当前位置:网站首页>Spark及相关生态组件安装配置——快速回忆
Spark及相关生态组件安装配置——快速回忆
2022-08-02 14:09:00 【虹夭】
目录
Scala安装配置
- 先安装java
- 安装路径
- 环境变量
# Scala Env
export PATH=$PATH:/usr/local/scala/bin
- 命令
scala- 退出
:quit
- 退出
Spark安装配置
- 安装路径
/usr/local/spark
环境变量
# Spark Env
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
Spark集群配置
cd $SPARK_HOME/conf
cp slaves.template slaves
slaves
hadoophost
## slave01 ##多个工作节点时配置对应的主机名
## slave02 ##多个工作节点时配置对应的主机名
spark-env.sh
cp spark-env.sh.template spark-env.sh
修改spark-env.sh文件内容
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_MASTER_IP=hadoophost ##(或者配置主机IP)
配置好后,将Master主机上的/usr/local/spark文件夹复制到各个节点上。在Master主机上执行如下命令:
cd /usr/local/
tar -zcf ~/spark.master.tar.gz ./spark
cd ~
scp ./spark.master.tar.gz slave01:/home/hadoop
scp ./spark.master.tar.gz slave02:/home/hadoop
多个worker节点时,需要在每个worker节点中如slave01,slave02节点上分别执行下面同样的操作:
sudo rm -rf /usr/local/spark/
sudo tar -zxf ~/spark.master.tar.gz -C /usr/local
sudo chown -R hadoop /usr/local/spark
Spark命令
在Master主机上运行命令
start-all.sh #启动所有节点,和hadoop的命令冲突,建议重命名为spark-start-all.sh
stop-all.sh # 建议重命名为spark-start-all.sh
start-master.sh #启动主节点
stop-master.sh
start-slaves.sh #启动从节点
stop-slaves.sh
spark命令和hadoop的命令冲突,建议重命名
cd $SPARK_HOME/sbin
mv start-all.sh spark-start-all.sh
mv stop-all.sh spark-stop-all.sh
参数
--master
执行
spark-shell #Spark Shell
spark-submit
--class <main-class> //需要运行的程序的主类,应用程序的入口点
--master <master-url> //Master URL,下面会有具体解释
--deploy-mode <deploy-mode> //部署模式
--driver-class-path //驱动的类路径
... # other options //其他参数
<application-jar> //应用程序JAR包
[application-arguments] //传递给主类的主方法的参数
–master
local 使用一个Worker线程本地化运行SPARK(完全不并行)
local[*] 使用逻辑CPU个数数量的线程来本地化运行Spark
local[K] 使用K个Worker线程本地化运行Spark(理想情况下,K应该根据运行机器的CPU核数设定)
spark://HOST:PORT 连接到指定的Spark standalone master。默认端口是7077.
yarn-client 以客户端模式连接YARN集群。集群的位置可以在HADOOP_CONF_DIR 环境变量中找到。
yarn-cluster 以集群模式连接YARN集群。集群的位置可以在HADOOP_CONF_DIR 环境变量中找到。
mesos://HOST:PORT 连接到指定的Mesos集群。默认接口是5050。
Spark的Hive支持配置
添加hive配置文件
cp $HIVE_HOME/conf/hive-site.xml $SPARK_HOME/conf
添加mysql驱动
将mysql-connector-java-5.1.49-bin.jar放到$SPARK_HOME/jars/ext下
配置文件
spark-env.sh
export JAVA_HOME=/usr/lib/java/jdk1.8.0_271
export CLASSPATH=$CLASSPATH:/usr/local/hive/lib
export SCALA_HOME=/usr/local/scala
export HIVE_CONF_DIR=/usr/local/hive/conf
spark-defaults.conf
cp spark-defaults.conf.template spark-defaults.conf
spark.driver.extraClassPath=/usr/local/spark/jars/ext/*
测试
spark-shell
整段复制命令即可
import org.apache.spark.sql.SparkSession
val warehouseLocation = "spark-warehouse"
val spark = SparkSession.builder().appName("Spark Hive Example").config("spark.sql.warehouse.dir", warehouseLocation).enableHiveSupport().getOrCreate()
import spark.implicits._
spark.sql("CREATE DATABASE IF NOT EXISTS sparktest")
Kafka安装配置
- 安装到/usr/local/kafka
环境变量
#KAFKA Env
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/bin
Kafka配置
cd $KAFKA_HOME/config
server.properties
zookeeper.connect=hadoophost:2181
Kafka命令
kafka-server-start.sh $KAFKA_HOME/config/server.properties
外部支持
SparkStreaming
将spark-streaming-kafka-0-10_2.12-2.4.0.jar放到$SPARK_HOME/jars/ext下
spark-submit时添加–driver-class-path
spark-submit --driver-class-path $SPARK_HOME/jars/ext/*:$KAFKA_HOME/libs/* 其他参数...
Flume安装配置
flume下载地址: https://mirrors.tuna.tsinghua.edu.cn/apache/flume/1.9.0/
/usr/local/flume
环境变量
# Flume Env
export FLUME_HOME=/usr/local/flume
export FLUME_CONF_DIR=$FLUME_HOME/conf
export PATH=$PATH:$FLUME_HOME/bin
Flume配置
cd $FLUME_HOME/conf
flume-env.sh
cp flume-env.sh.template flume-env.sh
export JAVA_HOME=/usr/lib/java/jdk1.8.0_271
问题处理
找不到或无法加载主类 org.apache.flume.tools.GetJavaProperty问题
如果系统里安装了hbase,会出现错误: 找不到或无法加载主类 org.apache.flume.tools.GetJavaProperty。如果没有安装hbase,这一步可以略过。
修改flume-ng脚本,找到如下local HBASE_JAVA_LIBRARY_PATH这个配置项,在最后增加“2>/dev/null | grep hbase”
cd $FLUME_HOME/bin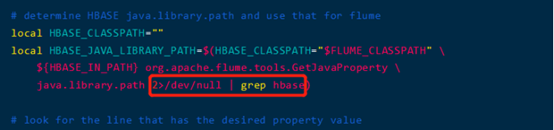
Flume命令
flume-ng version #查看flume版本信息
外部支持
SparkStreaming
将spark-streaming-flume_2.11-2.1.0.jar放到$SPARK_HOME/jars/ext下(可以通过maven下载到)
spark-submit时添加–driver-class-path
spark-submit --driver-class-path $SPARK_HOME/jars/ext/*:$FLUME_HOME/libs/* 其他参数...
边栏推荐
- 循环神经网络RNN 之 LSTM
- Win11 computer off for a period of time without operating network how to solve
- PyTorch①---加载数据、tensorboard的使用
- FP6296锂电池升压 5V9V12V内置 MOS 大功率方案原理图
- 将SSE指令转换为ARM NEON指令
- Bash shell位置参数
- PyTorch⑥---卷积神经网络_池化层
- [论文阅读] ACT: An Attentive Convolutional Transformer for Efficient Text Classification
- 深度学习之 卷积网络(textCNN)
- “自主可控”的正确姿势
猜你喜欢



随机推荐
arm ldr系列指令
win10怎么设置不睡眠熄屏?win10设置永不睡眠的方法
The problem that UIWindow's makeKeyAndVisible does not call viewDidLoad of rootviewController
内存申请(malloc)和释放(free)之下篇
针对多轮推理分类问题的软标签构造方法
vscode镜像
FP7195转模拟恒流调光芯片在机器视觉光源的应用优势
DP4344兼容CS4344-DA转换器
神经网络可以解决一切问题吗:一场知乎辩论的整理
Win10电脑需要安装杀毒软件吗?
Publish module to NPM should be how to operate?Solutions to problems and mistake
DP1101兼容CC1101是SUB1GHz无线收发芯片应用于智能家居
General syntax and usage instructions of SQL (picture and text)
Win11电脑一段时间不操作就断网怎么解决
Daily - Notes
【使用Pytorch实现ResNet网络模型:ResNet50、ResNet101和ResNet152】
Binder机制(下篇)
“自主可控”的正确姿势
The overlapping effect of the two surfaceviews is similar to the video and handout practice in the live effect
Win10 can't start WampServer icon is orange solution