当前位置:网站首页>MySQL advanced part 1: index
MySQL advanced part 1: index
2022-07-05 06:13:00 【Dawnlighttt】
List of articles
Indexes
Index Overview
Indexes (index) Help MySQL Data structure for efficient data acquisition ( Orderly ). Indexes are added to the fields of the database table , It is a mechanism to improve query efficiency . Out of data , The database system also maintains a data structure that satisfies a specific search algorithm , These data structures are referenced in some way ( Point to ) data , In this way, advanced search algorithms can be implemented on these data structures , This data structure is the index . Like the one below Sketch Map Shown :
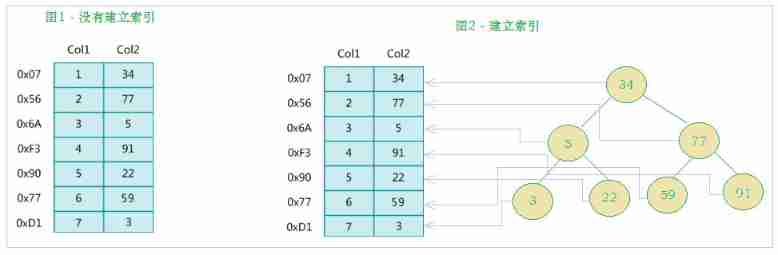
On the left is the data table , There are two columns and seven records , On the far left is the physical address of the data record ( Note that logically adjacent records are not physically adjacent to each other on disk ). In order to speed up Col2 Lookup , You can maintain a binary search tree as shown on the right , Each node contains an index key value and a pointer to the physical address of the corresponding data record , In this way, we can use binary search to get the corresponding data quickly .
Generally speaking, the index itself is very large , It's impossible to store everything in memory , So indexes are often stored on disk as index files . Index is the most commonly used tool in database to improve performance .
Index strengths and weaknesses
advantage
1) It's like a catalog index of books , Improve the efficiency of data retrieval , Reduce the IO cost .
2) Sort data through index columns , Reduce the cost of sorting data , Reduce CPU Consumption of .
Inferiority
1) The index is actually a table , The table holds the primary key and index fields , And point to the record of the entity class , So index columns also need to occupy space .
2) Although indexing greatly improves query efficiency , At the same time, it also reduces the speed of updating tables , Such as on the table INSERT、UPDATE、DELETE. Because when updating tables ,MySQL Not only to save data , And save the index file . Each update adds the field of the index column , Will adjust the index information after the key value changes due to the update .
Index structure
The index is in MySQL In the storage engine layer , Not at the server level . So the indexes of each storage engine are not necessarily the same , Not all storage engines support all index types .MySQL The following are currently available 4 Species index :
- BTREE Indexes : The most common type of index , Most indexes support B Tree index .
- HASH Indexes : Only Memory Engine support , The use scenario is simple .
- R-tree Indexes ( Spatial index ): The spatial index is MyISAM A special index type of the engine , Mainly used for geospatial data types , Usually used less , No special introduction .
- Full-text ( Full-text index ) : Full text index is also MyISAM A special index type of , Mainly used for full-text indexing ,InnoDB from Mysql5.6 Full text indexing is now supported .
MyISAM、InnoDB、Memory Three storage engines support various index types
| Indexes | InnoDB engine | MyISAM engine | Memory engine |
|---|---|---|---|
| BTREE Indexes | Support | Support | Support |
| HASH Indexes | I won't support it | I won't support it | Support |
| R-tree Indexes | I won't support it | Support | I won't support it |
| Full-text | 5.6 Support for | Support | I won't support it |
What we usually call index , If not specified , All refer to B+ Trees ( Multiple search trees , It doesn't have to be a binary ) Index of structural organization . Where the clustered index 、 Composite index 、 Prefix index 、 The only index defaults to B+tree Indexes , Collectively referred to as Indexes .
BTREE structure
BTree It's also called multiple balanced search tree , One m Forked BTree Characteristics are as follows :
- Each node in the tree contains at most m A child .
- Except root node and leaf node , Each node has at least [ceil(m/2)] A child .
- If the root node is not a leaf node , There are at least two children .
- All the leaf nodes are on the same layer .
- Each non leaf node is composed of n individual key And n+1 Pointer composition , among [ceil(m/2)-1] <= n <= m-1
With 5 fork BTree For example ,key The number of : Formula derivation [ceil(m/2)-1] <= n <= m-1. therefore 2 <= n <=4 . When n>4 when , The intermediate node splits into the parent node , Split nodes on both sides .
Insert C N G A H E K Q M F W L T Z D P R X Y S Take the data .
The evolution process is as follows :
1). Before insertion 4 Letters C N G A
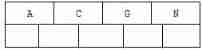
2). Insert H,n>4, The middle element G Letters split up to new nodes
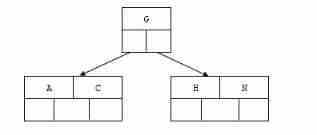
3). Insert E,K,Q There is no need to split
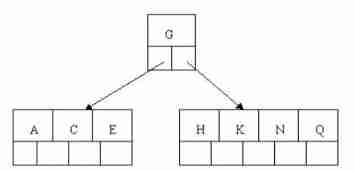
4). Insert M, The middle element M The letter splits up to the parent node G
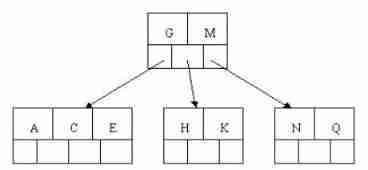
5). Insert F,W,L,T There is no need to split
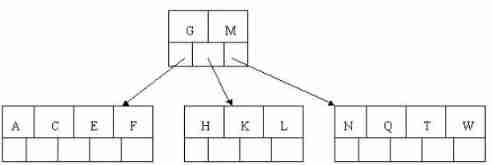
6). Insert Z, The middle element T Split up into parent nodes
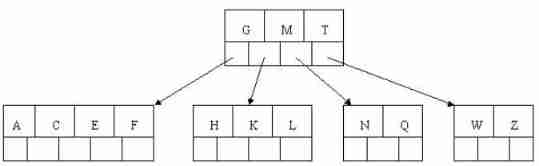
7). Insert D, The middle element D Split up into parent nodes . Then insert P,R,X,Y There is no need to split
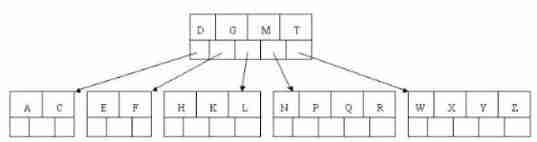
8). Finally insert S,NPQR node n>5, Intermediate nodes Q Split up , But split the parent node DGMT Of n>5, Intermediate nodes M Split up
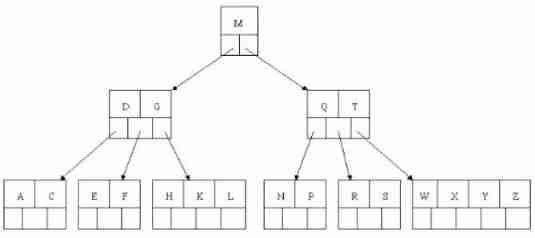
Here we are , The BTREE The tree has been built , BTREE Trees and Binary tree comparison , Query data more efficiently , Because for the same amount of data ,BTREE The hierarchical structure of a tree is smaller than that of a binary tree , So search speed is fast .
B+TREE structure
B+Tree by BTree Variants ,B+Tree And BTree The difference is :
1). n fork B+Tree Up to n individual key, and BTree Up to n-1 individual key.
2). B+Tree The leaf node in the key Information , In accordance with the key In order of size .
3). All non leaf nodes can be regarded as key The index part of .
because B+Tree Only leaf nodes are saved key Information , Query any key All from root Go to the leaves . therefore B+Tree The query efficiency is more stable .
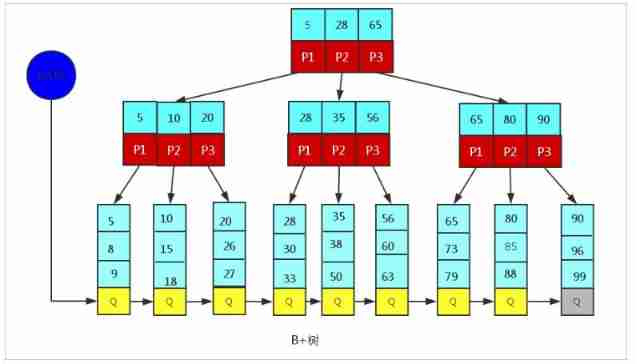
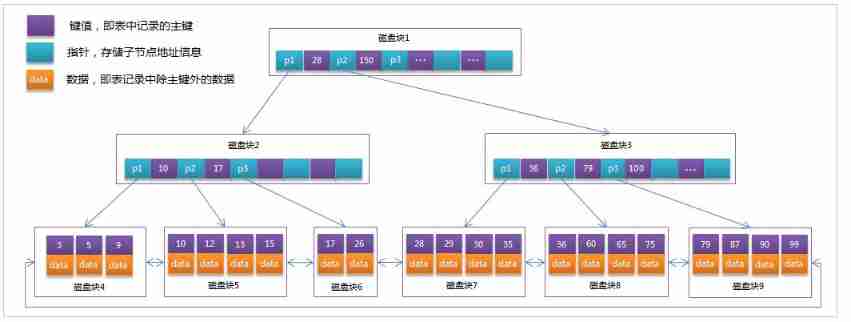
MySQL Medium B+Tree
MySql Index data structure for classic B+Tree optimized . In the original B+Tree On the basis of , Add a pointer to the linked list of adjacent leaf nodes , So we have a sequence pointer B+Tree, Improve the performance of interval access .
MySQL Medium B+Tree Index structure diagram :
Index classification
1) Single value index : That is, an index contains only a single column , A table can have multiple single-column indexes
2) unique index : The value of the index column must be unique , But you can have an empty value
3) Composite index : That is, an index contains multiple columns
Index Syntax
When the index creates the table , You can create at the same time , You can also add new indexes at any time .
Prepare the environment :
create database demo_01 default charset=utf8mb4;
use demo_01;
CREATE TABLE `city` (
`city_id` int(11) NOT NULL AUTO_INCREMENT,
`city_name` varchar(50) NOT NULL,
`country_id` int(11) NOT NULL,
PRIMARY KEY (`city_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `country` (
`country_id` int(11) NOT NULL AUTO_INCREMENT,
`country_name` varchar(100) NOT NULL,
PRIMARY KEY (`country_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into `city` (`city_id`, `city_name`, `country_id`) values(1,' Xi'an ',1);
insert into `city` (`city_id`, `city_name`, `country_id`) values(2,'NewYork',2);
insert into `city` (`city_id`, `city_name`, `country_id`) values(3,' Beijing ',1);
insert into `city` (`city_id`, `city_name`, `country_id`) values(4,' Shanghai ',1);
insert into `country` (`country_id`, `country_name`) values(1,'China');
insert into `country` (`country_id`, `country_name`) values(2,'America');
insert into `country` (`country_id`, `country_name`) values(3,'Japan');
insert into `country` (`country_id`, `country_name`) values(4,'UK');
Create index
grammar :
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name
[USING index_type]
ON tbl_name(index_col_name,...)
index_col_name : column_name[(length)][ASC | DESC]
Example : by city In the table city_name Field creation index :

Look at the index
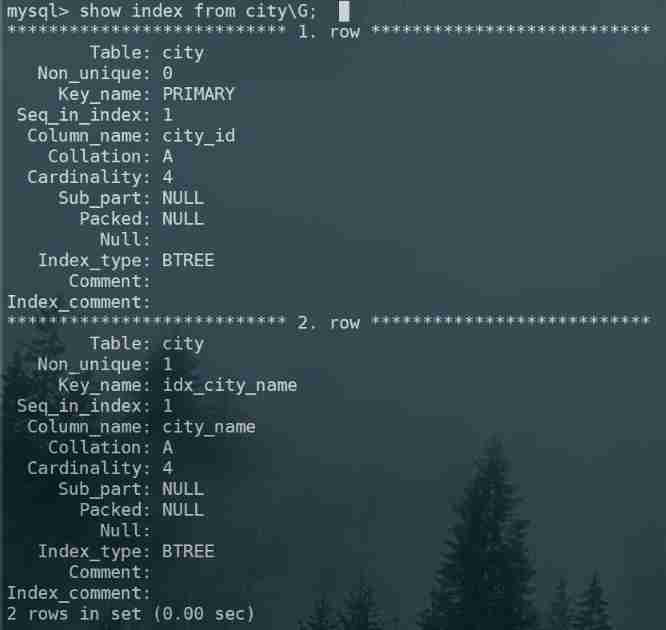
grammar
show index from table_name;
Example : see city Index information in the table :
Delete index
grammar
DROP INDEX index_name ON tbl_name;
Example : Want to delete city The index on the table idx_city_name, It can be operated as follows :

ALERT command
1). alter table tb_name add primary key(column_list);
This statement adds a primary key , This means that the index value must be unique , And cannot be NULL
2). alter table tb_name add unique index_name(column_list);
The value of the index created by this statement must be unique ( except NULL Outside ,NULL There may be many times )
3). alter table tb_name add index index_name(column_list);
Add a normal index , Index values can appear multiple times .
4). alter table tb_name add fulltext index_name(column_list);
The statement specifies that the index is FULLTEXT, For full-text indexing
Index design principles
Index design can follow some existing principles , When creating an index, try to conform to these principles , It is easy to improve the efficiency of the index , More efficient use of indexes .
The query frequency is high , And a table with a large amount of data is indexed .Selection of index fields , The best candidate column should be from where Clause is extracted from the condition of clause , If where There are more combinations in clauses , Then choose the most commonly used 、 The combination of the best filtering Columns .Use unique index, The more distinguishable , The more efficient the index is .Index can effectively improve the efficiency of query data , But the number of indexes is not the better , More indexes , The cost of maintaining the index naturally goes up. For inserting 、 to update 、 Delete etc. DML For tables that operate more frequently , Too many indexes , It's going to introduce quite a high maintenance cost , Reduce DML Efficiency of operation , Increase the time consumption of the corresponding operation .In addition, if there are too many indexes ,MySQL It's also a choice problem , Although you'll still find a usable index in the end , But it certainly raises the cost of choice .Use short index , After the index is created, it is also stored on the hard disk , Therefore, the index access is improved I/O efficiency , It can also improve the overall access efficiency .If the total length of the fields that make up the index is short , Then more index values can be stored in a given size of memory block , Correspondingly, it can effectively improve MySQL Access to the index I/O efficiency .Use the leftmost prefix,N A composite index of columns , So it's equivalent to creating N An index , If you query where Clause uses the first few fields that make up the index , So this query SQL We can use composite index to improve query efficiency .
Create composite index :
CREATE INDEX idx_name_email_status ON tb_seller(NAME,email,STATUS);
Equivalent to
Yes name Create index ;
Yes name , email Created index ;
Yes name , email, status Created index ;
边栏推荐
- Leetcode-6111: spiral matrix IV
- Simple knapsack, queue and stack with deque
- R language [import and export of dataset]
- Is it impossible for lamda to wake up?
- 【云原生】微服务之Feign自定义配置的记录
- 快速使用Amazon MemoryDB并构建你专属的Redis内存数据库
- A reason that is easy to be ignored when the printer is offline
- Introduction to convolutional neural network
- leetcode-1200:最小绝对差
- 1039 Course List for Student
猜你喜欢
WordPress switches the page, and the domain name changes back to the IP address
Appium自动化测试基础 — Appium测试环境搭建总结
Appium automation test foundation - Summary of appium test environment construction
Introduction et expérience de wazuh open source host Security Solution
1.13 - RISC/CISC
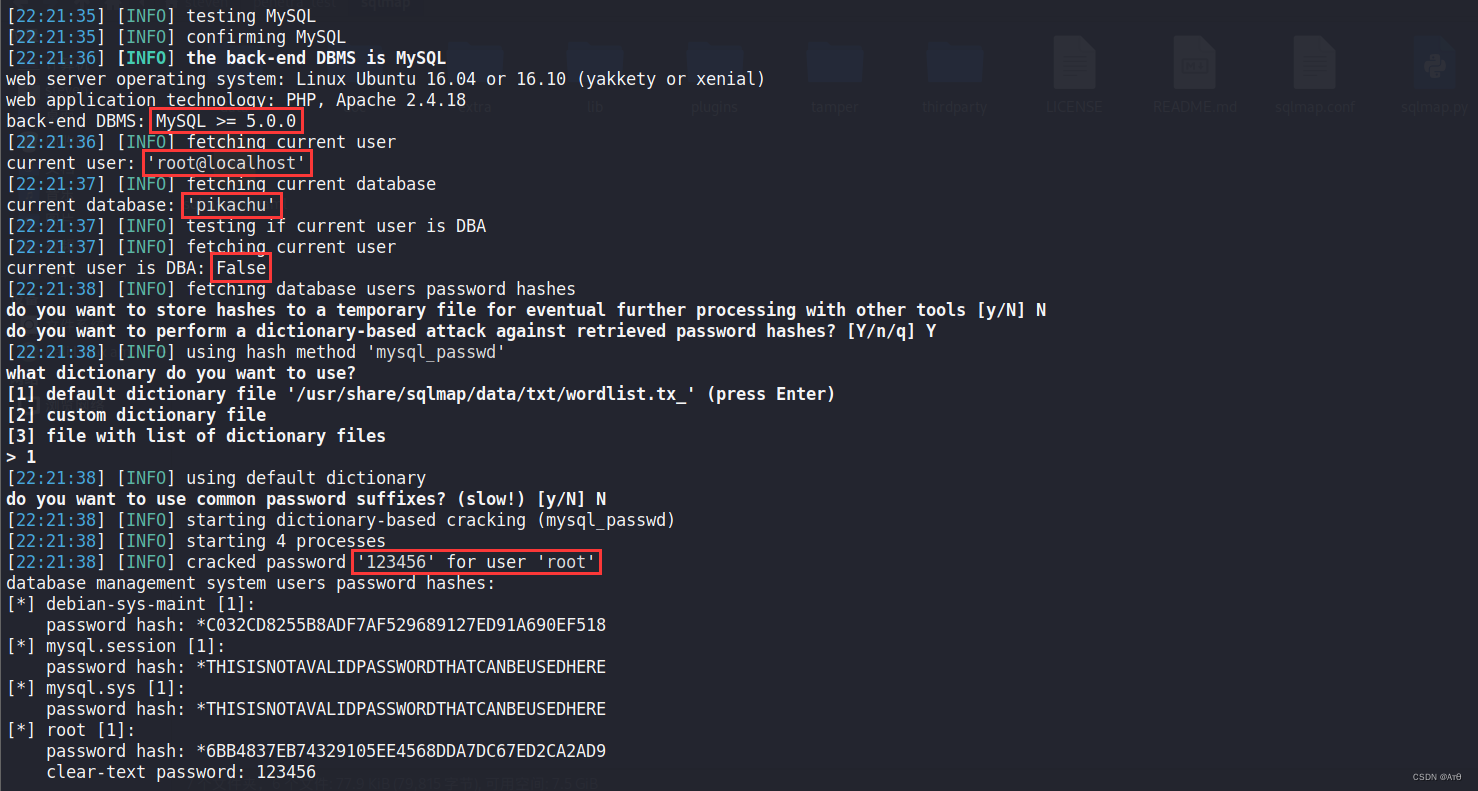
Sqlmap tutorial (II) practical skills I
![Introduction to LVS [unfinished (semi-finished products)]](/img/72/d5a943a8d6d71823dcbd7f23dda35b.png)
Introduction to LVS [unfinished (semi-finished products)]
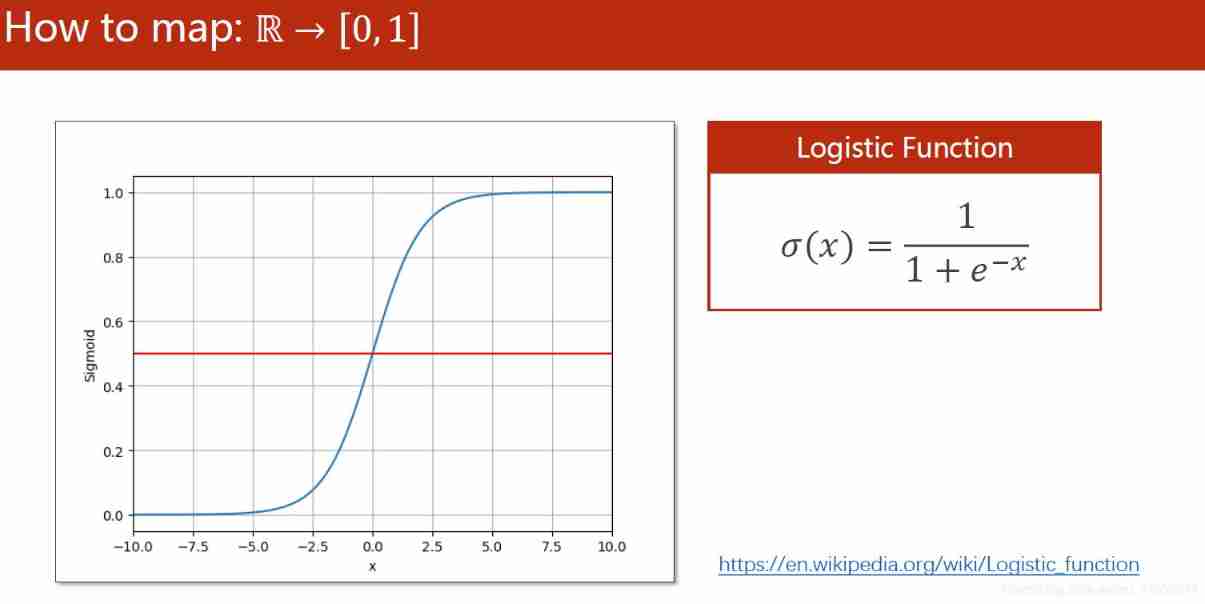
6. Logistic model
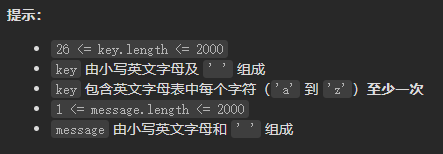
Leetcode-6108: decrypt messages
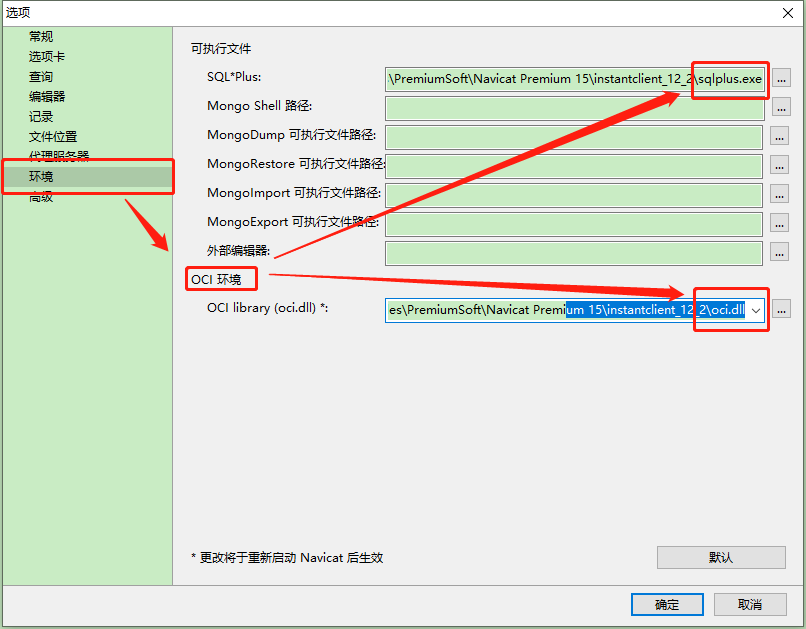
Erreur de connexion Navicat à la base de données Oracle Ora - 28547 ou Ora - 03135
随机推荐
Typical use cases for knapsacks, queues, and stacks
leetcode-1200:最小绝对差
Is it impossible for lamda to wake up?
数据可视化图表总结(二)
Introduction to LVS [unfinished (semi-finished products)]
CPU内核和逻辑处理器的区别
可变电阻器概述——结构、工作和不同应用
Data visualization chart summary (II)
1040 Longest Symmetric String
Appium automation test foundation - Summary of appium test environment construction
SQLMAP使用教程(二)实战技巧一
Scope of inline symbol
【Rust 笔记】17-并发(下)
One question per day 1765 The highest point in the map
927. 三等分 模拟
MatrixDB v4.5.0 重磅发布,全新推出 MARS2 存储引擎!
Implement a fixed capacity stack
2022 极术通讯-Arm 虚拟硬件加速物联网软件开发
Matrixdb V4.5.0 was launched with a new mars2 storage engine!
SQLMAP使用教程(一)