当前位置:网站首页>金融数据获取(三)当爬虫遇上要鼠标滚轮滚动才会刷新数据的网页(保姆级教程)
金融数据获取(三)当爬虫遇上要鼠标滚轮滚动才会刷新数据的网页(保姆级教程)
2022-07-07 10:26:00 【Simon Cao】
目录
1. 谁这么会给我整活儿
什么,新浪的股票历史数据已经不直接提供了!

笔者前几日需要找一些澳洲市场的数据,奈何API没到澳洲落地生根,无奈的我只好寄希望于爬虫。当我轻车熟路的点开新浪财经上相关数据,我惊讶的发现早已空空如也。再看看A股数据,原本熟悉的交易数据也早已不复存在,取而代之的是一个叫数据中心的东西,里面也没有笔者想要的数据。

以前还很容易找到的数据现在人是物非,以前的代码也参考不了了,令人唏嘘。笔者不禁感叹难怪爬数据的越来越少了,毕竟有API这种东西谁还会去干这种费力不讨好的活。
笔者当即换了Yahoo Finance,果不其然找到了想要的数据。于是笔者开心的写了个小爬虫。
import requests
import pandas as pd
headers = {"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.53 Safari/537.36 Edg/103.0.1264.37"}
url = "https://finance.yahoo.com/quote/%5EDJI/history?period1=1601510400&period2=1656460800&interval=1d&filter=history&frequency=1d&includeAdjustedClose=true"
re = requests.get(url, headers = headers)
print(pd.read_html(re.text)[0])然而还不待笔者开心,立马发现爬到的数据只有短短100行???

笔者百思不得其解,re明明请求的是三年数据的URL,为何爬下来就只剩100行了。
折腾了好半天,终于发现原来是因为雅虎数据要用鼠标滚轮往下滑才会刷出来,原始请求的网页上只有100行数据。现在排查到问题所在,那么如何解决呢?
2. Selenium模拟网页浏览器爬取
Selenium为我们提供了一个很好的解决方案, 我们传统的requests模块请求只能请求到固定网页所返回的内容,但对于需要进行点击或者像笔者碰到这个用鼠标滚轮滚动才能刷出来的数据便显得苍白无力。
笔者只在以前初学爬虫时用过selenium,毕竟不是经常碰到这么难搞的网页。因此笔者将从0开始出一期针对这种网页爬虫的保姆级教程。
2.1 安装和准备工作
请先装,导入模块
pip install selenium
from selenium import webdriver
from selenium.webdriver.common.by import By
import time接下来正是开始,经过C站搜索,这种网页先要使用selenium模拟的浏览器打开:
url = "https://finance.yahoo.com/quote/%5EDJI/history?period1=1601510400&period2=1656460800&interval=1d&filter=history&frequency=1d&includeAdjustedClose=true"
driver = webdriver.Chrome() #启动模拟浏览器
driver.get(url) # 打开要爬取的网页地址
运行到这里笔者踩第一个雷,报错WebDriverException: Message: 'chromedriver' executable needs to be in PATH:

又是一番折腾笔者找到解决办法:首先要下载一个模拟浏览器的启动文件,地址:ChromeDriver - WebDriver for Chrome - Downloads (chromium.org) https://chromedriver.chromium.org/downloads
https://chromedriver.chromium.org/downloads
需要注意的是,根据你的Chrome浏览器版本下载:

解压即可,但是安装位置必须在python.exe那个文件的同一个文件夹下:

接着就在环境变量中加入chromedriver.exe文件的地址,笔者是直接放在D盘里:
 依次确认后不用重启电脑,直接开CMD启动 chromedriver.exe。如果如下图一样successfuly就代表成功了,之前的代码便可以成功运行
依次确认后不用重启电脑,直接开CMD启动 chromedriver.exe。如果如下图一样successfuly就代表成功了,之前的代码便可以成功运行

运行代码后会直接打开网页,提示正在受到自动软件的控制:
2.2 用鼠标滑动网页
当然不是真的用鼠标滑动网页,而是通过selenium实现控制,有 to(划到) 和 by(划多少) 两种划动方式,输入xy参数即可实现控制:
driver.execute_script('window.scrollBy(x, y)') #横向滑动x, 纵向滑动y
driver.execute_script('window.scrollTo(x,y)') #滑动到页面的x, y位置通过写循环就可以控制它一直往下划动到底部以达到获取全部数据的目的,下面笔者提供两种划动策略,一种是别人写的,一种是笔者自己写的:
2.2.1 高度判断
思路是获取页面高度——To划动——再次获取页面高度——比较两次高度,如果==证明滑到底部了,结束循环。
while True:
h_before = driver.execute_script('return document.body.scrollHeight;')
time.sleep(2)
driver.execute_script(f'window.scrollTo(0,{h_before})')
time.sleep(2)
h_after = driver.execute_script('return document.body.scrollHeight;')
if h_before == h_after:
break但是!笔者用这种策略发现在Yahoo上不顶用,雅虎不管怎么划动,页面高度永远是一个固定的值。

出于给大家参考的目的笔者还是放上来了,看下面一堆评论说好,说不定别的网页能用上。
2.2.2 顶部距离判断
笔者自己另写了一个,利用到顶部距离判定是否到底:
driver.execute_script('return document.documentElement.scrollTop')其实和刚刚差不多,也是用循环:获取当前位置到页面顶部距离——To划动——再次获取到顶部距离——比较两次距离——固定单位增加,如果==证明到底了,结束循环。
roll = 500
while True:
h_before = driver.execute_script('return document.documentElement.scrollTop')
time.sleep(1)
driver.execute_script(f'window.scrollTo(0,{roll})')
time.sleep(1)
h_after = driver.execute_script('return document.documentElement.scrollTop')
roll += 500
print(h_after, h_before)
if h_before == h_after:
break一次滑500像素可能有点慢,大家可以自行更改每次的划动参数。

这个方案对雅虎有用, 可以看到的确在往下滑了,模拟浏览器上也能看到。至此,不显示数据的问题全部解决。
3: 爬取内容
通过page_source即可将划出来的数据统统导出,返回的数据是str的一堆网页标签。
driver.page_source前面滑动最难的坎都过了,剩下全是基本爬虫操作了,因为这次笔者目标是表格数据,直接pandas read。先把滑动爬到的数据存变量, 然后pandas解析即可,如果是爬取文本数据就需要大家用BeautifulSoup或者正则进一步解析一下了:
content = driver.page_source
data = pd.read_html(content)
table = pd.DataFrame(data[0])4: 完整代码,结果展示
url = # 您需要爬取的网站
driver = webdriver.Chrome()
driver.get(url)
roll = 1000
while True:
h_before = driver.execute_script('return document.documentElement.scrollTop')
time.sleep(1)
driver.execute_script(f'window.scrollTo(0,{roll})')
time.sleep(1)
h_after = driver.execute_script('return document.documentElement.scrollTop')
roll += 1000
print(h_after, h_before)
if h_before == h_after:
break
content = driver.page_source
data = pd.read_html(content)
table = pd.DataFrame(data[0])
print(table)
table.to_csv("market_data.csv")可以看到,笔者已经把道指的近几年数据全部拿到了:

这么简单的网页划动,您,学废了吗?
点赞评论+关注三连,您若不弃,我们风雨共济。
边栏推荐
- Up meta - Web3.0 world innovative meta universe financial agreement
- 112.网络安全渗透测试—[权限提升篇10]—[Windows 2003 LPK.DDL劫持提权&msf本地提权]
- Unity 贴图自动匹配材质工具 贴图自动添加到材质球工具 材质球匹配贴图工具 Substance Painter制作的贴图自动匹配材质球工具
- Tutorial on the principle and application of database system (008) -- exercises on database related concepts
- 2022 8th "certification Cup" China University risk management and control ability challenge
- Flet教程之 18 Divider 分隔符组件 基础入门(教程含源码)
- 软件内部的定时炸弹:0-Day Log4Shell只是冰山一角
- 超标量处理器设计 姚永斌 第8章 指令发射 摘录
- PowerShell cs-utf-16le code goes online
- Tutorial on principles and applications of database system (010) -- exercises of conceptual model and data model
猜你喜欢
Flet教程之 15 GridView 基础入门(教程含源码)
Upgrade from a tool to a solution, and the new site with praise points to new value
Tutorial on principles and applications of database system (010) -- exercises of conceptual model and data model
解决 Server returns invalid timezone. Go to ‘Advanced’ tab and set ‘serverTimezone’ property manually

Xiaohongshu microservice framework and governance and other cloud native business architecture evolution cases
SwiftUI 教程之如何在 2 秒内实现自动滚动功能
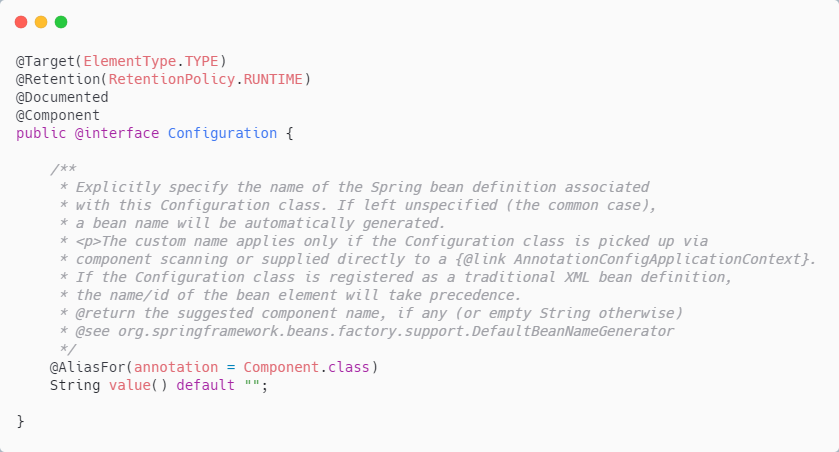
@Bean与@Component用在同一个类上,会怎么样?
千人规模互联网公司研发效能成功之路
![An error occurred when vscade tried to create a file in the target directory: access denied [resolved]](/img/14/9899f5a765872fb3238be4305a2dc7.png)
An error occurred when vscade tried to create a file in the target directory: access denied [resolved]
@What happens if bean and @component are used on the same class?
随机推荐
百度数字人度晓晓在线回应网友喊话 应战上海高考英语作文
[filter tracking] strapdown inertial navigation pure inertial navigation solution matlab implementation
ENSP MPLS layer 3 dedicated line
防红域名生成的3种方法介绍
Visual Studio 2019 (LocalDB)\MSSQLLocalDB SQL Server 2014 数据库版本为852无法打开,此服务器支持782版及更低版本
30. Feed shot named entity recognition with self describing networks reading notes
Swiftui tutorial how to realize automatic scrolling function in 2 seconds
问题:先后键入字符串和字符,结果发生冲突
Summed up 200 Classic machine learning interview questions (with reference answers)
Review and arrangement of HCIA
Typescript interface inheritance
Superscalar processor design yaoyongbin Chapter 10 instruction submission excerpt
Simple network configuration for equipment management
Tutorial on the principle and application of database system (011) -- relational database
Matlab implementation of Huffman coding and decoding with GUI interface
108. Network security penetration test - [privilege escalation 6] - [windows kernel overflow privilege escalation]
【全栈计划 —— 编程语言之C#】基础入门知识一文懂
Improve application security through nonce field of play integrity API
Zero shot, one shot and few shot
什么是局域网域名?如何解析?