Introduction to shared memory
Shared memory is a user controlled level 1 cache , The shared memory is on-chip high-speed memory , It's a piece that can be the same block Read write memory accessed by all threads in . Access to shared memory is almost as fast as accessing registers ( Relatively speaking , Not exactly , The truth is , Shared memory latency is extremely low , about 1.5T/s The bandwidth of the , Much higher than global memory 190G/s, This speed is registered 1/10), It is the way to minimize the delay of communication between threads . Shared memory can be used to achieve a variety of functions , If it's used to save shared counters or block Public results of .
Ability to calculate 1.0、1.1、1.2、1.3 In hardware , Every SM The size of shared memory for is 16KByte, Organized as 16 individual bank, Dynamic and static allocation and initialization of shared memory
int main(int argc, char** argv)
{
// ...
testKernel<<<1, 10, mem_size >>>(d_idata, d_odata);
// ...
CUT_EXIT(argc, argv);
}
__global__ void testKernel(float* g_idata, float* g_odata)
{
// extern Statement , The size is determined by the host program . Dynamic statement
extern __shared__ float sdata_dynamic[];
// Static declaration
__shared__ int sdata_static[16];
// Be careful shared memory Initialize when no longer defined
sdata_static[tid] = 0;
}
Be careful , When a variable in shared memory is declared as external data , for example
extern __shared__ float shared[];
The size of the array will be in kernel Confirm at startup , It is determined by its execution parameters . All variables defined in this way start at the same address , Therefore, the layout of variables in the array must be managed through the offset display . for example , If you want to get the content corresponding to the following code in the dynamically allocated shared memory :
short array0[128];
float array1[64];
int array2[256];
It should be defined in the following way :
extern __shared__ char array[];
// __device__ or __global__ function
__device__ void func()
{
short* array0 = (short*)array;
float* array1 = (float*)&array0[128];
int* array2 = (int*)&array1[64];
}
Shared memory architecture
Shared memory is based on memory switching architecture (bank-switched architecture). In order to be able to obtain high bandwidth in parallel access , Shared memory is divided into equal sizes , Memory modules that cannot be accessed at the same time , be called bank. Because different memory modules can work without interference , So for the location of n individual bank Upper n Access to addresses can be done at the same time , At this time, there is only one available bandwidth bank Of n times .
If half-warp Multiple addresses requested for access are located in the same bank in , Will appear bank conflict. Since the memory module cannot respond to multiple requests at one time , So these requests have to be done serially . Hardware will cause bank conflict A set of memory access requests are divided into several times that do not exist conflict Independent request of , At this time, the effective bandwidth will be reduced and the split result will not exist conflict A multiple of the same number of requests . Exceptions : One half-warp When all threads in request access to the same address , There will be a broadcast , In this case, it only needs one time to respond to requests from all threads .
bank The way we organize is : Every bank The width of is fixed to 32bit, The adjacent 32bit Words are organized in adjacent bank in , Every bank In each clock cycle, it can provide 32bit The bandwidth of the .
On Fermi devices there is 32 It's a memory , And in the G200 And G80 In terms of hardware 16 It's a memory . Each storage can store 4 Bytes of data , Enough to store a single precision floating-point data , Or a standard 32 The integer number of bits . Kepler architecture also introduces 64 Bit wide memory , So that double precision data doesn't need to span two memory . No matter how many threads initiate operations , Each memory performs only one operation per cycle .
If each thread in the thread bundle accesses a memory , Then all thread operations can be executed simultaneously in a cycle . At this point, there is no need to access , Because the memory accessed by each thread is independent in shared memory , They don't influence each other . actually , There is a cross switch between each memory and thread to connect them , This is very useful in word exchange .
Besides , When all threads in the thread bundle access the memory with the same address at the same time , Using shared memory can help a lot , Same as constant memory , When all threads access a storage unit at the same address , A broadcast mechanism is triggered to each thread in the thread bundle . Usually 0 Thread No. will write a value and communicate with other threads in the thread bundle .
Shared storage access optimization
When accessing shared memory , We need to focus on how to reduce bank conflict. produce bank conflict Will cause serialization access , Severely reduces the effective bandwidth .
For computing power 1.x equipment , Every warp It's big and small 32 Threads , And one SM Medium shared memory Is divided into 16 individual bank(0-15). One warp Access requests to shared memory by threads in are divided into 2 individual half-warp Access requests for , Only in the same place half-warp Only threads within the bank conflict, And one warp Middle in front of half-warp The thread with the position after half-warp It doesn't happen between threads of bank conflict.
No, bank conflic Shared memory access examples for ( The thread reads from the array 32bit Word scene ):

produce bank conflict Shared memory access examples for ( The thread reads from the array 32bit Word scene ):
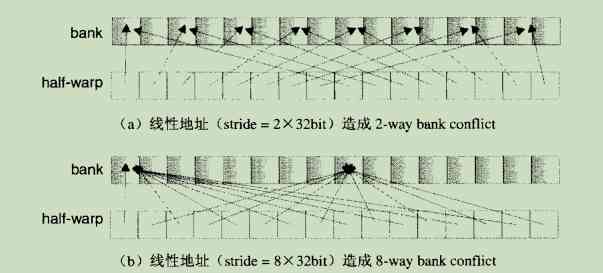
If the data size accessed by each thread is not 32bit when , There will be bank conflict. For example, the following is true of char Array access causes 4way bank conflict:
__shared__ char shared[32];
char data = shared[BaseIndex + tid];
here ,shared[0]、shared[1]、shared[2]、shared[3] Belong to the same bank. For the same array , Visit in the following form , You can avoid bank conflict problem :
char data = shared[BaseIndex + 4* tid];
For a structure assignment is compiled into several memory access requests , for example :
__shared__ struct type shared[32];
struct type data = shared[BaseIndex + tid];
If type There are several types of :
// type1
struct type {
float x, y, z;
};
// type2
struct type {
float x, y;
};
// type3
struct type {
float x;
char c;
};
If type Defined as type1, that type Will be compiled into three separate memory accesses , There is... Between the same member of each structure 3 individual 32bit Word spacing , So there is no bank conflict.( No, bank conflic To access the scene in the example c)
If type Defined as type2, that type Access to is compiled into two separate memory accesses , Every structural member has 2 individual 32bit Word spacing , Threads ID Apart, 8 Between threads of bank conflict.( produce bank conflict To access the scene in the example b)
If type Defined as type3, that type Access to is compiled into two separate memory accesses , Every member of a structure is passed through 5byte To visit , So there will always be bank conflict.
shared memory Deposit access mechanism
shared memory It uses a broadcast mechanism , In response to a read When asked , One 32bit It can be read and broadcast to different threads at the same time . When half-warp There are multiple threads Read same 32bit Data in the word address , Can reduce the bank conflict The number of . And if the half-warp When all threads in the same address are reading data from the same address , It's not going to happen at all bank conflict. however , If half-warp There are multiple threads in the same address Write operation , At this point, there will be uncertain results , When this happens, you should use the shared memory Atomic operation of .
Access requests to different addresses , It will be divided into several processing steps , Complete one step every two execution unit cycles , Only one at a time conflict-free A subset of access requests for , know half-warp All thread requests for completed . At each step, subsets are constructed according to the following rules :
(1) From words pointed to by addresses that have not been accessed , Choose one as the broadcast word ;
(2) Continue to select access to other bank, And it doesn't exist bank conflict The thread of , Then build a subset with the thread corresponding to the broadcast word in the previous step . In each cycle , Which word to choose as the broadcast word , And what to choose from and others bank The corresponding thread , It's all uncertain .
Reference resources :
《 High performance computing CUDA》
《CUDA Parallel programming GPU Programming Guide 》
《GPU High performance programming CUDA actual combat 》
《CUDA Expert manual GPU Programming authority Guide 》