当前位置:网站首页>[redis foundation] understand redis persistence mechanism together (rdb+aof graphic explanation)
[redis foundation] understand redis persistence mechanism together (rdb+aof graphic explanation)
2022-07-03 15:55:00 【Chen Xi should work hard】
【 Chen Xi has to work hard 】:hello Hello, I'm Chen Xi , I'm glad you came to read , Nickname is the hope that you can constantly improve , Moving forward to good programmers !
The blog comes from the project and the summary of the problems encountered in programming , Occasionally there are books to share , I'll keep updating Java front end 、 backstage 、 database 、 Project cases and other related knowledge points summary , Thank you for your reading and attention , I hope my blog can help more people , Share and gain new knowledge , Make progress together !
We quarryers , The heart of a cathedral , May we go in our own love …
Why persistence
We all know Redis The relevant data of is based on memory operation , Since the data is stored in memory , When the server restarts or goes down, memory data will be lost ;
In order to solve the problem of data loss, it is of course necessary to persist the data in memory to disk
After we installed redis after , All configurations are in redis.conf In file , It's preserved RDB and AOF Various configurations of the two persistence mechanisms

RDB Explain
By default , It's a snapshot RDB Persistence of , Write the data in memory to the binary file in the form of snapshot , The default file name is dump.rdb


Redis There is a default configuration in the configuration file
save 900 1
save 300 10
save 60 10000
900 Seconds , If exceeded 1 individual key Be modified , Then initiate snapshot saving
300 Seconds , If exceeded 10 individual key Be modified , Then initiate snapshot saving
60 Seconds , If 1 m key Be modified , Then initiate snapshot saving
for instance , The following settings will make Redis In the meet “ 60 At least in seconds 1000 Keys changed ” On this condition , Save the data set automatically once :
# save 60 10000 // close RDB Just put all the save Save the policy and comment it out
At the same time, we can also manually execute command generation RDB snapshot , Get into redis The client executes the command save or bgsave Can generate dump.rdb file , Every time the command is executed, all redis Memory snapshot to a new rdb In the document , And cover the original rdb Snapshot file .
RDB Three mechanisms for generating snapshots are provided :save、bgsave、 Automatic triggering
save command : Block the current Redis The server , until RDB Until the process is complete , For memory Larger examples can create long-term blockages , Online environment is not recommended
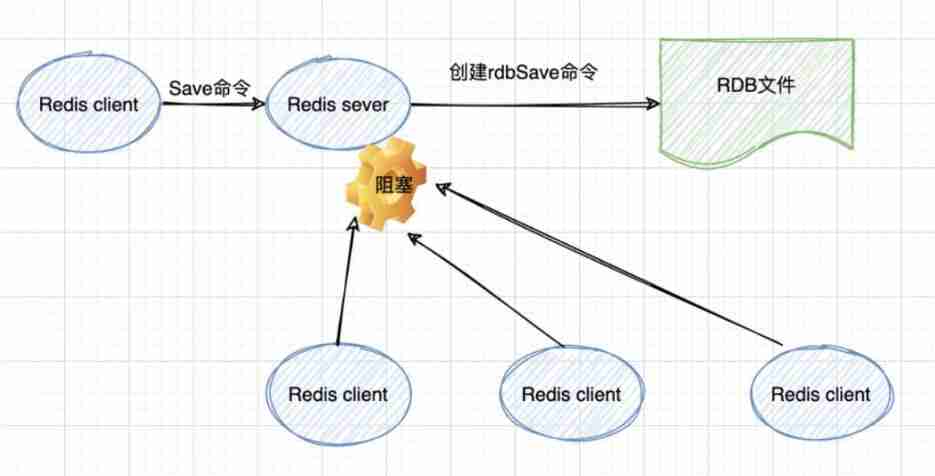
bgsave command :bgsave Copy on write (COW) Mechanism
Redis With the help of write time replication technology provided by the operating system (Copy-On-Write, COW), While taking a snapshot , The write command can still be processed normally .
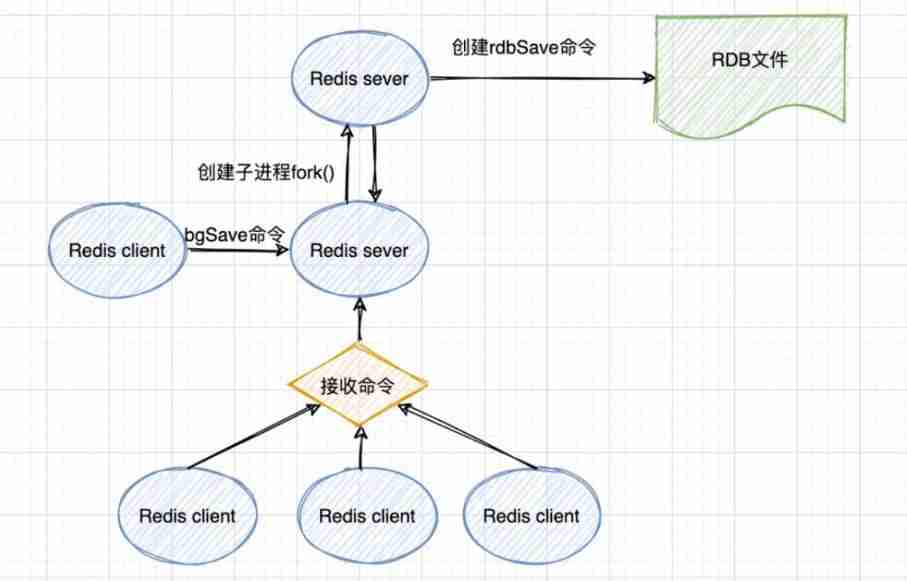
1、bgsave The child process is made up of the main thread fork Generated , All memory data of the main thread can be shared .bgsave After the subprocess runs , Start to read the memory data of the main thread , And write them in RDB file .
2、 here , If the main thread is also reading these data , that , Main thread and bgsave Subprocesses don't interact with each other . however , If the main thread wants to modify a piece of data , that , This data will be copied , Make a copy of the data . then ,bgsave The child process will write the replica data to RDB file , And in the process , The main thread can still modify the original data directly .
Automatic triggering : Auto trigger is done by our configuration file .
// Case study
save 60 10000
save、bgsave contrast
| Compare | save | bgsave |
|---|---|---|
| IO type | Sync | asynchronous |
| Is it blocked redis Other commands | yes | no ( Execute the call in the build subprocess fork There will be a temporary block in the function ) |
| Complexity | O(n) | O(n) |
| advantage | No extra memory consumed | Do not block client commands |
| shortcoming | Block client command | need fork Subprocesses , Memory consumption |
Configure automatic generation rdb The file background uses bgsave The way
AOF Explain
AOF(append only file) Persistence : Each write is logged as a separate log , Reexecute on reboot AOF The command in the file restores the data .AOF Main role of It solves the real-time problem of data persistence , So far Redis The mainstream way of persistence
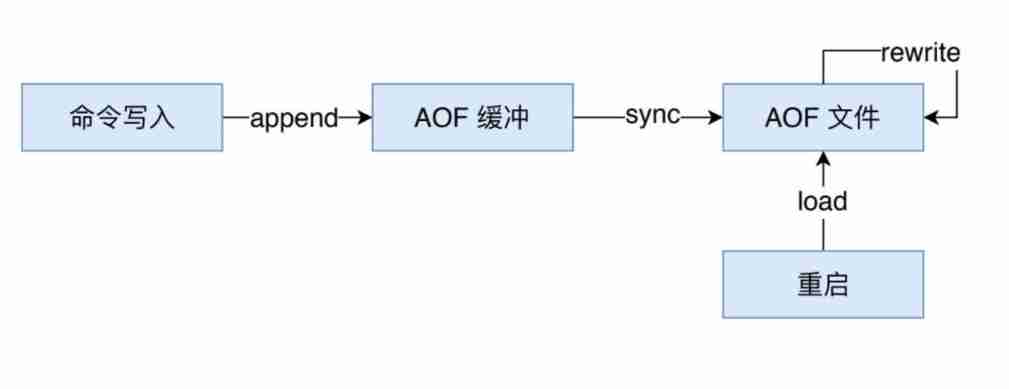
You can open... By modifying the configuration file AOF function :
appendonly yes
from now on , whenever Redis When executing a command to change a dataset ( such as SET), This order will be appended to AOF End of file .
In this case , When Redis On reboot , The program can be re executed by AOF The command in the file to rebuild the dataset . You can configure Redis How long will the data fsync Go to disk once .
There are three options :
appendfsync always: Every time a new order is added to AOF Execute the document once fsync , Very slow , It's also very safe .
appendfsync everysec: Per second fsync once , Fast enough , And it will only be lost in case of failure 1 Seconds of data .
appendfsync no: never fsync , Give the data to the operating system to process . faster , It's also a safer option .
AOF rewrite
With AOF The files are getting bigger , It needs to be done regularly AOF File rewriting
for instance , If you call a counter 100 Time INCR , So just to save the current value of this counter , AOF Documents need to be used 100 Bar record .
But in fact , Use only one SET The command is enough to hold the current value of the counter , rest 99 Records are actually redundant .
The following two configurations can be controlled AOF Auto rewrite frequency
# auto-aof-rewrite-min-size 64mb //aof Documents must at least reach 64M Will automatically rewrite , Files are too small to recover quickly , Rewriting doesn't mean much
# auto-aof-rewrite-percentage 100 //aof The file size has increased since it was last rewritten 100% Then trigger rewrite again
Redis Data persistence RDB-AOF Mixed mode
Redis 4.0 Brings a new persistence option —— Mix persistence .
Mixed persistence can be turned on through the following configuration ( Must be on first aof):
# aof-use-rdb-preamble yes
1、 If mixed persistence is turned on ,AOF When rewriting , It's no longer just about converting memory data to RESP Command write AOF file , But will rewrite the memory before this moment to do RDB Snapshot processing
2、 And will RDB Snapshot content and incremental AOF There are commands for modifying memory data , All write new AOF file , The new document didn't start with appendonly.aof, Wait until the new AOF The document will be renamed , Cover the original AOF file , Finish the new and the old AOF Replacement of documents .
3、 stay Redis When restarting , You can load RDB The content of , Then replay the increment AOF Log can completely replace the previous AOF Full file replay , So the restart efficiency has been greatly improved 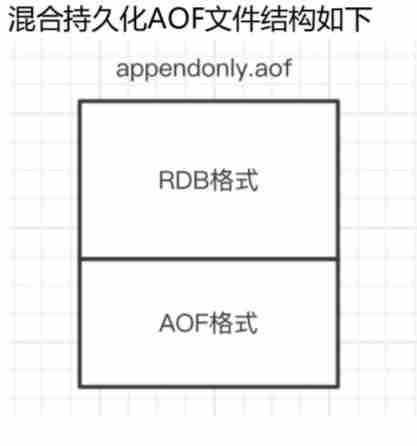
In the development of enterprises, we can adopt Redis Mix persistence methods to persist data , guarantee Redis Data is not lost
Think about the interview questions : How do you ensure persistence in your actual project ?

Think about it in real business !
Redis Data backup strategy
To prevent data loss , We can take necessary backup to save
1 、 Write crontab Scheduled scripts , Every hour copy One copy rdb or aof Backup to a directory , Just keep the latest 48 Hours of backup
2 、 Keep a copy of the data of the day every day and back it up to a directory , You can keep the last month's backup
3 、 Every time copy Back up , I deleted the old backup
4 、 Copy the backup on the current machine to other machines every night , In case of machine damage 
Redis Related articles : Read it together Redis Master slave architecture 、 Sentinel mode 、 colony (Demo Detailed explanation )
Thank you very much for reading here , If this article helps you , I hope I can leave your praise Focus on ️ Share Leaving a message. thanks!!!
2021 year 11 month 30 Japan 22:25:45 May we go in our love !
边栏推荐
- Tensorflow realizes verification code recognition (III)
- nifi从入门到实战(保姆级教程)——flow
- 软件逆向破解入门系列(1)—xdbg32/64的常见配置及功能窗口
- Wechat payment -jsapi: code implementation (payment asynchronous callback, Chinese parameter solution)
- Backtracking method to solve batch job scheduling problem
- 秒杀系统1-登录功能
- 关于网页中的文本选择以及统计选中文本长度
- Create gradle project
- [combinatorial mathematics] binomial theorem and combinatorial identity (binomial theorem | three combinatorial identities | recursive formula 1 | recursive formula 2 | recursive formula 3 Pascal / Ya
- Halcon and WinForm study section 1
猜你喜欢
Seckill system 2 redis solves the problem of distributed session
Summary of JVM knowledge points
Create gradle project
Microservice API gateway zuul

Redis在Windows以及Linux系统下的安装

Popular understanding of linear regression (I)
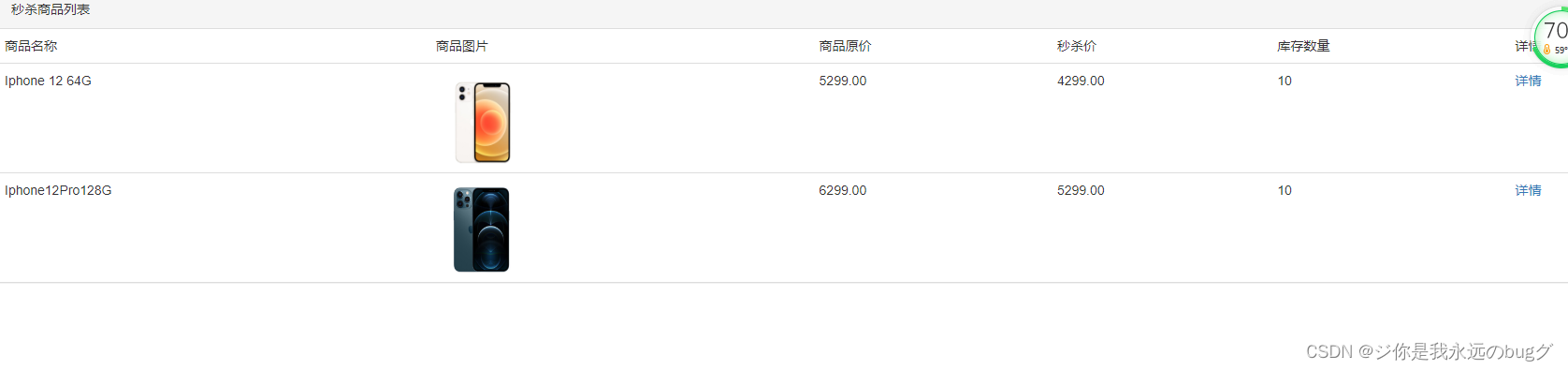
Second kill system 3 - list of items and item details

"Remake Apple product UI with Android" (2) -- silky Appstore card transition animation
![App mobile terminal test [5] file writing and reading](/img/f1/4bff6e66b77d0f867bf7237019e982.png)
App mobile terminal test [5] file writing and reading

Three dimensional reconstruction of deep learning
随机推荐
找映射关系
Vs2017 is driven by IP debugging (dual machine debugging)
利用MySQL中的乐观锁和悲观锁实现分布式锁
详解指针进阶2
Reflection on some things
Under VC, Unicode and ANSI are converted to each other, cstringw and std:: string are converted to each other
How are integer and floating-point types stored in memory
Semi supervised learning
CString getbuffer and releasebuffer instructions
GCC cannot find the library file after specifying the link library path
软件安装信息、系统服务在注册表中的位置
Go语言自学系列 | golang中的if else if语句
Calibre LVL
2022年Q2加密市场投融资报告:GameFi成为投资关键词
Create gradle project
坚持输出需要不断学习
Visual upper system design and development (Halcon WinForm) -6 Nodes and grids
Introduction series of software reverse cracking (1) - common configurations and function windows of xdbg32/64
The wonderful use of do{}while()
Microservices - load balancing ribbon