当前位置:网站首页>[secretly kill little buddy pytorch20 days] - [Day2] - [example of picture data modeling process]
[secretly kill little buddy pytorch20 days] - [Day2] - [example of picture data modeling process]
2022-07-05 22:30:00 【aJupyter】
System tutorial 20 Heaven takes Pytorch
Recently with Brother Zhong 、 Huige Do a little punch in ,20 God pytorch, This is the next day . Welcome to one button and three links .
List of articles
import os
import datetime
# Print time
def printbar():
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("\n"+"=========="*8 + "%s"%nowtime)
#mac On the system pytorch and matplotlib stay jupyter You need to change the environment variable when running in
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
!pip install prettytable
!pip install torchkeras
One 、 Prepare the data
cifar2 The data set is cifar10 A subset of a dataset , Only the first two categories are included airplane and automobile.
The training set has airplane and automobile Each picture 5000 Zhang , The test set has airplane and automobile Each picture 1000 Zhang .
cifar2 The goal of the mission is to train a model for the aircraft airplane And motor vehicles automobile Classify two kinds of pictures .
stay Pytorch There are usually two ways to build a picture data pipeline in .
The first is to use torchvision Medium datasets.ImageFolder To read the picture and then use DataLoader To load in parallel .
The second is through inheritance torch.utils.data.Dataset Implement user-defined read logic, and then use DataLoader To load in parallel .
The second method is a general method of reading user-defined data sets , You can read the picture data set , You can also read text data sets .
In this article, we introduce the first method .
import torch
from torch import nn
from torch.utils.data import Dataset,DataLoader
from torchvision import transforms,datasets
transform_train = transforms.Compose(
[transforms.ToTensor()])
transform_valid = transforms.Compose(
[transforms.ToTensor()])
ds_train = datasets.ImageFolder("/home/mw/input/data6936/eat_pytorch_data/data/cifar2/train",
transform = transform_train,target_transform= lambda t:torch.tensor([t]).float())
ds_valid = datasets.ImageFolder("/home/mw/input/data6936/eat_pytorch_data/data/cifar2/test",
transform = transform_train,target_transform= lambda t:torch.tensor([t]).float())
print(ds_train.class_to_idx.values())
print(ds_train.classes)
print(ds_train.imgs)
''' Output : dict_values([0, 1]) ['0_airplane', '1_automobile'] [('/home/mw/input/data6936/eat_pytorch_data/data/cifar2/train/0_airplane/0.jpg', 0), ('/home/mw/input/data6936/eat_pytorch_data/data/cifar2/train/0_airplane/1.jpg', 0), ('/home/mw/input/data6936/eat_pytorch_data/data/cifar2/train/0_airplane/10.jpg', 0), ('/home/mw/input/data6936/eat_pytorch_data/data/cifar2/train/0_airplane/100.jpg', 0), ('/home/mw/input/data6936/eat_pytorch_data/data/cifar2/train/0_airplane/1000.jpg', 0), ('/home/mw/input/data6936/eat_pytorch_data/data/cifar2/train/0_airplane/1001.jpg', 0)] '''
tips:
ImageFolder Is a universal data loader , It requires us to organize the training of data sets in the following format 、 Verify or test pictures .
root/dog/xxx.png
root/dog/xxy.png
root/dog/xxz.png
root/cat/123.png
root/cat/nsdf3.png
root/cat/asd932_.png
dataset=torchvision.datasets.ImageFolder(
root, transform=None,
target_transform=None,
loader=<function default_loader>,
is_valid_file=None)
Parameters, :
root: The root directory of image storage , That is, the upper level directory of the directory where each category folder is located .
transform: The operation of preprocessing pictures ( function ), The original image as input , Return a converted image .
**target_transform:** The operation of preprocessing picture categories , Input is target, Output to its conversion . If you don't pass this parameter , to target No conversion , The order index returned 0,1, 2…
loader: Indicates how the dataset is loaded , Usually, the default loading method is OK .
is_valid_file: Function to get the path of the image file and check whether the file is a valid file ( Used to check for damaged files )
Back to dataset All have the following three properties :
- self.classes: Use one list Save category name
- self.class_to_idx: Dictionary type 、 The index corresponding to the category , And return without any conversion target Corresponding
- self.imgs: preservation (img-path, class) tuple Of list
print(ds_train[0][1])
''' Output : tensor([0.]) '''
dl_train = DataLoader(ds_train,batch_size = 50,shuffle = True,num_workers=3)
dl_valid = DataLoader(ds_valid,batch_size = 50,shuffle = True,num_workers=3)
%matplotlib inline
%config InlineBackend.figure_format = 'svg'
# Check out some samples
from matplotlib import pyplot as plt
plt.figure(figsize=(8,8))
for i in range(9):
img,label = ds_train[i]
img = img.permute(1,2,0)
ax=plt.subplot(3,3,i+1)
ax.imshow(img.numpy())
ax.set_title("label = %d"%label.item())
ax.set_xticks([])
ax.set_yticks([])
plt.show()

tips:
img = img.permute(1,2,0) # Transforming dimensions
Original image size 33232 Turn to 32323
ax=plt.subplot(3,3,i+1) # Cutting subgraph
ax.imshow(img.numpy()) # visualization
# Pytorch The default order of pictures is Batch,Channel,Width,Height
for x,y in dl_train:
print(x.shape,y.shape)
break
''' Output : torch.Size([50, 3, 32, 32]) torch.Size([50, 1]) '''
Two 、 Defining models
Use Pytorch There are usually three ways to build models :
- Use nn.Sequential Build models in a hierarchical order
- Inherit nn.Module Base classes build custom models
- Inherit nn.Module Base classes build models and assist in applying model containers (nn.Sequential,nn.ModuleList,nn.ModuleDict) encapsulate .
Choose to inherit here nn.Module Base classes build custom models .
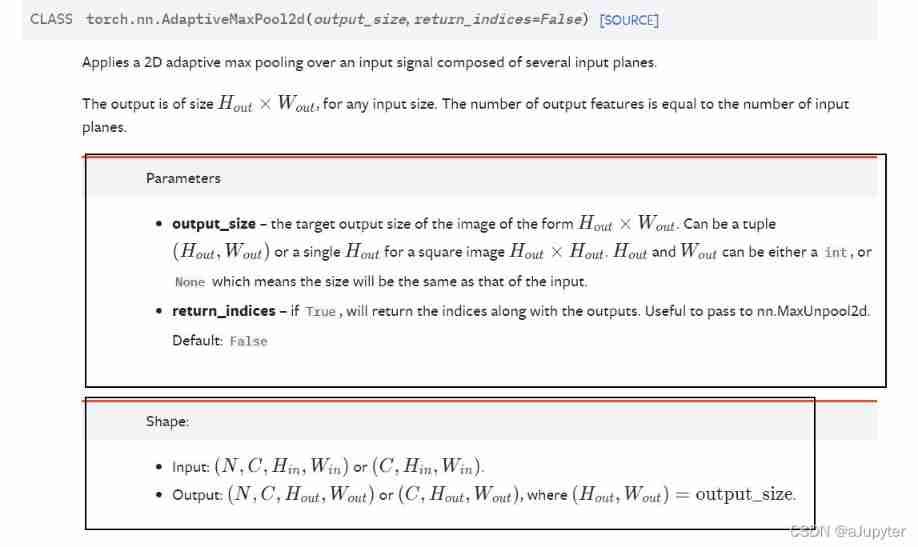
# test AdaptiveMaxPool2d The effect of
pool = nn.AdaptiveMaxPool2d((1,1))
t = torch.randn(10,8,32,32)
pool(t).shape
''' Output : torch.Size([10, 8, 1, 1]) '''
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3,out_channels=32,kernel_size = 3)
self.pool = nn.MaxPool2d(kernel_size = 2,stride = 2)
self.conv2 = nn.Conv2d(in_channels=32,out_channels=64,kernel_size = 5)
self.dropout = nn.Dropout2d(p = 0.1)
self.adaptive_pool = nn.AdaptiveMaxPool2d((1,1))
self.flatten = nn.Flatten()
self.linear1 = nn.Linear(64,32)
self.relu = nn.ReLU()
self.linear2 = nn.Linear(32,1)
self.sigmoid = nn.Sigmoid()
def forward(self,x):
x = self.conv1(x)
x = self.pool(x)
x = self.conv2(x)
x = self.pool(x)
x = self.dropout(x)
x = self.adaptive_pool(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.relu(x)
x = self.linear2(x)
y = self.sigmoid(x)
return y
net = Net()
print(net)
''' Output : Net( (conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1)) (pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (conv2): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1)) (dropout): Dropout2d(p=0.1, inplace=False) (adaptive_pool): AdaptiveMaxPool2d(output_size=(1, 1)) (flatten): Flatten(start_dim=1, end_dim=-1) (linear1): Linear(in_features=64, out_features=32, bias=True) (relu): ReLU() (linear2): Linear(in_features=32, out_features=1, bias=True) (sigmoid): Sigmoid() ) '''
import torchkeras
torchkeras.summary(net,input_shape= (3,32,32))
''' ---------------------------------------------------------------- Layer (type) Output Shape Param # ================================================================ Conv2d-1 [-1, 32, 30, 30] 896 MaxPool2d-2 [-1, 32, 15, 15] 0 Conv2d-3 [-1, 64, 11, 11] 51,264 MaxPool2d-4 [-1, 64, 5, 5] 0 Dropout2d-5 [-1, 64, 5, 5] 0 AdaptiveMaxPool2d-6 [-1, 64, 1, 1] 0 Flatten-7 [-1, 64] 0 Linear-8 [-1, 32] 2,080 ReLU-9 [-1, 32] 0 Linear-10 [-1, 1] 33 Sigmoid-11 [-1, 1] 0 ================================================================ Total params: 54,273 Trainable params: 54,273 Non-trainable params: 0 ---------------------------------------------------------------- Input size (MB): 0.011719 Forward/backward pass size (MB): 0.359634 Params size (MB): 0.207035 Estimated Total Size (MB): 0.578388 ---------------------------------------------------------------- '''
3、 ... and 、 Training models
Pytorch It usually requires the user to write a custom training cycle , The code style of the training cycle varies from person to person .
Yes 3 Class typical training cycle code style : Script form training cycle , Function form training cycle , Class form training cycle .
Here is a more general Function form training cycle .
import pandas as pd
from sklearn.metrics import roc_auc_score
model = net
model.optimizer = torch.optim.SGD(model.parameters(),lr = 0.01)
model.loss_func = torch.nn.BCELoss()
model.metric_func = lambda y_pred,y_true: roc_auc_score(y_true.data.numpy(),y_pred.data.numpy())
model.metric_name = "auc"
tips:
from sklearn.metrics import roc_auc_score
roc_auc_score
def train_step(model,features,labels):
# Training mode ,dropout The layer acts
model.train()
# Gradient clear
model.optimizer.zero_grad()
# Forward propagation for loss
predictions = model(features)
loss = model.loss_func(predictions,labels)
metric = model.metric_func(predictions,labels)
# Back propagation gradient
loss.backward()
model.optimizer.step()
return loss.item(),metric.item()
def valid_step(model,features,labels):
# Prediction model ,dropout The layer does not work
model.eval()
# Turn off gradient computation
with torch.no_grad():
predictions = model(features)
loss = model.loss_func(predictions,labels)
metric = model.metric_func(predictions,labels)
return loss.item(), metric.item()
# test train_step effect
features,labels = next(iter(dl_train))
train_step(model,features,labels)
''' Output : (0.6954520344734192, 0.500805152979066) '''
def train_model(model,epochs,dl_train,dl_valid,log_step_freq):
metric_name = model.metric_name
dfhistory = pd.DataFrame(columns = ["epoch","loss",metric_name,"val_loss","val_"+metric_name])
print("Start Training...")
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("=========="*8 + "%s"%nowtime)
for epoch in range(1,epochs+1):
# 1, Training cycle -------------------------------------------------
loss_sum = 0.0
metric_sum = 0.0
step = 1
for step, (features,labels) in enumerate(dl_train, 1):
loss,metric = train_step(model,features,labels)
# Print batch The level of log
loss_sum += loss
metric_sum += metric
if step%log_step_freq == 0:
print(("[step = %d] loss: %.3f, "+metric_name+": %.3f") %
(step, loss_sum/step, metric_sum/step))
# 2, Verification cycle -------------------------------------------------
val_loss_sum = 0.0
val_metric_sum = 0.0
val_step = 1
for val_step, (features,labels) in enumerate(dl_valid, 1):
val_loss,val_metric = valid_step(model,features,labels)
val_loss_sum += val_loss
val_metric_sum += val_metric
# 3, Log -------------------------------------------------
info = (epoch, loss_sum/step, metric_sum/step,
val_loss_sum/val_step, val_metric_sum/val_step)
dfhistory.loc[epoch-1] = info
# Print epoch The level of log
print(("\nEPOCH = %d, loss = %.3f,"+ metric_name + \
" = %.3f, val_loss = %.3f, "+"val_"+ metric_name+" = %.3f")
%info)
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("\n"+"=========="*8 + "%s"%nowtime)
print('Finished Training...')
return dfhistory
epochs = 20
dfhistory = train_model(model,epochs,dl_train,dl_valid,log_step_freq = 50)
Four 、 Evaluation model
dfhistory

%matplotlib inline
%config InlineBackend.figure_format = 'svg'
import matplotlib.pyplot as plt
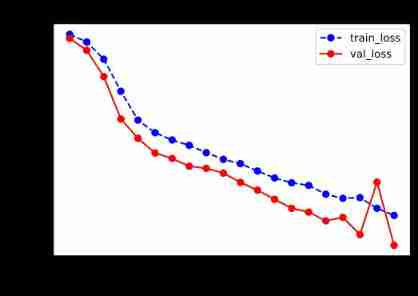
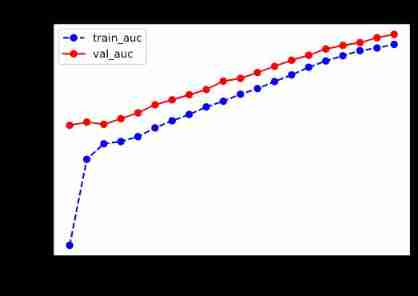
def plot_metric(dfhistory, metric):
train_metrics = dfhistory[metric]
val_metrics = dfhistory['val_'+metric]
epochs = range(1, len(train_metrics) + 1)
plt.plot(epochs, train_metrics, 'bo--')
plt.plot(epochs, val_metrics, 'ro-')
plt.title('Training and validation '+ metric)
plt.xlabel("Epochs")
plt.ylabel(metric)
plt.legend(["train_"+metric, 'val_'+metric])
plt.show()
plot_metric(dfhistory,"loss")
plot_metric(dfhistory,"auc")
5、 ... and 、 Using the model
def predict(model,dl):
model.eval()
with torch.no_grad():
result = torch.cat([model.forward(t[0]) for t in dl])
return(result.data)
# Prediction probability
y_pred_probs = predict(model,dl_valid)
y_pred_probs
''' tensor([[0.0342], [0.9139], [0.5341], ..., [0.7885], [0.9491], [0.5726]]) '''
# Forecast category
y_pred = torch.where(y_pred_probs>0.5,
torch.ones_like(y_pred_probs),torch.zeros_like(y_pred_probs))
y_pred
''' Output : tensor([[0.], [1.], [0.], ..., [0.], [1.], [1.]]) '''
6、 ... and 、 Save the model
It is recommended to save the parameters Pytorch Model .
print(model.state_dict().keys())
''' Output : odict_keys(['conv1.weight', 'conv1.bias', 'conv2.weight', 'conv2.bias', 'linear1.weight', 'linear1.bias', 'linear2.weight', 'linear2.bias']) '''
# Save model parameters
torch.save(model.state_dict(), "./data/model_parameter.pkl")
net_clone = Net()
net_clone.load_state_dict(torch.load("./data/model_parameter.pkl"))
predict(net_clone,dl_valid)
''' Output : tensor([[0.8983], [0.5431], [0.9716], ..., [0.0663], [0.1317], [0.4519]]) '''
summary
- datasets.ImageFolder
- from sklearn.metrics import roc_auc_score
- nn.AdaptiveMaxPool2d((1,1))
边栏推荐
- 实战:fabric 用户证书吊销操作流程
- 90后测试员:“入职阿里,这一次,我决定不在跳槽了”
- What changes has Web3 brought to the Internet?
- Thinkphp5.1 cross domain problem solving
- Performance testing of software testing
- 元宇宙中的三大“派系”
- Common interview questions of redis factory
- 了解 Android Kotlin 中 DataStore 的基本概念以及为什么应该停止在 Android 中使用 SharedPreferences
- What about data leakage? " Watson k'7 moves to eliminate security threats
- Oracle triggers
猜你喜欢
我把开源项目alinesno-cloud-service关闭了
All expansion and collapse of a-tree
2022-07-05:给定一个数组,想随时查询任何范围上的最大值。 如果只是根据初始数组建立、并且以后没有修改, 那么RMQ方法比线段树方法好实现,时间复杂度O(N*logN),额外空间复杂度O(N*

Pl/sql basic syntax

Wonderful review of the digital Expo | highlight scientific research strength, and Zhongchuang computing power won the digital influence enterprise award
Solutions for unexplained downtime of MySQL services

A trip to Suzhou during the Dragon Boat Festival holiday

Nanjing: full use of electronic contracts for commercial housing sales

Double pointer of linked list (fast and slow pointer, sequential pointer, head and tail pointer)
Metasploit(msf)利用ms17_010(永恒之蓝)出现Encoding::UndefinedConversionError问题
随机推荐
Postman核心功能解析-参数化和测试报告
谷歌地图案例
The statistics of leetcode simple question is the public string that has appeared once
Comment développer un plug - in d'applet
[untitled]
Assign the output of a command to a variable [repeat] - assigning the output of a command to a variable [duplicate]
Binary tree (II) -- code implementation of heap
Oracle triggers
Oracle is sorted by creation time. If the creation time is empty, the record is placed last
The countdown to the launch of metaverse ape is hot
APK加固技术的演变,APK加固技术和不足之处
Pl/sql basic syntax
How to develop and introduce applet plug-ins
Damn, window in ie open()
【无标题】
Text组件新增内容通过tag_config设置前景色、背景色
分布式解决方案之TCC
Go语言学习教程(十五)
Nanjing: full use of electronic contracts for commercial housing sales
ESP32 hosted