当前位置:网站首页>周报2022-8-4
周报2022-8-4
2022-08-05 08:56:00 【Alice01010101】
周报2022-8-4
一、MoE(Mixture of Experts)相关论文
Adaptive mixtures of local experts, Neural Computation’1991
- 参考:https://zhuanlan.zhihu.com/p/542465517
- 期刊/会议:Neural Computation (1991)
- 论文链接:https://readpaper.com/paper/2150884987
- 代表性作者:Michael Jordan, Geoffrey Hinton
- Main Idea:
提出了一种新的监督学习过程,一个系统中包含多个分开的网络,每个网络去处理全部训练样本的一个子集。这种方式可以看做是把多层网络进行了模块化的转换。
假设我们已经知道数据集中存在一些天然的子集(比如来自不同的domain,不同的topic),那么用单个模型去学习,就会受到很多干扰(interference),导致学习很慢、泛化困难。这时,我们可以使用多个模型(即专家,expert)去学习,使用一个门网络(gating network)来决定每个数据应该被哪个模型去训练,这样就可以减轻不同类型样本之间的干扰。
其实这种做法,也不是该论文第一次提出的,更早就有人提出过类似的方法。对于一个样本c,第i个 expert 的输出为 o i c o_i^c oic理想的输出是 d c d^c dc,那么损失函数就这么计算: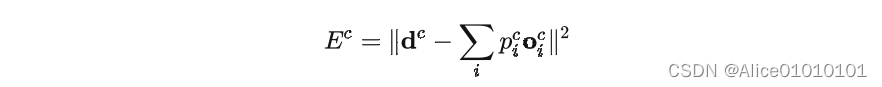
其中 p i c p_i^c pic是 gating network 分配给每个 expert 的权重,相当于多个 expert 齐心协力来得到当前样本 c c c的输出。
这是一个很自然的设计方式,但是存在一个问题——不同的 expert 之间的互相影响会非常大,一个expert的参数改变了,其他的都会跟着改变,即所谓牵一发而动全身。这样的设计,最终的结果就是一个样本会使用很多的expert来处理。于是,这篇文章设计了一种新的方式,调整了一下loss的设计,来鼓励不同的expert之间进行竞争: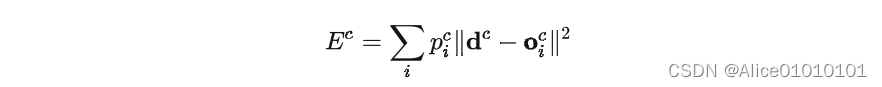
就是让不同的 expert 单独计算 loss,然后在加权求和得到总体的 loss。这样的话,每个专家,都有独立判断的能力,而不用依靠其他的 expert 来一起得到预测结果。下面是一个示意图: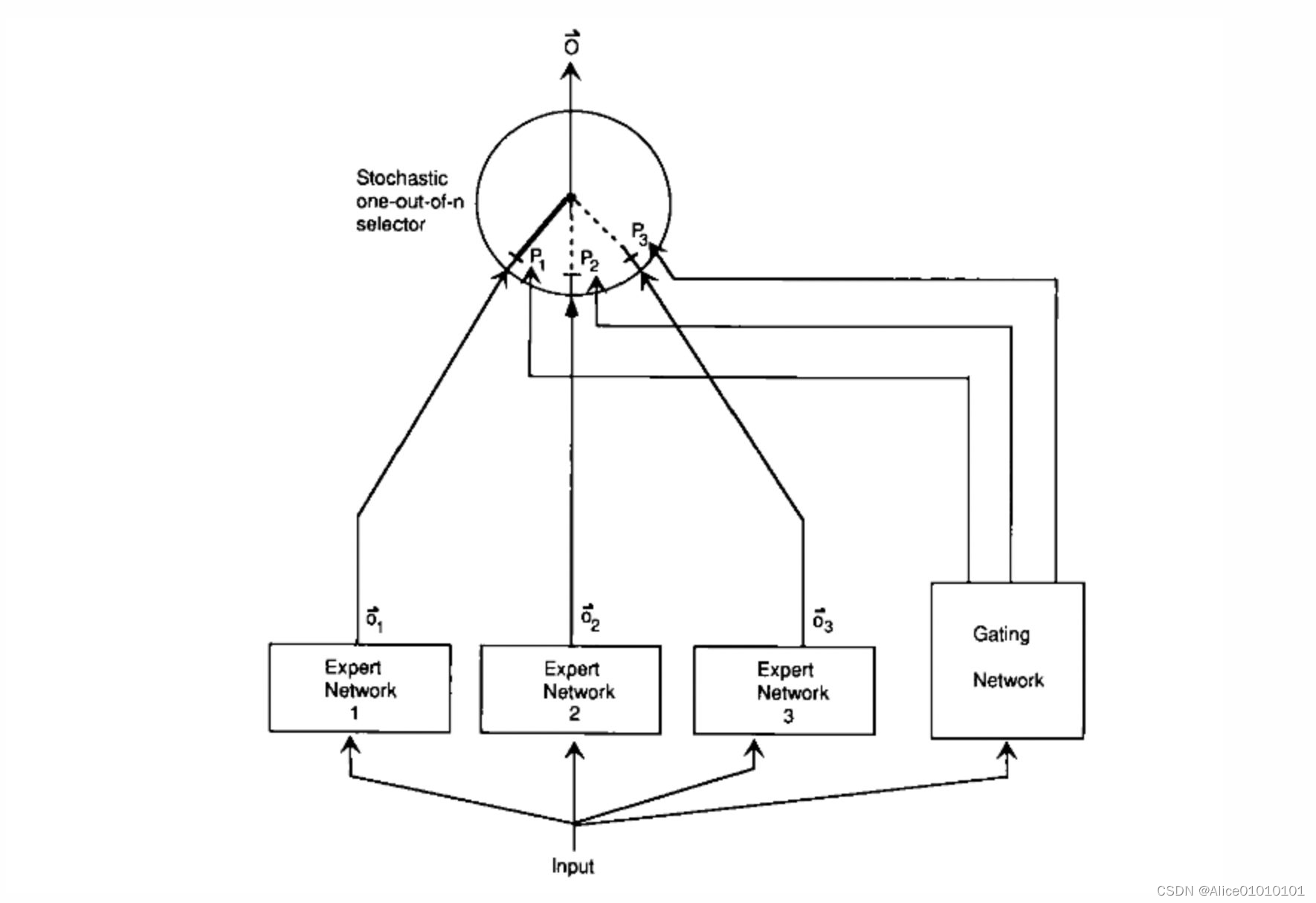
在这种设计下,我们将 experts 和 gating network 一起进行训练,最终的系统就会倾向于让一个 expert 去处理一个样本。
上面的两个 loss function,其实长得非常像,但是一个是鼓励合作,一个是鼓励竞争。这一点还是挺启发人的。
论文还提到另外一个很启发人的 trick,就是上面那个损失函数,作者在实际做实验的时候,用了一个变体,使得效果更好: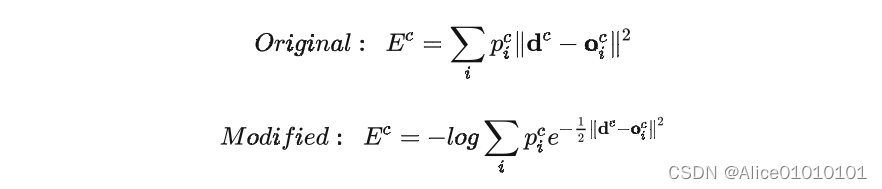
对比一下可以看出,在计算每个 expert 的损失之后,先把它给指数化了再进行加权求和,最后取了log。这也是一个我们在论文中经常见到的技巧。这样做有什么好处呢,我们可以对比一下二者在反向传播的时候有什么样的效果,使用 E c E^c Ec对第 i i i个 expert 的输出求导,分别得到: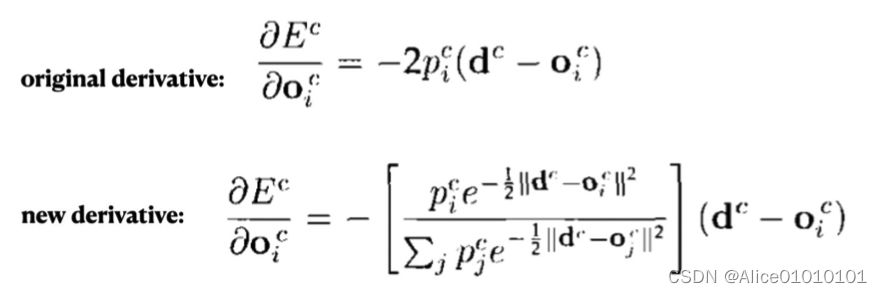
可以看到,前者的导数,只会跟当前 expert 有关,但后者则还考虑其他 experts 跟当前 sample c的匹配程度。换句话说,如果当前 sample 跟其他的 experts 也比较匹配,那么 E c E^c Ec对 第 i i i个 expert 的输出的导数也会相对更小一下。(其实看这个公式,跟我们现在遍地的对比学习loss真的很像!很多道理都是相通的)

二、Perceiver相关
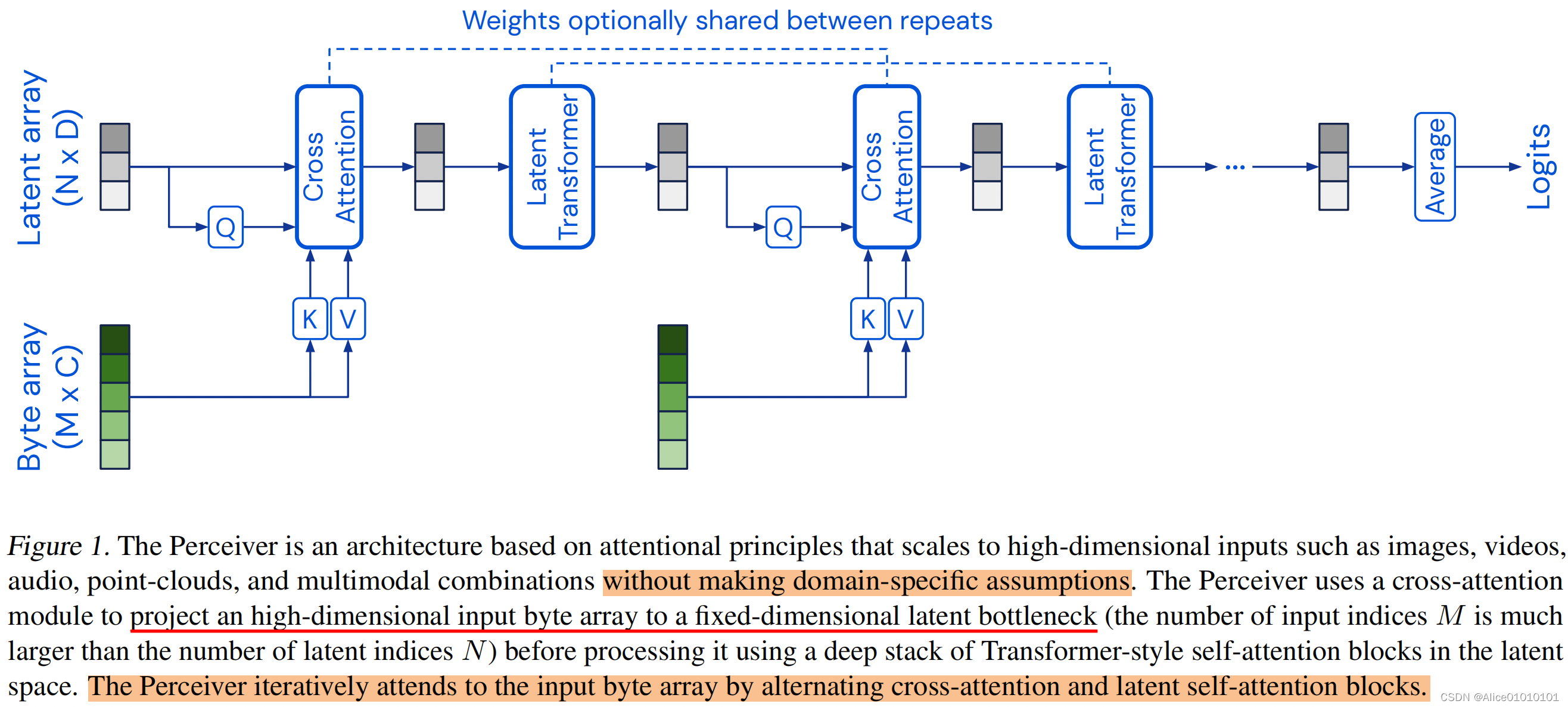
optical flow

- Task definition:Transfer
- Problem: No large-scale realistic training data!
- Typical protocol:
- Train on highly synthetic scenes(AutoFlow)
- Transfer to more realistic scenes(Sintel,KITTI)
三、多模态ViLT
特色:多模态论文,去除掉目标检测领域的Region Feature。在ViT之前,针对图像像素的处理,VLP主要选择目标检测器,使密集的图像像素生成为特征性强、离散化的表示。ViLT核心思路为参考ViT,将图像划分为patch,通过线性映射的方式将patch转换为embedding,避免繁琐的图像特征抽取的过程。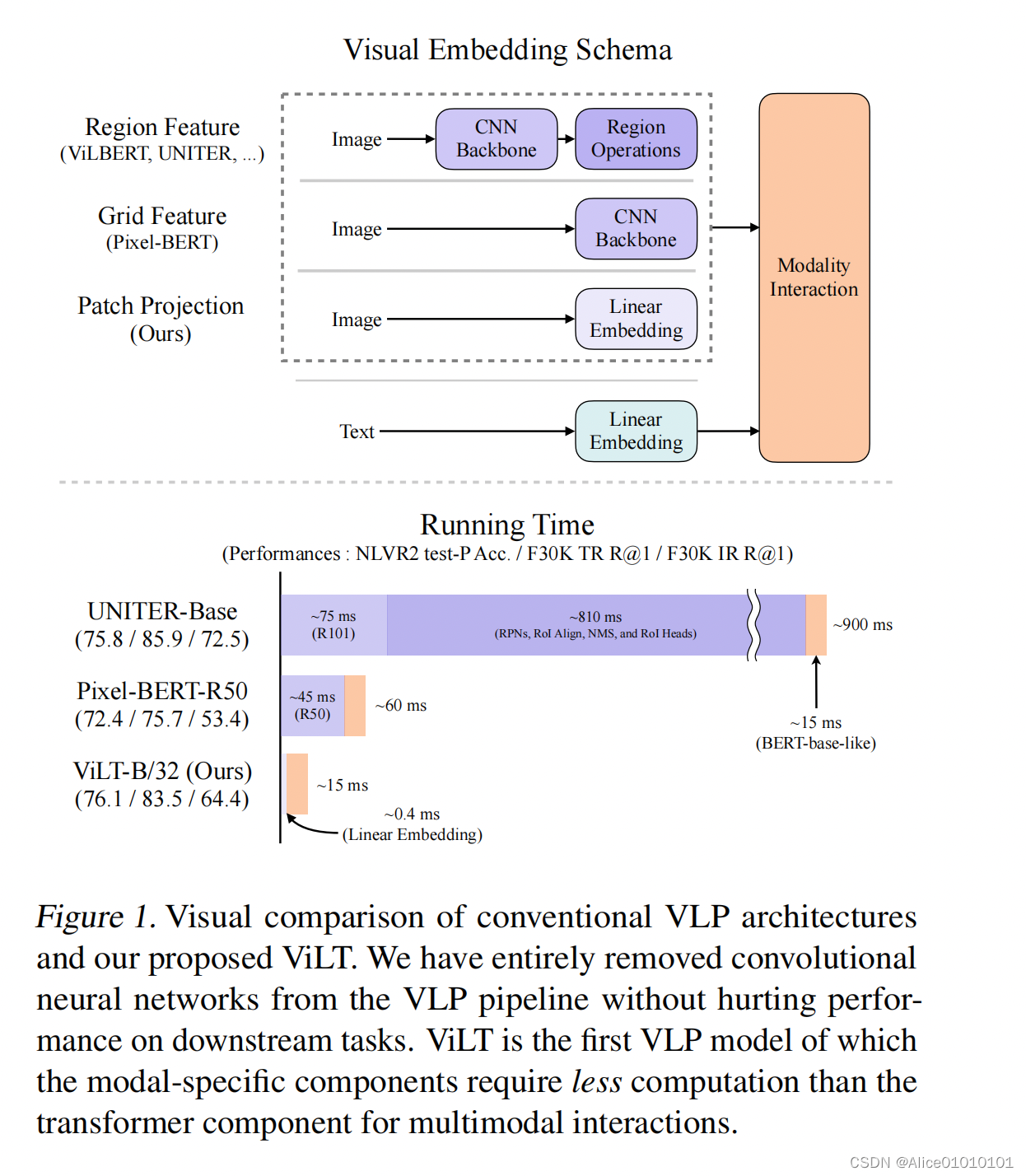
- ViLT is the simplest architecture by far for a vision-and-language model as it commissions the transformer module to extract and process visual features in place of a separate deep visual embedder. This design inherently leads to significant runtime and parameter efficiency.
- For the first time, we achieve competent performance on vision-and-language tasks without using region features or deep convolutional visual embedders in general.
- Also, for the first time, we empirically show that whole word masking and image augmentations that were unprecedented in VLP training schemes further drive downstream performance.
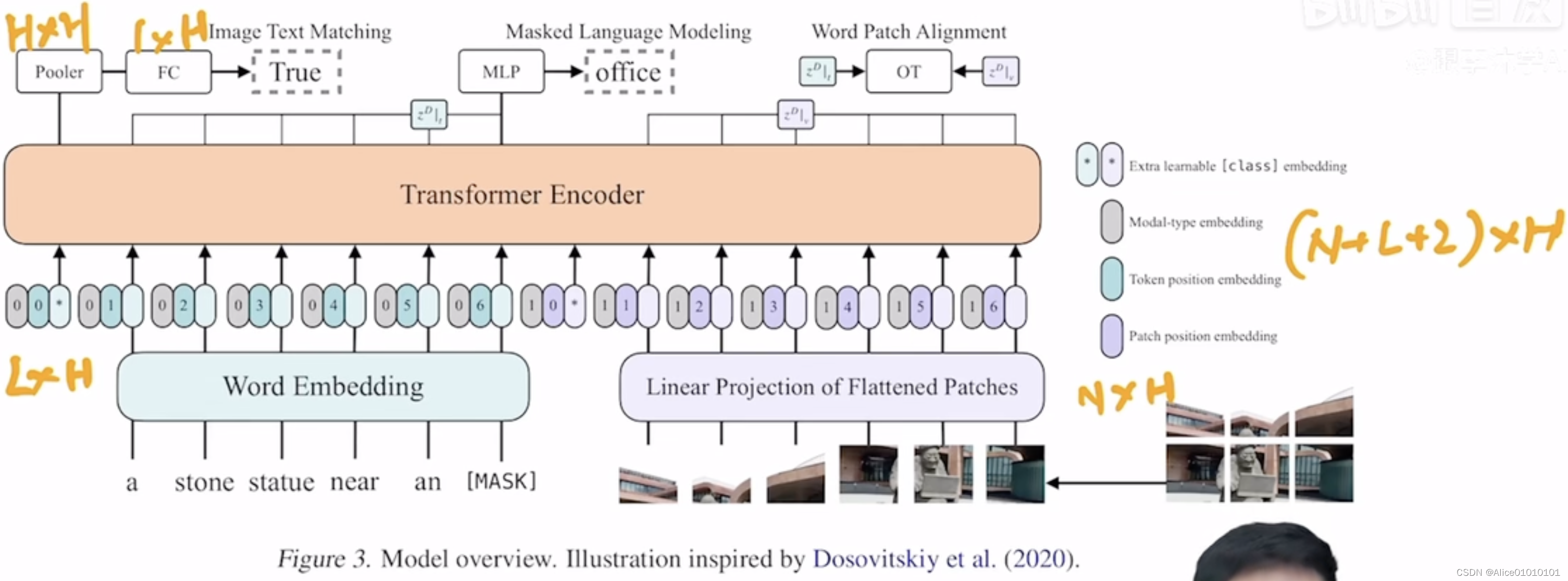
多模态需要保持文本和图像的匹配。所以在进行图像和文本的数据增强时,需要保持一致。
建议:读近期论文future work看是否有坑可以填。
边栏推荐
- 画法几何及工程制图考试卷A卷
- Why is pnpm hitting npm and yarn dimensionality reduction?
- Pagoda measurement - building small and medium-sized homestay hotel management source code
- RedisTemplate: error template not initialized; call afterPropertiesSet() before using it
- 15.1.1、md—md的基础语法,快速的写文本备忘录
- [Structure internal power practice] Structure memory alignment (1)
- [Structural Internal Power Cultivation] The Mystery of Enumeration and Union (3)
- sphinx matches the specified field
- Code Audit - PHP
- Beautifully painted MM set
猜你喜欢

Thinking and summary of the efficiency of IT R&D/development process specification

七夕看什么电影好?爬取电影评分并存入csv文件
How to make pictures clear in ps, self-study ps software photoshop2022, simple and fast use ps to make photos clearer and more textured

全面讲解GET 和 POST请求的本质区别是什么?原来我一直理解错了
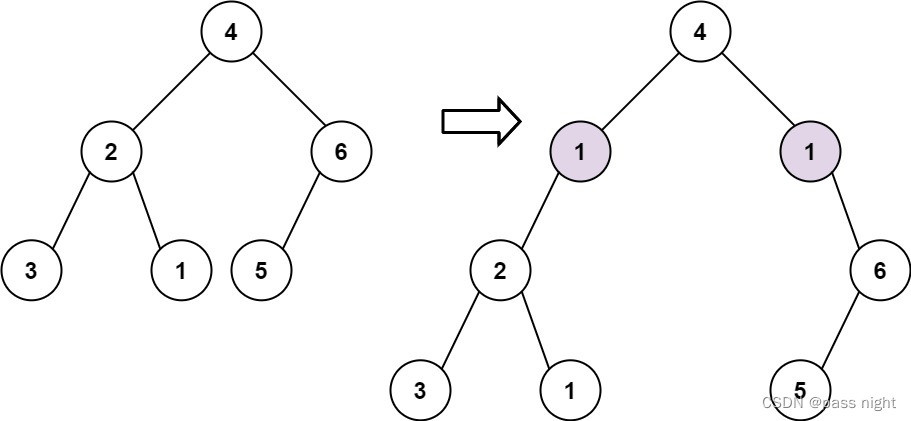
【LeetCode】623. 在二叉树中增加一行
使用 External Secrets Operator 安全管理 Kubernetes Secrets
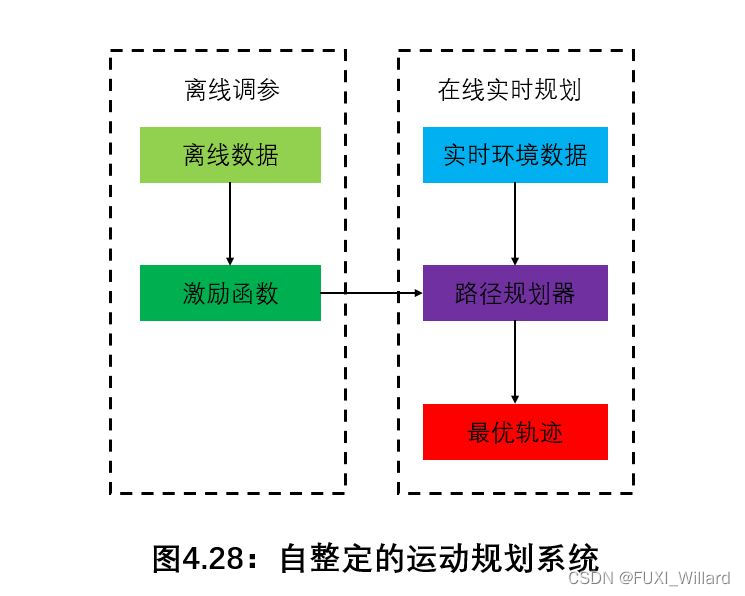
学习笔记14--机器学习在局部路径规划中的应用
嵌入式实操----基于RT1170 移植memtester做SDRAM测试(二十五)

代码审计—PHP
How to make a puzzle in PS, self-study PS software photoshop2022, PS make a puzzle effect
随机推荐
mySQL数据库初始化失败,有谁可以指导一下吗
DTcloud 装饰器
最 Cool 的 Kubernetes 网络方案 Cilium 入门教程
“充钱”也难治快手的“亏亏亏”?
Iptables implementation under the network limited (NTP) synchronization time custom port
工程制图知识点
pnpm 是凭什么对 npm 和 yarn 降维打击的
openpyxl操作Excel文件
Dynamic memory development (C language)
EA谈单机游戏:仍是产品组合中极其重要的部分
微信小程序请求封装
Thinking and summary of the efficiency of IT R&D/development process specification
D2--FPGA SPI interface communication2022-08-03
Long-term recruitment embedded development-Shenzhen Baoan
8.4模拟赛总结
苹果官网商店新上架Mophie系列Powerstation Pro、GaN充电头等产品
Detailed explanation of DNS query principle
[Structural Internal Power Cultivation] The Mystery of Enumeration and Union (3)
k-nearest neighbor fault monitoring based on multi-block information extraction and Mahalanobis distance
8.4 Summary of the mock competition