当前位置:网站首页>cuda编程
cuda编程
2022-07-06 21:08:00 【AphilGuo】
/* 程序开始->cpu运行->将cpu数据copy到gpu->gpu运行->将gpu数据copy到cpu->cpu运行->结束 */
#include<stdio.h>
#include<stdlib.h>
#include<cuda_runtime.h>
#include<device_launch_parameters.h>
// 定义宏,主要功能是检测cuda函数的错误
#define CHECK(call) \ {
\ const cudaError_t err = call; \ if (err != cudaSuccess) \ {
\ fprintf(stderr, "Error: %s:%d, ", __FILE__, __LINE__); \ fprintf(stderr, "code: %d, reason: %s\n", err, \ cudaGetErrorString(err)); \ exit(1); \ } \ }
// 内核函数
__global__ void helloFromGPU()
{
printf("======================\n");
}
// 主函数
/* * <<<grid, block>>>:三个尖括号是cuda特有,是核函数的执行配置,调用核函数必须用 * grid是网格,这个值代表调用多少个block;block是线程块,代表调用多少个线程 * cudaDeviceReset():显示地释放和清空当前进程gpu资源 */
int main(int argc, char** argv)
{
printf("print from cpu\n");
helloFromGPU << <1, 10 >> > ();
CHECK(cudaDeviceReset());
return 0;
}
cuda程序中既包含host程序,又包含device程序,分别在cpu和gpu上运行。host与device之间进行通信,这样可以进行数据拷贝。
1、分配host内存,并进行数据初始化
2、分配device内存,并从host将数据拷贝到device上
3、调用cuda的核函数在device上完成指定的运算
4、将device上的运算结果拷贝到host上
5、释放device和host上分配的内存
在cuda中每一个线程都要执行核函数,并且每个线程都会分配一个唯一的线程号threadid,这个id值可以通过核函数的内置变量threadIdx来获得。
由于gpu实际上是异构模型,所以需要区分host和device上的代码,在cuda中是通过函数类型限定词区别host和device上的函数,主要三个函数类型限定词:
global:在device上执行,从host中调用,返回类型必须是void,不支持可变参数,不能成为类成员函数;__global__定义的kernel是异步的,host不会等待kernel执行完就执行下一步。
device:在device上执行,单仅可以从device中调用,不可以和__global__同时使用。
host:在host上执行,仅可以从host上调用,可省略不写,不可和__global__同时用,但可和__device__一起使用,此时函数会在device和host都编译。
kernel在device上执行时实际上是启动了很多线程,一个kernel所启动的所有线程称为一个网格(grid),同一个网格的线程共享相同的全局内存空间,grid是线程结构的第一层次,而网格又可分为很多线程块(block),一个线程块中包含很多线程,这是第二个层次。
sm的核心组件包括cuda核心,共享内存,寄存器等。sm可并发执行数百个线程,并发能力取决于sm所拥有的资源数。当一个kernel被执行时,它的grid中的线程块被分配到sm上,一个线程块只能在一个sm上被调度。
#include<cuda_runtime.h>
#include<device_launch_parameters.h>
#include<stdio.h>
#include<stdlib.h>
#include<iostream>
using namespace std;
#define CHECK(call) \ {
\ const cudaError_t err = call; \ if (err != cudaSuccess) \ {
\ fprintf(stderr, "Error: %s:%d, ", __FILE__, __LINE__); \ fprintf(stderr, "code: %d, reason: %s\n", err, \ cudaGetErrorString(err)); \ exit(1); \ } \ }
int main()
{
int dev = 0;
cudaDeviceProp devProp;
CHECK(cudaGetDeviceProperties(&devProp, dev));
std::cout << "use gpu device: " << dev << ":" << devProp.name << std::endl;
std::cout << "number of sm: " << devProp.multiProcessorCount << std::endl;
std::cout << "shared memory space of each thread block: " << devProp.sharedMemPerBlock / 1024.0 << "KB" << std::endl;
std::cout << "max thread number of each thread block: " << devProp.maxThreadsPerBlock << std::endl;
std::cout << "max thread number of each em: " << devProp.maxThreadsPerMultiProcessor << std::endl;
std::cout << "max thread number of each sm: " << devProp.maxThreadsPerMultiProcessor / 32 << std::endl;
}

cuda编程中的api:
cudaMalloc函数:cudaError_t cudaMalloc(void** devPtr, size_t size);
在device上申请一定字节大小的显存,其中devPtr是指向所分配内存的指针。同时要释放分配的内存使用cudaFree函数,另一个重要的函数是负责host和device之间数据通信的cudaMemcpy函数:
cudaError_t cudaMemcpy(void* dst, const void* src,size_t count, cudaMemcpyKind king)
src:指向数据源,dst是目标区域, const是复制的字节数,kind控制复制的方向:
cudaMemcpyHostToHost, cudaMemcpyHostToDevice, cudaMemcpyDeviceToHost以及cudaMemcpyDeviceToDevice。
#include<cuda_runtime.h>
#include<device_launch_parameters.h>
#include<iostream>
/*#define CHECK(call) \ { \ const cudaError_t err = call; \ if (err != cudaSuccess) \ { \ fprintf(stderr, "Error: %s:%d, ", __FILE__, __LINE__); \ fprintf(stderr, "code: %d, reason: %s\n", err, \ cudaGetErrorString(err)); \ exit(1); \ } \ } */
//内核函数
__global__ void add(float* x, float* y, float* z, int n)
{
//获取全局索引 1-dim
int index = threadIdx.x + blockIdx.x * blockDim.x;
//步长
int stride = blockDim.x * gridDim.x;
for (int i = index; i < n; i += stride)
{
z[i] = x[i] + y[i];
}
}
int main()
{
int N = 1 << 20; //将1左移20位
int nBytes = N * sizeof(float);
//申请host空间
float* x, * y, * z;
x = (float*)malloc(nBytes);
y = (float*)malloc(nBytes);
z = (float*)malloc(nBytes);
//初始化数据
for (int i = 0; i < N; i++)
{
x[i] = 10.0;
y[i] = 20.0;
}
//申请device内存
float* d_x, * d_y, * d_z;
cudaMalloc((void**)&d_x, nBytes);
cudaMalloc((void**)&d_y, nBytes);
cudaMalloc((void**)&d_z, nBytes);
//将host数据拷贝到device
cudaMemcpy((void*)d_x, (void*)x, nBytes, cudaMemcpyHostToDevice);
cudaMemcpy((void*)d_y, (void*)y, nBytes, cudaMemcpyHostToDevice);
//定义kernel的执行配置
dim3 blockSize(256);
dim3 gridSize((N + blockSize.x - 1) / blockSize.x);
//执行kernel
add << <gridSize, blockSize >> > (d_x, d_y, d_z, N);
//将device得到结果拷贝到host
cudaMemcpy((void*)z, (void*)d_z, nBytes, cudaMemcpyDeviceToHost);
//检查执行结果
float maxError = 0.0;
for (int i = 0; i < N; i++)
{
maxError = fmax(maxError, fabs(z[i] - 30.0));
}
std::cout << "max error: " << maxError << std::endl;
//释放device内存
cudaFree(d_x);
cudaFree(d_y);
cudaFree(d_z);
//释放host内存
free(x);
free(y);
free(z);
return 0;
}
统一内存管理,上面需要单独在host和device上进行内存分配,并进行数据拷贝,很容易出错。cuda6.0引入统一内存来避免这种麻烦。就是使用一个一个托管内存来共同管理host和device中的内存,并且自动在host和device中进行数据传输。cuda中使用cudaMallocManaged函数分配托管内存:
cudaError_t cudaMallocManaged(void** devPtr, size_t size, unsigned int flag=0);
边栏推荐
猜你喜欢
【安全攻防】序列化與反序列,你了解多少?
![[dpdk] dpdk sample source code analysis III: dpdk-l3fwd_ 001](/img/f6/dced69ea36fc95ef84bb546c56dd91.png)
[dpdk] dpdk sample source code analysis III: dpdk-l3fwd_ 001
ggplot 分面的细节调整汇总
About Tolerance Intervals
接口数据安全保证的10种方式

QT item table new column name setting requirement exercise (find the number and maximum value of the array disappear)

Function reentry, function overloading and function rewriting are understood by yourself
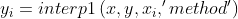
预处理——插值
QT opens a file and uses QFileDialog to obtain the file name, content, etc
QT 项目 表格新建列名称设置 需求练习(找数组消失的数字、最大值)
随机推荐
史上最全学习率调整策略lr_scheduler
My brave way to line -- elaborate on what happens when the browser enters the URL
Set static IP for raspberry pie
Function reentry, function overloading and function rewriting are understood by yourself
24.(arcgis api for js篇)arcgis api for js点修改点编辑(SketchViewModel)
[hcie TAC] question 3
First understand the principle of network
ubuntu20安裝redisjson記錄
CMB's written test - quantitative relationship
Introduction to opensea platform developed by NFT trading platform (I)
HW notes (II)
pip只下载不安装
【安全攻防】序列化與反序列,你了解多少?
MySQL storage engine
再AD 的 界面顶部(菜单栏)创建常用的快捷图标
R data analysis: how to predict Cox model and reproduce high score articles
[dpdk] dpdk sample source code analysis III: dpdk-l3fwd_ 001
Adaptive non European advertising retrieval system amcad
HW-小记(二)
Calculation of time and space complexity (notes of runners)