当前位置:网站首页>Statistical method for anomaly detection
Statistical method for anomaly detection
2022-07-07 23:06:00 【Anny Linlin】
1、 The general idea is : Learn a generation model that fits a given data set , Then identify the objects in the low probability region of the model , Take them as outliers .
2、 Statistical methods for anomaly detection can be divided into two main types : Parametric and nonparametric methods .
3、 Parameter method
3.1 Univariate outlier detection based on normal distribution
Data involving only one attribute or variable is called metadata . We assume that the data is generated by a normal distribution , Then the parameters of normal distribution can be learned from the input data , And identify the points with low probability as abnormal points .
3.2 Multivariate outlier detection
Data involving two or more attributes or variables is called multivariate data . Many unary outlier detection methods can be extended , Used to process multivariate data . The core idea is to transform the multi outlier detection task into a single outlier detection problem . For example, when univariate outlier detection based on normal distribution is extended to multivariate cases , You can find the mean and standard deviation of each dimension .
4、 Nonparametric methods
In the nonparametric method of anomaly detection ,“ Normal data ” Learning from input data , Instead of assuming a priori . Usually , Nonparametric methods make less assumptions about data , So it can be used in more cases .
Example : Use histogram to detect outliers .
Histogram is a frequently used nonparametric statistical model , It can be used to detect outliers . This process includes the following two steps :
step 1: Construct histogram . Use input data ( Training data ) Construct a histogram . The histogram can be unary , Or diversified ( If the input data is multidimensional ).
Although nonparametric methods do not assume any prior statistical model , However, it is often true that the user is required to provide parameters , In order to learn from data . for example , The user must specify the type of histogram ( Equal in width or depth ) And other parameters ( The number of boxes in the histogram or the size of each box ). Different from the parametric method , These parameters do not specify the type of data distribution .
step 2: Detect outliers . To determine whether an object is an outlier , You can check it against the histogram . In the simplest way , If the object falls into a box in the histogram , Then the object is considered normal , Otherwise, it is considered as an outlier .
For more complex methods , Histogram can be used to give each object an outlier score . For example, let the abnormal point score of the object be the reciprocal of the volume of the box that the object falls into .
One disadvantage of using histogram as a nonparametric model for outlier detection is , It's hard to choose the right box size . One side , If the box size is too small , Then many normal objects will fall into empty or sparse boxes , Therefore, it is mistakenly recognized as an outlier . On the other hand , If the box size is too large , Then the abnormal point object may penetrate into some frequent boxes , thus “ Pretending to be ” Become normal .
5、HBOS
HBOS Full name :Histogram-based Outlier Score. It's a combination of univariate methods , You can't model dependencies between features , But it's faster , Friendly to big data sets . The basic assumption is that each dimension of the dataset is independent of each other . Then interval each dimension (bin) Divide , The higher the density of the interval , The lower the abnormal score .
6、 practice
边栏推荐
- Sword finger offer 27 Image of binary tree
- 聊聊 Dart 的空安全 (null safety) 特性
- 每日一题——PAT乙级1002题
- Personal statement of testers from Shuangfei large factory: is education important for testers?
- 0-5VAC转4-20mA交流电流隔离变送器/转换模块
- 微生物健康網,如何恢複微生物群落
- Loki, the "open source star picking program", realizes the efficient management of harbor logs
- Amesim2016 and matlab2017b joint simulation environment construction
- 一次搞明白 Session、Cookie、Token,面试问题全稿定
- 【刷题记录】3. 无重复字符的最长子串
猜你喜欢

iNFTnews | NFT技术的广泛应用及其存在的问题
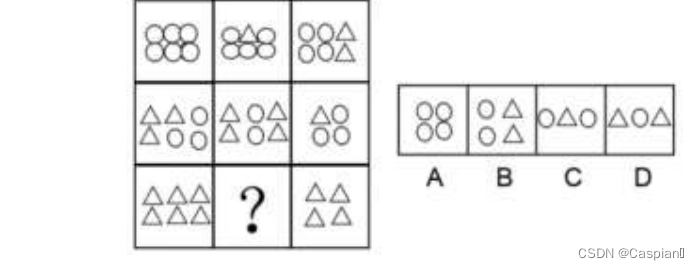
行测-图形推理-8-图群类

Line test - graphic reasoning - 1 - Chinese character class
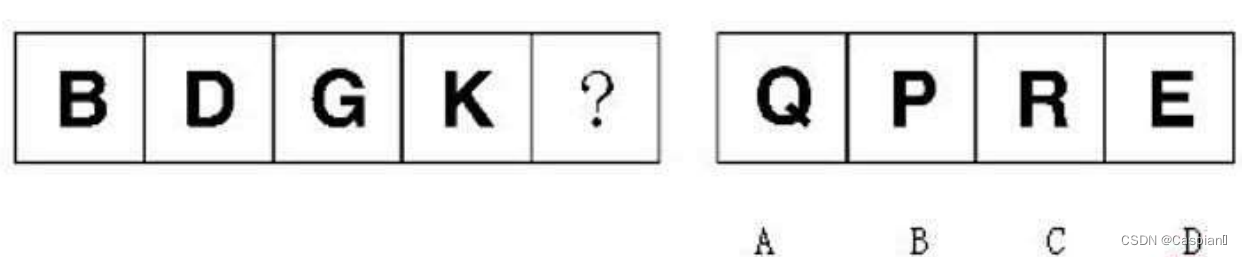
行測-圖形推理-4-字母類
Unity与WebGL的相爱相杀
Line test graph reasoning graph group class

Sword finger offer 27 Image of binary tree
![Leetcode interview question 02.07 Linked list intersection [double pointer]](/img/a5/58b4735cd0e47f1417ac151a1bcca4.jpg)
Leetcode interview question 02.07 Linked list intersection [double pointer]

Microbial health network, how to restore microbial communities

行测-图形推理-5-一笔画类
随机推荐
Cascade-LSTM: A Tree-Structured Neural Classifier for Detecting Misinformation Cascades-KDD2020
[record of question brushing] 3 Longest substring without duplicate characters
Signal feature extraction +lstm to realize gear reducer fault diagnosis -matlab code
微生物健康網,如何恢複微生物群落
Debezium series: source code reading snapshot reader
Use JfreeChart to generate curves, histograms, pie charts, and distribution charts and display them to JSP-1
LeetCode206. Reverse linked list [double pointer and recursion]
Leetcode19. Delete the penultimate node of the linked list [double pointer]
Interview questions: how to test app performance?
LeetCode707. Design linked list
Leetcode interview question 02.07 Linked list intersection [double pointer]
Visual studio 2019 installation
Class implementation of linear stack and linear queue (another binary tree pointer version)
Sword finger offer 63 Maximum profit of stock
行测-图形推理-4-字母类
数据库每日一题---第22天:最后一次登录
Line test - graphic reasoning - 1 - Chinese character class
CTF练习
Use JfreeChart to generate curves, histograms, pie charts, and distribution charts and display them to jsp-2
Unity 动态合并网格纹理