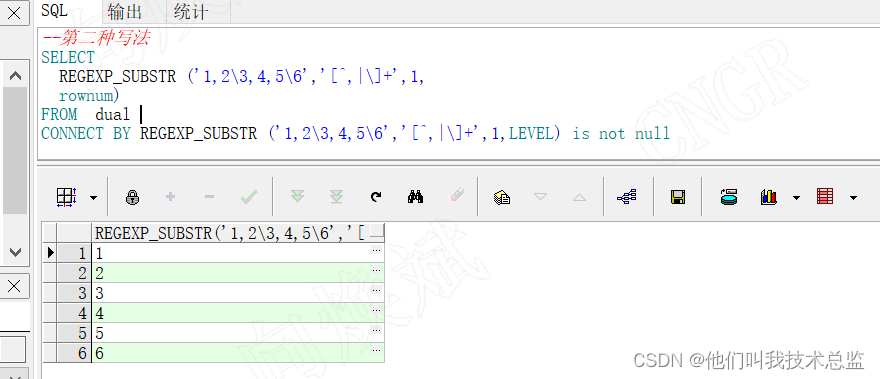
analysis :
As shown in the figure , We just need to add [^,] Change to [^,|\] that will do , That is, through “|” Separator list the separators in turn . Is it brain melon seeds buzzing , Ha ha ha , Don't worry. , More buzzing in the back .

Two 、 Multiple rows, multiple columns, multiple separators, split multiple rows
Ha ha ha , After learning above , Believe that ordinary splitting has been difficult for you , So it's estimated that you already feel like you can go to heaven , At this time, the business department tells you that this situation is unknown , There are multiple columns , And there are many separators , At this time, you will find that your small head is not enough seeds . What do I do ? Don't worry , Let's take a look at the scene first .
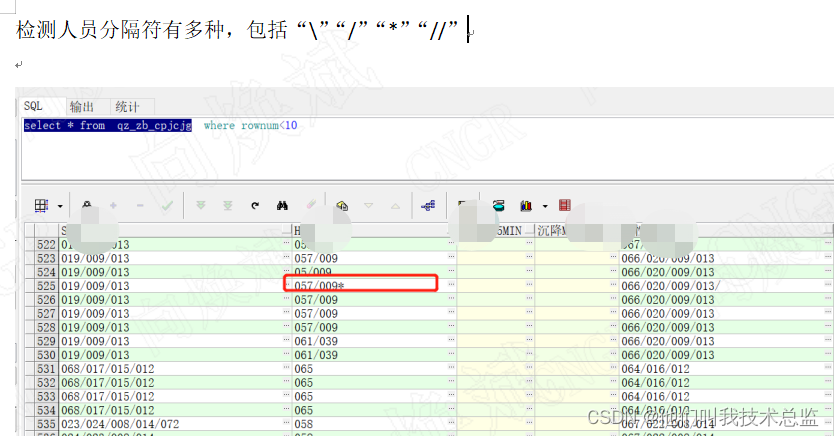
1、 Single row multi column multi separator split
Code :
-- Split multiple columns
SELECT
REGEXP_SUBSTR ('1,2\3,4,5\6','[^,|\]+',1,LEVEL) a,
REGEXP_SUBSTR ('7,8\3,5,9,0,6,4','[^,|\]+',1,LEVEL) a1
FROM dual
CONNECT BY REGEXP_SUBSTR ('1,2\3,4,5\6','[^,|\]+',1,LEVEL) is not null
or REGEXP_SUBSTR ('7,8\3,5,9,0,6,4','[^,|\]+',1,LEVEL) is not null
effect :

analysis :
As shown in the figure , When we split a single line , When there are multiple columns of data , The final data will be split into multiple rows by the most data columns , Then the data correspond one by one , In turn, is [(1,7),(2,8),(3,3),(4,5),(5,9),(6,0),('',6),('',4)] , To display all the data , So in CONNECT BY in , use or Connect multiple columns and calculate . There will be 3...n Columns are also passed or Separate .
2、 Split multiple rows, columns and separators
Let's first look at the original data , Try splitting again
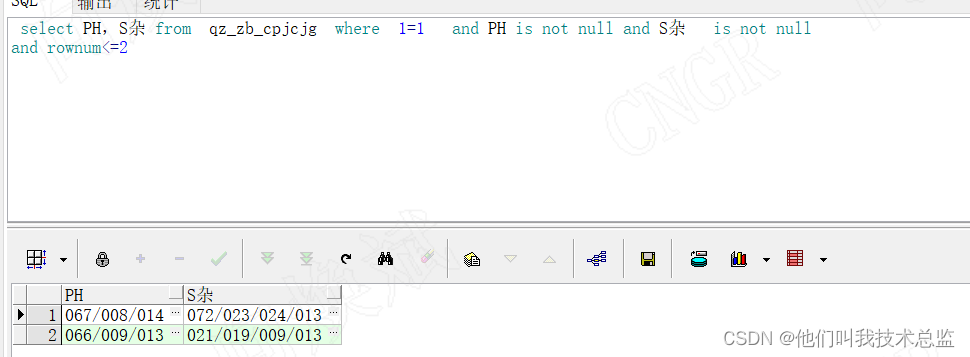
Code :
SELECT REGEXP_SUBSTR (PH,'[^/|\|//|*]+',1,LEVEL) PH,
REGEXP_SUBSTR (S miscellaneous ,'[^/|\|//|*]+',1,LEVEL) S miscellaneous
from ( select PH,S miscellaneous from qz_zb_cpjcjg where 1=1
and PH is not null and S miscellaneous is not null
and rownum<=2
) qz_zb_cpjcjg
CONNECT BY REGEXP_SUBSTR (PH,'[^/|\|//|*]+',1,LEVEL) is not null or
REGEXP_SUBSTR (S miscellaneous ,'[^/|\|//|*]+',1,LEVEL) is not nulleffect :
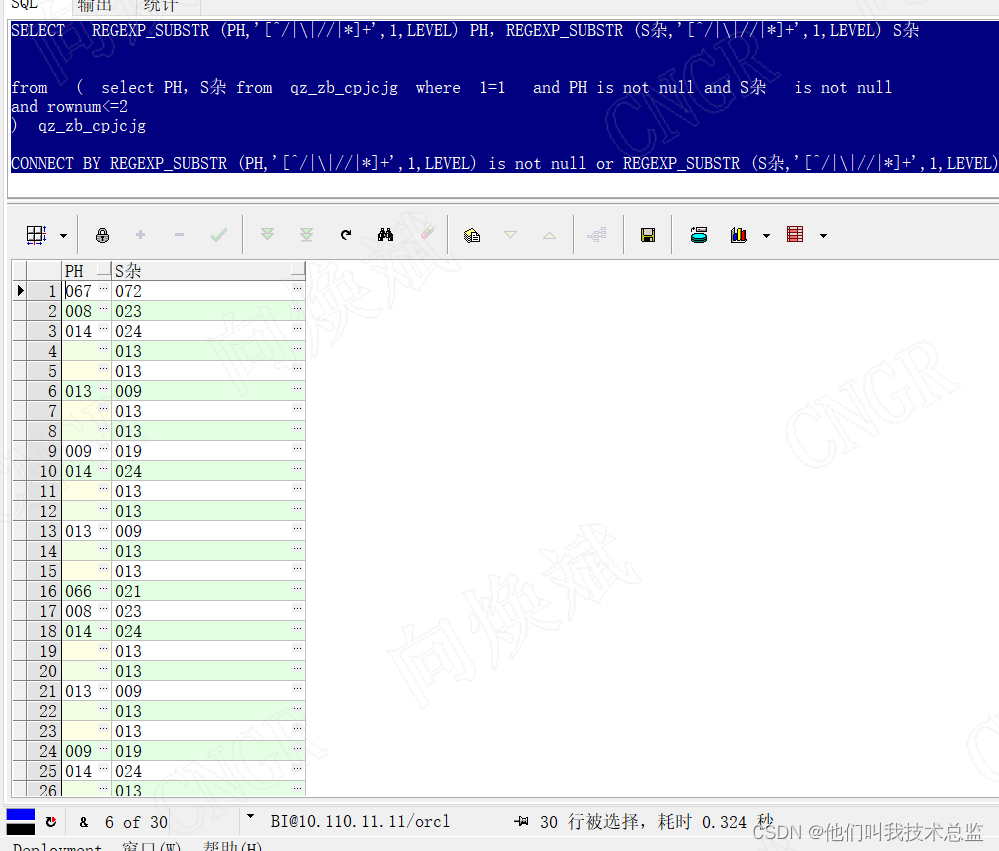
analysis :
When there is a 2 That's ok , The first column is 3 It's worth , The second as 4 It's worth , At this time, the total number of split rows is (1+2+4+8)*2 That's ok =30 That's ok , When we change the number of lines to 3 The result of the split is (1+3+9+27)*3 That's ok =120 That's ok , When we change the number of rows to 4 The result of row splitting is (1+4+16+64)*4=340 That's ok . At this point, we find that when the number of rows increases , The total number of branches we split will increase regularly , namely (1+n+n²+n³)*n=n+n²+n³+n^4, among n The number of lines calculated for you , The largest power is the largest split term . So when we have more rows , And the more projects you split , The number of items we finally split will be larger , When our number of rows is 64 That's ok , Split items 10 Time , At this time, the efficiency of splitting will be very low .
3、 ... and 、 Handle more than 100 million ... Billion level data
As shown in the figure , It took us an hour to split a project without calculating , Later, in the test, I took up all the cache and didn't calculate it . It seems that the above split method seems to be a little impractical for this multi line situation .
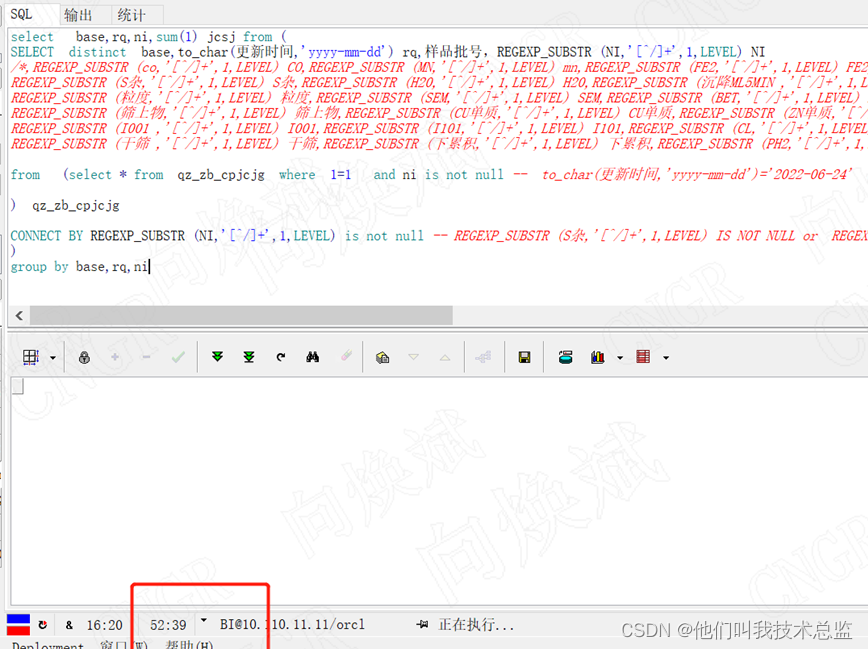
In reality, we have 80-90 term , And there are at least hundreds of lines , So such huge data , The result of the final split will be more than 100 million ... Billion level , It's going to be better than that 10^64 Much more . If we were to 10^64 Defined as incredible , So we call this split result “ It's incredible ” Well . Because it is composed of hundreds of millions of incredible . therefore , Facing us, there is only 128G It seems that it is impossible for a server with memory to handle this level of data , Do you have to give up ?
1、 Let's think about ?
We found that the efficiency of splitting single row data is very high , So we need to find the smallest unit of Statistics , And the number of rows of the smallest cell cannot exceed 10 That's ok , The time-consuming calculation results that cannot be split will be unacceptable . We think our demand this time is to count the daily workload of each person , Therefore, the first thing we think of is to count by day as the minimum dimension . That is, let's first count the workload of yesterday , Let's count today's workload . Then summarize the historical workload and today's workload, which corresponds to everyone's workload , Take another average to know whether the workload is saturated .

2、 But is it reasonable ?
At first, Xiaobian did the same , However, the amount of data found is still not small , because ....

3、 Statistics after converting multiple rows into single row split results
Because business says , This is the case , And it can't change . So I went to find the smallest unit . That is, split by single line , Finally, less than 1 Split all the workload in seconds . Finally, save the workload data of people on the corresponding date of each test item .
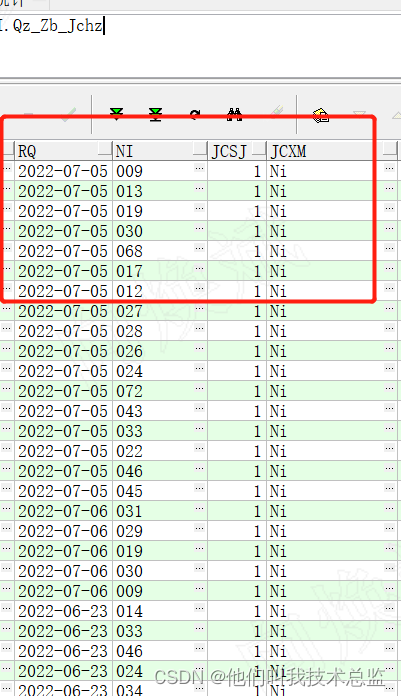
4、 Final effect
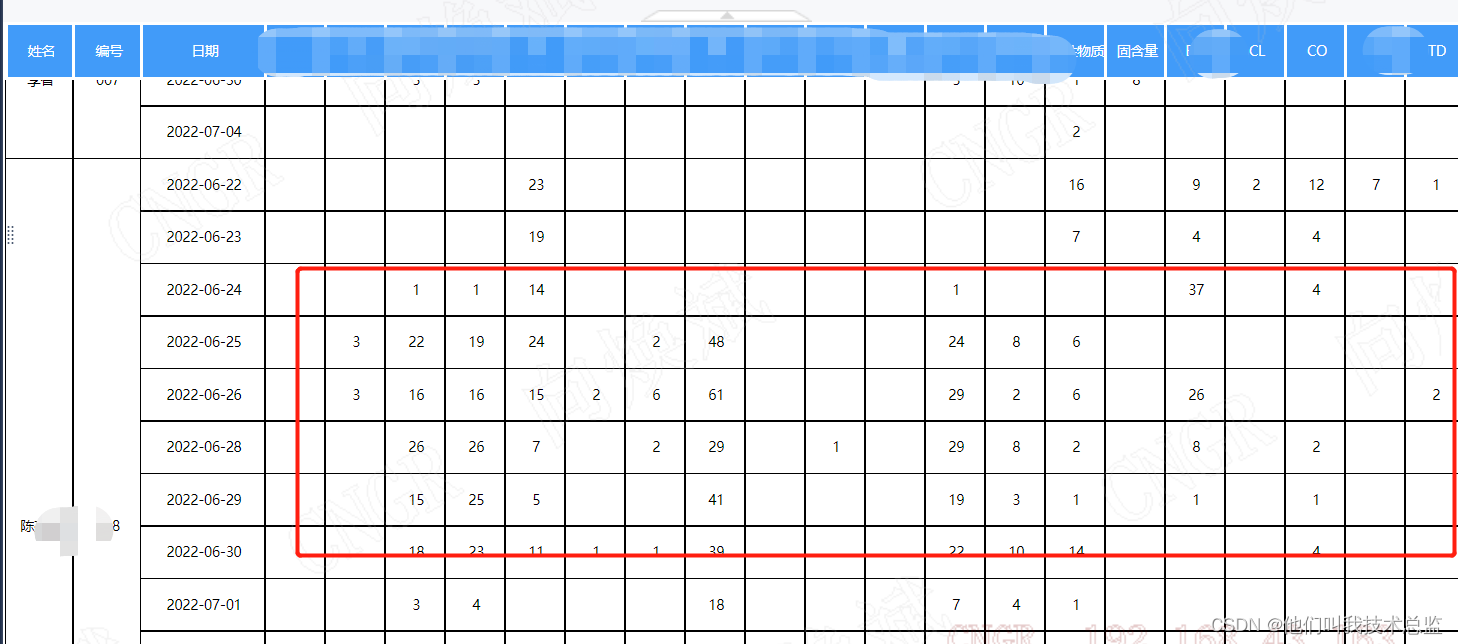
5、 analysis
The final split is split through the cursor loop of the stored procedure , Save the corresponding split details to the same table, and then summarize and analyze , Get the final workload , Because it's too late , I won't introduce the detailed split logic for the time being . If you want to get the final stored procedure splitting logic , Feel free to leave a comment ~
边栏推荐
- 字符串操作
- Upload an e-office V9 arbitrary file [vulnerability recurrence practice]
- 21 general principles of wiring in circuit board design_ Provided by Chengdu circuit board design
- ncs成都新电面试经验
- 如何在快应用中实现滑动操作组件
- [wechat applet: cache operation]
- leetcode135. Distribute candy
- [paper reading] icml2020: can autonomous vehicles identify, recover from, and adapt to distribution shifts?
- Frequently Asked Coding Problems
- NCS Chengdu Xindian interview experience
猜你喜欢

Calling the creation engine interface of Huawei game multimedia service returns error code 1002, error message: the params is error

About using CDN based on Kangle and EP panel
Golang compilation constraint / conditional compilation (/ / +build < tags>)
![[南京大学]-[软件分析]课程学习笔记(一)-introduction](/img/57/bf652b36389d2bf95388d2eb4772a1.png)
[南京大学]-[软件分析]课程学习笔记(一)-introduction
let const

Compilation and linking of programs

Input and output of floating point data (C language)

Opencv learning notes II - basic image operations
![FPGA knowledge accumulation [6]](/img/db/c3721c3e842ddf4c1088a3f54e9f2a.jpg)
FPGA knowledge accumulation [6]
Why choose cloud native database
随机推荐
opencv 将16位图像数据转为8位、8转16
Three series of BOM elements
Greenplum6.x重新初始化
Snyk dependency security vulnerability scanning tool
調用華為遊戲多媒體服務的創建引擎接口返回錯誤碼1002,錯誤信息:the params is error
数据分析方法论与前人经验总结2【笔记干货】
Introduction to data fragmentation
注解@ConfigurationProperties的三种使用场景
Gson converts the entity class to JSON times declare multiple JSON fields named
[Yu Yue education] higher vocational English reference materials of Nanjing Polytechnic University
POJ - 3784 running medium
Arm GIC (IV) GIC V3 register class analysis notes.
[wechat applet: cache operation]
IP guard helps energy enterprises improve terminal anti disclosure measures to protect the security of confidential information
2-3 lookup tree
String operation
[Chongqing Guangdong education] audio visual language reference materials of Xinyang Normal University
[kuangbin]专题十五 数位DP
[Yugong series] February 2022 U3D full stack class 007 - production and setting skybox resources
AVL balanced binary search tree