当前位置:网站首页>[pytorch practice] write poetry with RNN
[pytorch practice] write poetry with RNN
2022-07-07 12:34:00 【Sickle leek】
use RNN Writing a poem
1. background
natural language processing (Natural Language Processing, NLP) It's a branch of artificial intelligence and linguistics , The research direction involved is broad , Including machine translation 、 Syntactic parsing 、 Information retrieval, etc . Here we review two basic concepts : The word vector (word vector) and Cyclic neural network (Recurrent Neural Network,RNN).
1.1 The word vector
Natural language processing mainly studies language information , Language is made up of words and characters , Language can be transformed into a set of words or words . For convenience , Always use One-Hot Coding format , This method solves the problem that the classifier is difficult to deal with attributes (Categorical) Data problems , The disadvantage is too much redundancy , Unable to reflect the relationship between words . And in deep learning , Dimensional disasters often occur , So in deep learning, we use the expression form of word vector .
The word vector (Word Vector), Also known as Word embedding (Word Embedding). Conceptually , It refers to a high-dimensional space in which a dimension is the number of all words ( Tens of thousands of words , Hundreds of thousands of words ) Embedded into a much lower dimension continuous vector space ( Usually 128 perhaps 256 dimension ), Each word or phrase is mapped to a vector on a real field .
Word vectors are trained by special methods , for example GloVe. here , The most important feature of word vectors is that the word vectors of similar words are close . The word vector dimension of each word is fixed , Each dimension is a continuous number .
stay PyTorch in , There is a special layer for word vectors nn.Embedding, be used for Realize the mapping between words and word vectors .nn.Embedding Have a weight , The shape is (num_words, embedding_dim).
Embedding The input shape for is N×W,N yes batch size, W It's the length of the sequence , The output shape is N×W×embedding_dim. The input must be LongTensor, FloatTensor adopt tensor.long() Method is converted to LongTensor.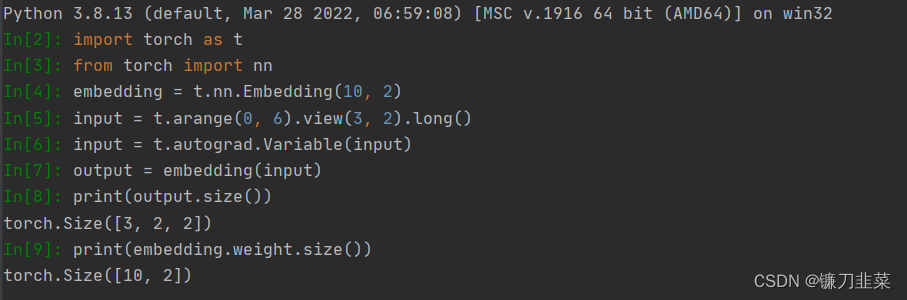
Be careful :Embedding The weight of can also be trained , Random initialization can be used , Pre trained word vectors can also be used to initialize .
1.2 RNN
RNN, It can solve the problem of dependence between words , By using the state of the previous word every time (hidden state) Combine with the current word to calculate the new state . The network structure is shown in the figure below :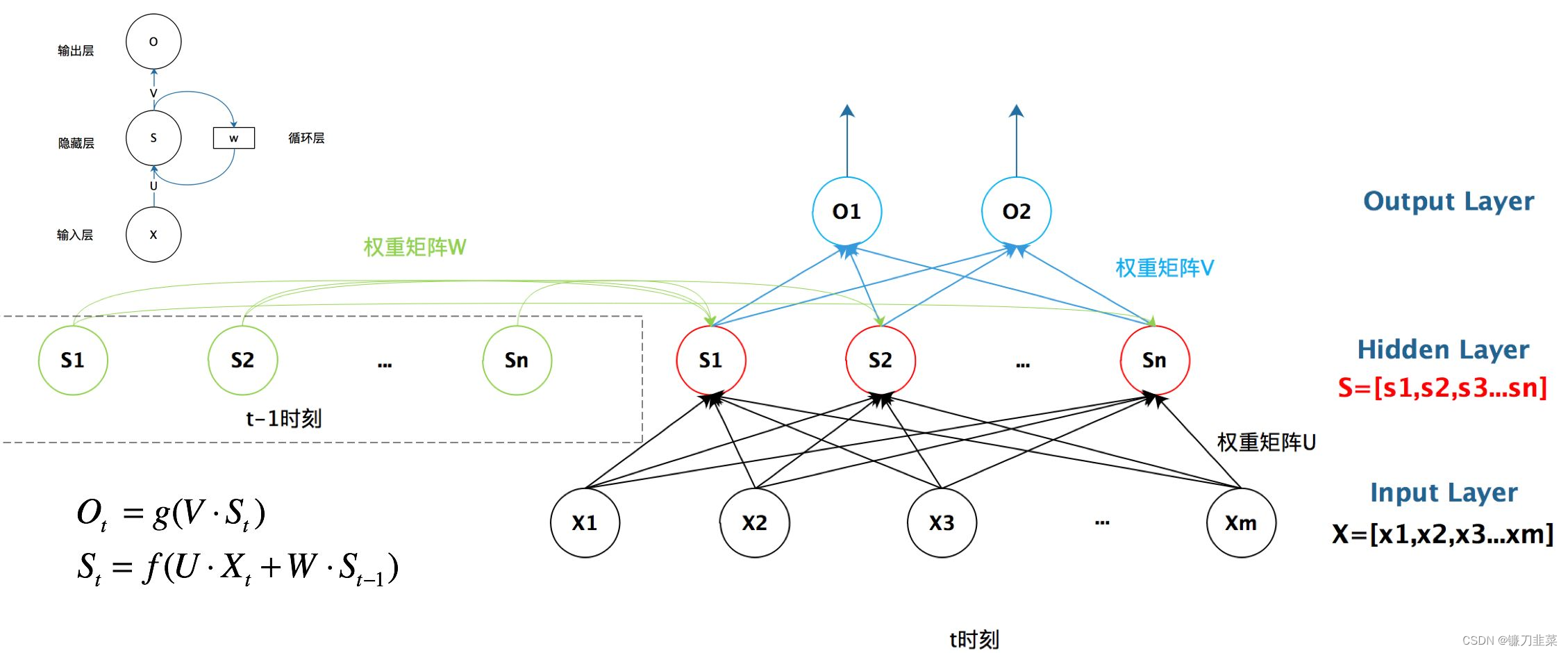
- x 1 , x 2 , x 3 , . . . , x T x_1,x_2,x_3,...,x_T x1,x2,x3,...,xT: Enter the sequence of words ( share T Word ), Every word is a vector , It is usually expressed by word vectors .
- S 0 , S 1 , S 2 , S 3 , . . . S T S_0,S_1,S_2,S_3,...S_T S0,S1,S2,S3,...ST: Hidden layer element ( share T+1 individual ), Each hidden element is calculated from the previous word , So you can think of information that includes all the previous words . S 0 S_0 S0 Indicates the initial information , Generally, all 0 Initializes the vector of .
- f f f: Conversion function , According to the current input X t X_t Xt And the state of the previous hidden element ( S t − 1 S_{t-1} St−1), Calculate the new hidden meta state S t S_t St. It can be said that S t − 1 S_{t-1} St−1 Before inclusion t − 1 t-1 t−1 A word of information , namely x 1 , x 2 , . . . , x t − 1 x_1,x_2,...,x_{t-1} x1,x2,...,xt−1, from f f f utilize S t − 1 S_{t-1} St−1 and x t x_t xt Calculated S t S_t St, It can be considered as including t A word of information . It should be noted that , Every calculation S t S_t St All with the same f f f. f f f It is generally a matrix multiplication operation .
RNN Finally, the information of all hidden elements will be output , Generally, only the information of the last hidden element is used , It can be considered that it contains the information of the whole sentence .
But this structure RNN Have serious The gradient disappears and Gradient explosion problem , It's hard to train . At present, in-depth learning, a common method called LSTM Of RNN structure .LSTM(Long Short Term Meomory Network, Long and short term memory network ), As shown in the figure below :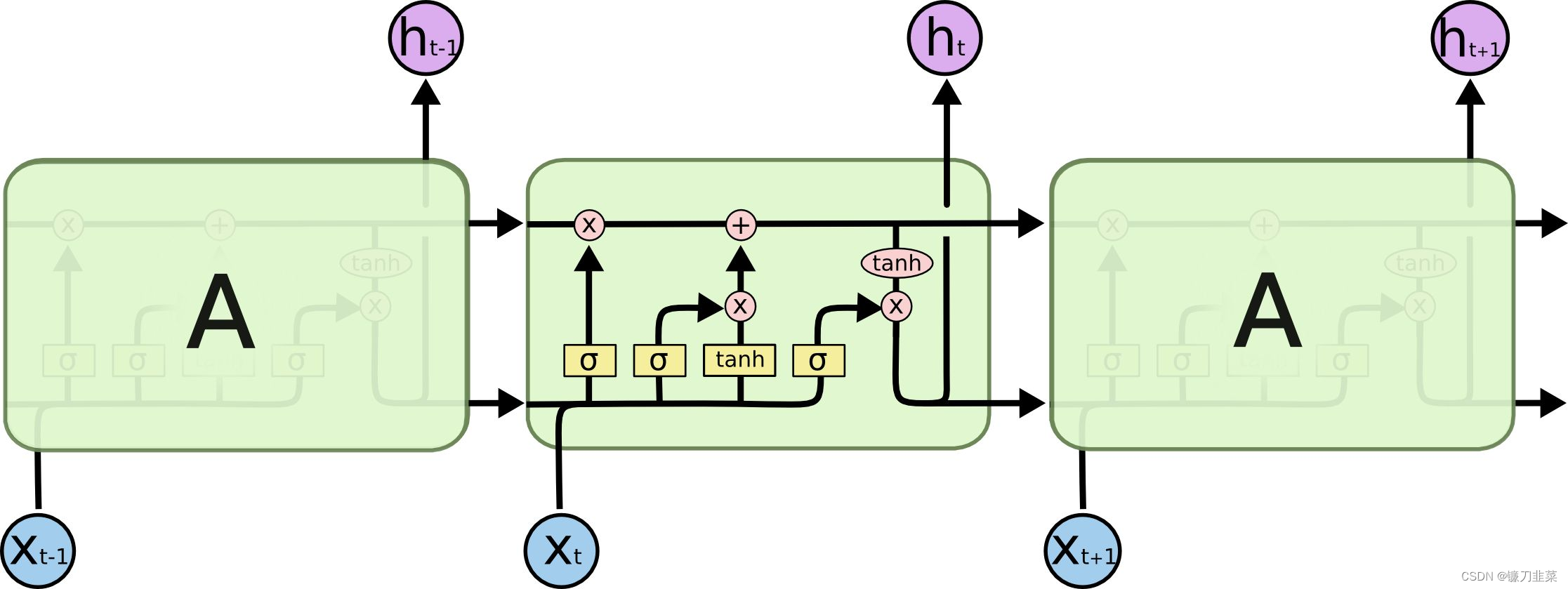
LSTM It is also by constantly using the previous state and the current input to calculate the new state , But its f Functions are more complex , In addition to hiding meta States (hidden state h), also cell state c. Every LSTM There are two outputs of the unit , One is the following h t h_t ht( h t h_t ht At the same time, it is led to the top by creating branches ), One is above c t c_t ct. c t c_t ct The existence of can well suppress the problems of gradient disappearance and gradient explosion .
problem 1:LSTM How to realize the long-term and short-term memory function ?
answer : With the traditional RNN comparison ,LSTM Although still based on x t x_t xt and h t − 1 h_{t-1} ht−1 To calculate h t h_t ht, It's just that the internal structure is more carefully designed , The input gate is added i i i、 Oblivion gate f t f_t ft And output gate o t o_t ot Three doors and an internal memory unit c t c_t ct.
Input gateControls how much the new state of the current calculation is updated into the memory unit ;Oblivion gateControl how much information in the previous memory unit is forgotten ;Output gateHow much control the current output depends on the current memory unit .
classical LSTM in , The first t The updated calculation formula of step is :
i t = σ ( W i x t + U i h t − 1 + b i ) i_t=\sigma (W_ix_t+U_ih_{t-1}+b_i) it=σ(Wixt+Uiht−1+bi)
f t = σ ( W f x t + U f h t − 1 + b f ) f_t=\sigma (W_fx_t+U_fh_{t-1}+b_f) ft=σ(Wfxt+Ufht−1+bf)
o t = σ ( W o x t + U o h t − 1 + b o ) o_t=\sigma (W_ox_t+U_oh_{t-1}+b_o) ot=σ(Woxt+Uoht−1+bo)
c ~ t = T a n h ( W c x t + U c h t − 1 ) \widetilde{c}_t=Tanh(W_cx_t+U_ch_{t-1}) ct=Tanh(Wcxt+Ucht−1)
c t = f t ⊙ c t − 1 + i t ⊙ c ~ t c_t=f_t\odot c_{t-1}+i_t\odot \widetilde{c}_t ct=ft⊙ct−1+it⊙ct
h t = o t ⊙ T a n h ( c t ) h_t=o_t\odot Tanh(c_t) ht=ot⊙Tanh(ct)
among , i t i_t it It's through input x t x_t xt And the hidden layer output of the previous step h t − 1 h_{t-1} ht−1 Make a linear transformation , After activating the function σ \sigma σ Got . Input gate i t i_t it The result is a vector , Each of these elements is 0 To 1 The real number between , It is used to control the amount of information flowing through the valve in each dimension ; W i W_i Wi, U i U_i Ui Two matrices and vectors b i b_i bi Enter the parameters of the door , It needs to be learned in the process of training . Oblivion gate f t f_t ft And the output gate o t o_t ot The calculation method is similar to that of the input gate , They have their own parameters W W W、 U U U and b.
With the traditional RNN The difference is , From the state of the previous memory unit c t − 1 c_{t-1} ct−1 To the current state c t c_t ct The transition of does not necessarily depend entirely on the state calculated by the activation function , It is also controlled by the input gate and the forgetting gate .
In a trained network , When there is no important information in the input sequence ,LSTM The value of the forgetting gate is close to 1, The value of the input gate is close to 0, At this time, the memory of the past will be preserved , Thus, the long-term memory function is realized ; When important information appears in the input sequence .,LSTM It should be stored in memory , At this time, the value of its input gate will be close to 1; When important information appears in the input sequence , And this information means that the previous memory is no longer important , The value of the input door is close to 1, The value of forgetting gate is close to 0, So old memories are forgotten , New important information is remembered . After this design , The whole network is easier to learn the long-term dependence between sequences .
problem 2:LSTM What activation functions are used in each module , Can I use another activation function ?
answer : About the selection of activation function , stay LSTM in , Oblivion gate 、 Input gate and output gate use Sigmoid Function as activation function ; When generating candidate memory , Use hyperbolic tangent function Tanh As an activation function . It is worth noting that , Both activation functions are Saturated , in other words When the input reaches a certain value , The output will not change significantly 了 .
If it's an unsaturated activation function , for example ReLU, It will be difficult to achieve the effect of door control .
- Sigmoid The output of the function is in 0~1 Between , Meet the physical definition of gating . And when the input is large or small , Its output will be very close to 1 perhaps 0, To ensure that the door is open or closed .
- When generating candidate memory , Use Tanh function , Because its output is in -1~1 Between , This distribution of features in most scenes is 0 The fit of the center . Besides ,Tanh The input of the function is 0 Compared with nearby Sigmoid The function has a larger gradient , Usually make the model converge faster .
The choice of activation function is not immutable . For example, in the original LSTM in , The activation function used is Sigmoid A variation of a function , h ( x ) = 2 s i g m o i d ( x ) − 1 , g ( x ) = 4 s i g m o i d ( x ) − 2 h(x)=2sigmoid(x)-1, g(x)=4sigmoid(x)-2 h(x)=2sigmoid(x)−1,g(x)=4sigmoid(x)−2, The ranges of these two functions are [-1, 1] and [-2, 2]. And in the original LSTM in , Only input gate and output gate , There is no forgetting door , The input is directly added to the memory after passing through the input gate , So input gating g ( x ) g(x) g(x) The value of is 0 Central .
Later, experiments showed that , Add forgotten pairs LSTM The performance of has been greatly improved , also h ( x ) h(x) h(x) Use Tanh Than 2 ∗ s i g m o i d ( x ) − 1 2\ast sigmoid(x)-1 2∗sigmoid(x)−1 It is better to , So modern LSTM use Sigmoid and Tanh As an activation function . in fact , In gating , Use Sigmoid Function is the common choice of almost all modern neural network modules . For example, in the gating cycle unit and attention mechanism , It is also widely used Sigmoid Function as the activation function of gating .
Besides , In some devices with limited computing power , For example, in wearable devices , because Sigmoid Finding the exponent of a function requires a certain amount of calculation , The 0 / 1 0/1 0/1 door (hard gate) Let the door empty output be 0 or 1 Discrete values of , That is, when the input is less than the threshold, the gating output is 0; When the input is greater than At threshold , Output is 1. Thus, when the performance degradation is not significant , Reduce computation .
classical LSTM When calculating each door control , Usually use input x t x_t xt And hidden layer output h t − 1 h_{t-1} ht−1 Participate in door control calculation , For example, input Door update : i t = σ ( W i x t + U i h t − 1 + b i ) i_t=\sigma (W_ix_t+U_ih_{t-1}+b_i) it=σ(Wixt+Uiht−1+bi). The most common variant is the addition of Peephole mechanism , Let memory c t − 1 c_{t-1} ct−1 Also participate in the calculation of door control , At this time, the update method of the input door changes to :
i t = σ ( W i x t + U i h t − 1 + V i c t − 1 + b i ) i_t=\sigma (W_ix_t +U_ih_{t-1}+V_ic_{t-1}+b_i) it=σ(Wixt+Uiht−1+Vict−1+bi)
In a Pytorch Use in LSTM An example of :
# -*- coding: utf-8 -*-#
# ----------------------------------------------
# Name: LSTMdemo.py
# Description:
# Author: PANG
# Date: 2022/6/27
# ----------------------------------------------
import torch as t
from torch import nn
from torch.autograd import Variable
# Input words with 10 Dimension word vector represents
# Hidden layer element 20 The dimension vector represents
# Two tier lstm
rnn = nn.LSTM(10, 20, 2)
# Input every sentence with 5 Word
# Every word has 10 The word vector of dimension represents
# All in all 3 Sentence (batch size)
input = Variable(t.randn(5, 3, 10))
# 1 A hidden yuan (hidden state and cell state) The initial value of the
# shape (num_layers, batch_size, hidden_size)
h0 = Variable(t.zeros(2, 3, 20))
c0 = Variable(t.zeros(2, 3, 20))
# output Is the value of all hidden elements in the last layer
# hn and cn All layers ( There are two layers here ) The value of the last hidden element of
output, (hn, cn) = rnn(input, (h0, c0))
print(output.size())
print(hn.size())
print(cn.size())
# Output
torch.Size([5, 3, 20])
torch.Size([2, 3, 20])
torch.Size([2, 3, 20])
Be careful :output The shape and shape of LSTM Independent of the number of layers , Only related to sequence length , and hn and cn On the contrary .
except LSTM, PyTorch There is also LSTMCell.LSTM Yes, one. LSTM The abstraction of layers , It can be seen as being made up of multiple LSTMCell form . While using LSTMCell You can perform more refined operations .LSTM There is also a variant called GRU(Gated Recurrent Unit), Compare with LSTM,GRU Faster , The effect is also close . Scenes with strict speed requirements can be used GRU.
2. CharRNN
CharRNN The author is Andrej karpathy.CharRNN Learn English letters from massive texts ( Be careful , It's the letters , It's not a word ) The combination of , And can automatically generate the corresponding text .
CharRNN The principle is very simple , It is divided into two parts: training and generation . The training is shown in the figure below :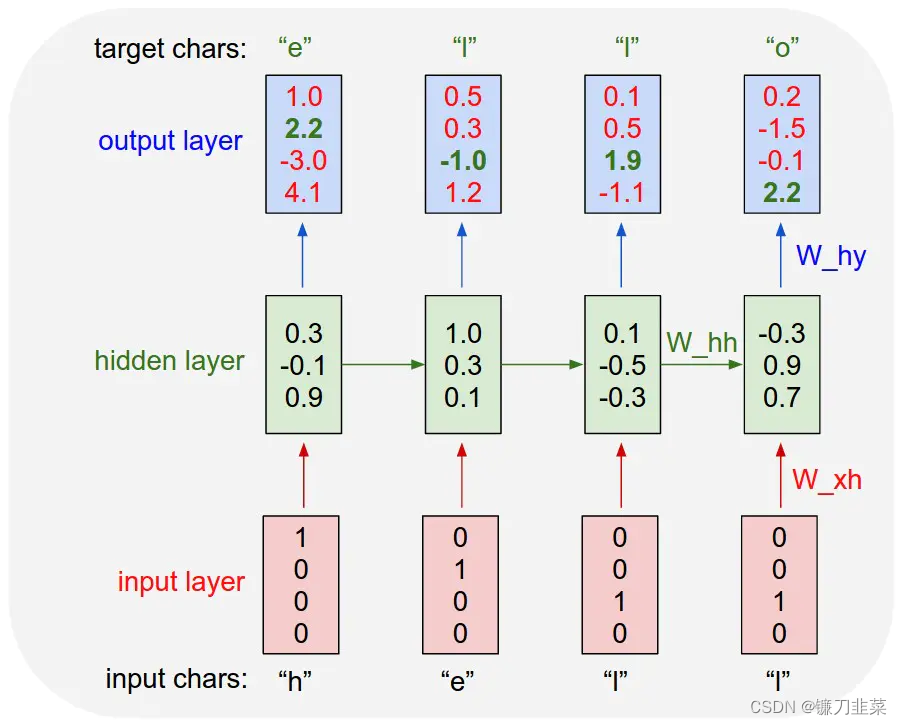
The picture above shows Char-RNN Principle . In order to let the model learn to write “hello” For example ,Char-RNN The input and output layers of are In characters . Input “h”, The output should be “e”; Input “e”, You should output the following “l”. Input layer we can use only one element as 1 To encode different characters , for example ,h Encoded as “1000”、“e” Encoded as “0100”, and “l” Encoded as “0010”.
Use RNN The goal of learning is , The next character generated can be as consistent as possible with the target output in the training sample . In the example in Figure 1 , Based on the state generated by the first two characters and the third input “l” The predicted vector of the next character is <0.1, 0.5, 1.9, -1.1>, The largest one is the third , The corresponding character is “0010”, Is precisely “l”. This is a correct prediction . But from the first “h” The output vector is the fourth largest , The corresponding is not “e”, So there's a price to pay . The process of learning is to reduce the cost . The learned model , For any input character, you can predict the next character very well , In this way, sentences or paragraphs can be generated .
As mentioned above ,CharRNN It can be regarded as a classification problem : According to the current character , Predict the next character . For English characters , The total amount used in the text is no more than 128 Characters ( The assumption is 128 Characters ), So the prediction problem can be changed to 128 Classification problem : Put the output of each hidden element , Input to a full connection layer , The calculated output belongs to 128 The probability of two characters , Calculate the cross entropy loss .
All in all ,CharRNN Predict the next word by using the hidden meta state of the current word , Turn the generation problem into a classification problem .
After training , You can use the network to generate text to write poetry and scripts . The generation steps are as follows :
- First enter a starting character ( It's usually used <start> identification ), Calculate the probability that the output belongs to each character .
- Select the character with the highest probability as the output .
- Take the output of the previous step as the input , Continue to input into the network , Calculate the probability that the output belongs to each character
- …
Finally, all words will be spliced together , Get the final generation result . Of course ,CharRNN There are also some lack of rigor , For example, it uses One-hot code , Not word vectors , Use RNN instead of LSTM.
3. use PyTorch Realization CharRNN
The data set used in the experiment is Github Collected by Chinese poetry lovers on 5 The original text of ten thousand Tang poems , And integrate into one numpy The package tang.npz, It contains three objects :
- data: (57580, 125) Of numpy Array , share 57580 A poem , The length of each poem is 125 Characters ( Insufficient 125 Fill in the blanks , exceed 125 Discarded by ).
- word2ix: Each word and its corresponding serial number
- ix2word: Each serial number and its corresponding word
among ,data The processing steps of poetry are as follows :
- First convert the poem into list, And add the start character before and after <start> And terminator <end>.
- For lengths less than 125 A poem of characters , Fill in the blanks before ( use </\s> Express ), Until the length reaches 125.
- For lengths over 125 Poetry of characters , Cut off the ending words .
- Convert each word into the corresponding serial number .
- Put the serial number list Turn into numpy Array .
After the data is processed , The document organization of this experiment is as follows :
data.py
main.py
model.py
tang.npz
utils.py
Some of the more important documents are as follows :
- main.py: Including program configuration 、 Training and generation .
- model.py: Model definition .
- utils.py: Visualization tools visdom Encapsulation .
- tang.npz: take 5 More than 10000 Tang poems have been pretreated into numpy data .
- data.py: Preprocess the original Tang poetry text , If used directly tang.npz, You don't need to be right json Data processing .
The main configuration options and command line parameters in the program are as follows
class Config(object):
data_path = 'data/' # Text file storage path of poetry
pickle_path = 'tang.npz' # Preprocessed binary file
author = None # Only learn the poems of one author
constrain = None # Length limit
category = 'poet.tang' # Category , Tang poetry or song poetry (poet.song)
lr = 1e-3
weight_decay = 1e-4
use_gpu = True
epoch = 20
batch_size = 128
maxlen = 125 # Words exceeding this length are discarded , If it is less than this length, fill in the space in front of it
plot_every = 20 # Every time 20 individual batch Visualize once
# use_env = True # Whether to use visodm
env = 'poetry' # visdom env
max_gen_len = 200 # Maximum length of generated poetry
debug_file = 'debug/debug.txt'
model_path = None # Pre training model path
prefix_words = ' Fish come out in the drizzle , Breeze swallow slant .' # Not part of poetry , Used to control the artistic conception of poetry
start_words = ' The shadow of the idle cloud pool is long ' # Poetry begins
acrostic = False # Is it a hidden poem
model_prefix = 'checkpoints/tang' # Model save path
stay data.py There are three main functions in :
- _parseRawData: Analyze the original json data , Extract into list.
- pad_sequences: Truncate or supplement data of different lengths to the same length .
- get_data: The interface called by the main program . If the binary file exists , Then directly read binary numpy file ; Otherwise, read the text file for processing , And save the processing results into binary files .
among get_data The function code is as follows :
def get_data(opt):
""" :param opt: configuration option ,Config object :return: data: numpy Array , Each line is the subscript of the word corresponding to a poem """
if os.path.exists(opt.pickle_path):
data = np.load(opt.pickle_path, allow_pickle=True)
data, word2ix, ix2word = data['data'], data['word2ix'].item(), data['ix2word'].item()
return data, word2ix, ix2word
# If there is no processed binary file , Then deal with the original json file
data = _parseRawData(opt.author, opt.constrain, opt.data_path, opt.category)
words = {
_word for _sentence in data for _word in _sentence}
word2ix = {
_word: _ix for _ix, _word in enumerate(words)}
word2ix['<EOP>'] = len(word2ix) # Termination identifier
word2ix['<START>'] = len(word2ix) # Start identifier
word2ix['</s>'] = len(word2ix) # Space
ix2word = {
_ix: _word for _word, _ix in list(word2ix.items())}
# Add start and end symbols to each poem
for i in range(len(data)):
data[i] = ["<START>"] + list(data[i]) + ["<EOP>"]
# Save the contents of each poem by ‘ word ’ become ‘ Count ’
# Form like [ In the spring , jiang , flowers , month , night ] become [1,2,3,4,5]
new_data = [[word2ix[_word] for _word in _sentence] for _sentence in data]
# The poem is not long enough opt.maxlen Fill in the blank in front of , More than , Delete... At the end
pad_data = pad_sequences(new_data, maxlen=opt.maxlen, padding='pre', truncating='post', value=len(word2ix) - 1)
# Save as binary file
np.savez_compressed(opt.pickle_path, data=pad_data, word2ix=word2ix, ix2word=ix2word)
return pad_data, word2ix, ix2word
The code of model construction is saved in model.py in , The code is as follows :
import torch
import torch.nn as nn
import torch.nn.functional as F
class PoetryModel(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
super(PoetryModel, self).__init__()
self.hidden_dim = hidden_dim
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, self.hidden_dim, num_layers=2)
self.linear1 = nn.Linear(self.hidden_dim, vocab_size)
def forward(self, input, hidden=None):
seq_len, batch_size = input.size()
if hidden is None:
# 2 Because there are two layers LSTM
h_0 = input.data.new(2, batch_size, self.hidden_dim).fill_(0).float()
c_0 = input.data.new(2, batch_size, self.hidden_dim).fill_(0).float()
else:
h_0, c_0 = hidden
# size: (seq_len, batch_size, embeding_dim)
embeds = self.embeddings(input)
# output size: (seq_len, batch_size, hidden_dim)
output, hidden = self.lstm(embeds, (h_0, c_0))
# size: (seq_len*batch_size, vocab_size)
output = self.linear1(output.view(seq_len * batch_size, -1))
return output, hidden
To make a long story short , The sequence number of the entered words goes through nn.Embedding Get the corresponding word vector representation , Then use two layers LSTM Extract the information of all hidden elements of the word , Then use the information of hidden elements to classify , Judge the probability that the output belongs to each word .
The training related code is saved in main.py in :
def train(**kwargs):
for k, v in kwargs.items():
setattr(opt, k, v)
opt.device = t.device('cuda') if opt.use_gpu else t.device('cpu')
device = opt.device
vis = Visualizer(env=opt.env)
# get data
data, word2ix, ix2word = get_data(opt)
data = t.from_numpy(data)
dataloader = t.utils.data.DataLoader(data, batch_size=opt.batch_size, shuffle=True, num_workers=1)
# Model definition
model = PoetryModel(len(word2ix), 128, 256)
optimizer = t.optim.Adam(model.parameters(), lr=opt.lr)
criterion = nn.CrossEntropyLoss()
if opt.model_path:
model.load_state_dict(t.load(opt.model_path))
model.to(device)
loss_meter = meter.AverageValueMeter()
for epoch in range(opt.epoch):
loss_meter.reset()
for ii, data_ in tqdm.tqdm(enumerate(dataloader)):
# Training
data_ = data_.long().transpose(1, 0).contiguous()
data_ = data_.to(device)
optimizer.zero_grad()
# The way to achieve dislocation
# The former includes from 0 Words until the last word ( It doesn't contain ), The latter is the first word to the end ( Including the last word )
input_, target = data_[:-1, :], data_[1:, :]
output, _ = model(input_)
loss = criterion(output, target.view(-1))
loss.backward()
optimizer.step()
loss_meter.add(loss.item())
# visualization
if (1 + ii) % opt.plot_every == 0:
if os.path.exists(opt.debug_file):
ipdb.set_trace()
vis.plot('loss', loss_meter.value()[0])
# The original poem
poetrys = [[ix2word[_word] for _word in data_[:, _iii].tolist()] for _iii in range(data_.shape[1])][:16]
vis.text('</br>'.join([''.join(poetry) for poetry in poetrys]), win=u'origin_poem')
gen_poetries = []
# Take these words as the first word of the poem , Generate 8 A poem
for word in list(u' The moonlight on the spring river is as cool as water '):
gen_poetry = ''.join(generate(model, word, ix2word, word2ix))
gen_poetries.append(gen_poetry)
vis.text('</br>'.join([''.join(poetry) for poetry in gen_poetries]), win=u'gen_poem')
t.save(model.state_dict(), '%s_%s.pth' % (opt.model_prefix, epoch))
(1) Given the first few words of the poem , Continue writing poetry .
def generate(model, start_words, ix2word, word2ix, prefix_words=None):
""" Given a few words , Based on these words, a complete poem is generated start_words:u' The spring tide is even with the sea ' such as start_words by The spring tide is even with the sea , Can generate : """
results = list(start_words)
start_word_len = len(start_words)
# Manually set the first word to <START>
input = t.Tensor([word2ix['<START>']]).view(1, 1).long()
if opt.use_gpu: input = input.cuda()
hidden = None
if prefix_words:
for word in prefix_words:
output, hidden = model(input, hidden)
input = input.data.new([word2ix[word]]).view(1, 1)
for i in range(opt.max_gen_len):
output, hidden = model(input, hidden)
if i < start_word_len:
w = results[i]
input = input.data.new([word2ix[w]]).view(1, 1)
else:
top_index = output.data[0].topk(1)[1][0].item()
w = ix2word[top_index]
results.append(w)
input = input.data.new([top_index]).view(1, 1)
if w == '<EOP>':
del results[-1]
break
return results
(2) Generate hidden poems
def gen_acrostic(model, start_words, ix2word, word2ix, prefix_words=None):
""" Generate hidden poems start_words : u' Deep learning ' Generate : Shenmutong Zhongyue , Moss semidiurnal fat . Du Shan Fen Di Insurance , Go against the waves to Nanba . Learning from Taoist soldiers is still poisonous , At that time, Yan Buyi . Xi Gen Tong Gu'an , Open the mirror to reveal Qing Lei . """
results = []
start_word_len = len(start_words)
input = (t.Tensor([word2ix['<START>']]).view(1, 1).long())
if opt.use_gpu: input = input.cuda()
hidden = None
index = 0 # Used to indicate how many hidden poems have been generated
# Last word
pre_word = '<START>'
if prefix_words:
for word in prefix_words:
output, hidden = model(input, hidden)
input = (input.data.new([word2ix[word]])).view(1, 1)
for i in range(opt.max_gen_len):
output, hidden = model(input, hidden)
top_index = output.data[0].topk(1)[1][0].item()
w = ix2word[top_index]
if (pre_word in {
u'.', u'!', '<START>'}):
# If you encounter a period , Hidden words are sent in to generate
if index == start_word_len:
# If the generated poetry already contains all hidden words , End
break
else:
# Put the hidden words into the model as input
w = start_words[index]
index += 1
input = (input.data.new([word2ix[w]])).view(1, 1)
else:
# Otherwise , Input the last predicted word as the next word
input = (input.data.new([word2ix[w]])).view(1, 1)
results.append(w)
pre_word = w
return results
4. Result analysis
First , perform python -m visdom.server start-up visdom Visual interface
(1) python main.py train --plot-every=150 --batch-size=8 --pickle-path='tang.npz' --lr=1e-3 --env='poetry3' --epoch=50 --num_workers=0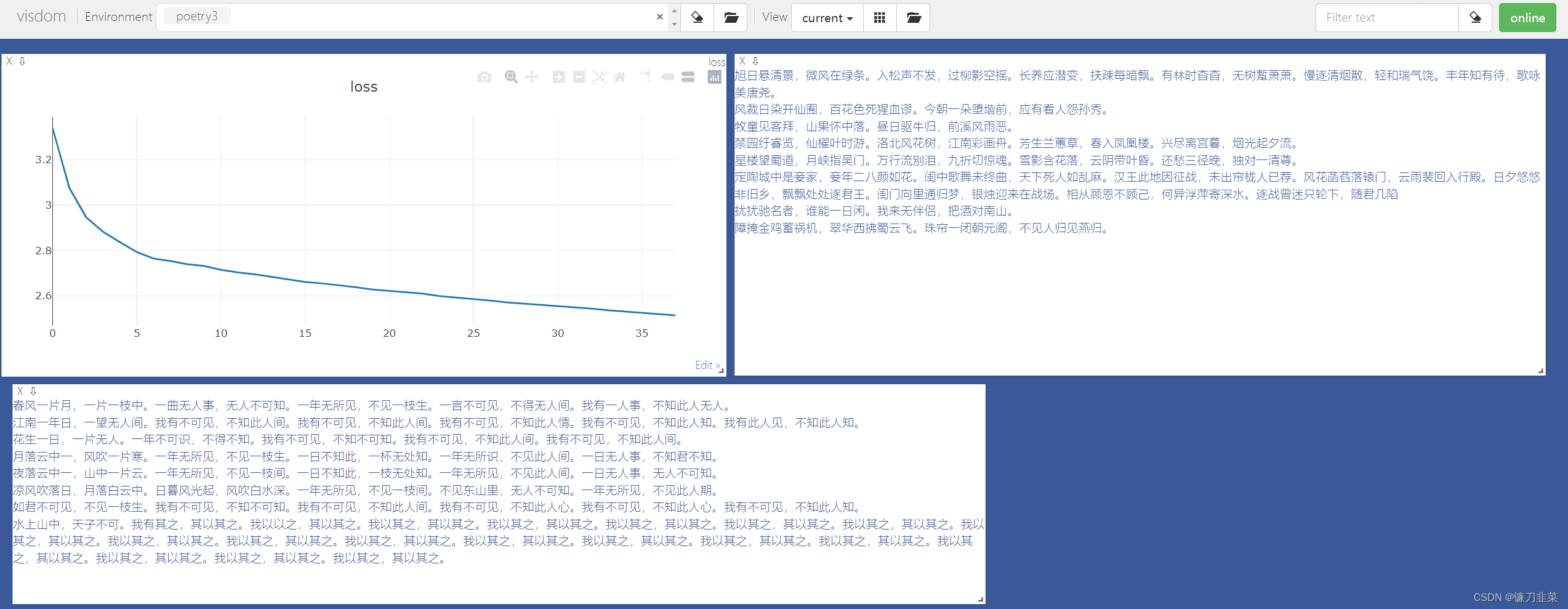
(2) Make a poem ( Specify the beginning 、 Specify artistic conception and rhyme )python main.py gen --model-path='checkpoints/tang_49.pth' --start-words=' Alone sail, far shadow, blue sky ,' --prefix-words=' Leaving at dawn the White King crowned with rainbow cloud , I have sailed a thousand miles through Three Georges in a day .'
(3) Generate a hidden poem ( Specify hidden head , Specify artistic conception rules )python main.py gen --model-path='checkpoints/tang_49.pth' --acrostic=True --start-words=' Deep learning ' --prefix-words=' Lonely smoke straight in the desert , Long river falling yen .'
Reference material
[1] Char RNN Principle introduction and text generation practice
[2] ordinary Char RNN The generation of textual
边栏推荐
- Dialogue with Wang Wenyu, co-founder of ppio: integrate edge computing resources and explore more audio and video service scenarios
- 【统计学习方法】学习笔记——第四章:朴素贝叶斯法
- Cenos openssh upgrade to version 8.4
- Tutorial on principles and applications of database system (007) -- related concepts of database
- [pytorch practice] image description -- let neural network read pictures and tell stories
- Static comprehensive experiment
- Solutions to cross domain problems
- 数据库系统原理与应用教程(009)—— 概念模型与数据模型
- Minimalist movie website
- 数据库系统原理与应用教程(007)—— 数据库相关概念
猜你喜欢

Static comprehensive experiment
idea 2021中文乱码

Baidu digital person Du Xiaoxiao responded to netizens' shouts online to meet the Shanghai college entrance examination English composition
Decrypt gd32 MCU product family, how to choose the development board?
Zero shot, one shot and few shot
What is an esp/msr partition and how to create an esp/msr partition
30. Feed shot named entity recognition with self describing networks reading notes
idm服务器响应显示您没有权限下载解决教程

对话PPIO联合创始人王闻宇:整合边缘算力资源,开拓更多音视频服务场景
Dialogue with Wang Wenyu, co-founder of ppio: integrate edge computing resources and explore more audio and video service scenarios
随机推荐
牛客网刷题网址
Attack and defense world ----- summary of web knowledge points
Learning and using vscode
Epp+dis learning road (2) -- blink! twinkle!
Tutorial on the principle and application of database system (008) -- exercises on database related concepts
Realize all, race, allsettled and any of the simple version of promise by yourself
SQL head injection -- injection principle and essence
College entrance examination composition, high-frequency mention of science and Technology
BGP third experiment report
关于 Web Content-Security-Policy Directive 通过 meta 元素指定的一些测试用例
How to use PS link layer and shortcut keys, and how to do PS layer link
Zhimei creative website exercise
SQL blind injection (WEB penetration)
<No. 9> 1805. Number of different integers in the string (simple)
Static comprehensive experiment
Unity map auto match material tool map auto add to shader tool shader match map tool map made by substance painter auto match shader tool
什么是ESP/MSR 分区,如何建立ESP/MSR 分区
In the small skin panel, use CMD to enter the MySQL command, including the MySQL error unknown variable 'secure_ file_ Priv 'solution (super detailed)
ES底层原理之倒排索引
SQL lab 11~20 summary (subsequent continuous update) contains the solution that Firefox can't catch local packages after 18 levels