当前位置:网站首页>Aike AI frontier promotion (7.3)
Aike AI frontier promotion (7.3)
2022-07-03 16:27:00 【Zhiyuan community】
LG - machine learning CV - Computer vision CL - Computing and language AS - Audio and voice RO - robot
Turn from love to a lovely life
Abstract : Use data pruning to overcome the power-law expansion rate of Neural Networks 、 Generative neural human radiation field 、 Theoretical analysis of deep learning methods in reverse problems 、 A critical review of Bayesian Causal Inference 、 Reproducible efficient collaborative optimization benchmark 、 Based on differentiable attitude estimation 3D Multitarget tracking 、 Refine the model failure mode as the potential space direction 、 A factually enhanced language model for open text generation 、 Neural deformable voxel mesh for fast optimization of dynamic view synthesis
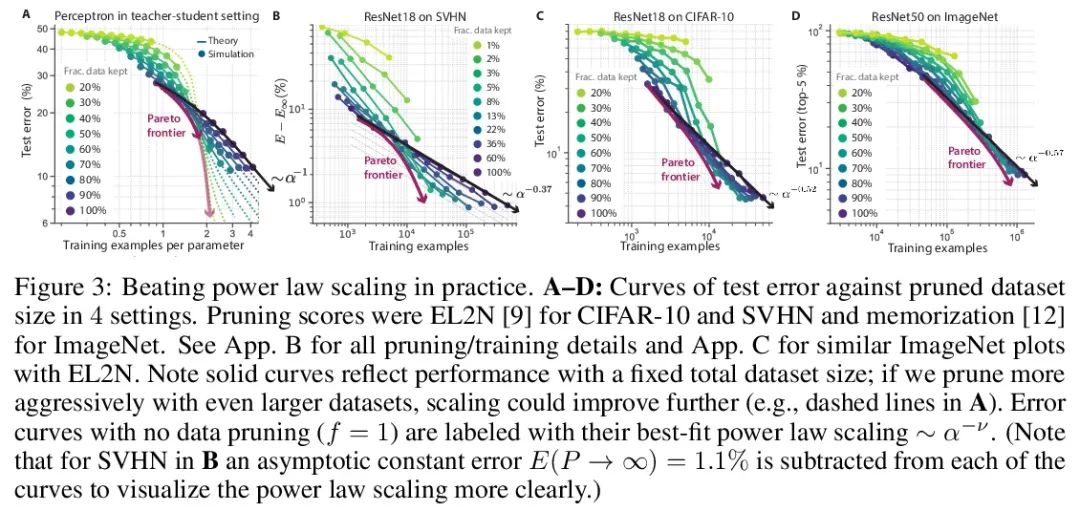
1、[LG] Beyond neural scaling laws: beating power law scaling via data pruning
B Sorscher, R Geirhos, S Shekhar, S Ganguli, A S. Morcos
[Stanford University & University of Tübingen & Meta AI]
Transcendental neural scaling law : Defeat power-law scaling with data pruning . The widely observed neural scaling law , That is, the error varies with the size of the training set 、 Model size or both exponentially decreases , Promote the deep learning performance to improve significantly . However , Achieving these improvements through expansion alone requires considerable computing and energy costs . This paper focuses on the proportional relationship between error and data set size , And it shows that in theory and practice , If there are high-quality data pruning indicators , Arrange the training samples in the order that they should be discarded , Achieve any trimmed dataset size , You can break through the power-law proportion , Reduce it to an exponential ratio . This paper tests the size of this new exponential scaling prediction and pruning data set based on experience , Indeed observed in CIFAR10、SVHN and ImageNet Trained on ResNets The scaling performance of is better than power-law scaling . In view of the importance of finding high-quality pruning indicators , stay ImageNet Yes 10 The first large-scale benchmark study was carried out on different data pruning indicators . It is found that most of the existing high-performance indicators are ImageNet Poor scalability on , The best indicator is computationally intensive , And you need to label every picture . therefore , This paper develops a new simple 、 cheap 、 Scalable self-monitoring pruning index , Its performance is equivalent to the best supervision index . The work of this paper shows that , Finding good data pruning indicators may provide a feasible path , To greatly improve the neuroscaling law , Reduce the resource cost of modern deep learning .
Widely observed neural scaling laws, in which error falls off as a power of the training set size, model size, or both, have driven substantial performance improvements in deep learning. However, these improvements through scaling alone require considerable costs in compute and energy. Here we focus on the scaling of error with dataset size and show how both in theory and practice we can break beyond power law scaling and reduce it to exponential scaling instead if we have access to a high-quality data pruning metric that ranks the order in which training examples should be discarded to achieve any pruned dataset size. We then test this new exponential scaling prediction with pruned dataset size empirically, and indeed observe better than power law scaling performance on ResNets trained on CIFAR10, SVHN, and ImageNet. Given the importance of finding high-quality pruning metrics, we perform the first large-scale benchmarking study of ten different data pruning metrics on ImageNet. We find most existing high performing metrics scale poorly to ImageNet, while the best are computationally intensive and require labels for every image. We therefore developed a new simple, cheap and scalable self-supervised pruning metric that demonstrates comparable performance to the best supervised metrics. Overall, our work suggests that the discovery of good data-pruning metrics may provide a viable path forward to substantially improved neural scaling laws, thereby reducing the resource costs of modern deep learning.
https://arxiv.org/abs/2206.14486




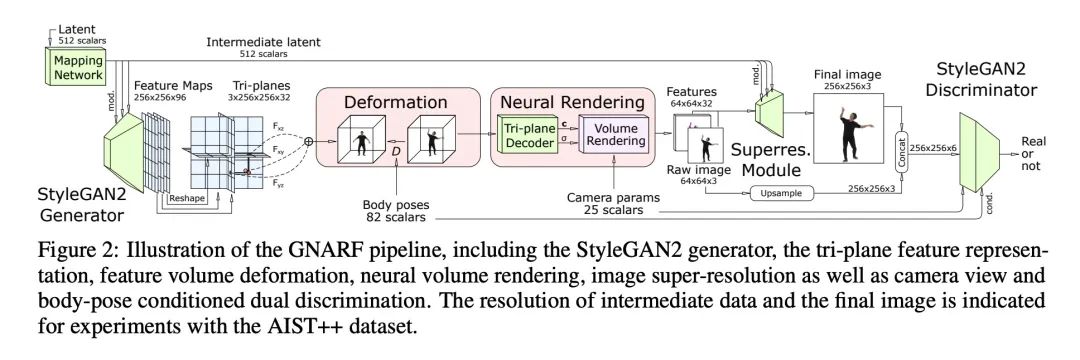
2、[CV] Generative Neural Articulated Radiance Fields
A W. Bergman, P Kellnhofer, Y Wang, E R. Chan, D B. Lindell, G Wetzstein
[Stanford University & TU Delft]
Generative neural human radiation field . lately , Just use a single perspective 2D Photo album 3D Perception generates confrontation networks (GAN) Great progress has been made in unsupervised learning . However , these 3D The generation of confrontation networks has not been proved to be applicable to the human body , Moreover, the radiation field generated by the existing framework cannot be edited directly , It limits their applicability in downstream tasks . This paper proposes a solution to these challenges , Developed a 3D GAN frame , You can learn to generate the radiation field of the human body or face in a typical posture , Use an explicit deformation field to twist it into the desired body posture or facial expression . Using the framework , It shows the first generation result of high-quality human radiation field . And those without explicit deformation training 3D GAN comparison , The deformation perception training program proposed in this paper significantly improves the quality of the generated human body or face when editing human posture or facial expression .
Widely observed neural scaling laws, in which error falls off as a power of the training set size, model size, or both, have driven substantial performance improvements in deep learning. However, these improvements through scaling alone require considerable costs in compute and energy. Here we focus on the scaling of error with dataset size and show how both in theory and practice we can break beyond power law scaling and reduce it to exponential scaling instead if we have access to a high-quality data pruning metric that ranks the order in which training examples should be discarded to achieve any pruned dataset size. We then test this new exponential scaling prediction with pruned dataset size empirically, and indeed observe better than power law scaling performance on ResNets trained on CIFAR10, SVHN, and ImageNet. Given the importance of finding high-quality pruning metrics, we perform the first large-scale benchmarking study of ten different data pruning metrics on ImageNet. We find most existing high performing metrics scale poorly to ImageNet, while the best are computationally intensive and require labels for every image. We therefore developed a new simple, cheap and scalable self-supervised pruning metric that demonstrates comparable performance to the best supervised metrics. Overall, our work suggests that the discovery of good data-pruning metrics may provide a viable path forward to substantially improved neural scaling laws, thereby reducing the resource costs of modern deep learning.
https://arxiv.org/abs/2206.14314




3、[LG] Theoretical Perspectives on Deep Learning Methods in Inverse Problems
J Scarlett, R Heckel, M R. D. Rodrigues, P Hand, Y C. Eldar
[National University of Singapore & Technical University of Munich & University College London & Northeastern University]
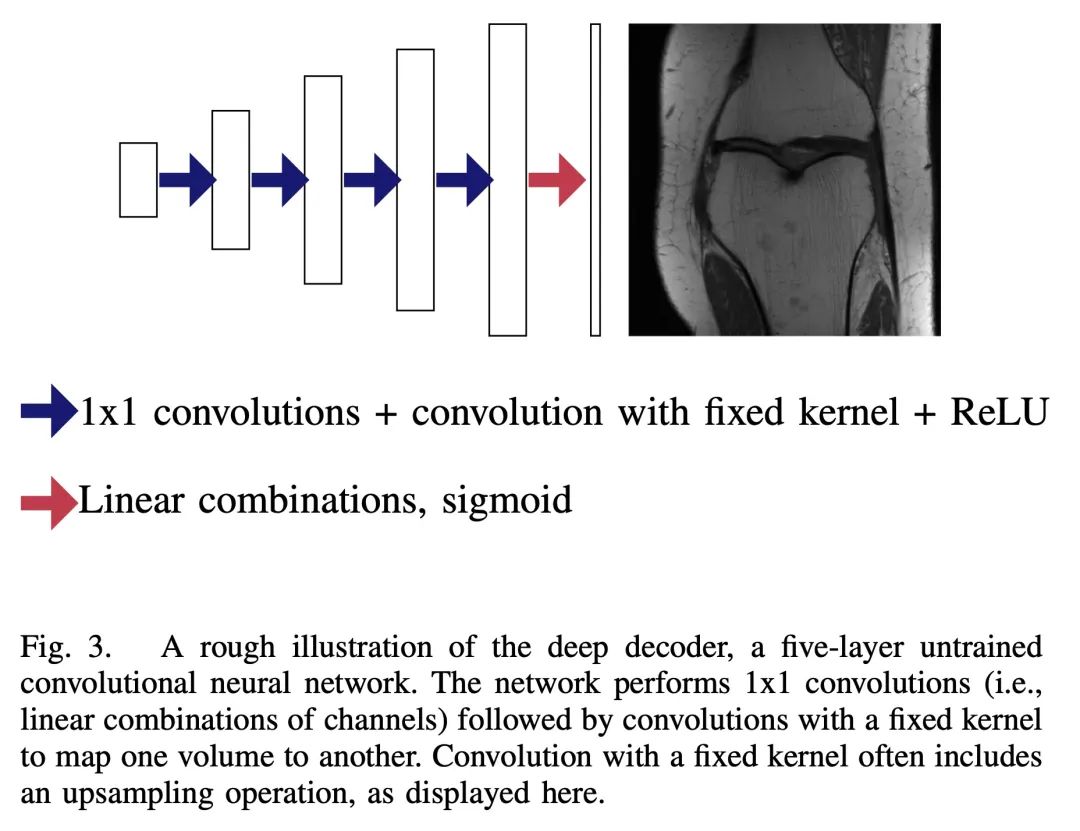
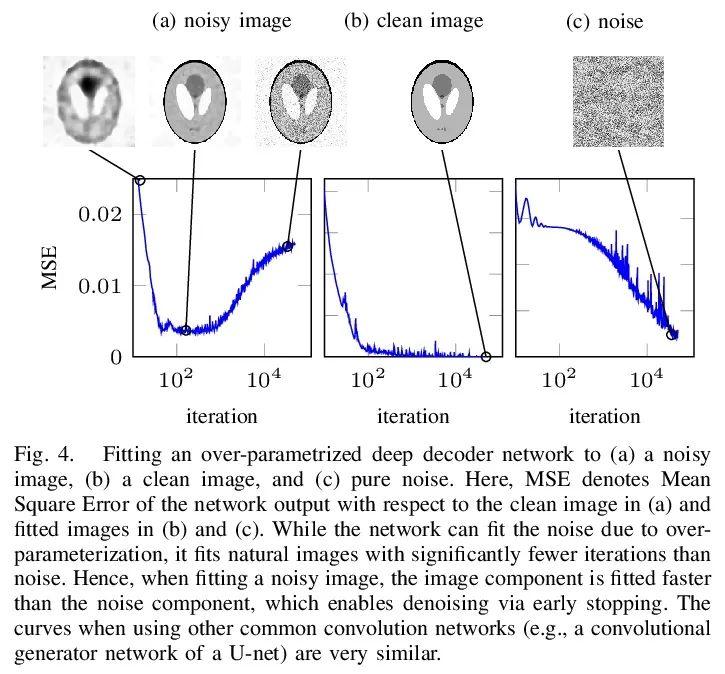
Theoretical analysis of deep learning methods in reverse problems . In recent years , Great progress has been made in the application of deep learning methods in reverse problems , Such as denoising 、 Compression induction 、 Painting and super resolution . Although this series of work is mainly driven by practical algorithms and experiments , But it also raises various interesting theoretical problems . This paper investigates some outstanding theoretical developments in this series of work , Pay special attention to generative presupposition 、 Untrained neural network preset and expansion algorithm . In addition to summarizing the existing results on these topics , Several challenges and open issues were also highlighted . Although the work in this field has developed rapidly , However, this paper believes that this topic is still in its early stage , Many of the most exciting developments are still ahead .
In recent years, there have been significant advances in the use of deep learning methods in inverse problems such as denoising, compressive sensing, inpainting, and super-resolution. While this line of works has predominantly been driven by practical algorithms and experiments, it has also given rise to a variety of intriguing theoretical problems. In this paper, we survey some of the prominent theoretical developments in this line of works, focusing in particular on generative priors, untrained neural network priors, and unfolding algorithms. In addition to summarizing existing results in these topics, we highlight several ongoing challenges and open problems.
https://arxiv.org/abs/2206.14373

4、[LG] Bayesian Causal Inference: A Critical Review
F Li, P Ding, F Mealli
[Duke University & UC Berkeley & University of Florence]
Bayesian Causal Inference : Critical review . This paper makes a critical review of Bayesian Causal Inference Based on the framework of potential results . Reviewed causal estimation 、 Identify the general structure of assumptions and Bayesian Causal Inference , It emphasizes the unique problems of Bayesian Causal Inference , Including the role of propensity scores 、 The definition of recognizability and a priori selection in low and high-dimensional scenarios . This paper points out the core role of covariate overlap , And the more general design stage in Bayesian Causal Inference . Expand the discussion to two complex allocation mechanisms : Processing of tool variables and time changes . For causal inference , Even everything in Statistics , Bayes should be a tool , Not the goal .
This paper provides a critical review of the Bayesian perspective of causal inference based on the potential outcomes framework. We review the causal estimands, identification assumptions, and general structure of Bayesian inference of causal effects. We highlight issues that are unique to Bayesian causal inference, including the role of the propensity score, definition of identifiability, and choice of priors in both low and high dimensional regimes. We point out the central role of covariate overlap and more generally the design stage in Bayesian causal inference. We extend the discussion to two complex assignment mechanisms: instrumental variable and time-varying treatments. Throughout, we illustrate the key concepts via examples.
https://arxiv.org/abs/2206.15460


5、[LG] Benchopt: Reproducible, efficient and collaborative optimization benchmarks
T Moreau, M Massias, A Gramfort, P Ablin, P Bannier, B Charlier...
[Université Paris-Saclay & Univ Lyon & Université Paris-Dauphine...]
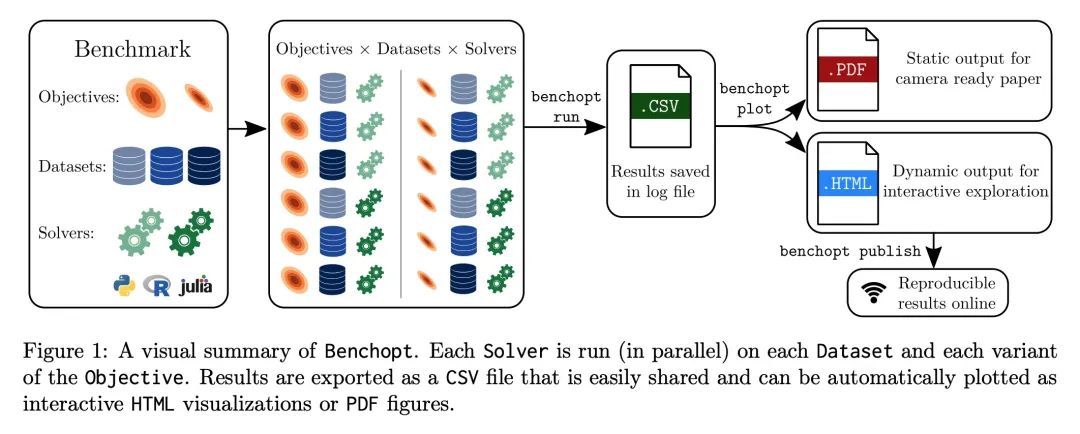
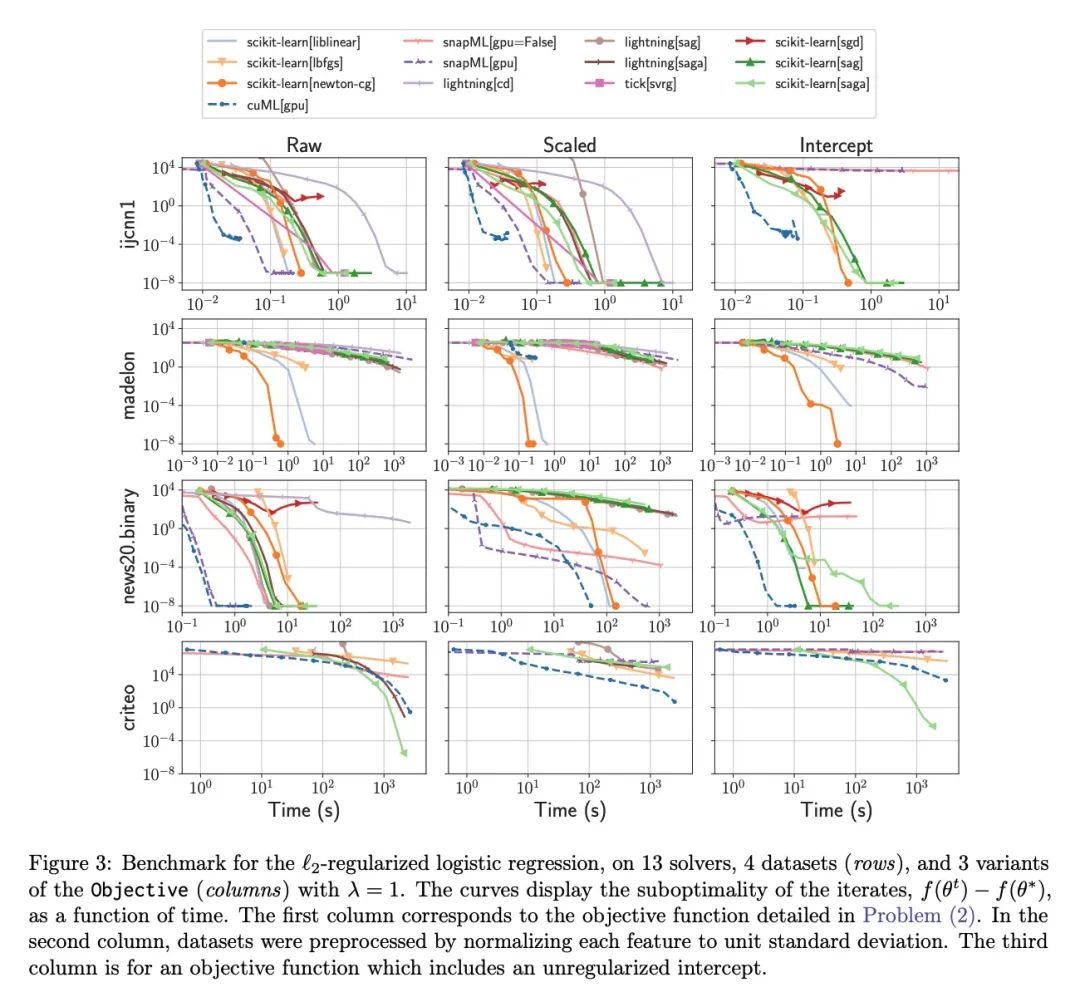
Benchopt: Reproducible efficient collaborative optimization benchmark . Numerical verification is the core of machine learning research , Because it can evaluate the actual impact of the new method , And confirm the consistency between theory and practice . However , The rapid development of this field has brought some challenges : Researchers face a large number of methods that need to be compared , Limited transparency and consensus on best practices , And the tedious reproduction work . therefore , Verification is often very one-sided , This may lead to wrong conclusions , Slow down the progress of research . In this paper, Benchopt, A writing framework , For Automation 、 Reproduce and publish optimization benchmarks for machine learning across programming languages and hardware architectures .Benchopt By providing an off the shelf tool to run 、 Share and expand experiments , Simplifies community benchmarking . In order to prove its wide applicability , This article presents benchmarks for three standard learning tasks :L2- Regular logistic Return to ,Lasso, And for image classification ResNet18 Training . These benchmarks highlight key practical findings , Give a more detailed view of the most advanced level of these issues , It shows that for the actual evaluation , The devil is in the details . hope Benchopt It can promote community cooperation , So as to improve the reproducibility of the research results .
Numerical validation is at the core of machine learning research as it allows to assess the actual impact of new methods, and to confirm the agreement between theory and practice. Yet, the rapid development of the field poses several challenges: researchers are confronted with a profusion of methods to compare, limited transparency and consensus on best practices, as well as tedious re-implementation work. As a result, validation is often very partial, which can lead to wrong conclusions that slow down the progress of research. We propose Benchopt, a collaborative framework to automate, reproduce and publish optimization benchmarks in machine learning across programming languages and hardware architectures. Benchopt simplifies benchmarking for the community by providing an off-the-shelf tool for running, sharing and extending experiments. To demonstrate its broad usability, we showcase benchmarks on three standard learning tasks: `2-regularized logistic regression, Lasso, and ResNet18 training for image classification. These benchmarks highlight key practical findings that give a more nuanced view of the state-of-the-art for these problems, showing that for practical evaluation, the devil is in the details. We hope that Benchopt will foster collaborative work in the community hence improving the reproducibility of research findings.
https://arxiv.org/abs/2206.13424



Several other papers worthy of attention :
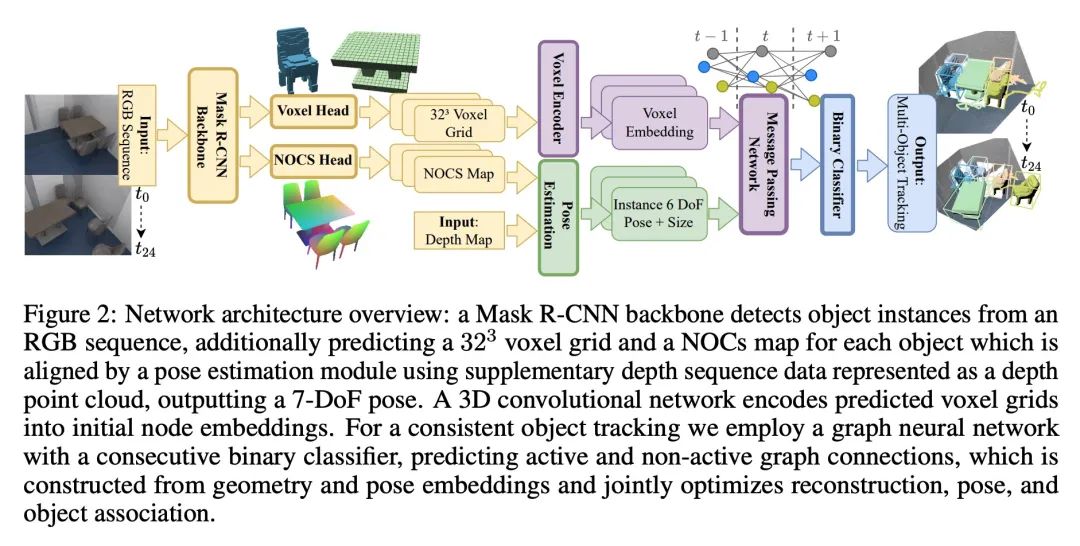
[CV] 3D Multi-Object Tracking with Differentiable Pose Estimation
Based on differentiable attitude estimation 3D Multitarget tracking
D Schmauser, Z Qiu, N Müller, M Nießner
[Technical University of Munich]
https://arxiv.org/abs/2206.13785



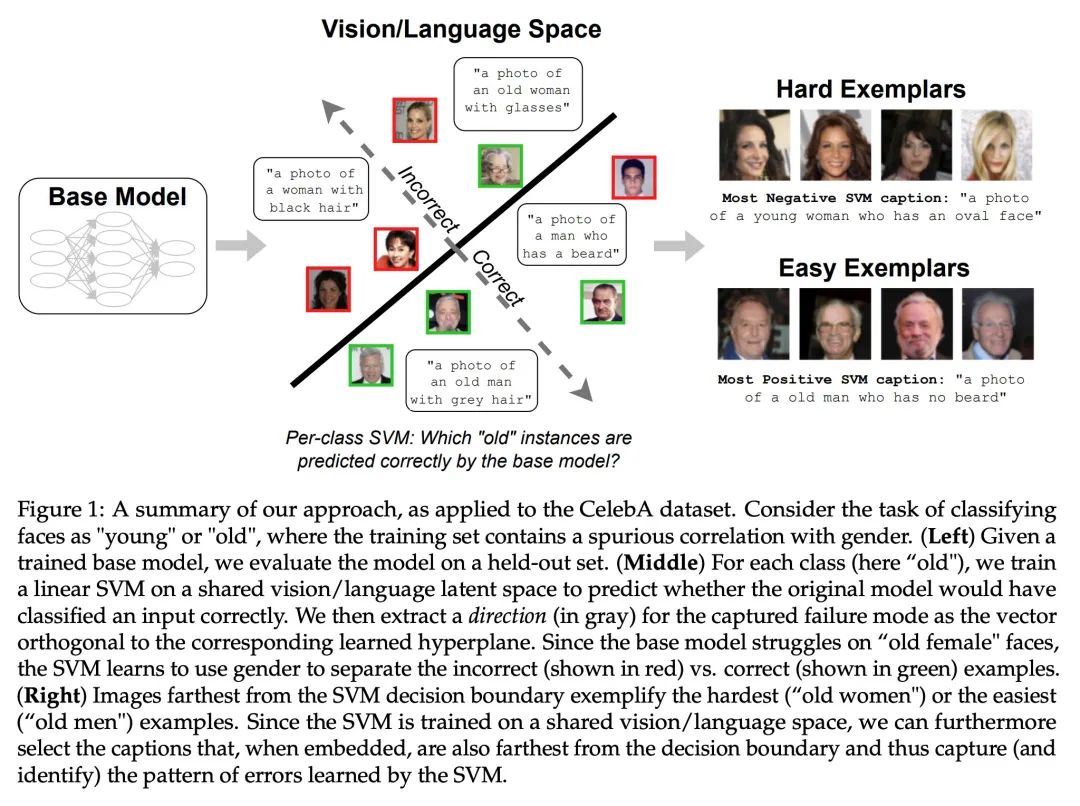
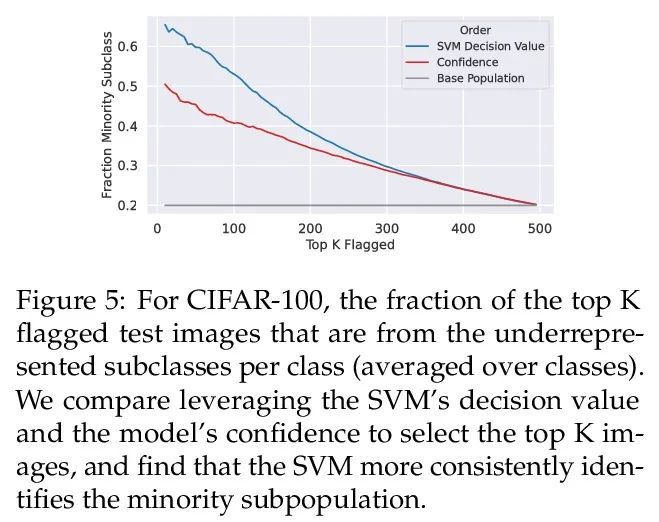
[LG] Distilling Model Failures as Directions in Latent Space
Refine the model failure mode as the potential space direction
S Jain, H Lawrence, A Moitra, A Madry
[MIT]
https://arxiv.org/abs/2206.14754



[CL] Factuality Enhanced Language Models for Open-Ended Text Generation
A factually enhanced language model for open text generation
N Lee, W Ping, P Xu, M Patwary, M Shoeybi, B Catanzaro
[Hong Kong University of Science and Technology & NVIDIA]
https://arxiv.org/abs/2206.04624



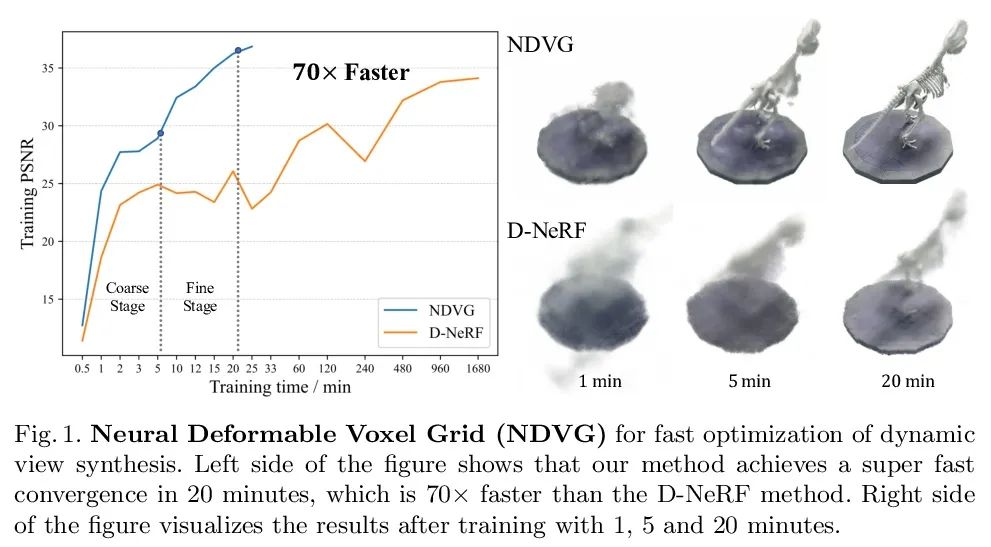
[CV] Neural Deformable Voxel Grid for Fast Optimization of Dynamic View Synthesis
Neural deformable voxel mesh for fast optimization of dynamic view synthesis
X Guo, G Chen, Y Dai, X Ye, J Sun, X Tan, E Ding
[Northwestern Polytechnical University & The Chinese University of Hong Kong & Baidu]
https://arxiv.org/abs/2206.07698




边栏推荐
- Nine ways to define methods in scala- Nine ways to define a method in Scala?
- PHP二级域名session共享方案
- 用通达信炒股开户安全吗?
- Slam learning notes - build a complete gazebo multi machine simulation slam from scratch (I)
- QT serial port UI design and solution to display Chinese garbled code
- 《天天数学》连载56:二月二十五日
- Basis of target detection (IOU)
- 面试官:JVM如何分配和回收堆外内存
- 初试scikit-learn库
- Mongodb installation and basic operation
猜你喜欢
Stm32f103c8t6 firmware library lighting

2022爱分析· 国央企数字化厂商全景报告
初试scikit-learn库

Myopia: take off or match glasses? These problems must be understood clearly first
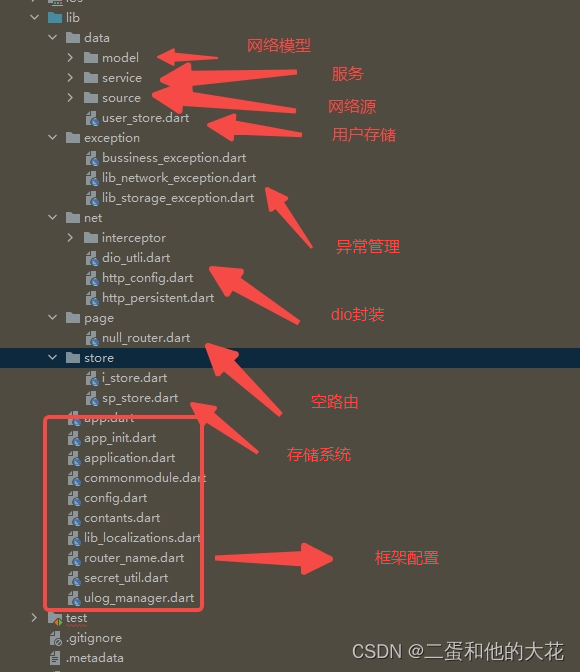
跟我学企业级flutter项目:简化框架demo参考
![[list to map] collectors Tomap syntax sharing (case practice)](/img/ac/e02deb1cb237806d357a88fb812852.jpg)
[list to map] collectors Tomap syntax sharing (case practice)

How to use AAB to APK and APK to AAB of Google play apps on the shelves

A survey of state of the art on visual slam
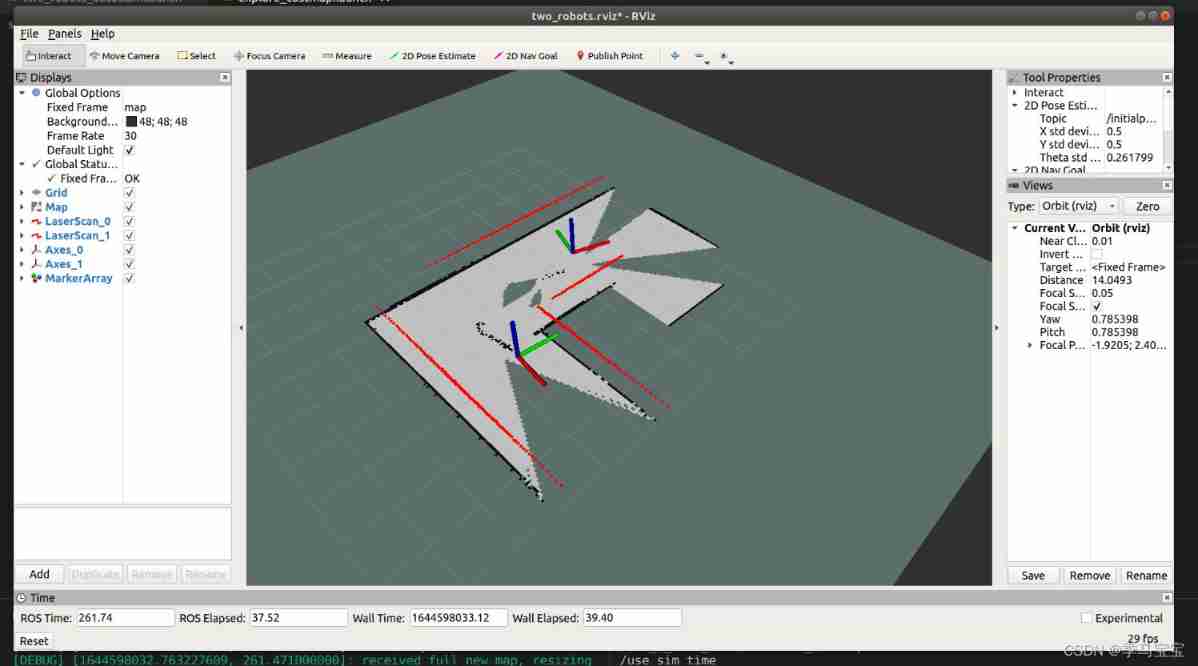
Slam learning notes - build a complete gazebo multi machine simulation slam from scratch (4)
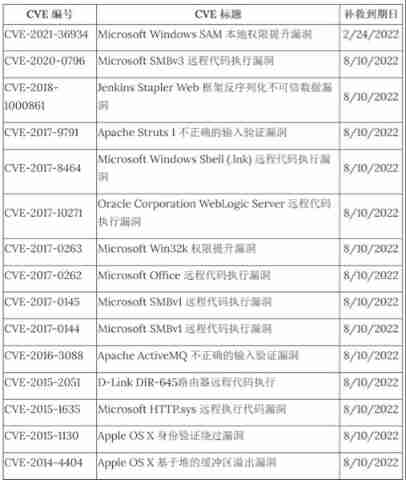
Famous blackmail software stops operation and releases decryption keys. Most hospital IOT devices have security vulnerabilities | global network security hotspot on February 14
随机推荐
There are several APIs of airtest and poco that are easy to use wrong in "super". See if you have encountered them
Page dynamics [2]keyframes
Slam learning notes - build a complete gazebo multi machine simulation slam from scratch (II)
QT串口ui设计和解决显示中文乱码
How to set up SVN server on this machine
Client does not support authentication protocol requested by server; consider upgrading MySQL client
Low level version of drawing interface (explain each step in detail)
TCP congestion control details | 3 design space
《天天数学》连载56:二月二十五日
Advanced Mathematics (Seventh Edition) Tongji University exercises 2-1 personal solutions
Asemi rectifier bridge umb10f parameters, umb10f specifications, umb10f package
斑马识别成狗,AI犯错的原因被斯坦福找到了
【声明】关于检索SogK1997而找到诸多网页爬虫结果这件事
Initial test of scikit learn Library
Uploads labs range (with source code analysis) (under update)
Google Earth engine (GEE) - daymet v4: daily surface weather data set (1000m resolution) including data acquisition methods for each day
Register in PHP_ Globals parameter settings
Is it safe to open an account with tongdaxin?
The accept attribute of the El upload upload component restricts the file type (detailed explanation of the case)
From "zero sum game" to "positive sum game", PAAS triggered the third wave of cloud computing