当前位置:网站首页>[pytorch practice] image description -- let neural network read pictures and tell stories
[pytorch practice] image description -- let neural network read pictures and tell stories
2022-07-07 12:26:00 【Sickle leek】
Image description —— Let the neural network read the picture and tell the story
Image Caption: Image description , Also known as image annotation , Is to generate a description text from a given image . Image description is a very interesting research direction in deep learning , It is also a key goal of computer vision . For the task of image description , Neural networks not only need to know which objects are in the graph , Relationships between objects , Also use natural language to describe the relationship between these objects .

The data set used in image description is usually MS COCO.COCO The data set uses English Corpus , Use here 2017 year 9 month ~12 Held in AI Challenger In the game ” Image description in Chinese “ Data of subtasks .
Address Links : https://pan.baidu.com/s/1K4DUjkqCyNNSysP31f5lJg?pwd=y35v Extraction code : y35v
1. Image Description Introduction
The work of using deep learning to complete image description can be traced back to 2014 Baidu Research Institute published Explain Images with Multimodal Recurrent Neural Networks The paper , Combine deep convolution neural network and deep cyclic neural network , It is used to solve the problems of image annotation and image and sentence retrieval .
Another paper :Show and tell: A neural image caption generator, This paper puts forward Caption The model is shown in the figure below :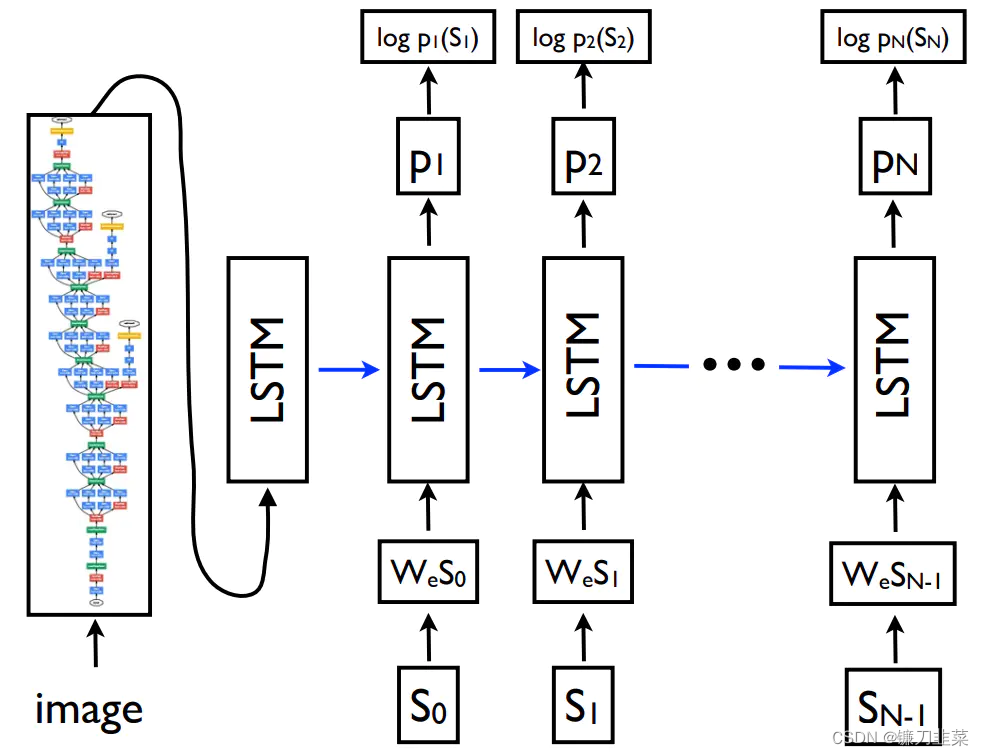
Image It's the original picture , On the left is GoogleLeNet, In practice, any deep learning network structure can be used to replace ( Such as VGG or ResNet etc. ), S 0 , S 1 , S 2 , … … , S N S_0,S_1,S_2,……,S_N S0,S1,S2,……,SN It is a sentence that describes the picture manually , for example “A dog is playing with a ball”, that S 0 S 6 S_0~S_6 S0 S6 This is the 7 Word . It is the word vector corresponding to these words .
The training methods in the paper are as follows :
- The high-level semantic information of the image is extracted by neural network f f f
- take f f f Input to LSTM in , And hope LSTM The output of is S 0 S_0 S0
- take S 0 S_0 S0 Input to LSTM in , And hope LSTM The output of is S 1 S_1 S1
- take S 1 S_1 S1 Input to LSTM in , And hope LSTM The output of is S 2 S_2 S2
- take S 2 S_2 S2 Input to LSTM in , And hope LSTM The output of is S 3 S_3 S3
- …
- And so on , take S N − 1 S_{N-1} SN−1 Input to LSTM in , And hope LSTM The output of is S N S_N SN
In the paper , The author used the pre trained GoogleLeNet Get the output of the picture before the full connection classification layer , As image semantics . The goal of training is to try to match the output words with the expected words , therefore Image description eventually becomes a classification problem , utilize LSTM Constantly predict the next most likely word .
2. data
2.1 Data is introduced
AI Challenger The Chinese image describes the data of the game, which is divided into two parts , The first part is the picture , in total 20 Thousands of copies , The second part is a caption_train_annotations_20170902.json file , It uses json Save the description of each picture in the format of , The format of each sample is as follows , All in all 20 Ten thousand such samples .
- url: Picture download address ( useless , Because the downloaded pictures have been provided ).
- image_id: The filename of the picture .
- caption: Five sentences corresponding to the picture .
url:
[{“url”: “http://img5.cache.netease.com/photo/0005/2013-09-25/99LA1FC60B6P0005.jpg”, “image_id”: “3cd32bef87ed98572bac868418521852ac3f6a70.jpg”, “caption”: [“\u4e00\u4e2a\u53cc\u81c2\u62ac\u8d77\u7684\u8fd0\u52a8\u5458\u8dea\u5728\u7eff\u8335\u8335\u7684\u7403\u573a\u4e0a”, “\u4e00\u4e2a\u62ac\u7740\u53cc\u81c2\u7684\u8fd0\u52a8\u5458\u8dea\u5728\u8db3\u7403\u573a\u4e0a”, “\u4e00\u4e2a\u53cc\u624b\u63e1\u62f3\u7684\u7537\u4eba\u8dea\u5728\u7eff\u8335\u8335\u7684\u8db3\u7403\u573a\u4e0a”, “\u4e00\u4e2a\u62ac\u8d77\u53cc\u624b\u7684\u7537\u4eba\u8dea\u5728\u78a7\u7eff\u7684\u7403\u573a\u4e0a”, “\u4e00\u4e2a\u53cc\u624b\u63e1\u62f3\u7684\u8fd0\u52a8\u5458\u8dea\u5728\u5e73\u5766\u7684\u8fd0\u52a8\u573a\u4e0a”]}, …
picture :
describe :
- “ An athlete with his arms raised kneels on the green pitch ”,
- “ A player with arms raised kneels on the football field ”,
- “ A man with clenched hands knelt on the green football field ”,
- “ A man with his hands up knelt on the Green Court ”,
- “ An athlete with clenched hands kneels on a flat playground ”
Describe the characteristics :
- The description of each sentence varies in length ;
- The description does not involve too much additional knowledge , Be as objective as possible ;
- Try to point out the characters in the image and the relationship between them .
Data processing mainly involves the pretreatment of pictures and descriptions . The image preprocessing is relatively simple , Send pictures to ResNet, Get the output of the specified layer and save it . The preprocessing of text is relatively troublesome , Here are a few steps :
- Chinese word segmentation
- Use serial numbers to indicate (word2idx), And filter low-frequency words , That is, count the number of times each word appears , Then delete some words with too low frequency .
- Complete all descriptions to equal length (pad_sequence)
- utilize pack_padded_sequence Speed up the calculation
Among them, Chinese word segmentation . English uses spaces to distinguish words , Chinese uses word segmentation software , The most effective is Stuttering participle , Installation uses pip install jieba.
import jieba
seq_list = jieba.cut(" I am learning deep learning knowledge ",cut_all=False)
print(u" Segmentation result : "+"/".join(seq_list))
Segmentation result : I / is / Study / depth / Study / knowledge
Be careful : Stuttering segmentation uses a self built dictionary to segment words , You can also specify your own custom dictionary .
PyTorch Middle function pack_padded_sequence Specially for passing pad operation After the sequence pack, Through pad There are many blank fill values in the sequence after , Make it possible to calculate RNN May affect the value of hidden elements , Make it complicated , Waste computing resources .PackedSequence Can solve this problem , It knows which of the input data is pad Value , Can't calculate pad Data output of , To save computing resources . The specific methods :
- For sentences of different lengths , on length ( From long to short ) Sort and record the length of sentences ;
- For different sentences , Unified pad In the same length ;
- Take what you got in the last step variable And sample length input pack_padded_sequence, Will be output PackedSequence object , This object can be input into any RNN Type of module in ( Include RNN、LSTM and GRU), It can also be sent into the partial loss function ( For example, cross entropy loss function ).
- PackedSequence Can pass pad_packed_sequence Method take out variable and length. This operation can be regarded as pack_padded_sequence The inverse operation , But generally, you don't need to take it out , Instead, the loss is calculated directly through the full connection layer .
Use cases :
import torch as t
from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence
from torch import nn
sen1 = [1, 1, 1]
sen2 = [2,2,2,2]
sen3 = [3,3,3,3,3,3,3,3]
sen4 = [4,4,4,4,4,4]
sentences = [sen1,sen2,sen3,sen4]
sentences
Out[16]: [[1, 1, 1], [2, 2, 2, 2], [3, 3, 3, 3, 3, 3, 3, 3], [4, 4, 4, 4, 4, 4]]
sentences = sorted(sentences, key=lambda x: len(x), reverse=True)
sentences
Out[20]: [[3, 3, 3, 3, 3, 3, 3, 3], [4, 4, 4, 4, 4, 4], [2, 2, 2, 2], [1, 1, 1]]
# Longer than 5 Word truncation to 5 Word
lengths = [5 if len(sen)>5 else len(sen) for sen in sentences]
lengths
Out[23]: [5, 5, 4, 3]
# pad data , If it is too long, it will be truncated , If it is too short, fill in zero
def pad_sen(sen, length=5, padded_num=0):
...: origin_len = len(sen)
...: padded_sen = sen[:length]
...: padded_sen = padded_sen + [padded_num for _ in range(origin_len, length)]
...:
...: return padded_sen
...:
pad_sentences = [pad_sen(sen) for sen in sentences]
pad_sentences
Out[31]: [[3, 3, 3, 3, 3], [4, 4, 4, 4, 4], [2, 2, 2, 2, 0], [1, 1, 1, 0, 0]]
# 4 * 5 batch_size = 3, word =5
pad_tensor = t.Tensor(pad_sentences).long()
# 5 * 4 batch_size = 4, word =5
pad_tensor = pad_tensor.t()
pad_variable = t.autograd.Variable(pad_tensor)
pad_variable # One column is a sentence
Out[38]:
tensor([[3, 4, 2, 1],
[3, 4, 2, 1],
[3, 4, 2, 1],
[3, 4, 2, 0],
[3, 4, 0, 0]])
# in total 5 Word , Every word uses 2 The dimension vector represents
embedding = nn.Embedding(5, 2)
# 5 * 4 * 2
pad_embeddings = embedding(pad_variable)
pad_embeddings
Out[43]:
tensor([[[-0.5019, 0.4527],
[ 1.4539, -0.8153],
[ 0.2895, -0.3784],
[ 1.2969, 1.7264]],
[[-0.5019, 0.4527],
[ 1.4539, -0.8153],
[ 0.2895, -0.3784],
[ 1.2969, 1.7264]],
[[-0.5019, 0.4527],
[ 1.4539, -0.8153],
[ 0.2895, -0.3784],
[ 1.2969, 1.7264]],
[[-0.5019, 0.4527],
[ 1.4539, -0.8153],
[ 0.2895, -0.3784],
[ 0.8121, 0.9832]],
[[-0.5019, 0.4527],
[ 1.4539, -0.8153],
[ 0.8121, 0.9832],
[ 0.8121, 0.9832]]], grad_fn=<EmbeddingBackward0>)
# pack data
packed_variable = pack_padded_sequence(pad_embeddings, lengths)
packed_variable # The output is PackedSequence
Out[47]:
PackedSequence(data=tensor([[-0.5019, 0.4527],
[ 1.4539, -0.8153],
[ 0.2895, -0.3784],
[ 1.2969, 1.7264],
[-0.5019, 0.4527],
[ 1.4539, -0.8153],
[ 0.2895, -0.3784],
[ 1.2969, 1.7264],
[-0.5019, 0.4527],
[ 1.4539, -0.8153],
[ 0.2895, -0.3784],
[ 1.2969, 1.7264],
[-0.5019, 0.4527],
[ 1.4539, -0.8153],
[ 0.2895, -0.3784],
[-0.5019, 0.4527],
[ 1.4539, -0.8153]], grad_fn=<PackPaddedSequenceBackward0>), batch_sizes=tensor([4, 4, 4, 3, 2]), sorted_indices=None, unsorted_indices=None)
# Input 2 dimension ( Word vector length ), The length of hidden element is 3
rnn = t.nn.LSTM(2, 3)
output, hn = rnn(packed_variable)
output = pad_packed_sequence(output)
output
Out[52]:
(tensor([[[ 0.1196, 0.0815, 0.0840],
[-0.0695, -0.0680, 0.2405],
[ 0.0309, -0.0104, 0.1873],
[-0.2330, 0.0528, 0.0075]],
[[ 0.1888, 0.1278, 0.1229],
[-0.1119, -0.1228, 0.2911],
[ 0.0386, -0.0304, 0.2468],
[-0.3550, 0.1099, 0.0170]],
[[ 0.2290, 0.1541, 0.1402],
[-0.1266, -0.1615, 0.3069],
[ 0.0408, -0.0499, 0.2678],
[-0.4142, 0.1606, 0.0280]],
[[ 0.2531, 0.1691, 0.1479],
[-0.1299, -0.1880, 0.3132],
[ 0.0427, -0.0663, 0.2759],
[ 0.0000, 0.0000, 0.0000]],
[[ 0.2681, 0.1777, 0.1513],
[-0.1292, -0.2064, 0.3162],
[ 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 0.0000]]], grad_fn=<CopySlices>),
tensor([5, 5, 4, 3]))
Because here Use only the original validation set , So use the code provided in the book to caption_validation_annotations_20170910.json Pre treatment , Save as pickle Format dict object , The name is caption_validation.pth.
The preprocessing code is as follows :
# -*- coding: utf-8 -*-#
# ----------------------------------------------
# Name: data_preprocess.py
# Description: Yes caption_validation_annotations_20170910.json Pre treatment , Save as pickle Format dict object
# Author: PANG
# Date: 2022/7/3
# ----------------------------------------------
import torch as t
import numpy as np
import json
import jieba
import tqdm
class Config:
annotation_file = 'ai_challenger_caption_validation_20170910/caption_validation_annotations_20170910.json'
unknown = '</UNKNOWN>'
end = '</EOS>'
padding = '</PAD>'
max_words = 10000
min_appear = 2
save_path = 'caption_validation.pth'
# START='</START>'
# MAX_LENS = 25,
def process(**kwargs):
opt = Config()
for k, v in kwargs.items():
setattr(opt, k, v)
with open(opt.annotation_file) as f:
data = json.load(f)
# 8f00f3d0f1008e085ab660e70dffced16a8259f6.jpg -> 0
id2ix = {
item['image_id']: ix for ix, item in enumerate(data)}
# 0-> 8f00f3d0f1008e085ab660e70dffced16a8259f6.jpg
ix2id = {
ix: id for id, ix in (id2ix.items())}
assert id2ix[ix2id[10]] == 10
captions = [item['caption'] for item in data]
# Segmentation result
cut_captions = [[list(jieba.cut(ii, cut_all=False)) for ii in item] for item in tqdm.tqdm(captions)]
word_nums = {
} # ' happy '-> 10000 ( Time )
def update(word_nums):
def fun(word):
word_nums[word] = word_nums.get(word, 0) + 1
return None
return fun
lambda_ = update(word_nums)
_ = {
lambda_(word) for sentences in cut_captions for sentence in sentences for word in sentence}
# [ (10000,u' happy '),(9999,u' Happy ') ...]
word_nums_list = sorted([(num, word) for word, num in word_nums.items()], reverse=True)
#### The above operation is lossless , Reversible operation ###############################
# ********** Some information will be deleted below ******************
# 1. Discard words with insufficient word frequency
# 2. ~~ Discard words that are too long ~~
words = [word[1] for word in word_nums_list[:opt.max_words] if word[0] >= opt.min_appear]
words = [opt.unknown, opt.padding, opt.end] + words
word2ix = {
word: ix for ix, word in enumerate(words)}
ix2word = {
ix: word for word, ix in word2ix.items()}
assert word2ix[ix2word[123]] == 123
ix_captions = [[[word2ix.get(word, word2ix.get(opt.unknown)) for word in sentence]
for sentence in item]
for item in cut_captions]
readme = u""" word: word ix:index id: Picture name caption: Description after participle , adopt ix2word You can get the original Chinese words """
results = {
'caption': ix_captions,
'word2ix': word2ix,
'ix2word': ix2word,
'ix2id': ix2id,
'id2ix': id2ix,
'padding': '</PAD>',
'end': '</EOS>',
'readme': readme
}
t.save(results, opt.save_path)
print('save file in %s' % opt.save_path)
def test(ix, ix2=4):
results = t.load(opt.save_path)
ix2word = results['ix2word']
examples = results['caption'][ix][4]
sentences_p = (''.join([ix2word[ii] for ii in examples]))
sentences_r = data[ix]['caption'][ix2]
assert sentences_p == sentences_r, 'test failed'
test(1000)
print('test success')
if __name__ == '__main__':
# import fire
#
# fire.Fire()
# python data_preprocess.py process --annotation-file=/data/annotation.json --max-words=5000
process()
caption_validation.pth The contents in are as follows :
import torch as t
data = t.load('D:\MyProjects\deeplearningDay100\Image_Caption\caption_validation.pth')
list(data.keys())
Out[4]: ['caption', 'word2ix', 'ix2word', 'ix2id', 'id2ix', 'padding', 'end', 'readme']
print(data['readme'])
word: word
ix:index
id: Picture name
caption: Description after participle , adopt ix2word You can get the original Chinese words
The meanings of key value pairs in the dictionary are as follows :
- word2idx: The length is 5911 Dictionary , The serial number corresponding to the word , for example “ A woman ”->10
- id2word: The length is 5911 Dictionary , The word corresponding to the serial number , for example 10 -> “ A woman ”
- id2ix: The length is 30000 Dictionary , The sequence number corresponding to the image file name , for example ’a20401efd162bd6320a2203057019afbf996423c.jpg’ -> 9
- ix2id: The length is 30000 Dictionary , The image file name corresponding to the serial number , for example 9 -> ‘a20401efd162bd6320a2203057019afbf996423c.jpg’
- end: End identifier </EOS>
- padding:pad identifier </PAD>
- caption: The length is 30000 A list of , Each item is a length of 5 A list of , All saved pictures should be described in five sentences . The data described goes through word segmentation , And map words to serial numbers . Can pass word2ix Check the correspondence between words and serial numbers .

A use case :
import torch as t
data = t.load('D:\MyProjects\deeplearningDay100\Image_Caption\caption_validation.pth')
ix2word = data['ix2word']
ix2id = data['ix2id']
caption = data['caption']
img_ix = 100 # The first 100 A picture
# The description corresponding to the picture
img_caption = caption[img_ix]
# Image file name
img_id = ix2id[img_ix]
img_caption
Out[15]:
[[60, 3, 46, 15, 4, 833, 230, 3, 7, 37, 11, 34, 9, 207, 41, 3, 10, 5, 177],
[46, 15, 4, 9, 50, 31, 3, 7, 110, 28, 9, 52, 3, 10, 5, 0],
[46, 15, 4, 7, 3, 37, 11, 28, 9, 756, 609, 3, 10, 5, 177],
[4, 7, 3, 29, 11, 28, 19, 223, 8, 229, 3, 10, 13, 5, 46, 15],
[46, 15, 4, 19, 57, 193, 6, 3, 7, 104, 28, 63, 207, 31, 3, 10, 5, 81]]
img_id
Out[16]: '644441869019a08b76a6eacc3d4ac4c21142e036.jpg'
# adopt ix2word Get the corresponding word
sen = img_caption[0]
sen = [ix2word[_] for _ in sen]
print(''.join(sen))
In the clean hall, in front of a cross fingered man, there are a group of women in yellow dancing

2.2 Image data processing
We need to use neural network to extract image features . In particular , Is the use ResNet Extract the picture on the penultimate layer ( Output of pool layer , Input for the full connection layer ) Of 2048 The vector of the dimension . There are two solutions :
- Copy and modify torchvision Medium ResNet Source code , Let it output and return on the penultimate layer
- Directly delete the last layer and replace it with an identity map .
First , to glance at torchvision in ResNet Of forward Source code , Our goal is to achieve x=self.avgpool(x) Output .
class ResNet(nn.Module):
def __init__(
self,
block: Type[Union[BasicBlock, Bottleneck]],
layers: List[int],
num_classes: int = 1000,
zero_init_residual: bool = False,
groups: int = 1,
width_per_group: int = 64,
replace_stride_with_dilation: Optional[List[bool]] = None,
norm_layer: Optional[Callable[..., nn.Module]] = None,
) -> None:
super().__init__()
_log_api_usage_once(self)
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.inplanes = 64
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError(
"replace_stride_with_dilation should be None "
f"or a 3-element tuple, got {
replace_stride_with_dilation}"
)
self.groups = groups
self.base_width = width_per_group
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2, dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 256, layers[2], stride=2, dilate=replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block, 512, layers[3], stride=2, dilate=replace_stride_with_dilation[2])
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0) # type: ignore[arg-type]
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0) # type: ignore[arg-type]
def _make_layer(
self,
block: Type[Union[BasicBlock, Bottleneck]],
planes: int,
blocks: int,
stride: int = 1,
dilate: bool = False,
) -> nn.Sequential:
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
layers = []
layers.append(
block(
self.inplanes, planes, stride, downsample, self.groups, self.base_width, previous_dilation, norm_layer
)
)
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(
block(
self.inplanes,
planes,
groups=self.groups,
base_width=self.base_width,
dilation=self.dilation,
norm_layer=norm_layer,
)
)
return nn.Sequential(*layers)
def _forward_impl(self, x: Tensor) -> Tensor:
# See note [TorchScript super()]
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x) # Get the output here
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def forward(self, x: Tensor) -> Tensor:
return self._forward_impl(x)
The first way : modify forward function
from torchvision.models import resnet50
def new_forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
# x = self.fc(x)
return x
model = resnet50(pretrained=True)
model.forward = lambda x:new_forward(model, x)
model = model.cuda()
The second way : Delete model The full connection layer of , Change it into an identity map
resnet50 = tv.models.resnet50(pretrained=True)
del resnet50.fc
resnet50.fc = lambda x: x
resnet50.cuda()
After revising ResNet After the structure of , You can extract 30000 Picture of feature. The code is as follows :
# -*- coding: utf-8 -*-#
# ----------------------------------------------
# Name: feature_extract.py
# Description: modify ResNet The second derivative , Extract picture features
# Author: PANG
# Date: 2022/7/3
# ----------------------------------------------
import os
import torch
import torchvision as tv
from PIL import Image
from torch.utils import data
from torchvision.models import resnet50
from Image_Caption.config import Config
torch.set_grad_enabled(False)
opt = Config()
IMAGENET_MEAN = [0.485, 0.456, 0.406]
IMAGENET_STD = [0.229, 0.224, 0.225]
normalize = tv.transforms.Normalize(mean=IMAGENET_MEAN, std=IMAGENET_STD)
# programme 1: modify forward function
def new_forward(self, x):
# See note [TorchScript super()]
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
# x = self.fc(x)
return x
# programme 2: Delete model The full connection layer of , Change it into an identity map
# model = resnet50(pretrained=False)
# model.load_state_dict(torch.load("resnet50-19c8e357.pth"))
# del model.fc
# model.fc = lambda x:x
# model = model.cuda()
class CaptionDataset(data.Dataset):
def __init__(self, caption_data_path):
self.transforms = tv.transforms.Compose([
tv.transforms.Resize(256),
tv.transforms.CenterCrop(256),
tv.transforms.ToTensor(),
normalize
])
data = torch.load(caption_data_path)
self.ix2id = data['ix2id']
self.imgs = [os.path.join(opt.img_path, self.ix2id[_]) for _ in range(len(self.ix2id))]
def __getitem__(self, index):
img = Image.open(self.imgs[index]).convert('RGB')
img = self.transforms(img)
return img, index
def __len__(self):
return len(self.imgs)
def get_dataloader(opt):
dataset = CaptionDataset(opt.caption_data_path)
dataloader = data.DataLoader(dataset, batch_size=opt.batch_size, shuffle=False, num_workers=opt.num_workers)
return dataloader
def feature_extract():
# data , obtain 30000 A picture
opt.batch_size = 32 # Can be set larger
dataloader = get_dataloader(opt)
results = torch.Tensor(len(dataloader.dataset), 2048).fill_(0)
batch_size = opt.batch_size
# Model
model = resnet50(pretrained=False)
model.load_state_dict(torch.load("resnet50-19c8e357.pth"))
# With the new forward Function overrides the old forward function
model.forward = lambda x: new_forward(model, x)
model = model.cuda()
# Forward propagation , obtain feature
for ii, (imgs, indexs) in enumerate(dataloader):
# Make sure there is no corresponding error in the serial number
assert indexs[0] == batch_size * ii
imgs = imgs.cuda()
features = model(imgs)
results[ii * batch_size:(ii + 1) * batch_size] = features.data.cpu()
print(ii * batch_size)
# 30000 * 2048 30000 A picture , Each image 2048 Dimensional feature
torch.save(results, 'results_val_2048.pth')
if __name__ == '__main__':
feature_extract()
Be careful :dataloader Don't shuffle, In order , In this way, we can communicate with ix2id The serial number in and the image file name correspond one to one .
2.3 Data loading
First , Encapsulate data into dataset.
class CaptionDataset(data.Dataset):
def __init__(self, opt):
""" Attributes: _data (dict): Data after preprocessing , Include the file names of all pictures , And the description after treatment all_imgs (tensor): utilize resnet50 Extracted image features , shape (30000,2048) caption(list): The length is 3 Ten thousand list, Include the text description of each picture ix2id(dict): Specify the file name corresponding to the picture with sequence number start_(int): Start sequence number , The starting sequence number of the training set is 0, The starting sequence number of the validation set is 29000, The former 29000 This picture is a training set , The rest 1000 This picture is a verification set len_(init): Dataset size , If it's a training set , Length is 29000, The validation set length is 1000 traininig(bool): It's a training set (True), Or verification set (False) """
self.opt = opt
data = torch.load(opt.caption_data_path)
word2ix = data['word2ix']
self.captions = data['caption']
self.padding = word2ix.get(data.get('padding'))
self.end = word2ix.get(data.get('end'))
self._data = data
self.ix2id = data['ix2id']
self.all_imgs = torch.load(opt.img_feature_path)
def __getitem__(self, index):
""" return : - img: Images features 2048 Vector - caption: describe , Form like LongTensor([1,3,5,2]), The length depends on the description length - index: Subscript , Sequence number of the image , Can pass ix2id[index] Get the corresponding image file name """
img = self.all_imgs[index]
caption = self.captions[index]
# 5 Choose one sentence at random
rdn_index = np.random.choice(len(caption), 1)[0]
caption = caption[rdn_index]
return img, torch.LongTensor(caption), index
def __len__(self):
return len(self.ix2id)
def train(self, training=True):
""" Switch between training set and test set ,training by True,getitem Return the data of the training set , Otherwise, return the data of the validation set :param training: :return: """
self.training = training
if self.training:
self._start = 0
self.len_ = len(self._data) - 1000
else:
self._start = len(self.ix2id) - 1000
self.len_ = 1000
return self
Be careful : stay __getitem__ in ,dataset The data of a sample will be returned , stay dataloader in , The data of each sample will be spliced into one batch, However, due to the length of the description , Cannot be spliced into one batch, This needs to be achieved by yourself collate_fn, Put each one batch Data of different lengths are spliced into one tensor.
def create_collate_fn(padding, eos, max_length=50):
def collate_fn(img_cap):
""" Splice multiple samples together to form one batch Input : list of data, Form like [(img1, cap1, index1), (img2, cap2, index2) ....] The splicing strategy is as follows : - batch The description length of each sample is changing , Don't discard any word \ - Choose the sentence with the longest length , Put all the sentences pad As long as - Not long enough to use </PAD> At the end PAD - No, START identifier - If the length is exactly the same as the word , Then there is no </EOS> return : - imgs(Tensor): batch_sie*2048 - cap_tensor(Tensor): batch_size*max_length - lengths(list of int): The length is batch_size - index(list of int): The length is batch_size """
img_cap.sort(key=lambda p: len(p[1]), reverse=True)
imgs, caps, indexs = zip(*img_cap)
imgs = torch.cat([img.unsqueeze(0) for img in imgs], 0)
lengths = [min(len(c) + 1, max_length) for c in caps]
batch_length = max(lengths)
cap_tensor = torch.LongTensor(batch_length, len(caps)).fill_(padding)
for i, c in enumerate(caps):
end_cap = lengths[i] - 1
if end_cap < batch_length:
cap_tensor[end_cap, i] = eos
cap_tensor[:end_cap, i].copy_(c[:end_cap])
return imgs, (cap_tensor, lengths), indexs
return collate_fn
After encapsulation , You can call it during training :
def get_dataloader(opt):
dataset = CaptionDataset(opt)
n_train = int(len(dataset) * 0.9)
split_train, split_valid = random_split(dataset=dataset, lengths=[n_train, len(dataset) - n_train])
train_dataloader = data.DataLoader(split_train, batch_size=opt.batch_size, shuffle=opt.shuffle, num_workers=0,
collate_fn=create_collate_fn(dataset.padding, dataset.end))
valid_dataloader = data.DataLoader(split_valid, batch_size=opt.batch_size, shuffle=opt.shuffle, num_workers=0,
collate_fn=create_collate_fn(dataset.padding, dataset.end))
return train_dataloader, valid_dataloader
# dataloader = data.DataLoader(dataset, batch_size=opt.batch_size, shuffle=opt.shuffle, num_workers=0,
# collate_fn=create_collate_fn(dataset.padding, dataset.end))
# return dataloader
if __name__ == '__main__':
from Image_Caption.config import Config
opt = Config()
opt.num_workers = 0 # add to : The number of threads is set to 1
dataloader = get_dataloader(opt)
for ii, data in enumerate(dataloader):
print(ii, data)
break
3. Modeling and training
After data processing , You can use it PyTorch The training model is trained .
(1) The picture passes by ResNet Extract into 2028 The vector of the dimension , Then use the full connection layer to 256 Dimension vector , It can be considered that from the semantic space of image to the semantic space of word vector .
(2) Describe the process Embedding layer , Every word becomes 256 Dimension vector
(3) Put the word vectors obtained in step 1 and step 2 together , Send in LSTM in , Calculate the output of each word .
(4) Use the output of each word to classify , Predict the next word ( classification )
class CaptionModel(nn.Module):
def __init__(self, opt, word2ix, ix2word):
super(CaptionModel, self).__init__()
self.ix2word = ix2word
self.word2ix = word2ix
self.opt = opt
self.fc = nn.Linear(2048, opt.rnn_hidden) # Use the full connection layer to turn into 256 Dimension vector
self.rnn = nn.LSTM(opt.embedding_dim, opt.rnn_hidden, num_layers=opt.num_layers)
self.classifier = nn.Linear(opt.rnn_hidden, len(word2ix))
self.embedding = nn.Embedding(len(word2ix), opt.embedding_dim)
# if opt.share_embedding_weights:
# # rnn_hidden=embedding_dim You can only
# self.embedding.weight
def forward(self, img_feats, captions, lengths):
embeddings = self.embedding(captions)
# img_feats yes 2048 Dimension vector , Through the full connection layer to 256 Dimension vector , Like word vectors
img_feats = self.fc(img_feats).unsqueeze(0)
# take img_feats Look at the word vector as the first word , Spliced with other word vectors
embeddings = torch.cat([img_feats, embeddings], 0)
# PackedSequence
packed_embeddings = pack_padded_sequence(embeddings, lengths)
outputs, state = self.rnn(packed_embeddings)
# lstm The output of is used as a feature to classify and predict the sequence number of the next word
# Because the input is PackedSequence, So the output output It's also PackedSequence
# PackedSequence The first element of is Variable, namely outputs[0]
# The second element is batch_size, namely batch The length of each sample in
pred = self.classifier(outputs[0])
return pred, state
def generate(self, img, eos_token='</EOS>', beam_size=3, max_caption_length=30, length_normalization_factor=0.0):
""" Generate a description from the picture , Mainly used beam search Algorithm to get a better description beam search The algorithm is a dynamic programming algorithm , Every time it searches , Don't just write down the most likely word , Instead, remember the most likely k Word , Then continue to search for the next word , find k^2 A sequence of , The one with the greatest probability of preservation k, So keep searching until you finally get the best result . """
cap_gen = CaptionGenerator(embedder=self.embedding,
rnn=self.rnn,
classifier=self.classifier,
eos_id=self.word2ix[eos_token],
beam_size=beam_size,
max_caption_length=max_caption_length,
length_normalization_factor=length_normalization_factor)
if next(self.parameters()).is_cuda:
img = img.cuda()
img = img.unsqueeze(0)
img = self.fc(img).unsqueeze(0)
sentences, score = cap_gen.beam_search(img)
sentences = [' '.join([self.ix2word[idx.item()] for idx in sent]) for sent in sentences]
return sentences
The more complicated part here is PackedSequence Use , because LSTM The input is PackedSequence, So the output is also PackedSequence,PackedSequence It's a special one tuple, That is, it can be done through packedsequence.data Get the corresponding variable, It can also be done through packedsequence[0] get . If you want to get the corresponding tensor, You need to packedsequence.data.data, first data Get is variable, the second data Get is tensor. Because there are about 10000 Word , So it finally became a 10000 Classification problem , Cross entropy loss is used as the objective function .
The code of the training part is as follows :
def train(**kwargs):
opt = Config()
for k, v in kwargs.items():
setattr(opt, k, v)
device = torch.device('cuda') if opt.use_gpu else torch.device('cpu')
opt.caption_data_path = 'caption_validation.pth' # Raw data
opt.test_img = 'example.jpeg' # Input picture
# opt.model_ckpt='caption_0914_1947' # Pre training model
# data
vis = Visualizer(env=opt.env)
# dataloader = get_dataloader(opt)
train_dataloader, valid_dataloader = get_dataloader(opt)
# Data preprocessing
_data = torch.load(opt.caption_data_path, map_location=lambda s, l: s)
word2ix, ix2word = _data['word2ix'], _data['ix2word']
# _data = dataloader.dataset._data
# word2ix, ix2word = _data['word2ix'], _data['ix2word']
max_loss = 263
# Model
model = CaptionModel(opt, word2ix, ix2word)
if opt.model_ckpt:
model.load(opt.model_ckpt)
optimizer = model.get_optimizer(opt.lr)
criterion = torch.nn.CrossEntropyLoss()
model.to(device)
# Statistics
loss_meter = meter.AverageValueMeter()
valid_losses = meter.AverageValueMeter()
for epoch in range(opt.max_epoch):
loss_meter.reset()
valid_losses.reset()
for ii, (imgs, (captions, lengths), indexes) in tqdm.tqdm(enumerate(train_dataloader)):
# Training
optimizer.zero_grad()
imgs = imgs.to(device)
captions = captions.to(device)
input_captions = captions[:-1]
target_captions = pack_padded_sequence(captions, lengths)[0]
score, _ = model(imgs, input_captions, lengths)
loss = criterion(score, target_captions)
loss.backward()
optimizer.step()
loss_meter.add(loss.item())
# visualization
if (ii + 1) % opt.plot_every == 0:
if os.path.exists(opt.debug_file):
ipdb.set_trace()
vis.plot('loss', loss_meter.value()[0])
# Visualizing the original image + Visual manual description statement
raw_img = _data['ix2id'][indexes[0]]
img_path = opt.img_path + raw_img
raw_img = Image.open(img_path).convert('RGB')
raw_img = tv.transforms.ToTensor()(raw_img)
raw_caption = captions.data[:, 0]
raw_caption = ''.join([_data['ix2word'][ii.item()] for ii in raw_caption])
vis.text(raw_caption, u'raw_caption')
vis.img('raw', raw_img, caption=raw_caption)
# Description statement generated by visual network
results = model.generate(imgs.data[0])
vis.text('</br>'.join(results), u'caption')
model.eval()
total_loss = 0
with torch.no_grad():
for ii, (imgs, (captions, lengths), indexes) in enumerate(valid_dataloader):
imgs = imgs.to(device)
captions = captions.to(device)
input_captions = captions[:-1]
target_captions = pack_padded_sequence(captions, lengths)[0]
score, _ = model(imgs, input_captions, lengths)
loss = criterion(score, target_captions)
total_loss += loss.item()
model.train()
valid_losses.add(total_loss)
if total_loss < max_loss:
max_loss = total_loss
torch.save(model.state_dict(), 'checkpoints/model_best.pth')
print(max_loss)
plt.figure(1)
plt.plot(loss_meter)
plt.figure(2)
plt.plot(valid_losses)
plt.show()
3. experimental result
The experimental effect is not very good , As shown below :
overall , The model can extract the relationship between the basic elements and objects of the picture , But the quality of the generated description is still far from the human level .
Reference material
[1] 《 Deep learning framework PyTorch: From introduction to practice 》
[2] Yang SiCheng: 【PyTorch】13 Image Caption: Let the neural network read the picture and tell the story
[3] Did you type the code today : pytorch Introduction and practice learning notes :chapter10 Neural network reading pictures and telling stories
边栏推荐
- AirServer自动接收多画面投屏或者跨设备投屏
- 108.网络安全渗透测试—[权限提升篇6]—[Windows内核溢出提权]
- ES底层原理之倒排索引
- Vxlan 静态集中网关
- The hoisting of the upper cylinder of the steel containment of the world's first reactor "linglong-1" reactor building was successful
- wallys/Qualcomm IPQ8072A networking SBC supports dual 10GbE, WiFi 6
- 112. Network security penetration test - [privilege promotion article 10] - [Windows 2003 lpk.ddl hijacking rights lifting & MSF local rights lifting]
- Sonar:Cognitive Complexity认知复杂度
- sql-lab (54-65)
- 消息队列消息丢失和消息重复发送的处理策略
猜你喜欢

NPC Jincang was invited to participate in the "aerospace 706" I have an appointment with aerospace computer "national Partner Conference

Minimalist movie website

SQL lab 11~20 summary (subsequent continuous update) contains the solution that Firefox can't catch local packages after 18 levels

In the small skin panel, use CMD to enter the MySQL command, including the MySQL error unknown variable 'secure_ file_ Priv 'solution (super detailed)
Unity map auto match material tool map auto add to shader tool shader match map tool map made by substance painter auto match shader tool
Experiment with a web server that configures its own content
Zhimei creative website exercise
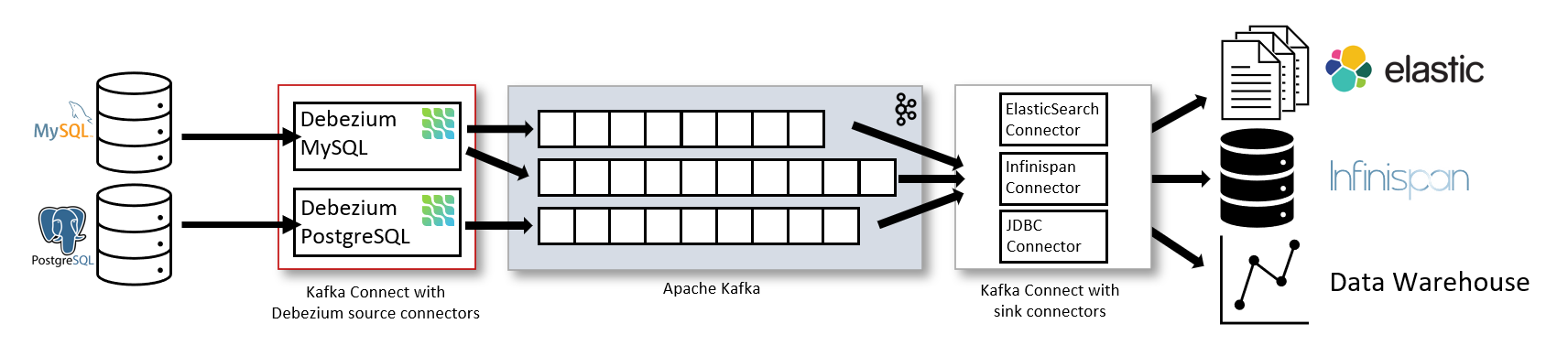
Detailed explanation of debezium architecture of debezium synchronization
@Bean与@Component用在同一个类上,会怎么样?
解密GD32 MCU产品家族,开发板该怎么选?
随机推荐
Learning and using vscode
College entrance examination composition, high-frequency mention of science and Technology
(to be deleted later) yyds, paid academic resources, please keep a low profile!
Solve server returns invalid timezone Go to ‘Advanced’ tab and set ‘serverTimezone’ property manually
Time bomb inside the software: 0-day log4shell is just the tip of the iceberg
ENSP MPLS layer 3 dedicated line
Will the filing free server affect the ranking and weight of the website?
Solutions to cross domain problems
Several methods of checking JS to judge empty objects
盘点JS判断空对象的几大方法
The road to success in R & D efficiency of 1000 person Internet companies
RHSA first day operation
开发一个小程序商城需要多少钱?
wallys/Qualcomm IPQ8072A networking SBC supports dual 10GbE, WiFi 6
Niuke website
Let digital manage inventory
"Series after reading" my God! It's so simple to understand throttling and anti shake~
About sqli lab less-15 using or instead of and parsing
Flet tutorial 17 basic introduction to card components (tutorial includes source code)
2022 年第八届“认证杯”中国高校风险管理与控制能力挑战赛