当前位置:网站首页>【点云处理之论文狂读前沿版11】—— Unsupervised Point Cloud Pre-training via Occlusion Completion
【点云处理之论文狂读前沿版11】—— Unsupervised Point Cloud Pre-training via Occlusion Completion
2022-07-03 08:53:00 【LingbinBu】
OcCo:Unsupervised Point Cloud Pre-training via Occlusion Completion
摘要
- 方法: 提出一种用于点云的预训练方法Occlusion Completion (OcCo)
- 技术细节:
- mask相机视角里被遮挡的点
- 学习一个encoder-decoder模型,用于重建被遮挡的点
- 使用encoder的权值作为下游点云任务的初始化
- 应用: object classification & part-based and semantic segmentation
- 代码:https://github.com/hansen7/OcCo (支持PyTorch和TensorFlow)
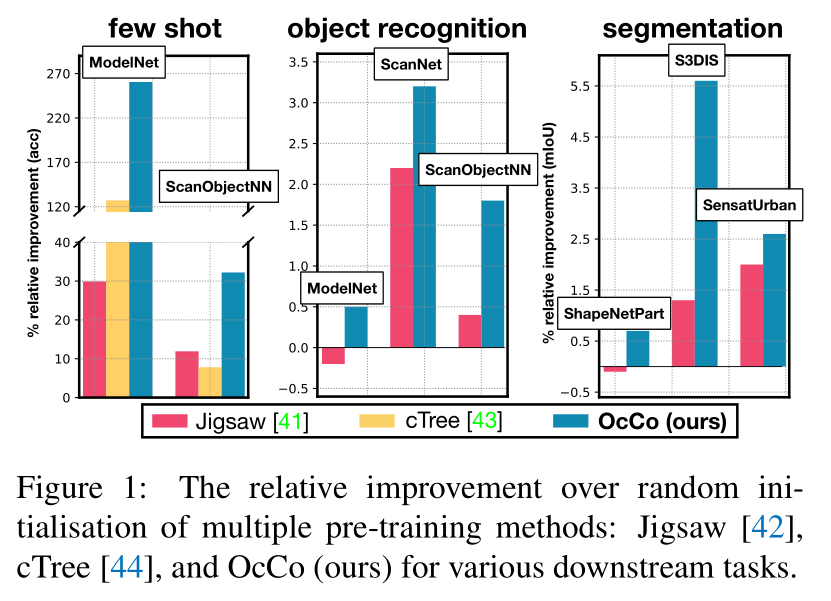
引言
OcCo有着如下的性质:
- 在小样本学习(few-shot learning)实验中能够提高采样效率
- 在分类和分割任务中能提高泛化性
- 在微调后能更容易找到局部最小值
- 通过network dissection能够描述更具语义的表示
- 在jittering, translation 和 rotation 变换下仍能保持更好的分类质量

方法
记 P \mathcal{P} P为3D欧式空间中的一组点云, P = { p 1 , p 2 , … , p n } \mathcal{P}=\left\{p_{1}, p_{2}, \ldots, p_{n}\right\} P={ p1,p2,…,pn},其中每个点 p i p_{i} pi是包含坐标 ( x i , y i , z i ) \left(x_{i}, y_{i}, z_{i}\right) (xi,yi,zi)和其他特征(颜色和法向量)的向量。先从occlusion mapping o ( ⋅ ) o(\cdot) o(⋅)开始描述,然后再介绍ompletion model c ( ⋅ ) c(\cdot) c(⋅),伪代码和结构细节在附录里展示。
Generating Occlusions
定义一个randomised occlusion mapping o : P → P o: \mathbb{P} \rightarrow \mathbb{P} o:P→P ,其中 P \mathbb{P} P是点云空间,描述的是从全部点云 P \mathcal{P} P 到遮挡点云 P ~ \tilde{\mathcal{P}} P~之间的映射。该映射通过移除 P \mathbb{P} P中那些无法从特定视点看到的点来构建 P ~ \tilde{\mathcal{P}} P~,步骤如下:
- 世界坐标系中的完整点云根据相机的视点被投射到相机坐标系中的坐标上
- 确定该视点下被遮挡的点
- 再将相机坐标系中的点反投影到世界坐标系
Viewing the point cloud from a camera
通过针孔相机定义从3D世界坐标系到特定相机坐标系之间的映射:

其中 ( x , y , z ) (x, y, z) (x,y,z)是原始点云在世界坐标系中的坐标,相机视点被旋转矩阵 R \mathbf{R} R和平移向量 t \mathbf{t} t决定。相机内参 K \mathbf{K} K由焦距 f f f,skewness γ \gamma γ,成像的宽 w w w,高 h h h决定。在给定上述参数后,就可以计算点在相机坐标系中的坐标 ( x c a m , y c a m , z c a m ) \left(x_{\mathrm{cam}}, y_{\mathrm{cam}}, z_{\mathrm{cam}}\right) (xcam,ycam,zcam)。
Determining occluded points
通过两种方式处理点 ( x c a m , y c a m , z c a m ) \left(x_{\mathrm{cam}}, y_{\mathrm{cam}}, z_{\mathrm{cam}}\right) (xcam,ycam,zcam) :
- 相机坐标系中的3D点 ( x c a m , y c a m , z c a m ) \left(x_{\mathrm{cam}}, y_{\mathrm{cam}}, z_{\mathrm{cam}}\right) (xcam,ycam,zcam)
- 深度为 z c a m z_{\mathrm{cam}} zcam的2D像素坐标 ( f x c a m / z c a m , f y c a m / z c a m ) \left(f x_{\mathrm{cam}} / z_{\mathrm{cam}}, f y_{\mathrm{cam}} / z_{\mathrm{cam}}\right) (fxcam/zcam,fycam/zcam)
通过这种方式,如果一些通过投影得到的点有相同的像素坐标,但是深度值却不相同,那么这些点间可能会存在遮挡关系。为了确定哪些点是被遮挡了,我们首先利用Delaunay triangulation来重建一个polygon mesh,然后移除属于hidden surface的点,这个hidden surface通过 z-buffering决定。
Mapping back from camera frame to world frame
一旦移除掉遮挡的点,我们就可以重新将点投射原先的世界坐标系中,使用的原理是公式1的逆变换。因此randomised occlusion mapping o ( ⋅ ) o(\cdot) o(⋅)的构造步骤如下:
- 固定一组初始点云 P \mathcal{P} P
- 给定相机的内参矩阵 K \mathbf{K} K,多个视点下的外参 [ [ R 1 ∣ t 1 ] , … , [ R V ∣ t V ] ] \left[\left[\mathbf{R}_{1} \mid \mathbf{t}_{1}\right], \ldots,\left[\mathbf{R}_{V} \mid \mathbf{t}_{V}\right]\right] [[R1∣t1],…,[RV∣tV]],其中 V V V表示视点的数量
- 对于每个视点 v ∈ [ V ] v \in[V] v∈[V],使用公式1将 P \mathcal{P} P都投射到对应的相机坐标系中
- 找到遮挡点并移除这些点
- 将剩下来的点反投影到世界坐标系中,对于每个视点 v ∈ [ V ] v \in[V] v∈[V],都得到最终的遮挡点云 P ~ v \tilde{\mathcal{P}}_{v} P~v
The Completion Task
给定通过遮挡映射 o ( ⋅ ) o(\cdot) o(⋅)得到的点云 P ~ \tilde{\mathcal{P}} P~,补全任务的目标便是从 P ~ \tilde{\mathcal{P}} P~学习一个completion mapping c : P → P c: \mathbb{P} \rightarrow \mathbb{P} c:P→P,用于补全点云 P ^ \hat{\mathcal{P}} P^。如果满足 E P ~ ∼ o ( P ) ℓ ( c ( P ~ ) , P ) → 0 \mathbb{E}_{\tilde{\mathcal{P}} \sim o(\mathcal{P})} \ell(c(\tilde{\mathcal{P}}), \mathcal{P}) \rightarrow 0 EP~∼o(P)ℓ(c(P~),P)→0,那么说明completion mapping 是准确的,其中 ℓ ( ⋅ , ⋅ ) \ell(\cdot, \cdot) ℓ(⋅,⋅)为损失函数。补全模型的结构是一个encoder-decoder的网络,encoder将遮挡的网络映射为一个向量,decoder对点云进行补全。在预训练后,encoder的权重可以作为下游任务的初始值。
实验
OcCo Pre-Training Setup
在所有的实验中都使用ModelNet40作为预训练数据集。相机的内参设置为 { f = 1000 , γ = 0 , w = 1600 , h = 1200 } \left\{ {f=1000,\gamma=0,w=1600,h=1200} \right\} { f=1000,γ=0,w=1600,h=1200} 。对于每组点云,随机选择10组视点,视点旋转不同,平移设置为0。
completion model中,encoder可以设置为PointNet, PCN 和 DGCNN。decoder选择folding操作,重建步骤分为两步,第一步将1024维的遮挡向量转换成包含1024个点的coarse点云 P ^ coarse \hat{\mathcal{P}}_{\text {coarse }} P^coarse ,然后对 P ^ coarse \hat{\mathcal{P}}_{\text {coarse }} P^coarse 中的每个点都使用 4 × 4 4 \times 4 4×4的2D网格重建带有16384个点的fine形状 P ^ fine \hat{\mathcal{P}}_{\text {fine }} P^fine ,使用Chamfer Distance (CD)作为预测 P ^ \hat{\mathcal{P}} P^和ground truth P \mathcal{P} P之间的损失函数:
C D ( P ^ , P ) = 1 ∣ P ^ ∣ ∑ x ^ ∈ P ^ min x ∈ P ∥ x ^ − x ∥ 2 + 1 ∣ P ∣ ∑ x ∈ P min x ^ ∈ P ^ ∥ x − x ^ ∥ 2 \begin{aligned} \mathrm{CD}(\hat{\mathcal{P}}, \mathcal{P}) &= \frac{1}{|\hat{\mathcal{P}}|} \sum_{\hat{x} \in \hat{\mathcal{P}}} \min _{x \in \mathcal{P}}\|\hat{x}-x\|_{2}+\frac{1}{|\mathcal{P}|} \sum_{x \in \mathcal{P}} \min _{\hat{x} \in \hat{\mathcal{P}}}\|x-\hat{x}\|_{2} \end{aligned} CD(P^,P)=∣P^∣1x^∈P^∑x∈Pmin∥x^−x∥2+∣P∣1x∈P∑x^∈P^min∥x−x^∥2
最终的补全模型损失是coarse和fine形状的Chamfer distances加权和:
ℓ : = CD ( P ^ coarse , P coarse ) + α C D ( P ^ fine , P fine ) \ell:=\operatorname{CD}\left(\hat{\mathcal{P}}_{\text {coarse }}, \mathcal{P}_{\text {coarse }}\right)+\alpha \mathrm{CD}\left(\hat{\mathcal{P}}_{\text {fine }}, \mathcal{P}_{\text {fine }}\right) ℓ:=CD(P^coarse ,Pcoarse )+αCD(P^fine ,Pfine )
Fine-Tuning Setup
Few-shot learning
小样本学习的目标是使用十分有限的数据训练精确的模型,在训练时,随机选择 K K K个classes,每个category都包含 N N N个样本。
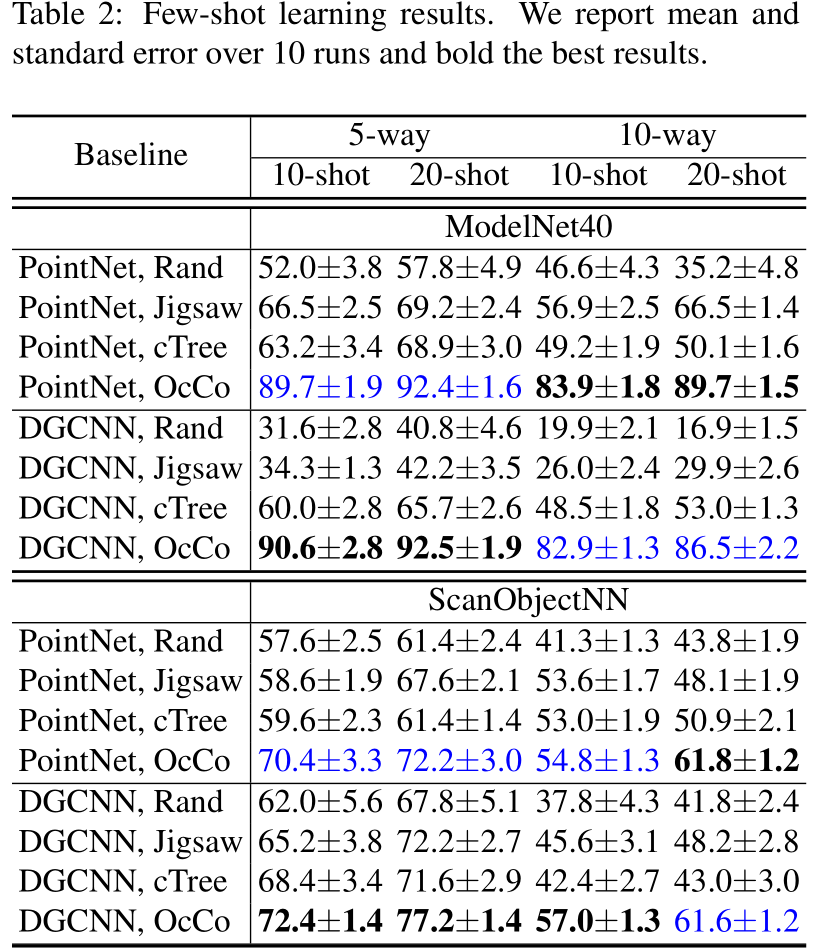
Object classification

Part segmentation

Semantic segmentation


分析
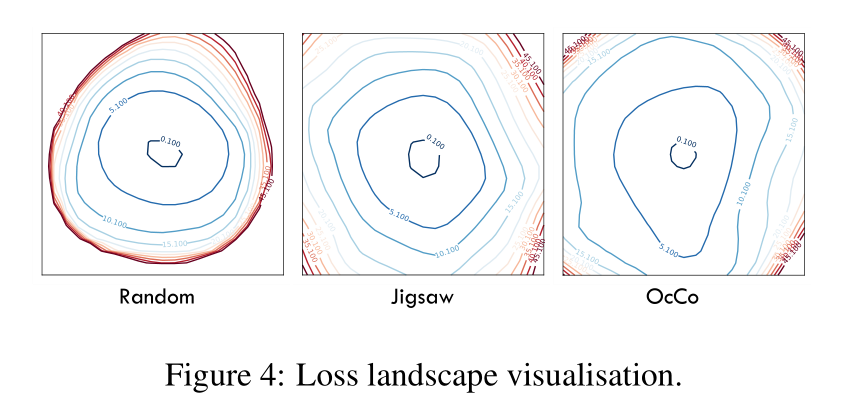
Visualisation of optimisation landscape
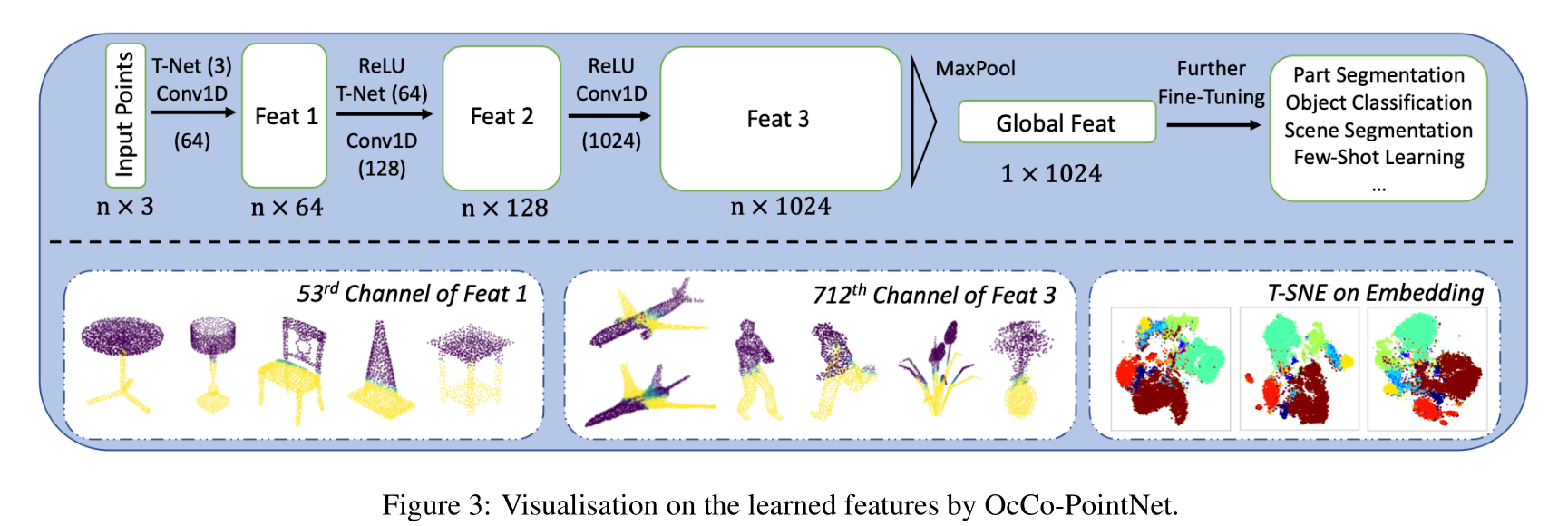
Visualisation of learned features
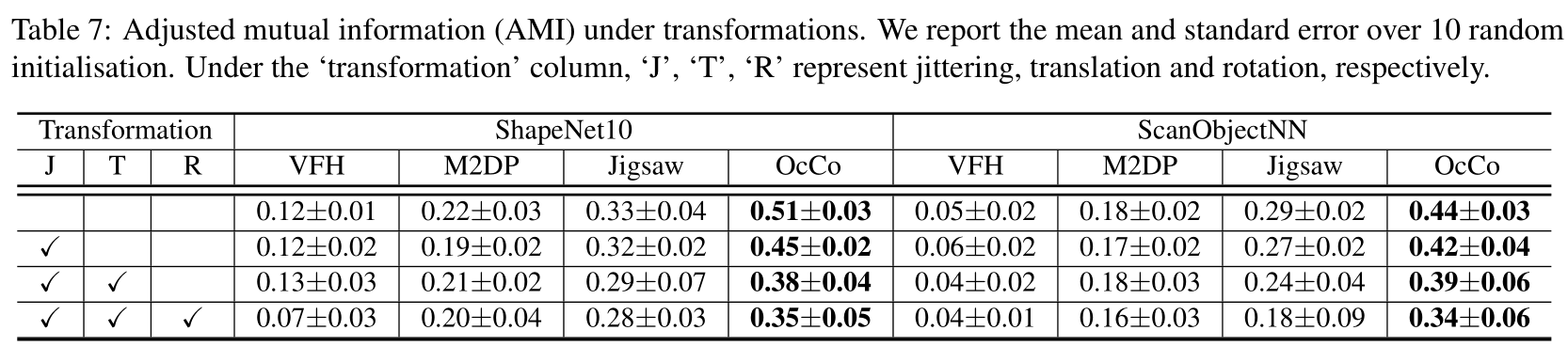
Unsupervised mutual information probe
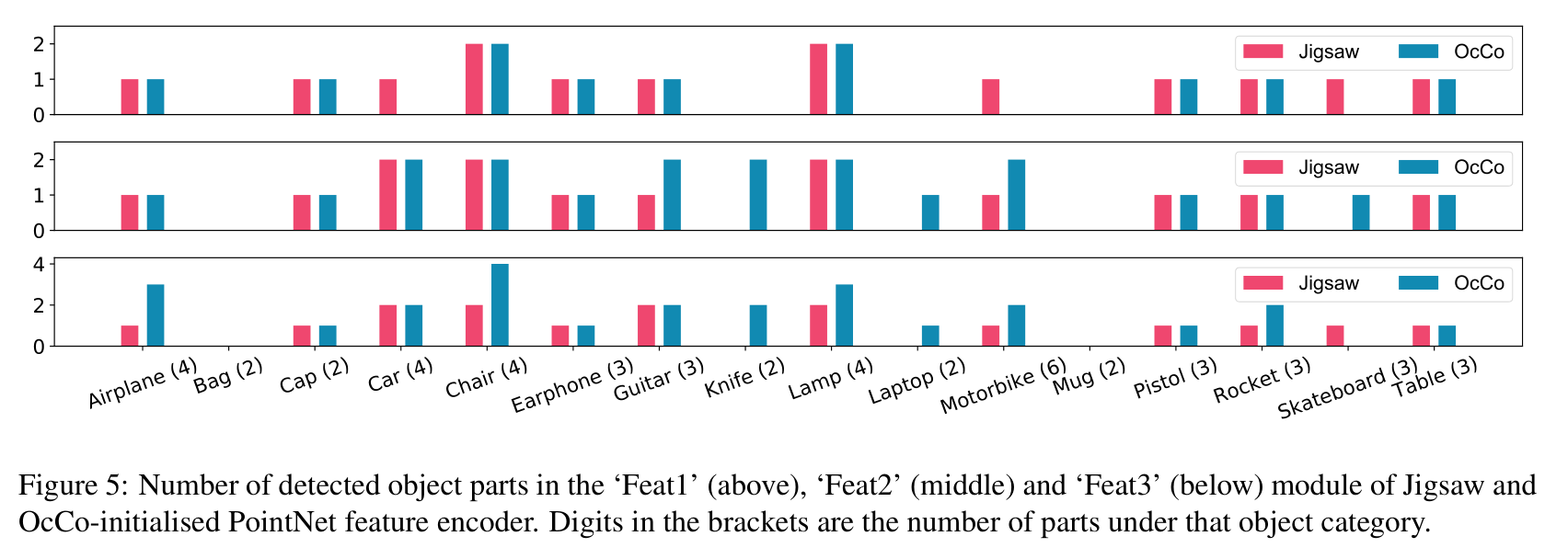
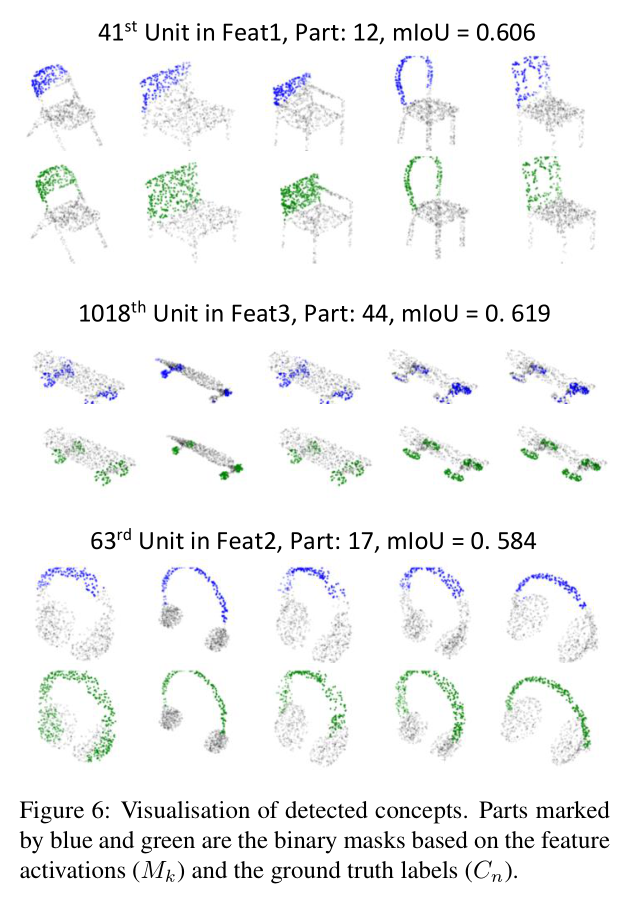
Detection of semantic concepts
讨论
在未来,设计一个显示考虑遮挡步骤的补全模型会更有趣。该模型可能收敛的更快,需要更少的参数,在训练时也可以当作很强的偏置。
生词
- a flurry of 许多的
边栏推荐
- Find the combination number acwing 886 Find the combination number II
- LeetCode 241. Design priorities for operational expressions
- 20220630 learning clock in
- Data mining 2021-4-27 class notes
- LeetCode 324. Swing sort II
- Severity code description the project file line prohibits the display of status error c2440 "initialization": unable to convert from "const char [31]" to "char *"
- LeetCode 438. 找到字符串中所有字母异位词
- Too many open files solution
- 我們有個共同的名字,XX工
- [point cloud processing paper crazy reading classic version 7] - dynamic edge conditioned filters in revolutionary neural networks on Graphs
猜你喜欢

状态压缩DP AcWing 91. 最短Hamilton路径

On the setting of global variable position in C language

Phpstudy 80 port occupied W10 system

【点云处理之论文狂读前沿版10】—— MVTN: Multi-View Transformation Network for 3D Shape Recognition
Find the combination number acwing 886 Find the combination number II

Data mining 2021-4-27 class notes

Slice and index of array with data type
AcWing 787. 归并排序(模板)
TP5 multi condition sorting

Instant messaging IM is the countercurrent of the progress of the times? See what jnpf says
随机推荐
LeetCode 30. 串联所有单词的子串
cres
[point cloud processing paper crazy reading classic version 14] - dynamic graph CNN for learning on point clouds
The "booster" of traditional office mode, Building OA office system, was so simple!
LeetCode 1089. Duplicate zero
PIC16F648A-E/SS PIC16 8位 微控制器,7KB(4Kx14)
传统办公模式的“助推器”,搭建OA办公系统,原来就这么简单!
[advanced feature learning on point clouds using multi resolution features and learning]
树形DP AcWing 285. 没有上司的舞会
Solution of 300ms delay of mobile phone
LeetCode 532. K-diff number pairs in array
LeetCode 57. Insert interval
LeetCode 515. 在每个树行中找最大值
Character pyramid
【点云处理之论文狂读前沿版10】—— MVTN: Multi-View Transformation Network for 3D Shape Recognition
Method of intercepting string in shell
Basic knowledge of network security
状态压缩DP AcWing 291. 蒙德里安的梦想
What are the stages of traditional enterprise digital transformation?
Divide candy (circular queue)