当前位置:网站首页>[Deep Learning] Overview of Efficient and Lightweight Semantic Segmentation
[Deep Learning] Overview of Efficient and Lightweight Semantic Segmentation
2022-08-03 13:08:00 【Demeanor 78】
原文:On Efficient Real-Time Semantic Segmentation: A Survey
链接:https://arxiv.org/abs/2206.08605
1摘要
Semantic segmentation is an important part of visual understanding in autonomous driving.然而当前SOTAThe models are very complex and cumbersome,Therefore, it is not suitable for deployment on in-vehicle chip platforms with limited computing resources and low time-consuming requirements..This article delves into the more compact、More efficient model in order to solve the above problems,These models can be deployed on low memory embedded systems,At the same time meet the needs of real-time reasoning.This article discusses some excellent work in the field,Categorized according to their main contribution,Finally, this paper evaluates the inference speed of the model under the same hardware and software conditions,These conditions represents a typical high performanceGPUand low memory embeddedGPUactual deployment scenarios.本文的实验结果表明,Many jobs enable a balance of performance and time-consuming on resource-constrained hardware.
2数据集
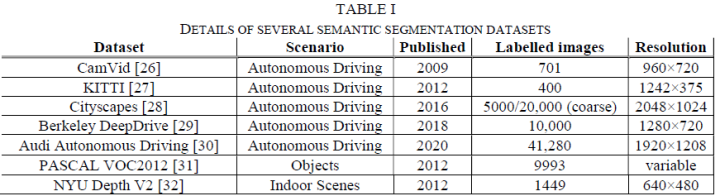
Common segmentation datasets areCamVid[1], KITTI[2], Cityscapes[3], Berkeley DeepDrive[4], Audi Autonomous Driving[5], PASCAL VOC2012[6], NYU Depth V2[7]等.
3Efficient depth CNN 的技术
Downsampling and Upsampling
降采样:Significantly reduces computation by downsampling the input image、Increase inference speed,At the same time sacrificing the accuracy of the output.一般而言,Large and complex models need to use downsampling to improve the receptive field,Common downsampling operations are max/average pooling.
上采样:Segmentation tasks are different from other vision tasks,Usually want to keep the dimensions of the input and output,So upsampling must be used to restore the resolution,The common upsampling method is bilinear interpolation、Deconvolution etc..
高效卷积
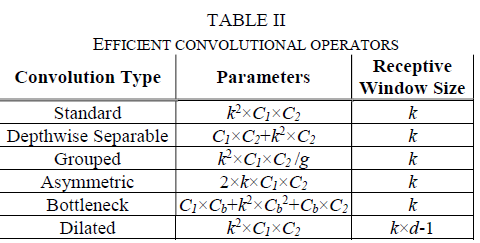
The core idea of efficient convolution is to expand the receptive field of the model by stacking convolutional layers,Reduce the amount of model parameters and computation.Common efficient convolutions areDepthwise-Separable Convolution[8],Grouped Convolution[9],Asymmetric Convolution[10], Bottleneck[11], Dilated Convolution[12].
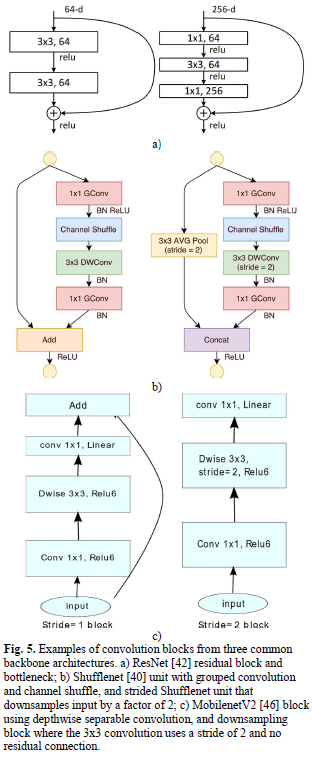
残差连接
residual connection pass[11]Often used in segmentation networks to improve gradient flow during backpropagation and reuse previous layer features.
主干网络
Many semantic segmentation models employ several widely used backbone networks as feature extractors,Common trunkResNet[11],Squeezenet[13],Shufflenet[14],Mobilenet[15],MobileNetV2[16],EfficientNet[17].
4Outstanding work
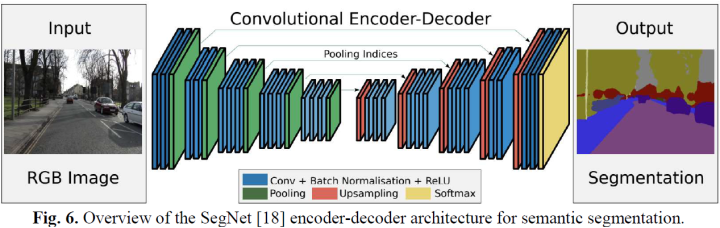
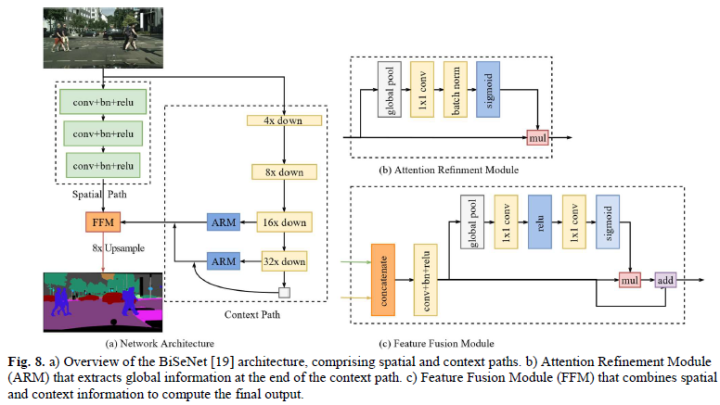
编码器-解码器
The core structure of semantic segmentation is the encoder-解码器.经典的模型有SegNet、U-net、Efficient Neural Network (ENet)、SQNet等等.
多分支
基于编码器-A major challenge of the decoder's approach is to preserve the high-resolution details extracted early in the network,So some multi-branch work feeds the original input image into the network at two or more scales.经典模型如Image Cascade Network (ICNet)、ContextNet、Guided Upsampling Network (GUN)等.
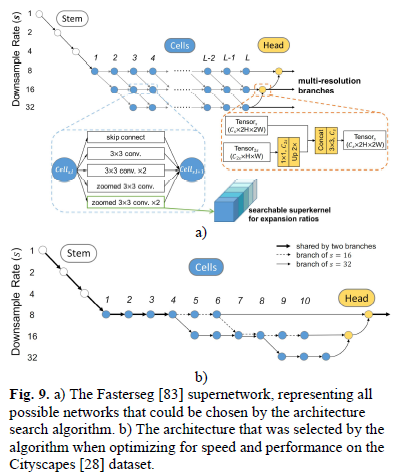
元学习
Most of the learning model in real-time semantic segmentation field are belong toNAS的范畴,is a method of automating the process of designing neural network structures.NAS Usually only the architectures that give the best results are involved,But under real-time requirements,Architecture size、Complexity and inference time constitute other factors that should be considered in optimizing functions.经典的算法有SqueezeNAS、FasterSeg、Graph-Guided Architecture Search (GAS) 等.
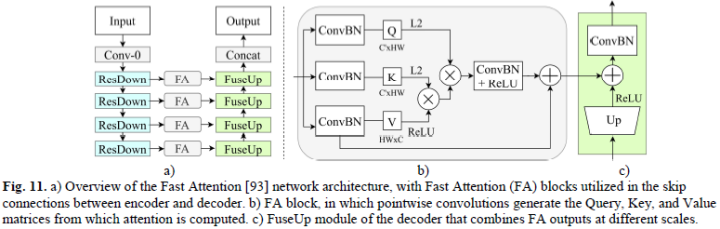
注意力
Attention mechanisms have been shown to be a key technique for vision tasks,But generally computationally cumbersome and inefficient.Although still not suitable for real-time inference,But some work likeDeep Feature Aggregation (DFANet)、Lightweight Encoder-Decoder (LEDNet)etc. reduce the complexity of attention.
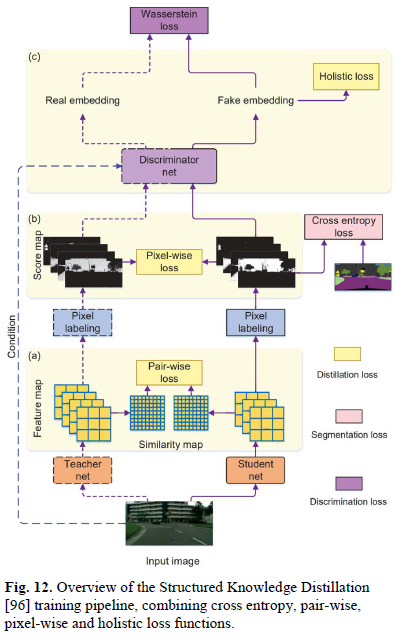
训练优化
The last category is methods that take existing network structures and change the training process to improve model performance,Common as Knowledge DistillationStructured Knowledge Distillation、Knowledge Adaptation等
5评估
本文在Nvidia RTX 3090 GPU和嵌入式平台Nvidia Jetson Xavier AGX Developer KitThe time-consuming and performance of different algorithms are verified under the two platforms.
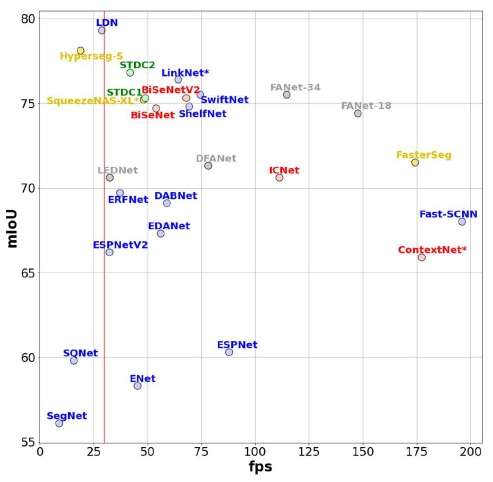
对比如下表所示:
6结论
This paper discusses a low-cost semantic segmentation algorithm for solving resource-constrained hardware,and discuss and categorize them according to their major contributions to the field.Finally, this paper conducts its own experiments,Analyze the speed and performance of the algorithm under the same hardware and software conditions,Provide a reference for model selection,Provide thinking direction for the optimization of future work.
7参考文献
[1] G. J. Brostow, J. Fauqueur and R. Cipolla, "Semantic object classes in video: A high-definition ground truth database," Pattern Recognit. Lett., vol. 30, p. 88–97, 2009.
[2] A. Geiger, P. Lenz, C. Stiller and R. Urtasun, "Vision meets robotics: The KITTI dataset," Int. J. Robotics Res., vol. 32, p. 1231–1237, 2013.
[3] M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth and B. Schiele, "The Cityscapes Dataset for Semantic Urban Scene Understanding," in 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, June 27-30, 2016, 2016.
[4] F. Yu, W. Xian, Y. Chen, F. Liu, M. Liao, V. Madhavan and T. Darrell, "BDD100K: A Diverse Driving Video Database with Scalable Annotation Tooling," CoRR, vol. abs/1805.04687, 2018.
[5] J. Geyer, Y. Kassahun, M. Mahmudi, X. Ricou, R. Durgesh, A. S. Chung, L. Hauswald, V. H. Pham, M. Mühlegg, S. Dorn, T. Fernandez, M. Jänicke, S. Mirashi, C. Savani, M. Sturm, O. Vorobiov, M. Oelker, S. Garreis and P. Schuberth, "A2D2: Audi Autonomous Driving Dataset," CoRR, vol. abs/2004.06320, 2020.
[6] M. Everingham, L. Van Gool, C. K. I. Williams, J. Winn and A. Zisserman, The PASCAL Visual Object Classes Challenge 2012 (VOC2012) Results.
[7] N. Silberman, P. Kohli and R. Fergus, "Indoor Segmentation and Support Inference from RGBD Images," in European Conference on Computer Vision, 2012.
[8] L. Sifre and S. Mallat, Rigid-Motion Scattering for Texture Classification, 2014.
[9] A. Krizhevsky, I. Sutskever and G. E. Hinton, "ImageNet Classification with Deep Convolutional Neural Networks," in Advances in Neural Information Processing Systems, 2012.
[10] M. Jaderberg, A. Vedaldi and A. Zisserman, Speeding up Convolutional Neural Networks with Low Rank Expansions, 2014.
[11] K. He, X. Zhang, S. Ren and J. Sun, "Deep Residual Learning for Image Recognition," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
[12] G. Papandreou, I. Kokkinos and P.-A. Savalle, "Modeling Local and Global Deformations in Deep Learning: Epitomic Convolution, Multiple Instance Learning, and Sliding Window Detection," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015.
[13] F. N. Iandola, S. Han, M. W. Moskewicz, K. Ashraf, W. J. Dally and K. Keutzer, SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size, 2016.
[14] X. Zhang, X. Zhou, M. Lin and J. Sun, "ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
[15] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto and H. Adam, MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications, 2017.
[16] M. Sandler, A. Howard, M. Zhu, A. Zhmoginov and L.-C. Chen, "MobileNetV2: Inverted Residuals and Linear Bottlenecks," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
[17] M. Tan and Q. Le, "EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks," in Proceedings of the 36th International Conference on Machine Learning, 2019.

往期精彩回顾
适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑机器学习交流qq群955171419,加入微信群请扫码
边栏推荐
- d写二进制
- 期货开户中常见问题汇总
- 安防监控必备的基础知识「建议收藏」
- Oracle安装完毕(系统盘),从系统盘转移到数据盘
- An动画基础之按钮动画与基础代码相结合
- YOLOv5 training data prompts No labels found, with_suffix is used, WARNING: Ignoring corrupted image and/or label appears during yolov5 training
- Feature dimensionality reduction study notes (pca and lda) (1)
- Secure Custom Web Application Login
- 易观分析:2022年Q2中国网络零售B2C市场交易规模达23444.7亿元
- Kubernetes 网络入门
猜你喜欢







随机推荐
An animation optimization of traditional guide layer animation
php microtime 封装工具类,计算接口运行时间(打断点)
查看GCC版本_qt版本
SQL分页查询_Sql根据某个字段分页
【蓝桥杯选拔赛真题48】Scratch跳舞机游戏 少儿编程scratch蓝桥杯选拔赛真题讲解
self-discipline
一些测试相关知识
[Blue Bridge Cup Trial Question 48] Scratch Dance Machine Game Children's Programming Scratch Blue Bridge Cup Trial Question Explanation
Win11怎么禁止软件后台运行?Win11系统禁止应用在后台运行的方法
Grafana 高可用部署最佳实践
Oracle is installed (system disk) and transferred from the system disk to the data disk
An动画优化之传统引导层动画
Nodejs 安装依赖cpnm时,install 出现Error: Cannot find module ‘fs/promises‘
五、函数的调用过程
An introduction to 3D tools
软件测试面试(四)
[Practical skills] APP video tutorial for updating APP in CANFD, I2C, SPI and serial port mode of single-chip bootloader (2022-08-01)
第十五章 源代码文件 REST API 简介
类型转换、常用运算符
BOM系列之sessionStorage