当前位置:网站首页>A model can do two things: image annotation and image reading Q & A. VQA accuracy is close to human level | demo can be played
A model can do two things: image annotation and image reading Q & A. VQA accuracy is close to human level | demo can be played
2022-07-02 09:56:00 【QbitAl】
bright and quick From the Aofei temple
qubits | official account QbitAI
Now? , Throw it to AI A picture , It can not only look at pictures and talk , It can also deal with the tricky problems raised by people .
such as , Show it a classic picture .

It can answer :
One in a suit 、 The man who is gesturing .
So what color are the men's eyes in the picture ?
Blue .
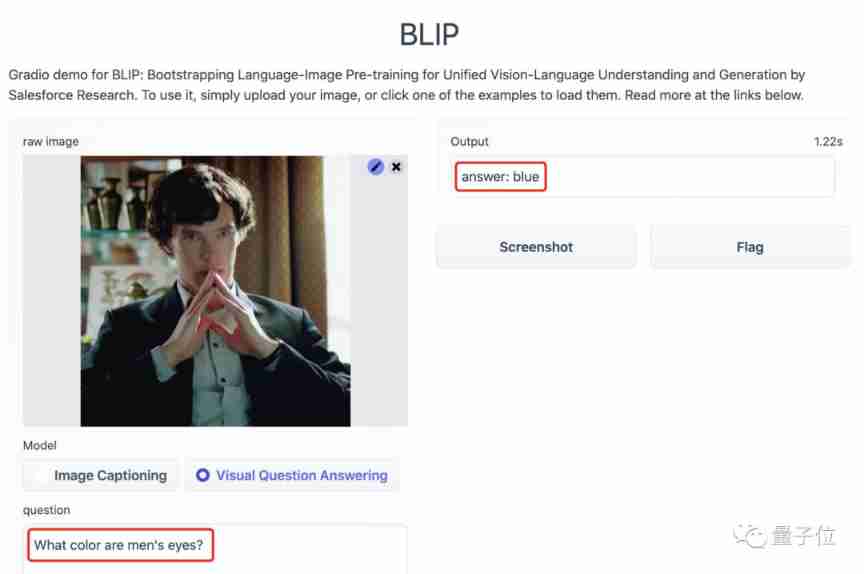
I have a good look , It's true !
This is vision - New achievements in the field of language :BLIP (Bootstrapping Language-Image Pre-training).
It is a breakthrough in the past that can only be implemented alone Vision - The text generated 、 Vision - Text understanding The two tasks are integrated , Give Way AI You can switch back and forth in the two modes of speaking with pictures and visual question and answer .
And his performance on various tasks is better than that in the past SOTA Method ,VQA Accuracy over 78%, Approaching the human baseline (80.83%).
Don't talk much , Let's try it , See how powerful this model is .
Demo demo
BLIP It can provide two functions .
The first is to describe the content of the picture , The second is to answer questions about pictures .
After uploading the picture , You can try one of the modes below the picture .

First, let's take a look at it Look at the picture What is the level of .
Uploaded a picture with children 、 cat 、 After the picture of various elements of dog , The output of the model is :
A little boy and a cat 、 A dog lay on the ground together .
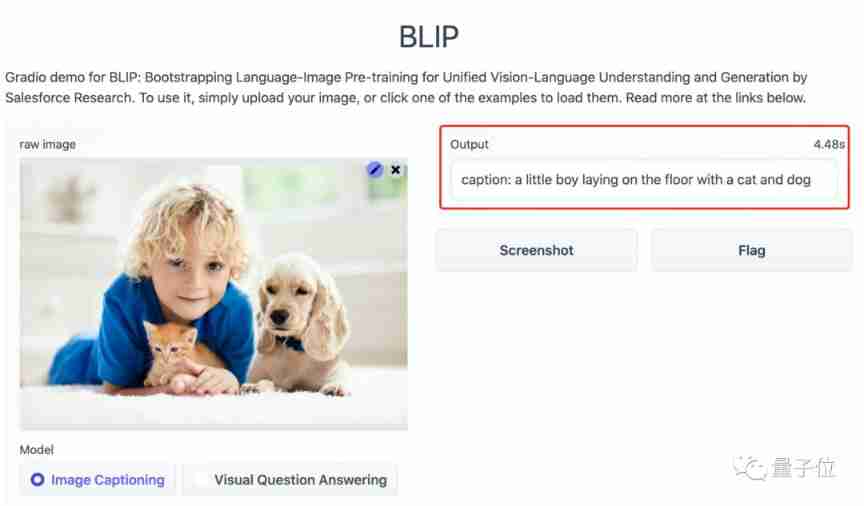
Try asking questions again :
The picture shows fish Do you ?
BLIP:NO.
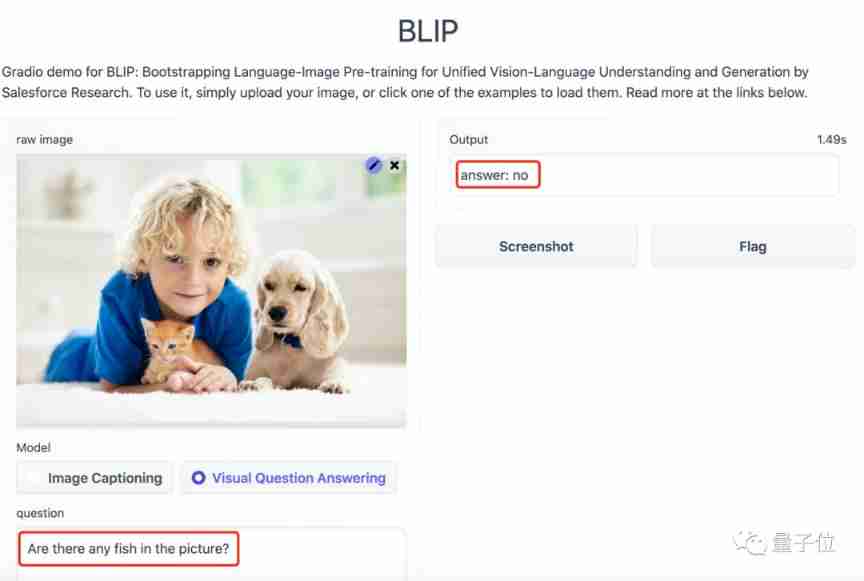
You can see ,BLIP The understanding of the picture is very good , Then how many more pictures ?
When we upload the portrait of Mona Lisa , The model easily identified that this is A portrait of a woman , It's not a photo .
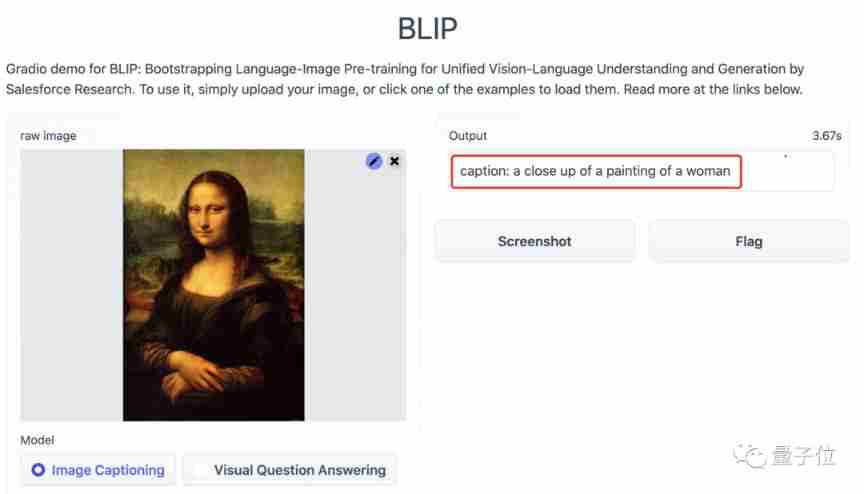
Even upload a spoof image of Altman , It's not difficult BLIP, And also gave a serious answer :
A man was carrying a cake with candles .
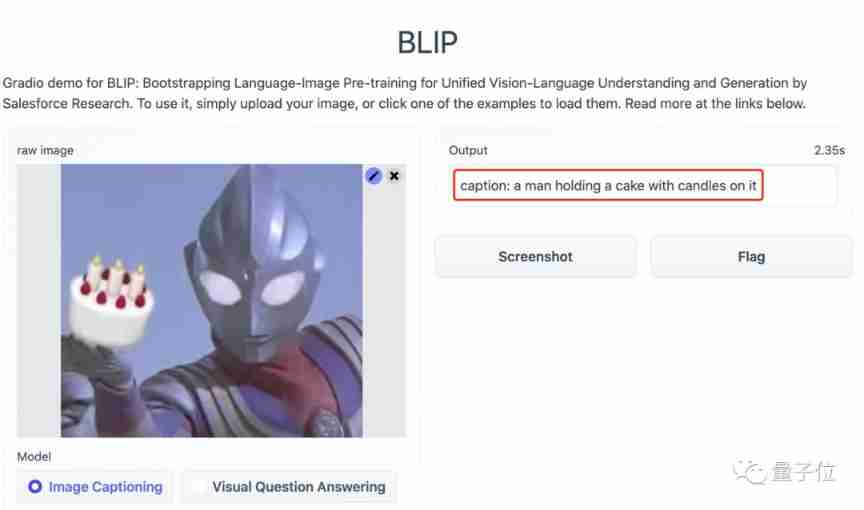
Even ask it : Is the cake on the man's left hand or right hand ?BLIP Can give the correct answer :
one 's right hand .

This wave of operation is true 6 It's me .
So what is the principle behind it ? Let's see .
Learn noisy images - The text is right
BLIP There are two aspects of work to be done this time .
First of all , It uses a Multitask model (MED), Integrate multiple task pre training .
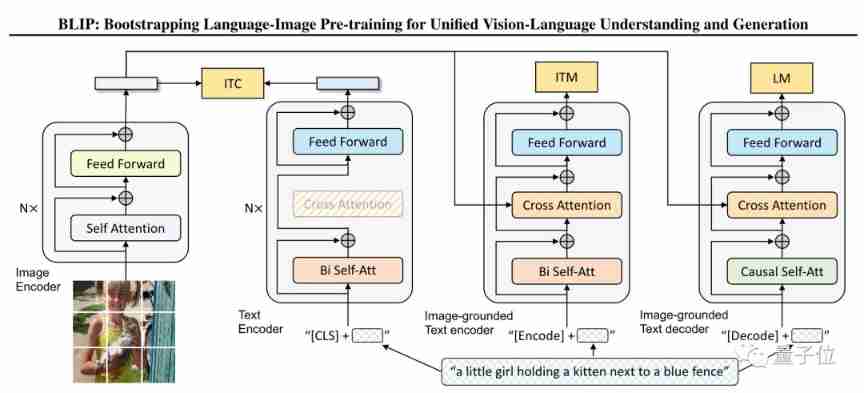
See from the frame diagram ,MED It mainly includes 3 Parts of :
Single peak encoder , Can use image - Text comparison loss (ITC) Training , Align visual and textual representations .
Image based text encoder , The traditional cross attention layer can be used to simulate vision - The transformation of language information , And through images - Text matching loss (ITM) To train , So as to distinguish positive 、 Negative image - The text is right .
Image based text decoder , The bidirectional self attention layer can be transformed into the causal self attention layer , And share the same cross attention layer and feedforward network with the encoder . The decoder is trained through language modeling (LM) To output text annotations .
thus , The model can execute images - Text contrast 、 Images - Text matching and image language generation tasks .
In the second , The researchers proposed a new type Data bootstrap method (CapFilt). It can make the model from the image with noise - Text centered learning .
CapFilt It mainly includes Taggers (captioner) and filter (filter) Two parts .
among , The annotator is used to generate text that describes the image , The filter will eliminate the results with noise .

For example, the following examples , It is the filter that rejects the wrong answer .

Studies have shown that , The more diverse the text the annotator lists , The better the final effect .
Compared with previous achievements SOTA Compared with ,BLIP In the image - Text retrieval task [email protected] On average, it's up 2.7%; In the picture generation text ,CIDEr promote 2.8%, The score of visual question and answer has improved 1.6%.
The corresponding author is Tsinghua alumni
The corresponding author of this study is Xu Zhuhong (Steven C.H. Hoi).

He is also currently employed in Salesforce Asian Institute . Previously, he was a professor at the school of information systems, National University of Singapore .
2002 year , Xu Zhuhong received his bachelor's degree from the Department of computer science of Tsinghua University . On 2004 year 、2006 He obtained a master's degree in computer science and engineering from the University of Hong Kong in 、 doctorate .
2019 Elected in IEEE Fellow. The main research fields are computer vision 、NLP、 Deep learning, etc .
The first author is Junnan Li.

He is now Salesforce Senior research scientist of Asian Academy .
Graduated from the University of Hong Kong , Ph.D. from National University of Singapore .
The research field is very extensive , Including self supervised learning 、 Semi-supervised learning 、 Weak supervised learning 、 The migration study 、 Vision - Language .
The other two authors are also Chinese , Namely Dongxu Li and Caiming Xiong.
Address of thesis :
https://arxiv.org/abs/2201.12086
Trial address :
https://huggingface.co/spaces/akhaliq/BLIP
GitHub Address :
https://github.com/salesforce/BLIP
边栏推荐
- Typora installation package sharing
- 2837xd code generation - Summary
- 【UE5】AI随机漫游蓝图两种实现方法(角色蓝图、行为树)
- Failed to configure a DataSource: ‘url‘ attribute is not specified and no embedd
- High level application of SQL statements in MySQL database (II)
- Error reporting on the first day of work (error reporting when Nessus installs WinPcap)
- C语言之分草莓
- ZK configuration center -- configuration and use of config Toolkit
- How to install PHP in CentOS
- MySQL default transaction isolation level and row lock
猜你喜欢

记录一下初次使用Xray的有趣过程

三相逆变器离网控制——PR控制

Bugkuctf-web21 (detailed problem solving ideas and steps)

2837xd code generation - Supplement (3)
2837xd code generation - stateflow (2)

Error reporting on the first day of work (incomplete awvs unloading)
YOLO物体识别,生成数据用到的工具

Navicat remote connection MySQL reports an error 1045 - access denied for user 'root' @ '222.173.220.236' (using password: yes)
图像识别-数据采集

TD conducts functional simulation with Modelsim
随机推荐
Is the C language too fat
渗透测试的介绍和防范
Read Day5 30 minutes before going to bed every day_ All key values in the map, how to obtain all value values
Image recognition - Data Acquisition
web安全与防御
2837xd代码生成模块学习(1)——GPIO模块
Record personal understanding and experience of game console configuration
Tinyxml2 reading and modifying files
攻防世界-Web进阶区-unserialize3
C language strawberry
Data insertion in C language
Skywalking theory and Practice
滲透測試的介紹和防範
int与string、int与QString互转
【UE5】AI随机漫游蓝图两种实现方法(角色蓝图、行为树)
BugkuCTF-web16(备份是个好习惯)
JDBC review
2837xd 代码生成——总结篇
Matlab代码生成之SIL/PIL测试
About the college entrance examination