当前位置:网站首页>玩转gRPC—深入概念与原理
玩转gRPC—深入概念与原理
2022-07-04 21:33:00 【InfoQ】
- 《玩转gRPC—Go使用gRPC通信实战》
- 《玩转gRPC—不同编程语言间通信》
- 《一文带你搞懂HTTP和RPC协议的异同》
- 《从1开始,扩展Go语言后端业务系统的RPC功能》
1 使用gRPC的基本架构
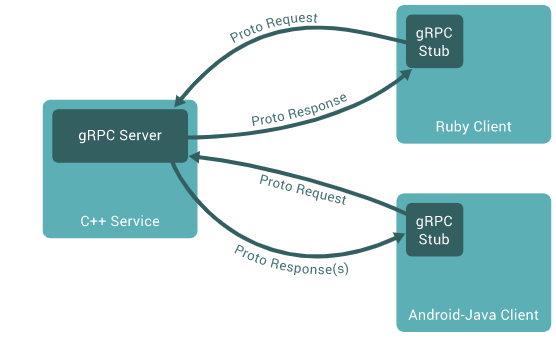
- Service:提供的服务
- Client:gRPC客户端
- gRPC Server:gRPC服务端接口
- gRPC Stub:gRPC客户端接口
- Proto Request/Proto Response(s):中间文件(代码/协议)
2 Protocol Buffers
2.1 什么是Protocol Buffers?
- 支持多种编程语言
- 序列化数据体积小
- 反序列化速度快
- 序列化和反序列化代码自动生成
2.2 Protocol Buffers和gRPC什么关系?
2.3 Protocol Buffers基本语法
.protomessage Person {
string name = 1;
int32 id = 2;
bool has_ponycopter = 3;
}
protocname()set_name()// The greeter service definition.
service Greeter {
// Sends a greeting
rpc SayHello (HelloRequest) returns (HelloReply) {}
}
// The request message containing the user's name.
message HelloRequest {
string name = 1;
}
// The response message containing the greetings
message HelloReply {
string message = 1;
}
protoc3 gRPC的四种服务提供方法
3.1 Unary RPC
rpc SayHello(HelloRequest) returns (HelloResponse);
3.2 Server streaming RPC
rpc LotsOfReplies(HelloRequest) returns (stream HelloResponse);
3.3 Client streaming RPC
rpc LotsOfGreetings(stream HelloRequest) returns (HelloResponse);
3.4 Bidirectional streaming RPC
rpc BidiHello(stream HelloRequest) returns (stream HelloResponse)
4 gRPC的生命周期
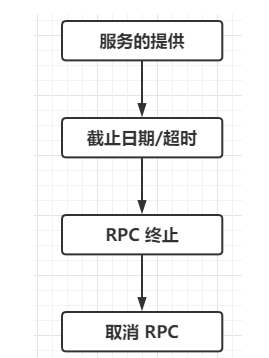
4.1 服务的提供
4.2 截止日期/超时
DEADLINE_EXCEEDED4.3 RPC 终止
4.4 取消 RPC
5 gRPC通信原理
5.1 HTTP2
- HTTP/2 的规范于 2015 年5 月发布,旨在解决其前身的一些可扩展性问题,在许多方面改进了 HTTP/1.1 的设计,最重要的是提供了连接上的语义映射。
- 创建 HTTP 连接的开销很大。您必须建立 TCP 连接、使用 TLS 保护该连接、交换标头和设置等。HTTP/1.1 通过将连接视为长期存在的、可重用的对象来简化此过程。HTTP/1.1 连接保持空闲,以便可以通过现有的空闲连接发送到同一目的地的新请求。虽然连接重用缓解了这个问题,但一个连接一次只能处理一个请求——它们是 1:1 耦合的。如果要发送一条大消息,新请求必须要么等待它完成(导致 队列阻塞),要么更频繁地为启动另一个连接付出代价。
- HTTP/2 通过在连接之上提供一个语义层:流,从而进一步扩展了持久连接的概念。流可以被认为是一系列语义连接的消息,称为帧。流可能是短暂的,例如请求用户状态的一元流(在 HTTP/1.1 中,这可能等同于
GET /users/1234/status)。随着频率的增加,它的寿命很长。接收者可能会建立一个长期存在的流,从而实时连续接收用户状态消息,而不是向 /users/1234/status 端点发出单独的请求。流的主要优点是连接并发,即在单个连接上交错消息的能力。
- 流量控制
- 然而,并发流包含一些微妙的陷阱。考虑以下情况:同一连接上的两个流 A 和 B。流 A 接收大量数据,远远超过它在短时间内可以处理的数据。最终,接收者的缓冲区被填满,TCP 接收窗口限制了发送者。这对于 TCP 来说都是相当标准的行为,但这种情况对于流来说是不利的,因为两个流都不会接收更多数据。理想情况下,流 B 应该不受流 A 的缓慢处理的影响。
- HTTP/2 通过提供流控制机制作为流规范的一部分来解决这个问题。流控制用于限制每个流(和每个连接)的未完成数据量。它作为一个信用系统运行,其中接收方分配一定的“预算”,发送方“花费”该预算。更具体地说,接收方分配一些缓冲区大小(“预算”),发送方通过发送数据填充(“花费”)缓冲区。接收方使用特殊用途的WINDOW_UPDATE帧向发送方通告可用的额外缓冲区 . 当接收方停止广播额外的缓冲区时,发送方必须在缓冲区(其“预算”)耗尽时停止发送消息。
- 使用流控制,并发流可以保证独立的缓冲区分配。再加上轮询请求发送,所有大小、处理速度和持续时间的流都可以在单个连接上进行多路复用,而无需关心跨流问题。
- 更智能的代理
- HTTP/2 的并发属性允许代理具有更高的性能。例如,考虑一个接受和转发尖峰流量的 HTTP/1.1 负载平衡器:当出现尖峰时,代理会启动更多连接来处理负载或将请求排队。前者——新连接——通常是首选(在某种程度上);这些新连接的缺点不仅在于等待系统调用和套接字的时间,还在于在 发生TCP 慢启动时未充分利用连接所花费的时间。
- 相比之下,考虑一个配置为每个连接多路复用 100 个流的 HTTP/2 代理。一些请求的峰值仍然会导致新的连接被启动,但与 HTTP/1.1 对应的连接数相比只有 1/100 个连接。更笼统地说:如果n 个HTTP/1.1 请求发送到一个代理,则n 个HTTP/1.1 请求必须出去;每个请求都是一个有意义的数据请求/有效负载,请求是 1:1 的连接。相反,使用 HTTP/2 发送到代理的n请求需要n 个流,但 不需要n 个连接!
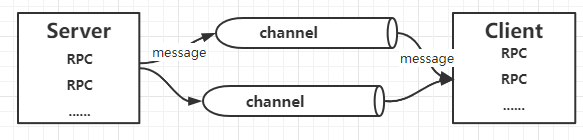
5.2 gRPC与HTTP2
6 总结
边栏推荐
- 挖财学院股票开户安全吗?开户只能在挖财开户嘛?
- 学习突围3 - 关于精力
- WebGIS framework -- kalrry
- 283. 移动零-c与语言辅助数组法
- Rotary transformer string judgment
- Go语言循环语句(第10课中3)
- GTEST from ignorance to proficiency (4) how to write unit tests with GTEST
- Monitor the shuttle return button
- [weekly translation go] how to code in go series articles are online!!
- [early knowledge of activities] list of recent activities of livevideostack
猜你喜欢



![Jerry's ad series MIDI function description [chapter]](/img/d7/348d85eb9f69ffd75612eeba56b16e.png)
随机推荐
Delphi soap WebService server-side multiple soapdatamodules implement the same interface method, interface inheritance
EhLib 数据库记录的下拉选择
面试官:说说XSS攻击是什么?
做BI开发,为什么一定要熟悉行业和企业业务?
How much is the minimum stock account opening commission? Is it safe to open an account online
Exclusive interview of open source summer | new committer Xie Qijun of Apache iotdb community
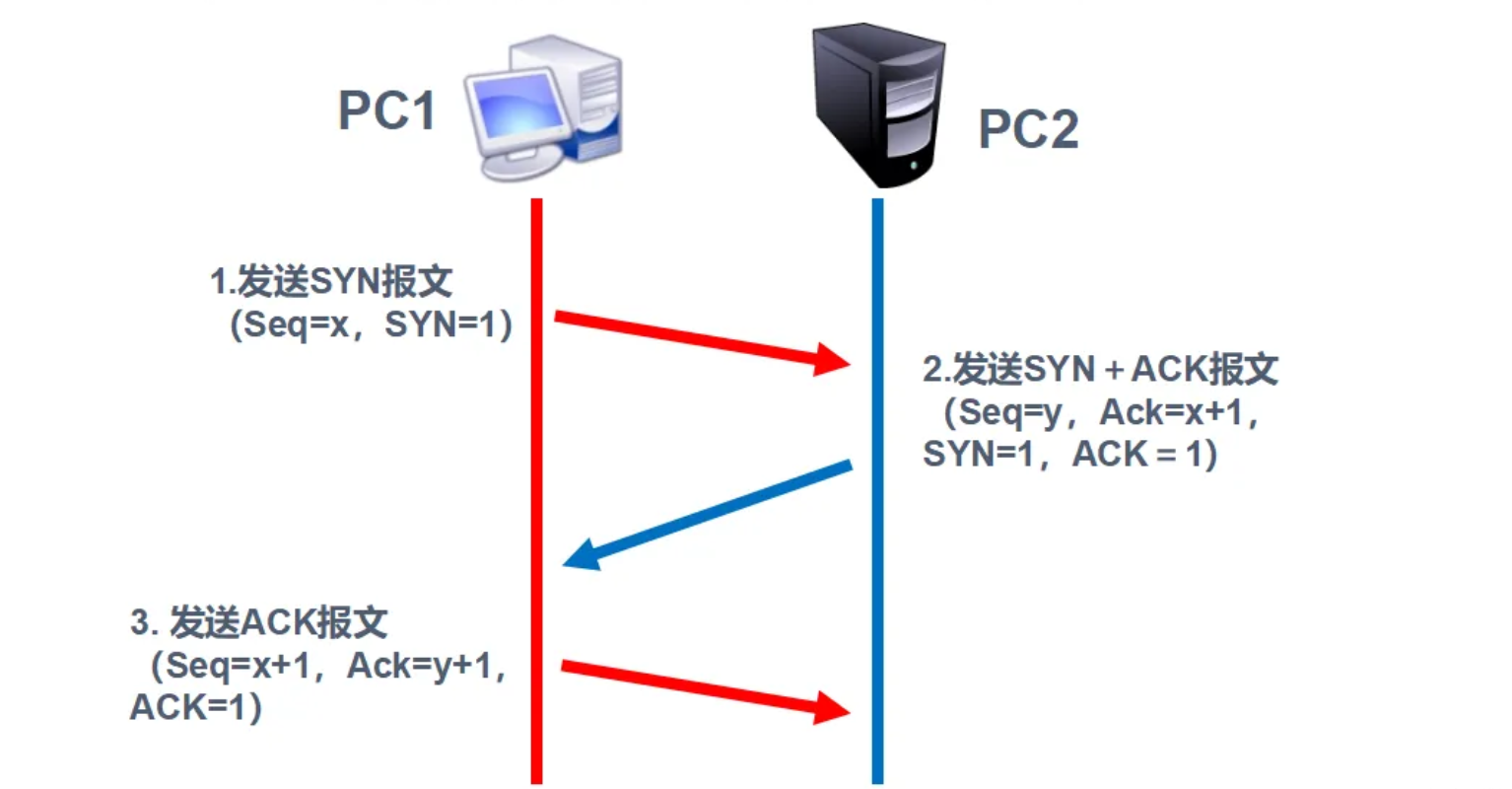
TCP protocol three times handshake process
How to use concurrentlinkedqueue as a cache queue
ArcGIS 10.2.2 | solution to the failure of ArcGIS license server to start
Shutter WebView example
Flutter TextField示例
Liu Jincheng won the 2022 China e-commerce industry innovation Figure Award
Solve the problem of data disorder caused by slow asynchronous interface
TCP shakes hands three times and waves four times. Do you really understand?
How was MP3 born?
Is it safe to open an account in the stock of Caicai college? Can you only open an account by digging money?
股票开户流程是什么?使用同花顺手机炒股软件安全吗?
Le module minidom écrit et analyse XML
Go语言循环语句(第10课中3)
Which securities company is better to open an account? Is online account opening safe