当前位置:网站首页>超标量处理器设计 姚永斌 第6章 指令解码 摘录
超标量处理器设计 姚永斌 第6章 指令解码 摘录
2022-07-04 15:51:00 【岐岇】
在流水线中,指令解码decode阶段的任务是将指令中携带的信息提取出来,处理器使用这些信息控制后续流水线来执行这条指令。
指令集的复杂程度直接决定了这部分任务的工作量,对于CISC指令集来说,例如x86来说,指令的长度是不固定的,解码阶段首先需要分辨指令的边界,这样才能够找到有效的指令,而且x86指令的寻址方式也很复杂,这增加了解码的难度。对于RISC指令集来说,指令的长度是固定,例如MIPS和ARM,都是32位,这样很容易分辨出来,而且RISC处理器的寻址方式相对也比较简单,这些因素导致RISC处理器的解码难度要远低于CISC处理器,因此RISC处理器在成本和功耗方面天生就比CISC处理器占据优势。影响处理器解码复杂度还有一个因素,那就是每周期可以解码的指令个数,由于每条指令都需要一个完整的解码电路,所以对于一个每周期可以解码n条的超标量处理器来说,就需要n个解码电路。
总结来看,一个RISC处理器的解码部分如下
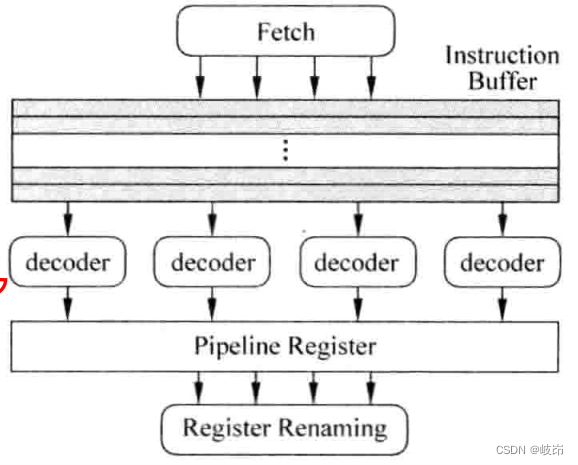
在超标量处理器中,即使是RISC指令集,仍存在一些另类的指令,这些指令不能使用一般指令的处理方式,需要特殊处理,例如有些指令的目的寄存器个数多于一个乘累加和LDM/STM等,这会影响寄存器重命名register renaming过程。再例如,有些RISC指令集支持每条指令都条件执行,不过这些另类指令使用的频率并不高,没有必要让后面的流水线增加硬件来对它们进行处理,这需要在解码阶段将它们转换为普通的指令,后面的流水线按照一般指令的处理方式来执行它们。
6.1 指令缓存
为了减少I-Cache缺失带来的影响,处理器可以在取指令阶段从I-Cache中取出的指令个数多于每周期可以解码的指令个数,例如MIPS 74kf处理器中,每周期取出4条指令,但是每周期只可以解码2条指令,这就需要在取指令和解码阶段之间加入一个缓存,用来将I-Cache取出的所有指令保存起来,这个缓存称为指令缓存instruction buffer。
(1)四条指令,当然这四条指令未必全部都是有效的;
(2)有效指令的个数,当取指令的地址落在Cache line的最后三个字,或者指令组fetch group中存在被预测跳转的分支指令时,会导致取指令阶段无法向指令缓存中写入四条指令,此时使用这个型号来告诉指令缓存,那些指令时有效的。
指令缓存本质上是一个FIFO,它能够将指令按照程序中指定的顺序存储起来,这样指令在解码的时候,仍旧可以按照程序中指定的顺序进行解码,便于找到指令间存在的相关性。指令缓存是超标量处理器中必须的部件,其原因有二:
(1)在很多超标量处理中,每周期可以取指令的个数大于每周期可以解码指令的个数,这样即使在I-Cache缺失的时候,指令缓存中仍然有一些余量的指令,如果I-Cache的缺失可以很快的解决,那么基本上不会引起流水线暂停。
(2)在超标量处理器中,即使每周期取指令的个数等于每周期解码指令的个数,例如都是4条指令,在流水线的解码阶段却有一些特殊的指令要处理,这回导致取指令阶段得到所有指令没有办法在解码阶段全部得到处理。例如乘累加指令有两个目的寄存器,为了减少对寄存器重命名阶段的影响,都会将其拆分成两条普通的指令,每条指令都只有一个目的寄存器,因此,一旦在取指令阶段得到的指令包括乘累加指令时,如果不进行处理,会导致解码之后的指令个数多于4条,而后续的流水线的处理能力都是按照每周期处理4条指令来设计的,不可能因为这种不常出现的情况而增阿基后续流水线的处理能力,这样会占用更多的硅片面积,因此就需要在解码阶段对乘累加类型的指令进行处理。
超标量处理器中限制的一种折中思想是不为很少出现的情况增加硬件的复杂度。由于这些限制的存在,在每周期内,取指令阶段送出的指令不一定能够在解码阶段全部被解码,因此就需要一个地方来暂存这些不能被解码的指令,这个地方就是指令缓存,使用它,可以使解码部分的设计更加灵活。
由于指令缓存每周期内可以写入多条指令,也可以读出多条指令,因此它是一个多端口的FIFO,实际是使用交叠interleaving方式,使用多个单端口的SRAM来实现,从而避免了使用多端口SRAM所带来的硬件和速度上的限制。
6.2 一般情况
MIPS指令一般包括两个源寄存器Rs和Rt和一个目的寄存器Rd;ARM指令一般包括三个源寄存器Rn,Rs和Rm和一个目的寄存器Rd,情况远不止如此,一些特殊情况为:
(1)对于条件执行的指令来说,还包括第四个源寄存器,也就是CPSR。
(2)所有改变状态寄存器的指令,还包括第二个目的寄存器,即CPSR。
(3)对于前后变址的load/store指令,也包括第二个目的寄存器,即用来作为地址的寄存器,当指令执行完成后,除了将正常地数据写到目的寄存器之外,还需要将地址寄存器的内容也进行更新。
(4)还有很另类的LDM/STM指令,包括了数量不确定的目的寄存器和源寄存器。
在上面特殊情况中,前两条体现在CPSR寄存器,它可以作为源寄存器,也可以作为目的寄存器。在超标量实现中,如果将CPSR寄存器作为一个普通的寄存器来对待,那么此时ARM的每条指令就包括四个源寄存器和两个目的寄存器,这对寄存器重命名register renaming过程的映射表的影响非常,本来映射表的端口个数已经很多了,面积和速度都很难进行优化,如果在加入额外的端口,那么情况就会更加糟糕;而且CPSR寄存器的宽度只有4位(N,C,Z,V),而普通通用寄存器是32位,如果将CPSR寄存器和通用寄存器统一对待,会造成很多寄存器不能得到有效利用,32位寄存器只装入4位的数据。考虑到这些限制,一般都是将CPSR寄存器单独处理,为CPSR寄存器设置一个独立的物理寄存器堆Physical register file,用来存放重命名之后的CPSR寄存器,并使用一个单独地映射表mapping table来进行管理。
对于(3)和(4)所体现的特殊性在于,将这些特殊的指令拆分为多条普通的RISC指令,这样就可以利用一般的硬件对这些特殊的指令进行处理,在超标量处理器中,一条指令所携带的源寄存器和目的寄存器的个数直接决定了寄存器重命名电路在实现上的难易,例如映射表的端口个数,指令间相关性检查电路的复杂度等。
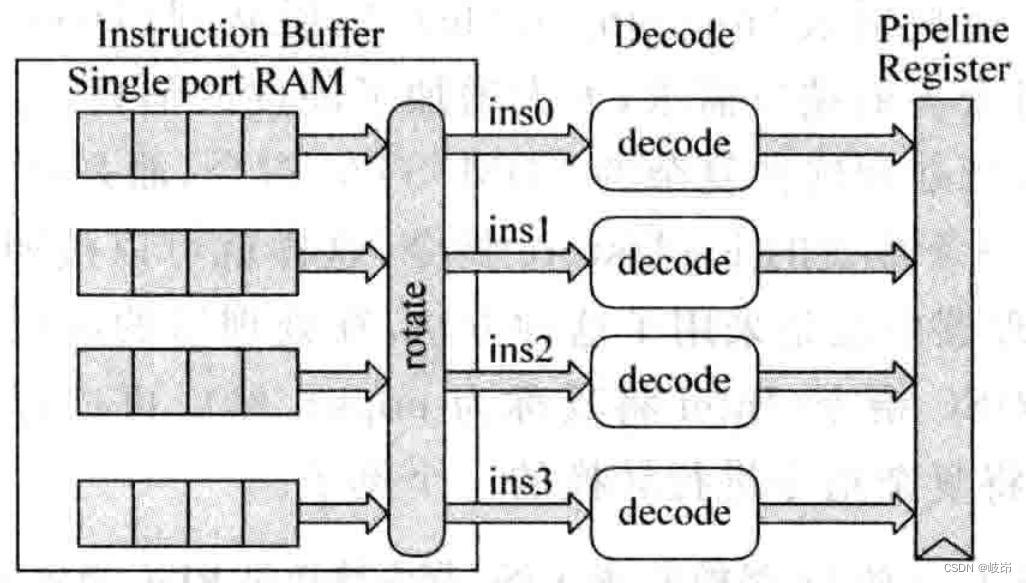
一般情况下,每周期都会从指令缓存instruction buffer中读取多条指令。从指令缓存中读取的4条指令未必是4字对齐,这就需要将4条指令按照程序中原始的顺序排序好,送给解码电路进行解码,这是采用交叠结构的多端口存储器所必须考虑的问题。
由于RISC指令比较规整,很容易找出指令中的操作码op和操作数operand,在解码阶段产生的流水线控制信号也会比较少,因此RISC处理器的解码一般都可以在一个周期内完成,突出RISC秉承通过简化的指令集来简化硬件设计的复杂度,从而获得更高的性能。
RISC处理在解码解码完成任务可以概括为三个what,它们解释如下:
(1)what type,例如指令时算术指令,访问存储器指令还是分支指令;
(2)what operation,例如当算术指令时进行何种算术运算
(3)what resource,例如对于算术指令来说,源寄存器和目的寄存器是那些,指令中是否有立即数等。
6.3 特殊情况
对于RISC中特殊指令,例如LDM/STM来说,需要多个周期才能完成,而且他们的目的/源寄存器有多个,如果在超标处理器中对它们按照普通指令对待的话,就会使映射表mapping table、发射队列issue queue和重排序缓存ROB等部件面临众多的端口要求,大大增加了硬件消耗,并且降低了速度,因此在超标量处理器中不会直接处理复杂的LDM/STM指令,而是将它们转换为多条简单指令。
在x86指令集中,是允许指令中的一个数来自于存储器的,这也是CISC指令的一个特点,而且为了便于访问存储器的指令之间进行相关性检查,会将store指令拆分成STA和STD两条指令,STA指令用于计算地址,而STD指令用来找到数据。
不管对于CISC指令集还是RISC指令集,使用比较复杂的指令可以获得更高的额代码密度和更低的I-Cache缺失率。但是在超标量处理器中这些复杂的指令引入了额外的麻烦,需要使用更多的硬件资源才可以对它们进行处理。最初在设计这些复杂指令的时候并没有考虑超标量的实现,例如ARM指令集是为了在普通的标量scalar流水线而设计,x86则诞生在编译器compiler很不发达的年代,需要硬件来承担更多的责任。
在现在的高性能应用领域,代码密度这个宝刀已经锈迹斑斑,失去了曾经的魅力。
而ARM指令集中这些复杂指令则需要消耗更多的硅片资源来实现,导致了功耗的增加,与低功耗设计愿景相违背。
在新的ARMv8指令集中,LDM/STM这样的复杂指令已经被砍掉了,而且通用寄存器的个数也变为32个,也不再有指令内嵌的移位运算,条件执行也被限制在少数的指令上。
6.3.1 分支指令的处理
采用Checkpoint的方式对分支预测失败的处理器进行状态恢复时,为了减少分支编号分配电路的复杂度,需要限制每周期进行解码的分支指令个数,例如最多有一条分支指令。
面对多条分支指令的一个简单解决方法,即遇到分支指令时,就不在本周期对这条分支指令后面的指令进行解码,而是将它们放到下个周期,这个功能只需要通过改变指令缓存的读指针即可。
如果采用基于ROB的方法对分支预测失败时的处理器进行状态恢复,就不在需要进行编号的分配工作了。
在解码阶段还有一个重要任务,就是对分支预测是否正确进行初步的检查,越早地发现错误的分支预测,引起的惩罚penalty越小,而一些直接跳转类型的分支指令在解码阶段就可以计算出目标地址,因此可以在解码阶段对这些分支指令的目标地址是否正确进行检查。
分支指令在解码阶段是无法得到实际方向的(除了Jump指令,因为它总是跳转的,一般不会预测错误),因为在解码阶段也就无法对分支预测的方向进行检查,这需要等到后续的流水线阶段才可以完成。
6.3.2 乘累加/乘法指令的处理
一般来说,越是简单的指令,越容易在超标量处理器中实现。MIPS中的特殊指令乘累加和乘法是一种特殊的指令,它的特殊之处在于指令中包括两个目的寄存器,且不属于通用寄存器。
乘法和目的寄存器有两个目的寄存器,非常规的情况就为重命名电路带来了麻烦。不仅如此,如果把这条乘累加.乘法指令直接放到ROB中,则ROB需要能够存放两个目的寄存器,这种非常规情况也增加了ROB的面积,而且由于大部分指令都不是乘累加类型的指令,所以ROB中增加的部分绝大部分时间都是没有使用的,采用以下两部来解决这个问题:
(1)将寄存器Hi和Lo分配给MIPS处理的第33个和34个通用寄存器,当然在指令集中是看不到这个过程的,这种分配只是在处理器内部进行,寄存器重命名过程的重映射表也相应地需要支持34个通用寄存器。
(2)将乘法/乘累加指令拆分成两条指令。
这两条指令经过重命名后并写到ROB中,会占用了ROB的两个表项entry,需要读取四个源寄存器,两个目的寄存器。其实在处理器内部,被拆分的乘累加指令并不是单独去完成运算的,而是在流水线执行阶段,仍旧以一个完整的乘累加指令来完成运算,因此指令的拆分只是更有利于寄存器重命名,以及便于在ROB中存放,每条被拆分的指令并不是单独地进行运算。
当然,要实现上述功能,还需要对发射队列issue queue做特殊处理,将乘法指令和乘累加指令使用一个运算单元Function Unit,这个FU的发射队列和其他的有所不同,它包括四个源操作数,两个目的寄存器。在解码阶段被拆分的指令,经过寄存器重命名后,就要写到ROB和发射队列中,这个阶段就是Dispatch,此时写到ROB中仍旧是以两条指令的方式写入,占据ROB中两个连续的空间;而写发射队列的时候,则是将两条指令进行了融合,这两条指令在发射队列中变成一条完整的乘累加或乘法指令,这样就能保证FU在执行的时候,能够执行一个完整的乘累加或者乘法指令。
对于一个周期内解码的四条指令中包括乘累加指令,采用下面两种方法来解决;
方法一:在解码阶段和寄存器重命名阶段之间加入一个缓存,用它来替换流水线寄存器,暂存解码阶段产生的指令信息。但是,由于指令经过解码之后会得到很多的信息,例如流水线的控制信号灯,导致这个缓存需要的位宽很大,在一定程度上增加了硬件面积。
方法二:限制每周期可以解码的个数,一旦在解码阶段发现乘累加指令,例如MADD,那么只有在MADD1指令及其之前的指令可以解码,在MADD2及其之后的指令需要等到下个周期才可以解码。
6.3.3 前后变址指令的处理
在ARM指令集中还有一种前后变址的寻址方式,能够在一条指令中完成两个任务,普通流水线处理器是容易实现的,但是在超标量实现中,会带来额外的麻烦。例如ARM中的一条load指令:
LDR R2,[R1,#4];
此指令执行了两个操作,即从存储器中将地址[R1+4]中的数据放到寄存器R2中,并且把用作地址的寄存器R1更新为R1+4的值。此时目的寄存器包括R1和R2,而两个目的寄存器会给寄存器重命名以及之后例如唤醒带来麻烦,因为在超标量处理器实现时,仍旧会在处理器内部将这个复杂的load指令拆分成两条普通的指令。
一条普通的load指令实现load数据的功能;
一条加法指令,用来改变地址寄存器。
这个拆分过程是在解码阶段完成的,
实现同样的功能,ARM处理器占用更少的指令存储器空间,使得ARM处理的I-Cache miss rate低于MIPS处理器;但是ARM需要在处理器内部使用硬件将指令进行拆分,这需要占据更多的硅片面积,也导致了功耗增加。
6.3.4 LDM/STM指令的处理
STM指令将多个寄存器的内容保存在存储器中一片连续的空间内,LDM指令可以将存储器中一片连续地址空间上的数据加载到多个寄存器中,在超标量处理器中,需要将它们拆分为多条普通的load/store指令。例如LDM指令;
LDM R5!, {R0~R3}
这条指令将存储器中四个地址的数据memory[R5],memory[R5+4],memory[R5+8],memory[R5+12]读取到R0,R1,R2,R3中,并将作为地址的寄存器R5更新为新值R5+12,因此这条指令相当于完成了五个任务。超标量处理器的解码阶段会将其拆分为4条普通的load指令和一条普通的add指令。
LDR R0, #0[R5]
LDR R0, #4[R5]
LDR R0, #8[R5]
LDR R0, #12[R5]
ADD R5, R5,12
拆分之后,LDM指令仍旧需要多个周期才可以完成,而且这种拆分需要一些逻辑电路,并对处理器的周期时间产生负面影响。
为什么要冲寄存器列表的最低位开始,顺序进行查找呢?这是因为在LDM/STM指令中,寄存器按照编号从小到大的顺序和存储器中一片连续的地址空间相对应,因此必须按照顺序找到寄存器列表中的寄存器,才可以正确的和存储器的地址相对应。
6.3.5 条件指令的处理
在ARM中,每条指令的编码中,Bit[31:28]用作了条件码,用来判断当前CPSR寄存器中的值是否是想要的值,从而决定这条指令是否执行。
ARM处理器中,条件执行的本质将CPSR寄存器也作为一个源目的寄存器来对待,当一条指令的执行需要改变状态寄存器时,CPSR作为一个目的寄存器,而当一条指令需要条件执行时,状态寄存器CPSR就作为源寄存器。
超标量处理器中指令都是乱序执行,条件执行的指令读取到CPSR寄存器的内容未必就是自己想要的。
在超标量寄存器的ARM处理器中,需要对条件执行的情况加以处理。当一条指令要改写CPSR寄存器时,使用一个新的CPSR寄存器来保存这个指令的状态,并给这个CPSR寄存器赋予一个新的名字,与之对应的条件执行指令都会使用这个新的CPSR寄存器作为它们的一个源寄存器。
边栏推荐
- VSCode修改缩进不成功,一保存就缩进四个空格
- It's too convenient. You can complete the code release and approval by nailing it!
- 大规模服务异常日志检索
- 补能的争议路线:快充会走向大一统吗?
- leetcode刷题目录总结
- leetcode:421. 数组中两个数的最大异或值
- Load test practice of pingcode performance test
- Offline and open source version of notation -- comprehensive evaluation of note taking software anytype
- Implementation of super large-scale warehouse clusters in large commercial banks
- MD5加密的两种方式
猜你喜欢
【HCIA持续更新】广域网技术

Smart Logistics Park supply chain management system solution: digital intelligent supply chain enables a new supply chain model for the logistics transportation industry
CANN算子:利用迭代器高效实现Tensor数据切割分块处理

【HCIA持续更新】网络管理与运维

雨量预警广播自动化数据平台BWII 型广播预警监测仪
数学分析_笔记_第7章:多元函数的微分学
Internet addiction changes brain structure: language function is affected, making people unable to speak neatly

Implementation of super large-scale warehouse clusters in large commercial banks
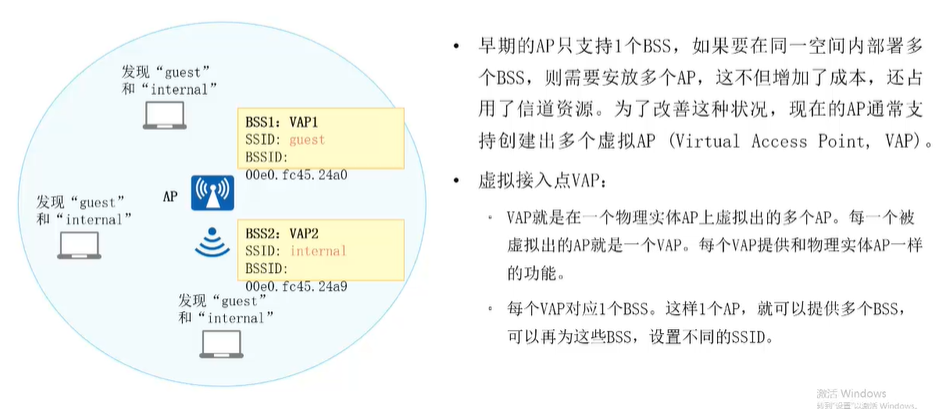
【HCIA持续更新】WLAN概述与基本概念

The test experience "tortured" by the PMP test is worth your review
随机推荐
Analysis of abnormal frequency of minor GC in container environment
[HCIA continuous update] overview of WLAN workflow
It's too convenient. You can complete the code release and approval by nailing it!
Congratulations to Mr. Zhang Pengfei, chief data scientist of artefact, for winning the campaign Asia tech MVP 2022
2022PMP考试基本情况详情了解
Is it safe for CITIC Securities to open an account online? Is the account opening fee charged
智捷云——元宇宙综合解决方案服务商
中银证券网上开户安全吗?
码农版隐秘的角落:作为开发者最讨厌的5件
整理混乱的头文件,我用include what you use
Zebras are recognized as dogs, and the reason for AI's mistakes is found by Stanford
Ble HCI flow control mechanism
【HCIA持续更新】广域网技术
CocosCreator事件派發使用
第十八届IET交直流輸電國際會議(ACDC2022)於線上成功舉辦
kaili不能输入中文怎么办???
Blood spitting finishing nanny level series tutorial - play Fiddler bag grabbing tutorial (2) - first meet fiddler, let you have a rational understanding
PingCode 性能测试之负载测试实践
TP configuring multiple databases
Hidden corners of coder Edition: five things that developers hate most