当前位置:网站首页>[neo4j] common operations of neo4j cypher and py2neo
[neo4j] common operations of neo4j cypher and py2neo
2022-07-05 07:30:00 【MatchaApril】
Cypher
Document links : https://neo4j.com/docs/cypher-manual/4.3/.
1. establish
- Create a node
create (n:teacher{name:“2”,id:”teacher1”}) return n - Create relationships
MATCH (a:TEST),(b:TEST)
WHERE a.name = ‘TEST-NAME’ AND b.name = ‘TEST-NAME1’
CREATE (a)-[r:RELTYPE] -> (b)
RETURN r
2. Inquire about
- Show all
MATCH(n) RETURN n - Show 20 Nodes
MATCH(n) RETURN n limit 20 - Query node
MATCH(n:User{name:“2”}) RETURN n - Query relationship
match ()-[r:watch]->() return r - Query nodes according to attributes
match(n:course) where (n.marked=TRUE) return count(n) - Query according to the relationship type
match(n)-[r]->(m) where type=“teach” return n - Query the number of nodes
MATCH(n:User{name:“2”}) RETURN count(n) - Query the number of nodes
MATCH(n:User{name:“2”}) RETURN count(n) - Query related nodes
match(n) where ((n)-[]-()) return n - It doesn't matter to query course node
match(n:course) where not ((n)-[]-()) return n - Query and course Unrelated nodes
match(n) where not ((n)-[]-(p:course)) return n - Query all labels of the node 、 Number of nodes per label
MATCH (n) RETURN distinct labels(n), count(*) - Inquire about ID It ends with ” mathematics ” The node of
match(n) where n.id ENDS WITH ‘ mathematics ’ return n - Inquire about ID The beginning is ” mathematics ” The node of
match(n) where n.id START WITH ‘ mathematics ’ return n
match(n) where n.id =~ ‘ mathematics .*’ return n - Inquire about ID The beginning is ”and”( Case insensitive ) The node of
match(n) where n.id =~ ‘(?!) mathematics .*’ return n - Inquire about ID It ends with ”.com” The node of
match(n) where n.id =~ ‘.*\.com’ return n - Inquire about ID contain ” mathematics ” The node of
match(n) where n.id CONTAINS ‘ mathematics ’ return n - The query contains attributes name The node of
match(n) where exists (n.name) return n - Inquire about A Type or B Type of relationship
match()->[r:A|:B]->() return r - Find all the shortest paths between nodes
match(n),(m),p=allShortestPaths((n)-[*]-(m)) - Find the shortest path between nodes , The maximum length of the path is 10
match(n),(m),p=shortestPath((n)-[*…10]-(m)) return p - Find the node 1~3 Jump in the relationship ( A little uncertain , Use with caution )
match(n)-[r:SHIP*1…3]-(m) - Query and display multiple relationships
MATCH p=()-[r:prerequisite]->(),q=()-[wr:taught]->() RETURN p,q
3. modify
Delete Used to delete graph elements ( node 、 Relationship 、 Or the path ), To delete the relationship connected with it, use detach delete.
remove Statement is used to delete attributes and labels of graph elements .
- clear database
match (n) detach delete n - Add the attribute of the node ( If the node does not exist, a new node will be created )
MERGE (n:Course) ON MATCH SET n.name=”yang” - Delete nodes and their related relationships
match (n:teacher) detach delete n - Delete node properties
match (n {name: “huzong”}) remove n.age - Delete node labels
match (n {name “huzong”}) remove n:teacher - Delete multiple labels of nodes
match (n {name “huzong”}) remove n:teacher:user - Delete node / Relationship
MATCH (n:User) -[r:study]-(p:Course{name:“f”}) DELETE n,r,p - Set up with course Properties of nodes on the path related to nodes
MATCH p = (t:course)-[r]-(A) FOREACH (n in nodes§| SET n.marked = TRUE )
4. Sort ORDER BY
Order by It's following RETURN perhaps WITH Clause of .
- Sort nodes according to attributes
MATCH (n) RETURN n.name ORDER BY n.name,n.id - The nodes are arranged in descending order
MATCH (n) RETURN n.name ORDER BY n.name DESC
5. Import csv file (load csv)
Than admin slow , Than py2neo fast .
- LOAD CSV FROM “file:///entities/teacher.csv” AS row For subsequent use row[0]、row[1] To read the corresponding information , If the file has a header , Then use row.id and row.name To read the corresponding attribute value . Here is the absolute path , Files to be placed in import Under the table of contents .
- if csv The documents are very large , Then use USING PERIODIC COMMIT LOAD CSV FROM “file:///entities/teacher.csv” AS row
6. Indexes
- Create index
create index on:Student(name) - Delete index
drop index on:Student(name) - Create unique index
create constraint on (s:Teacher) assert s.name is unique - Delete unique index
drop constraint on (s:Teacher) assert s.name is unique
py2neo
1. Connect to database
from py2neo import *
from py2neo.matching import *
test_graph = Graph( # Connect Neo4j,test_graph Name yourself , This is used for subsequent calls test_graph
"http://localhost:7474",
auth=("neo4j", "neo4j") # The former is the user name , Followed by password
)
Other header files that may be used :
from py2neo.bulk import create_nodes
from py2neo.bulk import merge_nodes
from py2neo.bulk import create_relationships
2. Create nodes
a = Node("Person", name="Alice") # The front is the label ,name For attributes
b = Node("Person", name="Bob")
test_graph.create(a) # Put it into the database
test_graph.create(b)
a.add_label("Employee") # Add tags ,a The label of becomes {
'Employee', 'Person'}
print(set(a.labels)) # a Node label set aggregate
a.remove_label("Employee") # Remove the label
print(a.has_label("Person")) # a If there is a label Person Then return to True
a.clear_labels() # Delete all labels of this node
other :
node[name] Return a file named name The value of the property .
node[name] = value Name it name The value of the property of is set to value.
del node[name] Remove from this node the name name Properties of .len(node) Returns the number of attributes on this node .
dict(node) Return the dictionary of all attributes in this node .
clear( ) Delete all attributes from this node .
values( ) Returns a list of all attribute values .
get( name , Default = nothing ) Return a file named name The value of the property .
3. Create relationships
ab = Relationship(a, 'CALL', b) # The type of relationship is "CALL", Both relationships have attributes count, And the value is 1
ab['count'] = 1 # Set the value of the relationship
KNOWS = Relationship.type("KNOWS") # The relationship of another expression is established
ba = KNOWS(b, a)
test_graph.create(ab)
test_graph.create(ba)
ab['count'] += 1 # node / Attribute assignment of relation
test_graph.push(ab) # Update of attribute value
print(ba.nodes) # Print nodes Start node and end node 2 Tuples .ba.end_node Indicates the end node .ba.start_node Indicates the start node .
other :
del ba[‘count’] Delete attribute .
clear( ) Delete all attributes in this relationship .
…
4. Query nodes
nodes = NodeMatcher(test_graph) # NodeMatcher Node matching
keanu = nodes.match("Person", name="Keanu Reeves").first() # For simple equal matching of tags and attributes
print(keanu)
nodes.match("Person", name=STARTS_WITH("John")).all() # Match name with “John” All nodes at the beginning ,
nodes.match("Person", born=ALL(GE(1964), LE(1966))).all() # Match was born in 1964 - 1966 year ( contain ) All of us
nodeList = list(nodes.match().where("_.name=~‘ Yang .*’")) # Find a name to “ Yang ” All nodes at the beginning
for i in nodeList:
print(i)
nodeList = list(nodes.match().where("_.name=~‘ Yang .*’")).order_by("_.name").limit(4) # add “ Sort ”“ Limit the number of returns ”
other :
IS_NULL( ),IS_NOT_NULL( ) Empty check predicate .
EQ( value ),NE( value ). Sort predicate LT( value ),LE( value ),GT( value ),GE( value ) Equality predicate .
…
5. Query relationship
relation_matcher = RelationshipMatcher(test_graph)
re = relation_matcher.match((a,), r_type="KNOWS").first()
print(re)
reList = list(relation_matcher.match()) # Query all relationships
6. route
abc = Path(a, "CALL", b, Relationship(c, "KNOWS", b), c)
print(abc.nodes)
print(abc.relationships)
d, e = Node(name="Dave"), Node(name="Eve")
de = Path(d, "KNOWS", e)
abcde = Path(abc, "KNOWS", de) # Two Path Constitute a Path
for relationship in abcde.relationships: # Traverse Path Relationship on
print(relationship)
other :
types( ) Returns a collection of all relationship types that exist on this path .
start_node.end_node.
…
7. Subgraphs Subgraph
A subgraph is an arbitrary set of nodes and relationships . A subgraph must contain at least one node , The empty subgraph should be None Express .
friends = ab | ba # Combine
test_graph.create(friends)
print(friends)
other :
keys( ).labels( ).nodes.relationships.types( ).
subgraph | other | …: Combine .
subgraph & other & …: intersection .
subgraph - other - …: reduce .
subgraph ^ other ^ …: Return to a new subgraph , The nodes and relationships contained in this subgraph only appear in subgraph Medium or other in , Nodes connected by relationships are also included in the new subgraph , Whether these nodes exist in subgraph perhaps other in .
8. call cypher Internal methods
You can use run Method to directly execute Cypher sentence , It returns a cursor cursors,cursors The results must be presented by traversal .
match_str = "match p=shortestPath((m:m Of label{name:'m Of name Property value '})-[r*1..4]-(n:n Of label{name:'name Property value '})) return p"
p1 = test_graph.run(match_str)
for p in p1:
print(p)
9. Import csv File and process
import csv
with open('F:/neo4j/data/MOOCCube/subject/ Computer science and technology .csv', 'r', encoding='UTF-8') as f:
next(f) # If the file has a header , You can make the file read from the second line
reader = csv.reader(f)
for item in reader:
# print(" The current number of lines :", reader.line_num, " Current content :", item)
a = Node("Course", name=item[1], ID=item[0], subject=' Computer science and technology ')
g.create(a)
Neo4j Database connection
stay cmd Input from the command line neo4j.bat console, After loading, open the web page in the browser http://localhost:7474/ You can use .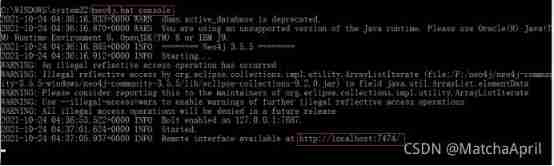
Other minor uses
1.neo4j–Cypher Grammar practice (WITH、 FOREACH、Aggregation、UNWIND、UNION、CALL):
link : https://blog.csdn.net/qq_37503890/article/details/101565515?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2defaultCTRLISTdefault-1.no_search_link&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2defaultCTRLISTdefault-1.no_search_link
2.Py2neo Partial right node、relations、subgraph The little usage of :
link : https://blog.csdn.net/claroja/article/details/84287093
3. Application of some methods in official documents :
link : https://blog.csdn.net/Elenstone/article/details/106452464
边栏推荐
- What if the DataGrid cannot see the table after connecting to the database
- Simple operation with independent keys (hey, a little fancy) (keil5)
- Web page Chinese display (print, etc.) GBK error, solution, software
- Today, share the wonderful and beautiful theme of idea + website address
- The number of occurrences of numbers in the offer 56 array (XOR)
- How to delete the virus of inserting USB flash disk copy of shortcut to
- How can Oracle SQL statements modify fields that are not allowed to be null to allow nulls?
- C learning notes
- Database SQL practice 4. Find the last of employees in all assigned departments_ Name and first_ name
- Deepin, help ('command ') output saved to file
猜你喜欢
Anaconda navigator click open no response, can not start error prompt attributeerror: 'STR' object has no attribute 'get‘
第 2 章:小试牛刀,实现一个简单的Bean容器

Daily Practice:Codeforces Round #794 (Div. 2)(A~D)

SD_ CMD_ RECEIVE_ SHIFT_ REGISTER
Light up the running light, rough notes for beginners (1)
Microservice registry Nacos introduction

The problem of configuring opencv in qt5.13.2 is solved in detail
HDU1232 畅通工程(并查集)
Jenkins reported an error. Illegal character: '\ufeff'. Class, interface or enum are required
611. Number of effective triangles
随机推荐
Pytorch has been installed in anaconda, and pycharm normally runs code, but vs code displays no module named 'torch‘
Basic knowledge of public security -- FB
With the help of Navicat for MySQL software, the data of a database table in different or the same database link is copied to another database table
Ggplot2 drawing learning notes in R
CADD course learning (6) -- obtain the existing virtual compound library (drugbank, zinc)
Detailed explanation of miracast Technology (I): Wi Fi display
Use of Pai platform
Raspberry pie 4B arm platform aarch64 PIP installation pytorch
selenium 元素定位
Play with grpc - go deep into concepts and principles
大学生活的自我总结-大一
ORACLE CREATE SEQUENCE,ALTER SEQUENCE,DROP SEQUENCE
GBK error in web page Chinese display (print, etc.), solution
Deepin get file (folder) list
Basic series of SHEL script (I) variables
Import CV2, prompt importerror: libcblas so. 3: cannot open shared object file: No such file or directory
611. Number of effective triangles
Brief description of inux camera (Mipi interface)
R language learning notes 1
The mutual realization of C L stack and queue in I